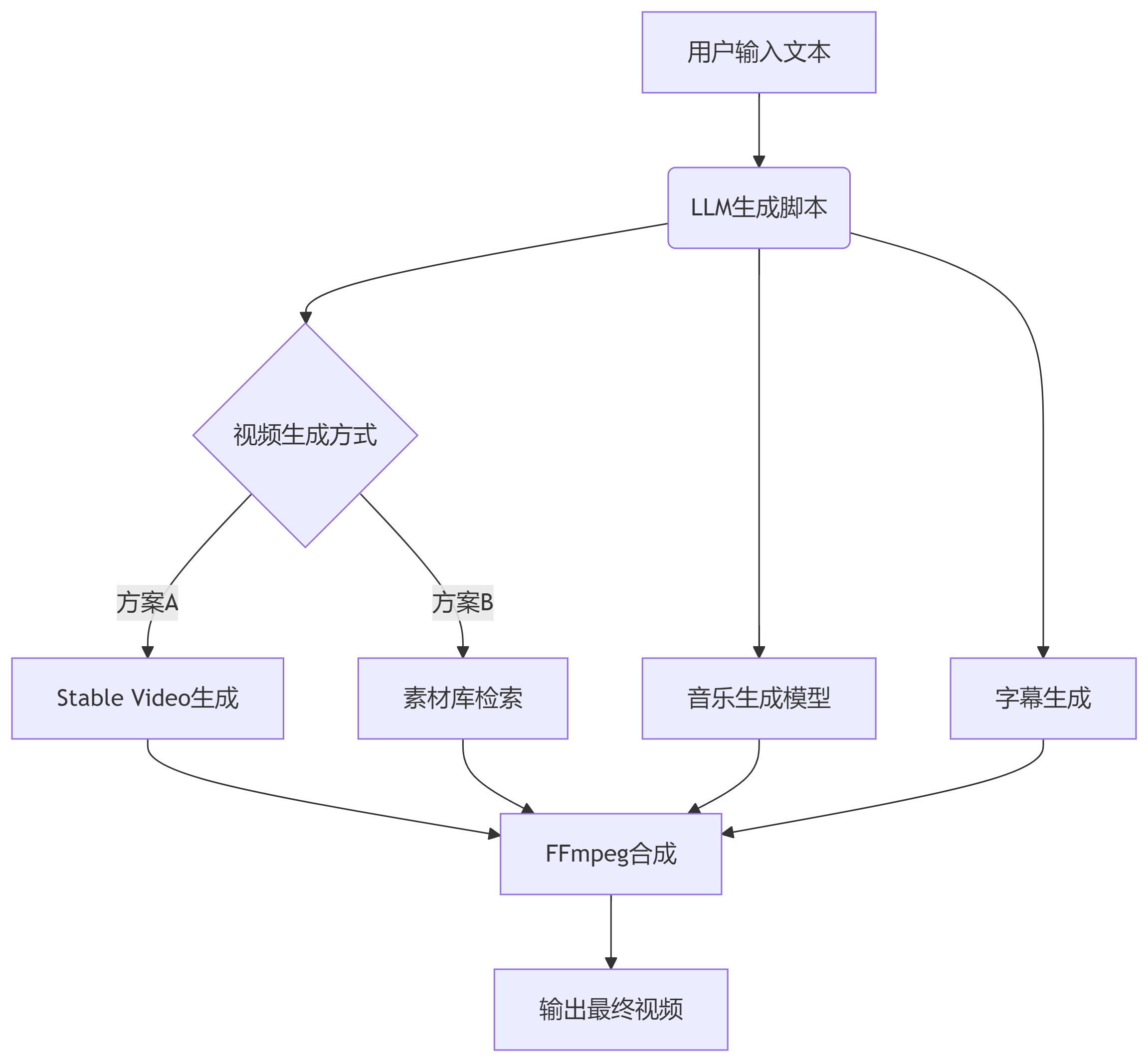
什么是Prometheus和Grafana?
- Prometheus:一款开源的监控告警工具,擅长时序数据存储和多维度查询(通过PromQL),采用Pull模型主动抓取目标指标。
- Grafana:数据可视化平台,支持多种数据源(如Prometheus),通过丰富的仪表盘展示监控数据。
- 核心协作流程:
- Exporters(如Node Exporter)采集指标 → Prometheus存储并计算 → Grafana可视化展示 → Alertmanager触发告警。
监控系统核心流程:
- 数据采集
📥 Exporters(如node_exporter、mysqld_exporter)从目标系统(主机、MySQL等)收集指标。 - 数据存储与计算
🗃️ Prometheus 定期从 Exporters 拉取(Pull) 数据,存储为时序数据,并通过 PromQL 进行实时计算。 - 可视化展示
📊 Grafana 从 Prometheus 读取数据,通过预定义仪表盘(如ID 1860)展示监控图表。 - 告警触发与通知
🔔 Prometheus 根据告警规则(如CPU > 85%)触发告警 → Alertmanager 分组、路由告警 → 通过邮件/Slack通知用户。
与Zabbix的对比与优势
- 数据模型:Prometheus的多维标签比Zabbix的扁平键值更灵活。
- 扩展性:通过Exporters轻松集成新系统,无需定制脚本。
- 云原生支持:天然适配Kubernetes,适合容器化环境。
建议从监控主机和现有Docker服务入手,逐步扩展至MySQL、Tomcat,最终实现全栈监控+告警闭环。
组件介绍
1、数据采集类(Exporters)
| 组件名称 | 核心功能 | 适用场景 | 官方文档 |
|---|---|---|---|
| Node Exporter | 采集主机基础指标(CPU、内存、磁盘、网络等) | 监控物理机/虚拟机性能 | GitHub |
| cAdvisor | 采集容器资源使用指标(CPU、内存、网络、文件系统) | 监控 Docker 容器 | GitHub |
| MySQL Exporter | 采集 MySQL 数据库性能指标(查询数、连接数等) | 监控 MySQL 数据库状态 | GitHub |
| JMX Exporter | 将 Java 应用的 JMX 指标转换为 Prometheus 格式 | 监控 Tomcat、Kafka 等 Java 应用 | GitHub |
| Blackbox Exporter | 通过 HTTP/HTTPS、TCP、ICMP 探测服务可用性 | 监控网站可用性、端口存活状态 | GitHub |
| SNMP Exporter | 采集网络设备(交换机、路由器)的 SNMP 指标 | 监控网络设备性能 | GitHub |
- cAdvisor google镜像
gcr.io/cadvisor/cadvisor网络无法pull可使用bitnami/cadvisor:0.52.1
2、数据存储与处理类
| 组件名称 | 核心功能 | 适用场景 |
|---|---|---|
| Prometheus Server | 时序数据库,存储监控数据,支持 PromQL 查询 | 核心组件,必选 |
| Thanos | 提供 Prometheus 高可用、长期存储和全局查询 | 大规模监控集群数据聚合 |
| VictoriaMetrics | 高性能时序数据库,兼容 Prometheus 协议 | 替代 Prometheus TSDB,适合海量数据 |
3、可视化与告警类
| 组件名称 | 核心功能 | 适用场景 |
|---|---|---|
| Grafana | 可视化平台,支持多种数据源和仪表盘模板 | 数据展示,必选 |
| Alertmanager | 告警路由、去重、静默,支持邮件/Slack/Webhook | 集中管理告警通知 |
| Grafana Loki | 日志聚合系统,与 Prometheus 指标联动 | 监控日志数据(需搭配 Promtail) |
4、辅助工具类
| 组件名称 | 核心功能 | 适用场景 |
|---|---|---|
| Pushgateway | 接收短期任务(如批处理作业)的指标推送 | 监控 Cron 任务、一次性脚本 |
| Prometheus Operator | 在 Kubernetes 中自动化管理 Prometheus 配置 | Kubernetes 环境监控部署 |
| Grafana Tempo | 分布式追踪系统,与 Prometheus 指标联动 | 链路追踪与性能分析 |
一、Server端配置
1. 配置文件目录结构
root@host4:/opt/monitor# tree
.
├── alertmanager.yml # Alertmanager配置
├── alert_rules.yml # 告警规则
├── docker-compose.yml # Compose主文件
└── prometheus.yml # Prometheus主配置
├── grafana-provisioning
│ ├── alerting #存储告警规则配置文件,用于预定义告警条件与通知策略
│ ├── dashboards #存放仪表板JSON配置文件,支持自动加载/更新仪表板(无需手动创建)
│ ├── datasources #配置数据源连接信息,支持多数据源并行配置(Prometheus/MySQL等)
│ │ └── prometheus.yml
│ ├── notifiers #定义告警通知渠道(邮件/钉钉/Slack等),与alerting/目录规则联动实现告警推送
│ └── plugins #放置预安装插件(如可视化插件或数据源插件),容器启动时自动加载插件二进制文
2. 关键配置文件示例
docker-compose.yml - Compose主文件
services:
# Prometheus核心服务
prometheus:
image: prom/prometheus:v3.4.0
container_name: prometheus
restart: unless-stopped
networks:
- monitor-net
ports:
- "9090:9090"
volumes:
- prometheus_data:/prometheus # 时序数据库持久化存储
- ./prometheus.yml:/etc/prometheus/prometheus.yml:ro # 主配置文件注入
- ./alert_rules.yml:/etc/prometheus/alert_rules.yml:ro # 告警规则注入
command:
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.retention.time=30d # 数据保留30天
- --web.enable-lifecycle # 启用配置热加载
environment:
- TZ=Asia/Shanghai # 时区设置
deploy:
resources:
limits:
cpus: '1.0'
memory: 2G
# Grafana可视化
grafana:
image: grafana/grafana:10.1.5
container_name: grafana
restart: unless-stopped
networks:
- monitor-net
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana # 配置/仪表盘持久化
- ./grafana-provisioning:/etc/grafana/provisioning # 预配置仪表盘
environment:
- GF_SECURITY_ADMIN_PASSWORD=L1L7WxZ443iyZd #必须修改为复杂密码
# - GF_SERVER_DOMAIN=monitor.yourcompany.com # 生产域名,若没有域名可注释或删除此行
- GF_SERVER_SERVE_FROM_SUB_PATH=true # 强制使用IP访问(可选)
- GF_SERVER_ENABLE_GZIP=true
- GF_USERS_ALLOW_SIGN_UP=false # 禁用公开注册
- GF_AUTH_DISABLE_LOGIN_FORM=false # SSO登录,需正确配置代理认证(需后端支持)
- GF_AUTH_PROXY_ENABLED=false #代理认证
# - GF_AUTH_PROXY_HEADER_NAME=X-WEBAUTH-USER #代理认证
- GF_PLUGINS_ALLOW_LOADING_UNSIGNED_PLUGINS=false
- GF_DATABASE_TYPE=postgres
- GF_DATABASE_HOST=postgres
- GF_DATABASE_USER=grafana
- GF_DATABASE_PASSWORD=L1L7WxZ443iyZd
- GF_LIVE_ENABLED=false
- GF_PLUGINS_DISABLE_AUTOLOAD=true # 禁用插件自动加载
# - GF_PATHS_PLUGINS=/var/lib/grafana/plugins # 显式指定插件路径
# - GF_DEFAULT_PLUGINS_PATH=/dev/null # 禁用默认插件路径
depends_on:
postgres:
condition: service_healthy # 等待 PostgreSQL 健康检查通过
prometheus:
condition: service_started # 确保 Prometheus 已启动
deploy:
resources:
limits:
cpus: '0.5'
memory: 1G
# Node Exporter示例 (按需部署到各主机)
node-exporter:
image: prom/node-exporter:v1.9.1
container_name: node-exporter
restart: unless-stopped
networks:
- monitor-net
ports:
- "9100:9100"
volumes:
- /proc:/host/proc:ro
- /run/udev:/run/udev:ro #获取磁盘设备信息
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
deploy:
resources:
limits:
cpus: '0.2'
memory: 256M
# 容器监控(可选)
cadvisor:
image: bitnami/cadvisor:0.52.1
# image: google/cadvisor:v0.33.0
user: "0:996" # root 用户 + docker 组 GID
container_name: cadvisor
restart: unless-stopped
networks:
- monitor-net
ports:
- "8080:8080"
volumes:
- /:/rootfs:ro,rslave # 只读挂载防止篡改
- /var/run:/var/run:ro,rslave
- /sys:/sys:ro,rslave
- /var/lib/docker:/var/lib/docker:ro,rslave #解决日志中 Failed to get system UUID 警告
- /etc/machine-id:/etc/machine-id:ro #挂载 /dev/disk:更精确的磁盘监控
- /dev/disk:/dev/disk:ro
privileged: true # 必须权限
# command:
# - --docker_only=true #仅监控 Docker 容器(隐式禁用 CRI-O/Podman 检测)
# - --disable_metrics=hugetlb,advtcp,udp # 可选:禁用不常用指标(减少日志干扰)
deploy:
resources:
limits:
cpus: '0.5'
memory: 1G
postgres:
image: postgres:15
restart: always
healthcheck:
test: ["CMD-SHELL", "pg_isready -U grafana -d grafana || exit 1"]
interval: 5s
timeout: 5s
retries: 10
networks:
- monitor-net
environment:
POSTGRES_USER: grafana
POSTGRES_PASSWORD: L1L7WxZ443iyZd
POSTGRES_DB: grafana
POSTGRES_HOST_AUTH_METHOD: scram-sha-256 # 启用加密认证
POSTGRES_INITDB_ARGS: "--auth-host=scram-sha-256 --auth-local=scram-sha-256" #安全加固
volumes:
- postgres_data:/var/lib/postgresql/data
deploy:
resources:
limits:
memory: 512M
# 自定义网络隔离监控系统流量
networks:
monitor-net:
driver: bridge
attachable: true
volumes:
prometheus_data: {} # Prometheus时序数据持久化
grafana_data: {} # Grafana配置/仪表盘数据持久化
postgres_data: {}
核心必选模块
| 服务名 | 必要性 | 说明 |
|---|---|---|
prometheus | 必选 | 监控数据存储与计算核心,不可缺失 |
grafana | 必选 | 可视化必备组件 |
node-exporter | 必选 | 采集主机基础指标(CPU/内存/磁盘等) |
按需选装模块
| 服务名 | 必要性 | 场景建议 |
|---|---|---|
cadvisor | 可选 | 需监控Docker容器时启用 |
alertmanager | 可选 | 需告警通知时启用(初期可跳过,后续添加) |
① prometheus.yml - Prometheus抓取目标配置
global: # 全局采集参数
scrape_interval: 15s # 抓取间隔
evaluation_interval: 15s # 告警规则评估间隔
# 告警规则加载
rule_files: # 告警规则文件路径
- "/etc/prometheus/alert_rules.yml"
# 抓取目标配置
scrape_configs: # 监控目标定义
- job_name: "node" # 监控组名称
static_configs:
- targets: ["node-exporter:9100"] # 监控本机node-exporter
- job_name: "docker"
static_configs:
- targets: ["cadvisor:8080"] # 监控容器
# 示例:添加其他主机监控(需对应主机部署node-exporter)
- job_name: "host1-node" # 监控其他主机示例
static_configs:
- targets: ["192.168.0.221:9100"] # 修改为host1的实际IP(需确保host1的node_exporter已运行)
# 监控 MySQL Exporter
- job_name: "mysql" # MySQL监控示例(需先部署mysqld_exporter)
scrape_interval: 30s # 降低抓取频率(根据负载调整)
static_configs:
- targets: ["192.168.0.221:9104"]
params:
collect[]: # 指定需要收集的指标组(减少冗余数据)
- standard
- engine_innodb
# scheme: https # 若启用HTTPS
tls_config:
insecure_skip_verify: true # 跳过证书验证(生产环境建议配置CA)
② alert_rules.yml - 告警规则定义
groups:
- name: host-alerts
rules:
- alert: HighCpuUsage
expr: 100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85
for: 5m
labels:
severity: critical
annotations:
summary: "High CPU usage on {{ $labels.instance }}"
③ alertmanager.yml - 告警通知配置
route:
group_by: ['alertname'] # 按告警名称分组
group_wait: 30s # 同一组告警等待时间
group_interval: 5m # 发送新告警间隔
repeat_interval: 4h # 重复发送相同告警间隔
receiver: 'email-notice' # 默认接收器
receivers:
- name: 'email-notice'
email_configs:
- to: 'admin@yourcompany.com' # 修改为实际接收邮箱
from: 'alert@monitor.com'
smarthost: 'smtp.yourcompany.com:587' # 根据邮箱服务商修改
auth_username: 'alert@monitor.com' # 发件邮箱账号
auth_password: 'your-smtp-password' # 邮箱SMTP授权码(非登录密码)
send_resolved: true
④ grafana-provisioning/datasources/prometheus.yml - Grafana数据源预配置
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
url: http://prometheus:9090
access: proxy
isDefault: true
3. 部署前准备
# 创建配置文件目录
mkdir -p /opt/monitor/{grafana-provisioning/dashboards,grafana-provisioning/datasources,grafana-provisioning/alerting,grafana-provisioning/notifiers,grafana-provisioning/plugins}
# 生成配置文件(手动填充上述示例内容)
touch /opt/monitor/docker-compose.yml
touch /opt/monitor/prometheus.yml
touch /opt/monitor/alert_rules.yml
touch /opt/monitor/alertmanager.yml
touch /opt/monitor/grafana-provisioning/datasources/prometheus.yml
# 设置文件权限(防止容器权限问题)
chmod -R 755 /opt/monitor/grafana-provisioning
4. 启动服务
cd /opt/monitor
docker compose up -d # 后台启动
5. 部署后验证
-
检查容器状态:
docker compose ps # 确保所有服务状态为 "Up" docker compose logs #查看全部日志 docker compose logs --no-color | grep -i -E "error|fail|exception|warning|timeout" -
访问服务:
- Grafana:
http://host4-ip:3000(默认账号admin/YourStrongPassword) - Prometheus:
http://host4-ip:9090/targets查看抓取目标状态
- Grafana:
-
导入仪表盘:
- Grafana中导航至
Create > Import,输入仪表盘ID(如1860) - 选择Prometheus数据源
- Grafana中导航至
二、客户端配置
我这里准备在host1:192.168.0.221配置客户端,上面已安装mysql, tomcat
1. 配置Node Exporter(监控主机资源)
在每台客户端主机(host1)创建以下 docker-compose.node.yml 文件:
services:
node-exporter:
image: prom/node-exporter:v1.9.1
container_name: node-exporter
restart: unless-stopped
ports:
- "9100:9100"
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
- /run/udev:/run/udev:ro #获取磁盘设备信息
command:
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
networks:
- app_ry-network
deploy:
resources:
limits:
cpus: '0.2'
memory: 256M
networks:
app_ry-network:
driver: bridge
external: true
启动服务:
docker-compose -f docker-compose.node.yml up -d
检查是否有数据: 192.168.0.221:9100/metrics
2. 配置MySQL Exporter(监控MySQL)
创建 MySQL 监控专用用户
-
登录 MySQL
在 MySQL 所在的主机(host1)上,使用管理员账号登录 MySQL:mysql -u root -p -
创建监控用户并授权
执行以下 SQL 语句,创建exporter用户并授予最小必要权限:CREATE USER 'exporter'@'%' IDENTIFIED BY 'your.secure.password1' WITH MAX_USER_CONNECTIONS 3; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'%'; FLUSH PRIVILEGES; mysql -uexporter -pyour.secure.password1your.secure.password:替换为强密码(需与后续mysqld-exporter配置一致)。MAX_USER_CONNECTIONS 3:限制最大连接数,防止监控占用过多资源。
在MySQL所在主机(host1)创建 docker-compose.mysql-exporter.yml:
创建my.cnf
cat my.cnf
[client]
user = exporter
password = your.secure.password1
host = ry-mysql # 关键:指定 MySQL 容器的主机名
port = 3306 # 可选:显式指定端口
#[client.servers] #可配置多个连接
#user = bar
#password = bar123
services:
mysqld-exporter:
image: prom/mysqld-exporter:v0.17.2
container_name: mysqld-exporter
restart: unless-stopped
ports:
- "9104:9104"
networks:
- app_ry-network #与mysql同一网络
volumes:
- ./my.cnf:/.my.cnf
deploy:
resources:
limits:
cpus: '0.5'
memory: 512M
networks:
app_ry-network:
driver: bridge
external: true # 关键:声明为外部网络
启动服务:
docker-compose -f docker-compose.mysql-exporter.yml up -d
验证: 192.168.0.221:9104/metrics 是否有数据
3. 配置Tomcat JMX Exporter(监控Tomcat)
集成 JMX Exporter 到 Tomcat 容器:
- 创建JMX配置文件
jmx-config.yml:
nano jmx-config.yml
rules:
- pattern: ".*"
- 下载 JMX Exporter 文件
Release 1.3.0 / 2025-05-16 · prometheus/jmx_exporter
- 修改Tomcat的
docker-compose.yml,添加JMX Exporter参数:
services:
ry-tomcat:
image: harbor.host3/ruoyi/ry-tomcat:39
environment:
CATALINA_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=12345 -Dcom.sun.management.jmxremote.rmi.port=12346 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Djava.rmi.server.hostname=192.168.0.221 -javaagent:/jmx/jmx_prometheus_javaagent-1.3.0.jar=9404:/jmx/jmx-config.yml"
volumes:
- ./jmx-config.yml:/jmx/jmx-config.yml # 挂载配置文件
- ./jmx_prometheus_javaagent-1.3.0.jar:/jmx/jmx_prometheus_javaagent-1.3.0.jar # 挂载 Agent
ports:
- "9404:9404" # 新增:暴露 JMX Exporter 的 HTTP 端口
测试连接
192.168.0.221:9404/metrics 搜索应有mysql_up 1
-
确认 Prometheus 抓取配置:
- job_name: "tomcat" static_configs: - targets: ["192.168.0.221:9404"]热加载(推荐):
Prometheus 支持通过 API 热加载配置,无需重启:curl -X POST http://prometheus-host:9090/-/reload curl -X POST http://192.168.0.224:9090/-/reload前提:启动 Prometheus 时需添加
--web.enable-lifecycle参数(已在您的docker-compose.yml中配置)。
| 参数 | 必要性 | 作用 |
|---|---|---|
-Dcom.sun.management.jmxremote | 必要 | 启用 JMX 远程管理功能,无此参数无法通过 JMX 连接。 |
-Dcom.sun.management.jmxremote.port=12345 | 必要 | 指定 JMX 连接的端口,Prometheus 通过此端口访问 JMX 数据。 |
-Dcom.sun.management.jmxremote.rmi.port=12346 | 可选 | 指定 RMI 通信端口,仅在需要远程方法调用(RMI)时使用,通常与 JMX 端口一致可省略。 |
-Dcom.sun.management.jmxremote.ssl=false | 可选 | 禁用 SSL 加密。生产环境建议启用 SSL(设置为 true),测试环境可禁用。 |
-Dcom.sun.management.jmxremote.authenticate=false | 可选 | 禁用认证。生产环境必须启用认证(设置为 true),测试环境可禁用。 |
-Djava.rmi.server.hostname=192.168.0.221 | 必要 | 指定 RMI 通信的主机名,容器化环境中必须设置为宿主机 IP 或可解析的域名。 |
启用 JMX 认证的步骤(生产环境建议配置)
-
生成密码文件:
创建jmxremote.password文件(示例内容):monitor password123 # 用户名和密码 -
设置文件权限:
chmod 600 jmxremote.password # 仅允许所有者读写 -
修改 Tomcat 配置:
environment: CATALINA_OPTS: " ... -Dcom.sun.management.jmxremote.authenticate=true -Dcom.sun.management.jmxremote.password.file=/etc/prometheus/ssl/jmxremote.password" volumes: - ./jmxremote.password:/etc/prometheus/ssl/jmxremote.password
Prometheus 是否需要调整配置?
- 无需调整:JMX Exporter 在 HTTP 模式下会将 JMX 数据转换为 Prometheus 兼容的指标,认证由 JMX Exporter 处理。
- 例外情况:如果直接通过 JMX 协议抓取(非 HTTP 模式),需在 Prometheus 配置中提供凭据。但您当前使用 HTTP 模式,无需额外配置。
4. 配置Prometheus服务端(host4)
修改 prometheus.yml,添加新的抓取目标:
scrape_configs:
# 原有配置...
- job_name: "host1-node" # 监控host1
static_configs:
- targets: ["192.168.0.221:9100"] # 修改为host1的实际IP(需确保host1的node_exporter已运行)
# 监控 MySQL Exporter
- job_name: "mysql" # MySQL监控示例(需先部署mysqld_exporter)
scrape_interval: 30s # 降低抓取频率(根据负载调整)
static_configs:
- targets: ["192.168.0.221:9104"]
params:
collect[]: # 指定需要收集的指标组(减少冗余数据)
- standard
- engine_innodb # 监控 MySQL Exporter
- job_name: "tomcat"
static_configs:
- targets: ["192.168.0.221:9404"]
热加载配置(或重启Prometheus):
curl -X POST http://192.168.0.224:9090/-/reload
前提:启动 Prometheus 时需添加 --web.enable-lifecycle 参数(已在您的 docker-compose.yml 中配置)。
网页上可查看状态
http://192.168.0.224:9090/targets

5. Grafana操作步骤
- 登录Grafana:访问
http://192.168.0.221:3000,使用管理员账号登录。 - 导入仪表板:
- 点击左侧菜单 ➔ Dashboards ➔ New➔ Import。
- 输入仪表板ID(例如:
8919用于Node Exporter,11323用于MySQL)。load

- 选择数据源为
Prometheus,Import。

- 验证数据:
- 在仪表板中选择对应的监控目标,查看指标是否正常显示。

6.更多 Grafana 仪表板模板
- 官方模板库:
Grafana 官方提供了丰富的仪表板模板,涵盖 MySQL、Node Exporter、JVM 等各类监控场景。访问 Grafana Dashboards,搜索关键词如MySQL、Node Exporter、Prometheus,筛选高评分模板。例如:- MySQL 监控:ID
7362(更详细的性能分析)、12826(分库分表监控)。 - 主机监控:ID
1860(Node Exporter 增强版)、11074(多维度资源展示)。 - 容器监控:ID
315(Docker 容器资源使用)。
- MySQL 监控:ID
- 社区推荐模板:
部分模板针对特定场景优化,例如:- 综合监控:ID
10000(集成主机、MySQL、Redis 等指标)。 - 告警关联视图:ID
6663(展示告警与指标的关联性)。
- 综合监控:ID
- 自定义模板:
若现有模板不满足需求,可基于已有模板修改或自行创建。Grafana 支持通过 JSON 文件导入导出,结合 PromQL 灵活定制。
三、配置告警规则
- 配置Alertmanager:
定义告警规则(如CPU>80%),集成邮件、Slack等通知渠道。
1. 安装 Alertmanager
推荐安装位置:与 Prometheus 同Server主机(host4),确保网络互通。
使用 Docker Compose 安装:在现有的 docker-compose.yml 中添加 Alertmanager 服务:
alertmanager:
profiles:
- alertmanager
image: prom/alertmanager:v0.28.1
container_name: alertmanager
restart: unless-stopped
networks:
- monitor-net
ports:
- "9093:9093"
volumes:
- ./alertmanager.yml:/etc/alertmanager/alertmanager.yml:ro
command:
- --config.file=/etc/alertmanager/alertmanager.yml
- --cluster.advertise-address=alertmanager:9093
depends_on:
- prometheus
deploy:
resources:
limits:
cpus: '0.3'
memory: 512M
启动服务
#profiles:
# - alertmanager
#使用profiles需指定名称启动,也可去除同时启动
docker compose --profile alertmanager up -d alertmanager
2. 配置 Alertmanager 邮件通知
步骤 1:创建 alertmanager.yml 文件
qq邮箱示例
https://mail.qq.com/–>登录–>设置–>账号–>POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务
开启服务获取授权码
route:
group_by: ['alertname'] # 按告警名称分组
group_wait: 30s # 同一组告警等待时间
group_interval: 5m # 发送新告警间隔
repeat_interval: 4h # 重复发送相同告警间隔
receiver: 'email-notice' # 默认接收器
retry_interval: 1m # 重试间隔,默认 5m
receivers:
- name: 'email-notice'
email_configs:
- to: 'aaa@qq.com' # 接收告警的邮箱
from: 'xxx@qq.com' # SMTP 服务器地址(根据邮箱服务商修改)
smarthost: 'smtp.qq.com:465' # 根据邮箱服务商修改
auth_username: 'xx@qq.com' # SMTP 登录账号
auth_password: 'xxxxx' # 邮箱SMTP授权码(非登录密码)
send_resolved: true # 发送告警恢复通知
require_tls: false # 禁用 STARTTLS
hello: 'qq.com' # 指定 SMTP 服务器的 HELO 标识
tls_config:
insecure_skip_verify: true # 忽略证书验证(可选)(测试环境)
# server_name: smtp.qq.com # 生产环境建议填写
常见邮箱 SMTP 配置示例:
| 邮箱服务商 | SMTP 地址 | 端口 | 加密方式 |
|---|---|---|---|
| Gmail | smtp.gmail.com | 587 | STARTTLS |
| QQ 邮箱 | smtp.qq.com | 465 | SSL |
| 企业邮箱 | smtp.yourcompany.com | 25 | 无 |
3. 配置 Prometheus 告警规则
步骤 1:创建告警规则文件 alert_rules.yml
groups:
- name: host-alerts
rules:
- alert: HighCpuUsage
expr: 100 - (avg by(instance)(rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85
for: 5m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} CPU 使用率过高"
description: "CPU 使用率持续5分钟超过85%,当前值为 {{ $value }}%"
- alert: LowMemoryAvailable
expr: (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100) < 10
for: 10m
labels:
severity: warning
annotations:
summary: "实例 {{ $labels.instance }} 可用内存不足"
description: "可用内存低于10%,当前剩余 {{ $value | humanize }}%"
- name: mysql-alerts
rules:
- alert: MysqlDown
expr: mysql_up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "MySQL 服务不可用"
description: "MySQL 实例 {{ $labels.instance }} 已宕机超过1分钟"
步骤 2:在 prometheus.yml 中引用告警规则
rule_files:
- "/etc/prometheus/alert_rules.yml" # 容器内路径(需挂载)
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093'] # Alertmanager 服务地址
步骤 3:重启 Prometheus 服务
docker compose restart prometheus
4. 验证告警配置
步骤 1:访问 Prometheus 告警页面
打开 http://192.168.0.224:9090/alerts,检查告警规则是否加载成功,状态是否为正常。

步骤 2:触发测试告警
-
模拟高 CPU 使用率:
stress -c 2 # 在监控的主机上运行(需安装 stress 工具) -
手动停止 MySQL 服务:
docker stop ry-mysql
步骤 3:查看 Alertmanager 界面
访问 http://host4:9093,确认告警是否显示,并检查邮件是否收到通知。


5. 其他告警配置选项
1. 多通知渠道集成
Alertmanager 支持以下通知方式(需在 alertmanager.yml 中配置):
-
Slack:
- name: 'slack-notice' slack_configs: - api_url: 'https://hooks.slack.com/services/XXXX/YYYY/ZZZZ' channel: '#alerts' -
Webhook(对接企业微信、钉钉):
- name: 'webhook-notice' webhook_configs: - url: 'http://webhook-server:5000/alert' -
PagerDuty:
- name: 'pagerduty-notice' pagerduty_configs: - service_key: 'your-pagerduty-key'
2. 告警分组与抑制
-
分组(Grouping):将相似告警合并发送,减少通知噪音。
-
抑制(Inhibition):当某类告警触发时,抑制其他相关告警。
inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['instance']
3. 静默(Silence)
在 Alertmanager 界面中设置临时静默,屏蔽特定时间段或条件的告警。
4.其他告警通知方式(短信/钉钉/企业微信)
若需发送短信,可通过以下方式集成:
1. 通过短信网关 API
receivers:
- name: 'sms-notice'
webhook_configs:
- url: 'http://sms-gateway-api:8080/send'
send_resolved: true
http_config:
basic_auth:
username: 'api-user'
password: 'api-password'
2. 通过钉钉机器人
receivers:
- name: 'dingtalk-notice'
webhook_configs:
- url: 'https://oapi.dingtalk.com/robot/send?access_token=xxxx'
send_resolved: true
3. 通过企业微信
receivers:
- name: 'wecom-notice'
wechat_configs:
- corp_id: 'your-corp-id'
to_party: '2'
agent_id: '1000002'
api_secret: 'your-api-secret'
6.故障排查指南
| 问题现象 | 排查步骤 |
|---|---|
| 告警未触发 | 检查 Prometheus 的 /alerts 页面,确认规则语法正确且表达式返回值符合预期。 |
| 邮件未收到 | 验证 SMTP 配置,检查 Alertmanager 日志 docker logs alertmanager。 |
| Alertmanager 无法连接 Prometheus | 确认 Prometheus 的 alerting 配置中地址正确,网络互通。 |
1. 部署与配置问题
问题1:Prometheus 配置文件语法错误
-
日志错误示例:
level=error ts=2024-03-01T12:00:00Z caller=main.go:123 err="error loading config from \"/etc/prometheus/prometheus.yml\": parsing YAML file: yaml: line 5: did not find expected key" -
解决方案:
使用promtool工具验证配置文件语法:docker exec prometheus promtool check config /etc/prometheus/prometheus.yml修复提示的语法错误(如缩进、冒号缺失)。
问题2:Grafana 数据源配置错误
-
日志错误示例:
t=2024-03-01T12:00:00Z lvl=eror msg="Failed to query Prometheus" error="client_error: client error: 404" -
解决方案:
检查grafana-provisioning/datasources/prometheus.yml的url配置:# 确保地址为 Prometheus 容器名称(容器内通信) url: http://prometheus:9090重启 Grafana 服务:
docker compose restart grafana
问题3:Alertmanager 集群通信失败
-
错误日志:
time=2025-05-26T21:33:45.119Z level=ERROR source=main.go:259 msg="unable to initialize gossip mesh" err="create memberlist: Failed to get final advertise address: Failed to parse advertise address \"alertmanager\"" -
原因:
- 单机部署 Alertmanager 时未禁用集群模式,导致尝试初始化 Gossip 协议失败。
- 容器名
alertmanager无法解析为有效 IP。
-
解决方案:
禁用集群模式:# docker-compose.yml 中 Alertmanager 的配置 services: alertmanager: command: - --config.file=/etc/alertmanager/alertmanager.yml - --cluster.listen-address= # 禁用集群模式
问题一:JMX Exporter 参数格式错误导致 Tomcat 启动失败
-
错误日志:
java.lang.ClassNotFoundException: org.apache.juli.ClassLoaderLogManager -
原因:
CATALINA_OPTS参数未正确使用 YAML 多行语法。- JMX Exporter 的 Agent 路径或配置文件未挂载。
-
解决方案:
修正参数格式和挂载路径:# docker-compose.yml 中 Tomcat 的配置 services: ry-tomcat: environment: CATALINA_OPTS: " -javaagent:/jmx/jmx_prometheus_javaagent-1.3.0.jar=9404:/jmx/jmx-config.yml" volumes: - ./jmx-config.yml:/jmx/jmx-config.yml - ./jmx_prometheus_javaagent-1.3.0.jar:/jmx/jmx_prometheus_javaagent-1.3.0.jar
问题二:Alertmanager TLS 配置冲突
-
错误日志:
level=WARN source=notify.go:866 msg="Notify attempt failed" err="'require_tls' is true but \"smtp.qq.com:465\" does not advertise STARTTLS" -
原因:
- QQ 邮箱的 465 端口使用 SSL 加密,但 Alertmanager 默认要求 STARTTLS。
-
解决方案:
显式禁用 TLS 并指定 SSL 端口:# alertmanager.yml 中的 SMTP 配置 email_configs: - smarthost: 'smtp.qq.com:465' require_tls: false # 禁用 STARTTLS
2. 网络与连接问题
问题3:Prometheus 无法连接 Exporter(Targets 显示 DOWN)
-
日志错误示例:
level=error ts=2024-03-01T12:00:00Z caller=scrape.go:1320 msg="Error scraping target" target="http://192.168.0.221:9100/metrics" err="Get \"http://192.168.0.221:9100/metrics\": context deadline exceeded" -
解决方案:
-
检查 Exporter 端口是否暴露:
docker ps --filter "name=node-exporter" --format "{{.Ports}}" -
测试网络连通性:
curl http://192.168.0.221:9100/metrics # 在 Prometheus 容器内执行 -
确保 Docker 网络配置一致(使用同一自定义网络)。
-
问题4:Alertmanager 无法接收 Prometheus 告警
-
日志错误示例(Prometheus 日志):
level=error ts=2024-03-01T12:00:00Z caller=notifier.go:256 component=notifier alertmanager=http://alertmanager:9093/api/v2/alerts count=1 msg="Error sending alert" err="Post \"http://alertmanager:9093/api/v2/alerts\": dial tcp: lookup alertmanager on 127.0.0.11:53: no such host" -
解决方案:
在prometheus.yml中确认 Alertmanager 地址正确:alerting: alertmanagers: - static_configs: - targets: ['alertmanager:9093'] # 使用容器名称而非IP确保
docker-compose.yml中 Alertmanager 与 Prometheus 共享同一网络。
3. 数据采集与指标问题
问题5:Exporter 未暴露指标(/metrics 端点无数据)
-
日志错误示例(Node Exporter 日志):
level=error ts=2024-03-01T12:00:00Z caller=collector.go:123 msg="collector failed" name=meminfo err="could not get meminfo: open /host/proc/meminfo: no such file or directory" -
解决方案:
检查 Exporter 的挂载路径是否正确(如 Node Exporter):volumes: - /proc:/host/proc:ro # 必须挂载宿主机 /proc - /sys:/host/sys:ro重启 Exporter 并验证:
curl http://localhost:9100/metrics | grep "node_"
问题6:Grafana 仪表盘显示 “No Data”
-
日志错误示例(Grafana 日志):
t=2024-03-01T12:00:00Z lvl=eror msg="Query error" error="invalid parameter 'query': parse error at char 15: syntax error: unexpected IDENT, expecting string or number" -
解决方案:
-
检查 PromQL 语法(如
node_memory_MemAvailable_bytes是否拼写正确)。 -
确认 Prometheus 中存在对应指标:
curl http://prometheus:9090/api/v1/label/__name__/values | jq # 列出所有指标名
-
4. 告警配置与通知问题
问题7:告警规则未触发(Prometheus 无告警)
-
日志错误示例(Prometheus 日志):
level=warn ts=2024-03-01T12:00:00Z caller=manager.go:654 component="rule manager" msg="Evaluating rule failed" rule="alert=HighCpuUsage" err="invalid expression type \"\" for range query, must be Scalar or instant Vector" -
解决方案:
检查告警规则的expr表达式是否为合法 PromQL(需返回瞬时向量):# 错误示例(缺少聚合函数) expr: node_cpu_seconds_total{mode="idle"} > 85 # 正确示例(使用 avg 聚合) expr: 100 - (avg by(instance)(rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100 > 85
问题8:Alertmanager 发送邮件失败
-
日志错误示例(Alertmanager 日志):
level=error ts=2024-03-01T12:00:00Z caller=notify.go:674 component=dispatcher msg="Error on notify" err="*email.loginAuth auth: 550 User has no permission" -
解决方案:
检查alertmanager.yml的 SMTP 配置(以 QQ 邮箱为例):receivers: - name: 'email-notice' email_configs: - to: 'user@qq.com' from: 'sender@qq.com' smarthost: 'smtp.qq.com:465' auth_username: 'sender@qq.com' auth_password: 'xxxxx' # 使用 SMTP 授权码,非登录密码 require_tls: false # 禁用 STARTTLS tls_config: insecure_skip_verify: true # 测试环境跳过证书验证确保邮箱已开启 SMTP 服务并生成授权码。
5. 权限与安全设置问题
问题9:容器因权限问题无法启动
-
日志错误示例(cAdvisor 日志):
F0301 12:00:00.000000 1 cadvisor.go:175] Failed to start container manager: inotify_add_watch /sys/fs/cgroup/cpuacct,cpu: permission denied -
解决方案:
在docker-compose.yml中为 cAdvisor 添加特权模式:cadvisor: privileged: true # 必须开启特权模式 volumes: - /:/rootfs:ro,rslave - /var/run:/var/run:ro,rslave
问题10:Grafana 登录失败(权限不足)
-
日志错误示例:
t=2024-03-01T12:00:00Z lvl=eror msg="Failed to login" error="invalid username or password" -
解决方案:
重置管理员密码(通过环境变量或配置文件):environment: - GF_SECURITY_ADMIN_PASSWORD=NewPassword123 # 在 docker-compose.yml 中设置重启 Grafana 后使用新密码登录。
问题一:MySQL 用户权限不足
-
错误日志:
time=2025-05-26T19:02:01.678Z level=ERROR source=exporter.go:131 msg="Error opening connection to database" err="Access denied for user 'exporter'@'%'" -
原因:
exporter用户缺少PROCESS、REPLICATION CLIENT、SELECT权限。
-
解决方案:
授予权限并刷新:-- 在 MySQL 中执行 GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'%'; FLUSH PRIVILEGES;
6. 容器化环境中的特殊问题
问题11:Docker 容器间网络不通
-
日志错误示例(Prometheus Targets 页面显示
Connection refused)。 -
解决方案:
确保所有服务使用同一 Docker 网络:# docker-compose.yml networks: monitor-net: driver: bridge services: prometheus: networks: - monitor-net grafana: networks: - monitor-net检查容器 IP:
docker network inspect monitor-net
问题12:容器挂载卷权限错误
-
日志错误示例(Grafana 日志):
t=2024-03-01T12:00:00Z lvl=eror msg="Failed to provision plugins" error="mkdir /var/lib/grafana/plugins: permission denied" -
解决方案:
调整宿主机目录权限(确保容器用户可读写):chmod -R 755 /opt/monitor/grafana-provisioning # 宿主目录权限或在
docker-compose.yml中指定用户:grafana: user: "472:472" # Grafana 默认用户ID
7.完整实例文档
global:
# The smarthost and SMTP sender used for mail notifications.
smtp_smarthost: 'localhost:25'
smtp_from: 'alertmanager@example.org'
# The root route on which each incoming alert enters.
route:
# The root route must not have any matchers as it is the entry point for
# all alerts. It needs to have a receiver configured so alerts that do not
# match any of the sub-routes are sent to someone.
receiver: 'team-X-mails'
# The labels by which incoming alerts are grouped together. For example,
# multiple alerts coming in for cluster=A and alertname=LatencyHigh would
# be batched into a single group.
#
# To aggregate by all possible labels use '...' as the sole label name.
# This effectively disables aggregation entirely, passing through all
# alerts as-is. This is unlikely to be what you want, unless you have
# a very low alert volume or your upstream notification system performs
# its own grouping. Example: group_by: [...]
group_by: ['alertname', 'cluster']
# When a new group of alerts is created by an incoming alert, wait at
# least 'group_wait' to send the initial notification.
# This way ensures that you get multiple alerts for the same group that start
# firing shortly after another are batched together on the first
# notification.
group_wait: 30s
# When the first notification was sent, wait 'group_interval' to send a batch
# of new alerts that started firing for that group.
group_interval: 5m
# If an alert has successfully been sent, wait 'repeat_interval' to
# resend them.
repeat_interval: 3h
# All the above attributes are inherited by all child routes and can
# overwritten on each.
# The child route trees.
routes:
# This route performs a regular expression match on alert labels to
# catch alerts that are related to a list of services.
- matchers:
- service=~"^(foo1|foo2|baz)$"
receiver: team-X-mails
# The service has a sub-route for critical alerts, any alerts
# that do not match, i.e. severity != critical, fall-back to the
# parent node and are sent to 'team-X-mails'
routes:
- matchers:
- severity="critical"
receiver: team-X-pager
- matchers:
- service="files"
receiver: team-Y-mails
routes:
- matchers:
- severity="critical"
receiver: team-Y-pager
# This route handles all alerts coming from a database service. If there's
# no team to handle it, it defaults to the DB team.
- matchers:
- service="database"
receiver: team-DB-pager
# Also group alerts by affected database.
group_by: [alertname, cluster, database]
routes:
- matchers:
- owner="team-X"
receiver: team-X-pager
- matchers:
- owner="team-Y"
receiver: team-Y-pager
# Inhibition rules allow to mute a set of alerts given that another alert is
# firing.
# We use this to mute any warning-level notifications if the same alert is
# already critical.
inhibit_rules:
- source_matchers:
- severity="critical"
target_matchers:
- severity="warning"
# Apply inhibition if the alertname is the same.
# CAUTION:
# If all label names listed in `equal` are missing
# from both the source and target alerts,
# the inhibition rule will apply!
equal: ['alertname']
receivers:
- name: 'team-X-mails'
email_configs:
- to: 'team-X+alerts@example.org, team-Y+alerts@example.org'
- name: 'team-X-pager'
email_configs:
- to: 'team-X+alerts-critical@example.org'
pagerduty_configs:
- routing_key: <team-X-key>
- name: 'team-Y-mails'
email_configs:
- to: 'team-Y+alerts@example.org'
- name: 'team-Y-pager'
pagerduty_configs:
- routing_key: <team-Y-key>
- name: 'team-DB-pager'
pagerduty_configs:
- routing_key: <team-DB-key>
四、配置 HTTPS 及认证授权(nginx)
推荐 Prometheus 使用 HTTP,TLS 交由 NGINX 的主要原因:
✅ 1:职责分离,简化配置和维护
| 组件 | 主要职责 |
|---|---|
| Prometheus | 专注于数据抓取、存储与查询 |
| NGINX | 专注于反向代理、TLS 终端、访问控制 |
让 NGINX 负责 TLS 意味着你只需配置一次 HTTPS,不管后端是 Prometheus、Grafana 还是其他服务,都可以共用这套 TLS 配置。这符合**“单一职责原则”**。
✅ 2:HTTPS 配置在 Prometheus 中更复杂、可维护性差
如果你坚持在 Prometheus 中启用 TLS,你需要:
- 生成/维护一份有效证书(哪怕是自签名)
- 配置
web.config.file,并将证书和私钥挂载进去 - 每次证书更新要重启容器或 reload Prometheus
而在 NGINX 中,TLS 是它的第一职责,证书热重载也更成熟。
✅ 3:Prometheus 并非为生产 HTTPS 暴露而优化
Prometheus 的官方文档中对 HTTPS 支持是 “experimental(实验性)”,其主要目标是供后端服务抓取数据,而不是作为前端暴露 HTTPS 服务。反而用反向代理(如 NGINX 或 Traefik)是更常见的部署方式。
✅4:Docker 容器内部使用 HTTPS 是性能浪费
容器之间通信时,TLS 加密并没有太多意义(因为已经在同一个网络或通过 Kubernetes 网络策略隔离),使用 HTTPS 会带来额外的:
- CPU 消耗(TLS 握手和加解密)
- 连接复杂度
- 不必要的证书信任验证问题(如自签名证书总是出 warning)
✅ 5:统一入口便于做访问控制和认证
你可以在 NGINX 统一做这些事情:
- 基于路径的认证(例如 Grafana 加认证,Prometheus 只读)
- IP 限制、速率限制、防火墙策略
- OAuth 或 LDAP 等集成
这让整个系统更加安全、集中控制。
如果你有特殊安全需求(比如 Prometheus 暴露在公网且不能使用 NGINX),那确实可以考虑启用 Prometheus 自带的 TLS,但默认建议就是走 NGINX。
4.1.自定义 Host + 自签名证书的(测试环境)
#域名映射
# Linux
echo "192.168.0.224 monitor.host4" | sudo tee -a /etc/hosts
Windows:
-
C:\Windows\system32\drivers\etc\hosts -
添加一行
192.168.0.224 monitor.host4
#证书存放目录
mkdir -p /opt/monitor/ssl && cd /opt/monitor/ssl
# 生成证书和私钥
openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -days 365 -nodes \
-subj "/CN=monitor.host4" \
-addext "subjectAltName=DNS:monitor.host4,IP:192.168.0.224"
sudo chmod 644 /opt/monitor/ssl/*.pem
# 生成的 cert.pem 和 key.pem 用于后续配置
1. 修改配置文件
grafana-provisioning/datasources/prometheus.yml
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
url: http://prometheus:9090/prometheus
access: proxy
isDefault: true
docker-compose.yml
# Prometheus
prometheus:
command:
- --web.route-prefix=/prometheus #
- --web.external-url=/prometheus #
# Grafana
grafana:
environment:
- GF_SERVER_ROOT_URL=https://monitor.host4/grafana/
- GF_SERVER_SERVE_FROM_SUB_PATH=true
| 参数/变量 | 组件 | 含义 |
|---|---|---|
--web.route-prefix=/prometheus | Prometheus | 指定 Prometheus 在 HTTP 服务端挂载的路径前缀。 所有内置页面和 API(如 /api/v1/query、/graph)都将自动变为 /prometheus/api/v1/...、/prometheus/graph。 |
--web.external-url=/prometheus | Prometheus | 告诉 Prometheus 当它生成跳转链接或 HTML 静态资源 URL 时,以此路径为根。 通常与 --web.route-prefix 配合使用,确保它发出的 <a href>、<script src> 正确指向子路径。 |
GF_SERVER_ROOT_URL=https://monitor.host4/grafana/ | Grafana | 配置 Grafana 自身生成的所有绝对跳转和资源链接的根 URL。 例如登录后重定向、仪表盘中的静态文件等,都以这个地址开头。末尾的 / 很关键,要与 NGINX 的子路径对应。 |
GF_SERVER_SERVE_FROM_SUB_PATH=true | Grafana | 告诉 Grafana “我部署在子路径下,请在内部路由中自动加上你在 GF_SERVER_ROOT_URL 里指定的那个子路径”。 只有开启后,Grafana 才会识别并正确处理 /grafana/... 这类 URI。 |
Prometheus
- 外层 NGINX 反代到
/prometheus/,然后转发到容器内部的同一路径。 - Prometheus 内部页面、API 都挂到这个子路径下,生成链接也会带上该前缀。
Grafana
- 外层 NGINX 反代到
/grafana/,容器内部同样映射到/grafana/。 GF_SERVER_ROOT_URL定义了用户在浏览器看到的根地址;GF_SERVER_SERVE_FROM_SUB_PATH=true让 Grafana 的内部路由和静态文件请求都带上子路径。
2. 安装 Nginx
宿主机直接安装(推荐)
sudo apt install -y nginx
-
优点
- 证书自动续期(Certbot + Cron)。
- 性能更优,适合生产环境。
-
缺点:
- 依赖宿主机环境,可能与其他服务冲突。
通过Docker 部署 Nginx
# docker-compose.yml
services:
nginx:
image: nginx:latest
ports:
- "80:80"
- "443:443"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
- /opt/monitor/ssl/cert.pem:/etc/nginx/cert.pem
- /opt/monitor/ssl/key.pem:/etc/nginx/key.pem
- /etc/letsencrypt:/etc/letsencrypt:ro # 若用 Let's Encrypt
networks:
- monitor-net
-
优点:
- 环境隔离,配置独立。
- 与 Prometheus/Grafana 容器网络互通。
-
缺点:
- 证书续期需手动处理(需挂载 Certbot 容器或宿主机路径)。
- 性能略低于宿主机直接安装。
3. 配置 Nginx HTTPS 反向代理
创建配置文件 /etc/nginx/sites-available/monitor.conf:
nano /etc/nginx/sites-available/monitor.conf
server {
listen 80;
server_name monitor.host4;
return 301 https://$host$request_uri;
}
server {
listen 443 ssl;
server_name monitor.host4;
ssl_certificate /opt/monitor/ssl/cert.pem;
ssl_certificate_key /opt/monitor/ssl/key.pem;
# 强制 TLS 1.2+ 并优化加密套件
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256;
ssl_prefer_server_ciphers on;
# /grafana 不带斜杠时补全
location = /grafana {
return 301 /grafana/;
}
# 根路径直接跳到 /grafana/
location = / {
return 302 /grafana/;
}
# Grafana 子路径代理——保持后端同样的 /grafana/ 前缀
location /grafana/ {
# 直接把 /grafana/… → 后端的 /grafana/…
proxy_pass http://192.168.0.224:3000/grafana/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# WebSocket 支持
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
# 自签证书时可关验证
proxy_ssl_verify off;
# 不做任何 Location 改写
proxy_redirect off;
}
# Prometheus 代理配置
location /prometheus/ {
proxy_pass http://192.168.0.224:9090/prometheus/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
# 自签证书时可关验证
proxy_ssl_verify off;
proxy_redirect off;
}
}
3. 启用配置并重启 Nginx
sudo ln -s /etc/nginx/sites-available/monitor.conf /etc/nginx/sites-enabled/
sudo nginx -t && sudo systemctl restart nginx
4.浏览器导入证书
- 导入证书:
- 下载
cert.pem到本地。 - Edge 浏览器:设置 → 隐私 →安全性 → 管理证书 → 导入(右下角选择所有文件) → 选择
cert.pem。 - 选择
受信任的根证书颁发机构
- 下载
- 访问测试:
- 输入
https://monitor.host4,忽略安全警告(或信任证书)。
- 输入

4.2.有域名并配置公网解析
1. 使用 Let’s Encrypt 证书(必须提供合法域名)
# 1. 安装 Certbot
sudo apt update
sudo apt install -y snapd
sudo snap install core
sudo snap install --classic certbot
sudo ln -s /snap/bin/certbot /usr/bin/certbot
# 2. 申请证书(需替换为你的域名)
sudo certbot --nginx \
-d monitor.host4 \
--agree-tos \
--redirect \
--no-eff-email \
-m your-email@example.com
#验证与续期
sudo certbot renew --dry-run
#如果没有报错,系统会自动在到期前续期,并在续期后自动重载 NGINX(Certbot 会安装好相应的 systemd / cron 钩子)。
--nginx:Certbot 会自动检测你的 NGINX 配置并插入新的 ssl_certificate/ssl_certificate_key 指令。
-d monitor.host4:确保 DNS 已经把 monitor.host4 指向你的服务器公网 IP。
--redirect:自动把 HTTP 跳到 HTTPS。
-m:你注册的邮箱,会在续期失败时给你警告。
2. 强化 NGINX 安全头
在你的 server { … } 块(listen 443)内,添加:
# HSTS:强制浏览器只用 HTTPS,180 天
add_header Strict-Transport-Security "max-age=15552000; includeSubDomains; preload" always;
# 防点击劫持
add_header X-Frame-Options "SAMEORIGIN" always;
# 防止 MIME 类型嗅探
add_header X-Content-Type-Options "nosniff" always;
# 防止跨站脚本
add_header X-XSS-Protection "1; mode=block" always;
# 引用来源策略
add_header Referrer-Policy "no-referrer-when-downgrade" always;
保存后:
sudo nginx -t && sudo systemctl reload nginx
3. 访问控制与认证
3.1 对 Grafana 启用 Basic Auth(可选二次认证)
在 location /grafana/ { … } 前面添加一段:
auth_basic "Monitoring";
auth_basic_user_file /etc/nginx/.grafana_htpasswd;
生成密码文件(Ubuntu 自带 apache2-utils):
sudo apt install -y apache2-utils
sudo htpasswd -c /etc/nginx/.grafana_htpasswd admin
# 系统提示输入密码
然后 reload NGINX。
3.2 Prometheus 层面 IP 白名单
在 location /prometheus/ { … } 中加入:
allow 10.0.0.0/8; # 允许内网
allow 192.168.0.0/16; # 允许局域网
deny all; # 其它一律拒绝
4. 日志集中与监控
4.1 NGINX 日志格式
在 http { … } 中定义:
log_format monitor '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" '
'rt=$request_time ua="$upstream_addr" us="$upstream_status" ut="$upstream_response_time"';
access_log /var/log/nginx/monitor-access.log monitor;
reload NGINX。
4.2 收集到集中系统
- 如果用 ELK/EFK/Loki,请在日志集中系统里配置对应的 Filebeat/Promtail 采集
/var/log/nginx/monitor-access.log,并做字段解析。 - 设置关键 URL(
/grafana/login、/prometheus/query)的 5xx/401/429 报警。
5. 服务自身监控与告警
5.1 安装 NGINX Exporter
在 Prometheus 下加入 NGINX Exporter(Docker 示例):
services:
nginx-exporter:
image: nginx/nginx-prometheus-exporter:0.13.0
ports:
- "9113:9113"
env:
- NGINX_STATUS_URL=http://host.docker.internal/nginx_status
并在主 NGINX 加入 stub_status:
location /nginx_status {
stub_status on;
allow 127.0.0.1;
deny all;
}
5.2 在 Prometheus 抓取
- job_name: 'nginx'
static_configs:
- targets: ['nginx-exporter:9113']
5.3 告警示例
在 alert_rules.yml 中加入:
groups:
- name: nginx_alerts
rules:
- alert: NginxHigh5xxRate
expr: rate(nginx_http_requests_total{status=~"5.."}[5m]) > 0.1
for: 5m
labels:
severity: critical
annotations:
summary: "High HTTP 5xx rate on NGINX"
6. 备份与恢复
6.1 Grafana Dashboards
docker exec grafana grafana-cli dashboards export-all --output /var/lib/grafana/dashboards-backup.json
定时把 /var/lib/grafana/dashboards-backup.json 同步到备份存储。
6.2 Prometheus TSDB 快照
curl -XPOST http://localhost:9090/api/v1/admin/tsdb/snapshot
# 会在 data/snapshots 目录生成快照,定时拷贝到远程存储
7. 自动化与 CI/CD
- 把 NGINX 配置、Docker Compose 文件 放到 Git 仓库;
- 使用 GitLab CI / GitHub Actions 在合并后自动执行 lint 检查 (
nginx -t、docker-compose config)、推送到测试环境、通过 Smoke Test 再部署到生产。 - 版本控制:打标签、打版本包;部署时记录变更日志。
最终验证清单
- 浏览器打开
https://monitor.host4/→ 自动跳/grafana/或/prometheus/,页面无 Mixed‑Content 警告。 - 查看浏览器开发者工具:所有资源都走 HTTPS。
curl -I https://monitor.host4/grafana/- 302 →
/grafana/login - 包含
Strict-Transport-Security头。
- 302 →
- Prometheus 路径、Grafana 路径都做了访问认证与 IP/Basic Auth 控制。
- 日志被正确收集到集中系统,且已有告警规则生效。
- 证书续期脚本通过
certbot renew --dry-run。 - 定时备份脚本落地、可恢复。



![[嵌入式实验]实验二:LED控制](https://i-blog.csdnimg.cn/direct/1c142b5933e6454bb7da895a35e883f1.png)