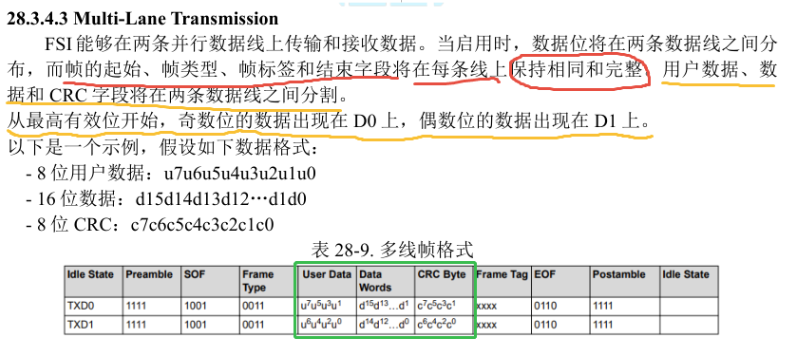
很多程序员都有这样的经历:刷掘金、看文章、找灵感、追热点。但你有没有想过,有一天让“爬虫”代替你去浏览这些内容?自动提取标题、作者、点赞数、评论数,一键生成你的专属“技术热点日报”。
今天我们就用 Trae IDE + PyQt5 来完成这样一个实用而不复杂的小项目:一个图形化的“掘金首页信息爬取器”。它不仅能自动抓取掘金首页的文章信息,还能在桌面界面中整洁地展示数据,为你节省大量筛选时间。
而 Trae IDE 的低门槛、多插件、轻后端特性,会让这件事变得非常简单。
项目目标:做一款你看得见的“网页爬虫”
我们要做的不是命令行下冷冰冰的“爬虫脚本”,而是一个有 GUI 界面的小工具,打开软件后,点击一个按钮,它就能帮你把掘金首页的文章都“搬”过来,像新闻列表一样列出来。
具体来说,我们想要实现这些功能:
-
一键采集掘金首页推荐文章列表
-
抽取标题、作者、点赞数、评论数、发布时间
-
显示在桌面窗口中,可滚动查看
-
可以刷新、导出为本地 Markdown 或 JSON
-
可选择“热门排序”或“最新发布”排序方式(高级功能)
同时我们不追求复杂的后台部署,也不想搭配浏览器环境 —— 纯 Python、纯桌面化、纯原生体验。使用 Trae IDE 的话,这一切将变得非常自然。
技术栈分析:PyQt5 + requests + Trae 的完美组合
为什么用 PyQt5?
PyQt5 是一个非常成熟的 GUI 框架,能够做出现代感强、用户体验不错的桌面应用。它既可以做简单的按钮窗口,也能做出复杂的数据展示表格。
在这个项目中,我们用 PyQt5 来实现以下界面组件:
-
输入框(可设置采集的页数或筛选条件)
-
按钮(“开始采集”、“刷新”、“导出”等)
-
表格视图(展示爬取下来的文章数据)
-
滚动区域(查看更多内容时保持界面流畅)
相比 Tkinter,PyQt5 的可扩展性和美观度更好;而对比 Electron,它又更轻量级,更适合做这种“数据爬取 + 信息展示”的小工具。
网络爬取部分
掘金首页的数据,大多是动态加载的,页面结构基于 Vue 渲染,直接用 requests 抓 HTML 是抓不到完整数据的。不过,掘金作为一个开放社区,推荐内容其实来自一个公开的接口(比如 https://api.juejin.cn/content_api/v1/article/recommend_all_feed 之类),我们可以直接模拟 POST 请求获取数据 JSON。
在 Trae IDE 里,借助原生 Python 脚本支持,我们可以轻松使用 requests 库来模拟网络请求、处理 JSON 响应,并提取出文章内容。
话不多说,上教程。
首先,我们先创建一个“网络爬虫”的只智能体,并简要的描述其角色,功能等等;
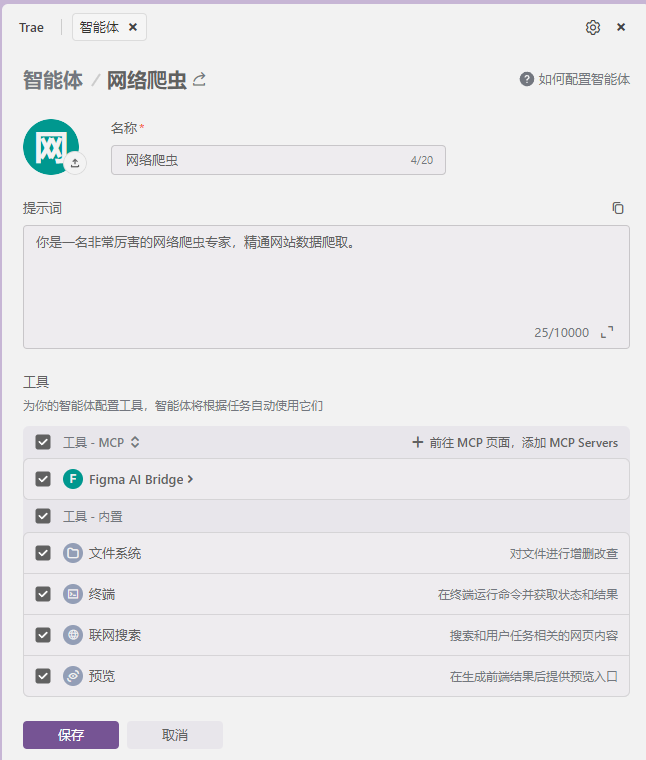
添加图片注释,不超过 140 字(可选)
然后再Trae的对话框中@我们创建的智能体,并输入需求,然后点击发送即可。
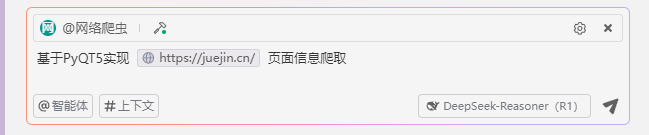
添加图片注释,不超过 140 字(可选)
接下来,Trae会根据需求,进行思考和任务自动实现。
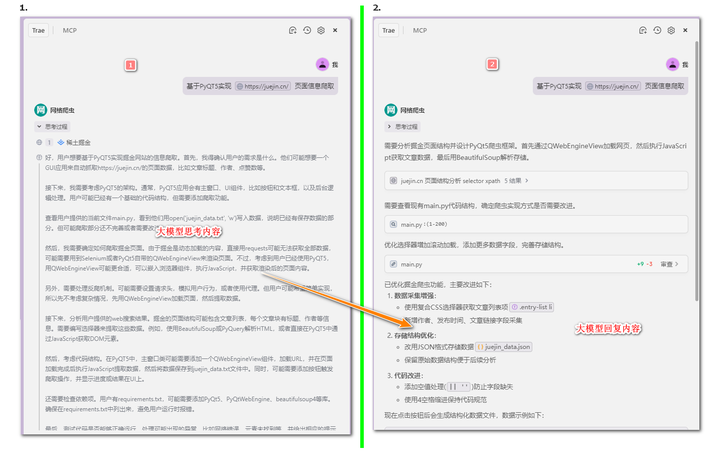
添加图片注释,不超过 140 字(可选)
2-3分钟后,我们就可以难道结果;运行程序,看一下效果。
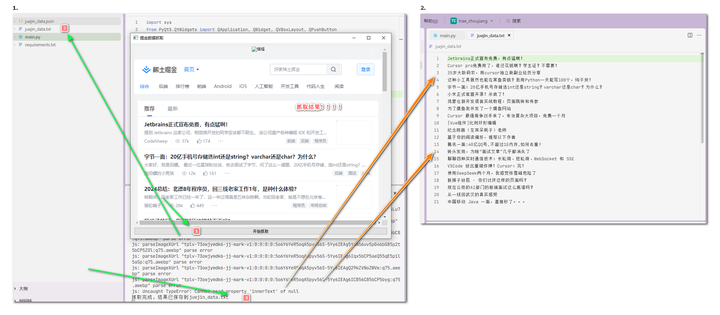
添加图片注释,不超过 140 字(可选)
功能代码块:
import sys
from PyQt5.QtWidgets import QApplication, QWidget, QVBoxLayout, QPushButton
from PyQt5.QtWebEngineWidgets import QWebEngineView
from PyQt5.QtCore import QUrl
class JuejinCrawler(QWidget):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
self.setWindowTitle('掘金数据抓取')
self.setGeometry(300, 300, 800, 600)
layout = QVBoxLayout()
self.browser = QWebEngineView()
self.btn = QPushButton('开始抓取', self)
self.btn.clicked.connect(self.start_crawl)
layout.addWidget(self.browser)
layout.addWidget(self.btn)
self.setLayout(layout)
def start_crawl(self):
self.browser.load(QUrl('https://juejin.cn/'))
self.browser.loadFinished.connect(self.handle_load_finished)
def handle_load_finished(self):
self.browser.page().runJavaScript(
"""
Array.from(document.querySelectorAll('.entry-list li')).map(item => ({
title: item.querySelector('.title').innerText,
author: item.querySelector('.username').innerText,
time: item.querySelector('.time')?.innerText || '',
link: item.querySelector('a')?.href || ''
}));
""",
self.save_results
)
def save_results(self, results):
import json
with open('juejin_data.json', 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=False, indent=2)
print('抓取完成,结果已保存到juejin_data.txt')
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = JuejinCrawler()
ex.show()
sys.exit(app.exec_())我们常说“编程改变世界”,但其实,哪怕只是写一个能帮自己高效获取技术文章的小工具,也是一种用代码改变生活的方式。
在这个项目中,我们用 PyQt5 打造出一个小而美的爬虫工具,借助 Trae IDE 的模块化、可视化支持,让整个开发过程变得顺畅而愉快。