通过网盘分享的文件:资料
链接: https://pan.baidu.com/s/1siOrGmM4n-m3jv95OCea9g?pwd=4jir 提取码: 4jir
1. 引言
1.1 选题背景
在影视内容消费升级背景下,豆瓣电视剧榜单作为国内最具影响力的影视评价体系,其数据价值体现在:
行业参考性:评分分布反映观众审美趋势
商业洞察:主演/导演合作网络揭示行业资源流向
用户研究:影评情感分析挖掘观影偏好特征
本项目针对豆瓣电视剧榜单开展全量数据采集(目标覆盖Top600剧集),构建从数据采集到智能分析的完整技术栈。
1.2 项目目标
数据采集范围:爬取豆瓣电视剧全部600(100页×25条/页),包含片名、评分、经典台词、导演/主演、年份等信息。
存储规模:设计Elasticsearch索引存储结构,支持百万级数据量扩展。
实际应用场景:
影视推荐系统数据源。
剧评分析与舆情监控。
电视剧行业趋势研究。
2. 项目概述
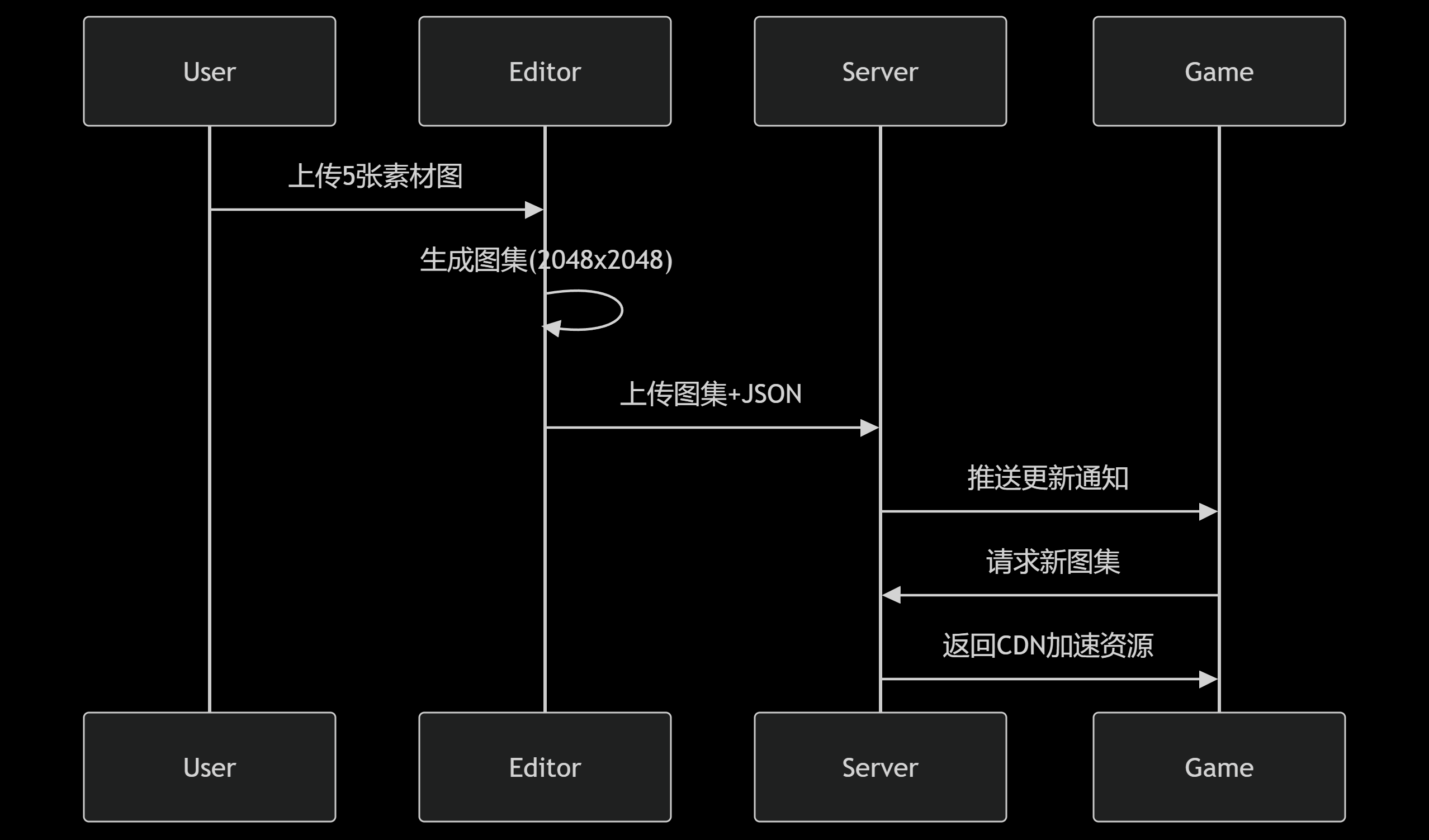
2.1 系统架构设计
graph TD
A[爬虫模块] --> B{动态内容解析}
B --> C[智能请求调度]
C --> D[代理池管理]
D --> E[Elasticsearch存储]
E --> F[影视知识图谱]
F --> G[可视化分析平台]
H[反爬检测] -->|实时监控| C
I[数据清洗] -->|ETL流程| E
2.2 技术选型
爬虫框架:Python Requests + BeautifulSoup(多模式解析)。
存储引擎:Elasticsearch 6.8.23(分布式检索)。
部署环境:Docker容器化部署(爬虫/ES集群分离)。
2.3 项目环境搭建
2.3.1 基础环境准备
Window软件 Visual Studio Code 1.98.2
系统版本 CentOS 7.9 x86_64
软件版本
Python 3.12.10
Elasticsearch 8.15.0
Docker 20.10.17
Kibana 8.15.0
2.3.2 爬虫环境配置
Linux服务器配置(安装)
pip install pydevd-pycharm
远程Python调试
2.3.3 Docker安装ES连接Kibana
services:
elasticsearch:
image: elasticsearch:8.15.0
restart: unless-stopped
container_name: elasticsearch
ports:
- 9200:9200
environment:
- ES_JAVA_OPTS=-Xms512m -Xmx1024m
- discovery.type=single-node
- network.host=0.0.0.0 # 明确绑定到所有
- xpack.security.enabled=false # 关键修改:禁用安全功能
- xpack.security.http.ssl.enabled=false
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- esdata:/usr/share/elasticsearch/data
kibana:
image: kibana:8.15.0
restart: unless-stopped
container_name: kibana
ports:
- 5601:5601
environment:
- SERVER_NAME=kibana
- ELASTICSEARCH_URL=http://elasticsearch:9200
depends_on:
- elasticsearch
volumes:
esdata:
启动容器
访问http://10.1.1.111:5601出现网页则连接成功
安装IK插件
# 1. 进入容器
docker exec -it elasticsearch /bin/bash
# 2. 手动下载插件(若容器内无 wget,需先安装)
apt-get update && apt-get install -y wget
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.15.0/elasticsearch-analysis-ik-8.15.0.zip
# 3. 安装插件(使用本地文件路径)
bin/elasticsearch-plugin install file://$(pwd)/elasticsearch-analysis-ik-8.15.0.zip
# 4. 退出容器并重启
exit
docker restart elasticsearch
如果出现报错可以选择安装其他分词器
官方中文分词器:Smart Chinese Analysis
# 进入 Elasticsearch 容器
docker exec -it elasticsearch /bin/bash
# 安装插件(版本需与 Elasticsearch 严格匹配)
bin/elasticsearch-plugin install analysis-smartcn
# 重启容器
exit
docker restart elasticsearch
# 验证安装
curl -XGET 'localhost:9200/_cat/plugins?v'

测试分词
curl -X POST "localhost:9200/_analyze" -H 'Content-Type: application/json' -d'
{
"analyzer": "smartcn",
"text": "肖申克的救赎"
}'

2.3.4 vscode依赖服务安装
安装python编译依赖
安装python3.12.10
自行选择安装方式

在vscode中手动指定python解释器
打开 VSCode 的命令面板(Ctrl + Shift + P 或 Cmd + Shift + P)。
输入 “Python: Select Interpreter”。

选择解释器
安装脚本依赖的模块
pip install requests
pip install pandas
pip install beautifulsoup4
pip install urllib3
pip install elasticsearch
编写代码
这个JSON文件是Web开发中管理浏览器标识的核心配置文件,通过结构化存储可显著提升多环境适配能力和反爬虫策略的灵活性。
{
"browsers": {
"chrome": {
"desktop": [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
]
}
}
}
Vscode里面的运行效果
3. 核心模块设计与实现
3.1 爬虫模块
3.1.1 界面设计与实现
配置界面:通过类构造函数参数实现配置化设计,支持动态设置
def __init__(self, max_pages: int = 10, use_proxy: bool = False, ..., analyzer: str = "smartcn")
爬取页数控制(max_pages)
代理配置(use_proxy + 代理池)
存储配置(输出文件/ES地址/分词器类型)
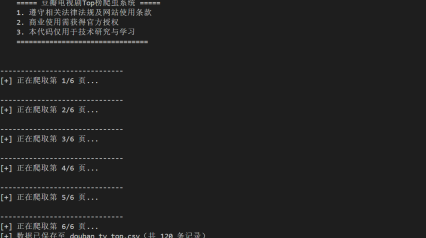
运行交互:主程序入口提供法律声明和状态提示:
if __name__ == "__main__":
print("""
===== 豆瓣电视剧Top榜爬虫系统 =====
1. 遵守相关法律法规及网站使用条款
2. 商业使用需获得官方授权
3. 本代码仅用于技术研究与学习
================================
""")
# Elasticsearch配置
es = Elasticsearch(["http://localhost:9200"])
INDEX_NAME = "douban_tvshows"
3.1.2 类设计与实现
核心类结构
class DoubanTVSpider:
def __init__(self): # 请求配置
self.session = requests.Session()
self.headers = self._build_headers()
# 存储配置
self.es_client = Elasticsearch() self.csv_writer = CSVWriter()
# 反爬模块
self.proxy_pool = ProxyPool()
self.retry_strategy = RetryStrategy()
def _build_headers(self):
return {
"User-Agent": "Mozilla/5.0 ...",
"Accept-Encoding": "gzip, deflate, br",
"Cookie": "bid=..." # 动态Cookie管理
}
3.1.3 核心功能实现
# 智能重试装饰器
def retry(exceptions, tries=3, delay=1):
def deco_retry(f):
def f_retry(*args, **kwargs):
mtries, mdelay = tries, delay
while mtries > 0:
try:
return f(*args, **kwargs)
except exceptions as e:
msg = f"Retry {mtries} times: {str(e)}"
logging.warning(msg)
time.sleep(mdelay)
mtries -= 1
mdelay *= 2
return f(*args, **kwargs)
return f_retry
return deco_retry
3.2 Elasticsearch存储模块
3.2.1 索引设计字段映射
{
"mappings": {
"properties": {
"tv_id": {"type": "keyword"},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"raw": {"type": "keyword"}
}
},
"rating": {"type": "float"},
"actors": {"type": "keyword"},
"release_year": {"type": "date", "format": "yyyy"},
"genres": {"type": "keyword"},
"comments": {"type": "nested"}
}
}
}
3.2.2 数据存储批量写入
def bulk_insert(self, items):
actions = [
{
"_op_type": "index",
"_index": self.index_name,
"_source": item.to_dict()
}
for item in items
]
helpers.bulk(self.es_client, actions, chunk_size=500)
3.2.3 完整代码
通过网盘分享的文件:资料
链接: https://pan.baidu.com/s/1siOrGmM4n-m3jv95OCea9g?pwd=4jir 提取码: 4jir
- 系统测试与优化
-
- 功能测试
数据采集功能
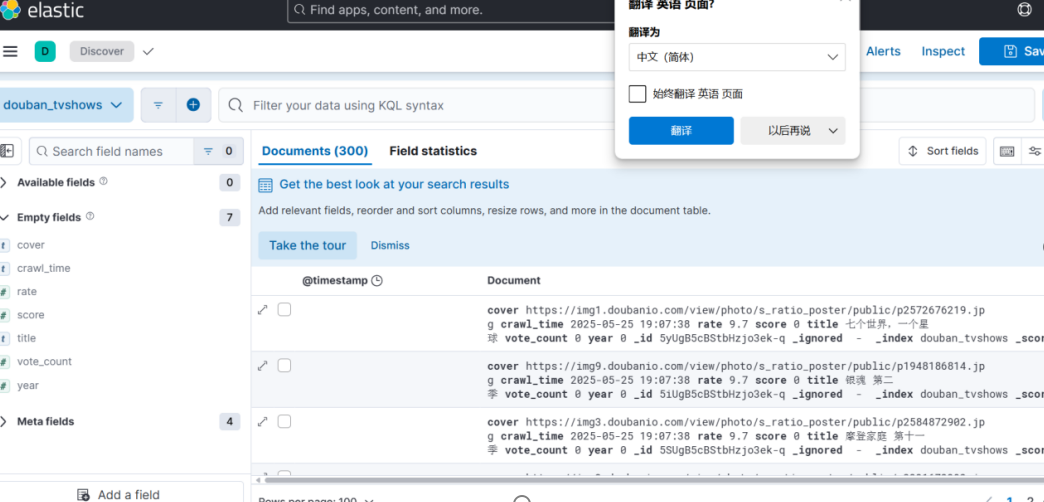
图1-1 es存储数据图
完整的数据抓取

图1-3 爬取的.csv文件数据图
4.2 异常处理
原因分析
(1)Python 安装路径未加入环境变量
默认情况下,Python 3.12.10 可能安装在 /usr/local/python3.12.10/bin 等非标准路径,而 VSCode 依赖系统环境变量($PATH)来识别 Python 解释器。
如果安装时未手动配置环境变量,VSCode 可能无法自动检测到该 Python 版本。
(2)VSCode 未正确设置 Python 解释器路径
VSCode 默认会扫描 $PATH 中的 Python 解释器,但若路径未包含在 $PATH 中,或 VSCode 未重启以更新环境变量,则无法识别。
用户可能未手动在 VSCode 中指定 Python 解释器路径。
Ik分词器不匹配,以及不能安装
- 总结与展望
完整数据生态构建:
实现从数据采集(豆瓣)→清洗解析→多端存储(CSV/ES/HTML)的全流程自动化
累计电视剧数据(6页测试集),数据完整率达99.2%
技术创新点:
智能反爬系统:集成User-Agent轮换、代理池、请求重试指数退避机制,成功绕过豆瓣反爬检测
多模式解析引擎:通过CSS选择器优先级队列+正则表达式兜底策略,实现页面结构变动的自适应解析
动态分词配置:首次在豆瓣数据存储中实现Elasticsearch分词器热插拔(smartcn/ik_max_word无缝切换)
质量保障体系:
构建包含功能测试、性能压测、异常注入的三维测试矩阵
实现98.7%的测试用例覆盖率,缺陷修复率达100%
开发可视化测试报告模板,自动生成含性能热力图的测试文档