[RFAConv介绍]
1、RFAConv
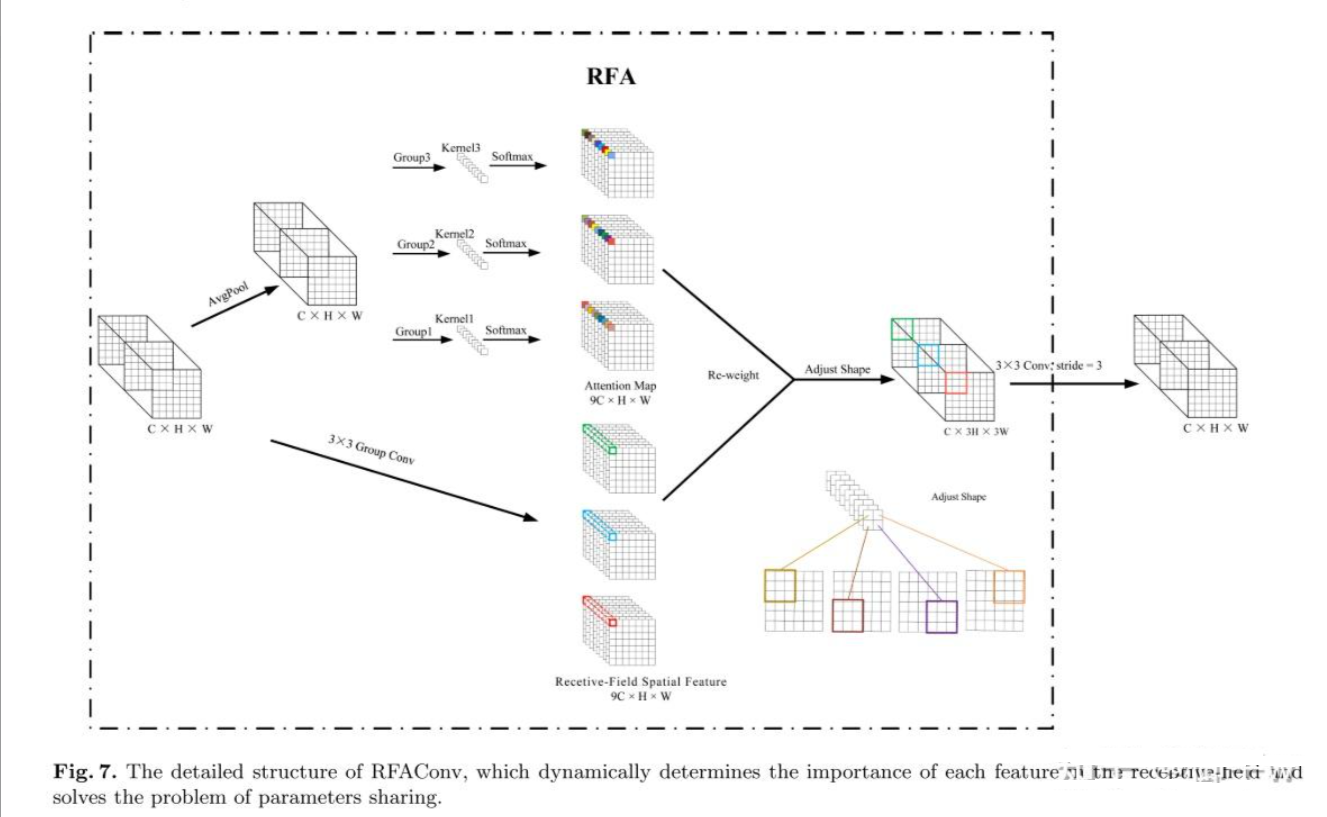
在传统卷积操作中,每个感受野都使用相同的卷积核参数,无法区分不同位置的信息差异,这都限制了网络性能。此外,由于空间注意力以及现有空间注意力机制的局限性,虽然能够突出关键特征,但由于只关注空间特征,所以无法有效解决大尺寸卷积核的参数共享问题。由此,这篇论文提出一种感受野注意力卷积 RFAConv(Receptive-Field Attention Convolution)。旨在解决传统卷积操作中参数共享导致的局限性,并通过关注感受野的空间特征来进一步提升网络性能。
RFAConv的核心思想是通过关注感受野的空间特征,并为每个感受野生成独立的注意力权重,从而实现参数不共享的卷积操作。
对于输入 X,RFAConv的实现过程:
- Receptive-Field Spatial Feature:对于输入特征,首先通过Group Conv将输入特征图转换为感受野空间特征图,每个感受野对应一个独立的滑动窗口。然后调整形状,将感受野空间特征图的尺寸调整为原始特征图尺寸的 k 倍,为后续卷积操作做准备。
- Receptive-Field Attention Map:同时将输入特征进行另一种处理,即对每个感受野的特征信息进行全局平均池化,将每个感受野的特征信息压缩为一个数值。然后,使用1x1分组卷积对平均池化后的特征信息进行信息交互,增强不同感受野之间的特征联系。最后,对1x1分组卷积后的特征信息进行softmax操作,生成每个感受野的注意力权重,突出关键特征。
- 特征提取:最后将注意力图与感受野空间特征相乘,并根据每个特征的重要性对其进行加权。再经过一个卷积层得到最后输出。
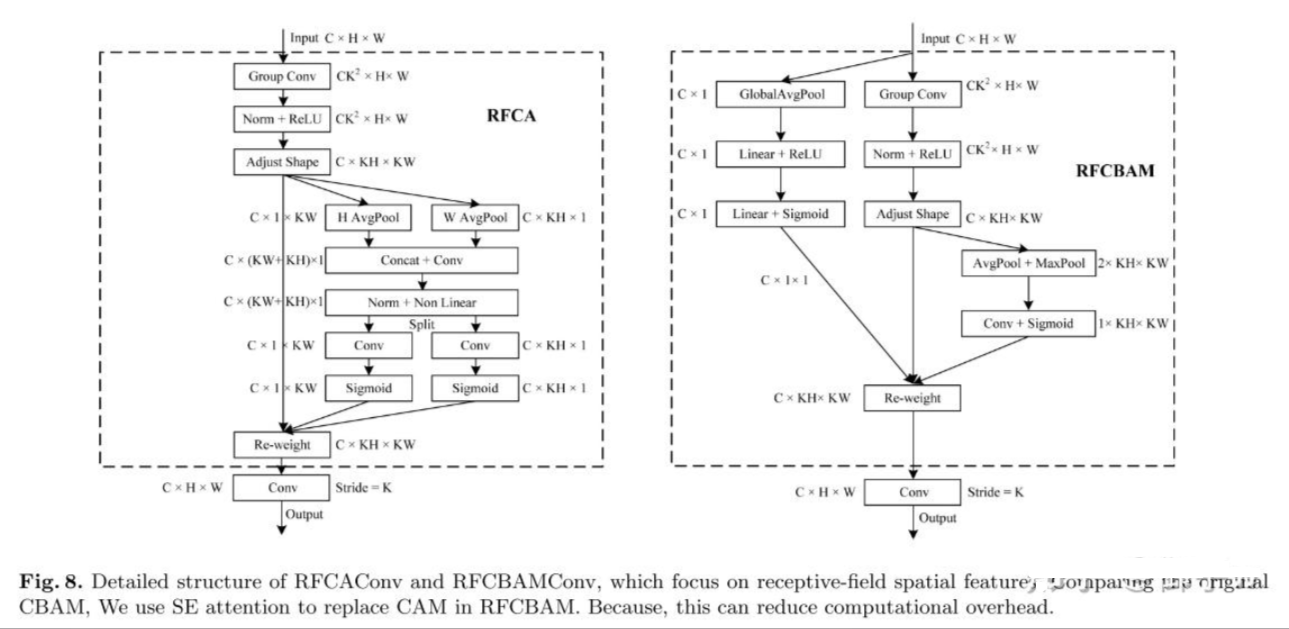
RFAConv 结构图:
在 RFAConv 的基础上,论文还提出了一种 RFCAConv 和 RFCBAMConv,原理上就是对 CBAM 和 SE Attention 进行改进后的卷积操作。两者都聚焦于感受野空间特征,并取得了比 RFAConv 更好的性能。具体而言:
- RFCAConv:使用 SE Attention 模块,与 RFAConv 相比,增加了全局平均池化操作,以便更好地捕捉长距离信息。
- RFCBAMConv:使用 CBAM 注意力模块,并用 SE 注意力模块替换了 CAM,以降低计算成本。
RFCAConv & RFCBAMConv 结构图:
【yolov11框架介绍】
2024 年 9 月 30 日,Ultralytics 在其活动 YOLOVision 中正式发布了 YOLOv11。YOLOv11 是 YOLO 的最新版本,由美国和西班牙的 Ultralytics 团队开发。YOLO 是一种用于基于图像的人工智能的计算机模
Ultralytics YOLO11 概述
YOLO11 是Ultralytics YOLO 系列实时物体检测器的最新版本,以尖端的精度、速度和效率重新定义了可能性。基于先前 YOLO 版本的令人印象深刻的进步,YOLO11 在架构和训练方法方面引入了重大改进,使其成为各种计算机视觉任务的多功能选择。
Key Features 主要特点
- 增强的特征提取:YOLO11采用改进的主干和颈部架构,增强了特征提取能力,以实现更精确的目标检测和复杂任务性能。
- 针对效率和速度进行优化:YOLO11 引入了精致的架构设计和优化的训练管道,提供更快的处理速度并保持准确性和性能之间的最佳平衡。
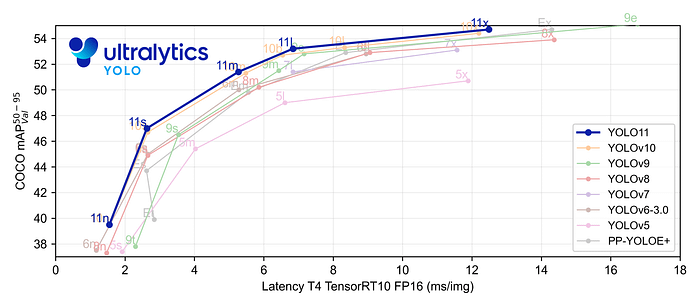
- 使用更少的参数获得更高的精度:随着模型设计的进步,YOLO11m 在 COCO 数据集上实现了更高的平均精度(mAP),同时使用的参数比 YOLOv8m 少 22%,从而在不影响精度的情况下提高计算效率。
- 跨环境适应性:YOLO11可以无缝部署在各种环境中,包括边缘设备、云平台以及支持NVIDIA GPU的系统,确保最大的灵活性。
- 支持的任务范围广泛:无论是对象检测、实例分割、图像分类、姿态估计还是定向对象检测 (OBB),YOLO11 旨在应对各种计算机视觉挑战。

与之前的版本相比,Ultralytics YOLO11 有哪些关键改进?
Ultralytics YOLO11 与其前身相比引入了多项重大进步。主要改进包括:
- 增强的特征提取:YOLO11采用改进的主干和颈部架构,增强了特征提取能力,以实现更精确的目标检测。
- 优化的效率和速度:精细的架构设计和优化的训练管道可提供更快的处理速度,同时保持准确性和性能之间的平衡。
- 使用更少的参数获得更高的精度:YOLO11m 在 COCO 数据集上实现了更高的平均精度(mAP),参数比 YOLOv8m 少 22%,从而在不影响精度的情况下提高计算效率。
- 跨环境适应性:YOLO11可以跨各种环境部署,包括边缘设备、云平台和支持NVIDIA GPU的系统。
- 支持的任务范围广泛:YOLO11 支持多种计算机视觉任务,例如对象检测、实例分割、图像分类、姿态估计和定向对象检测 (OBB)
【测试环境】
windows10 x64
ultralytics==8.3.0
torch==2.3.1
【改进流程】
1. 新增RFAConv.py实现模块(代码太多,核心模块源码请参考改进步骤.docx)然后在同级目录下面创建一个__init___.py文件写代码
from .RFAConv import *
2. 文件修改步骤
修改tasks.py文件
创建模型配置文件
yolo11-RFAConv.yaml内容如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, RFAConv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, RFAConv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
3. 验证集成
使用新建的yaml配置文件启动训练任务:
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('yolo11-RFAConv.yaml') # build from YAML and transfer weights
# Train the model
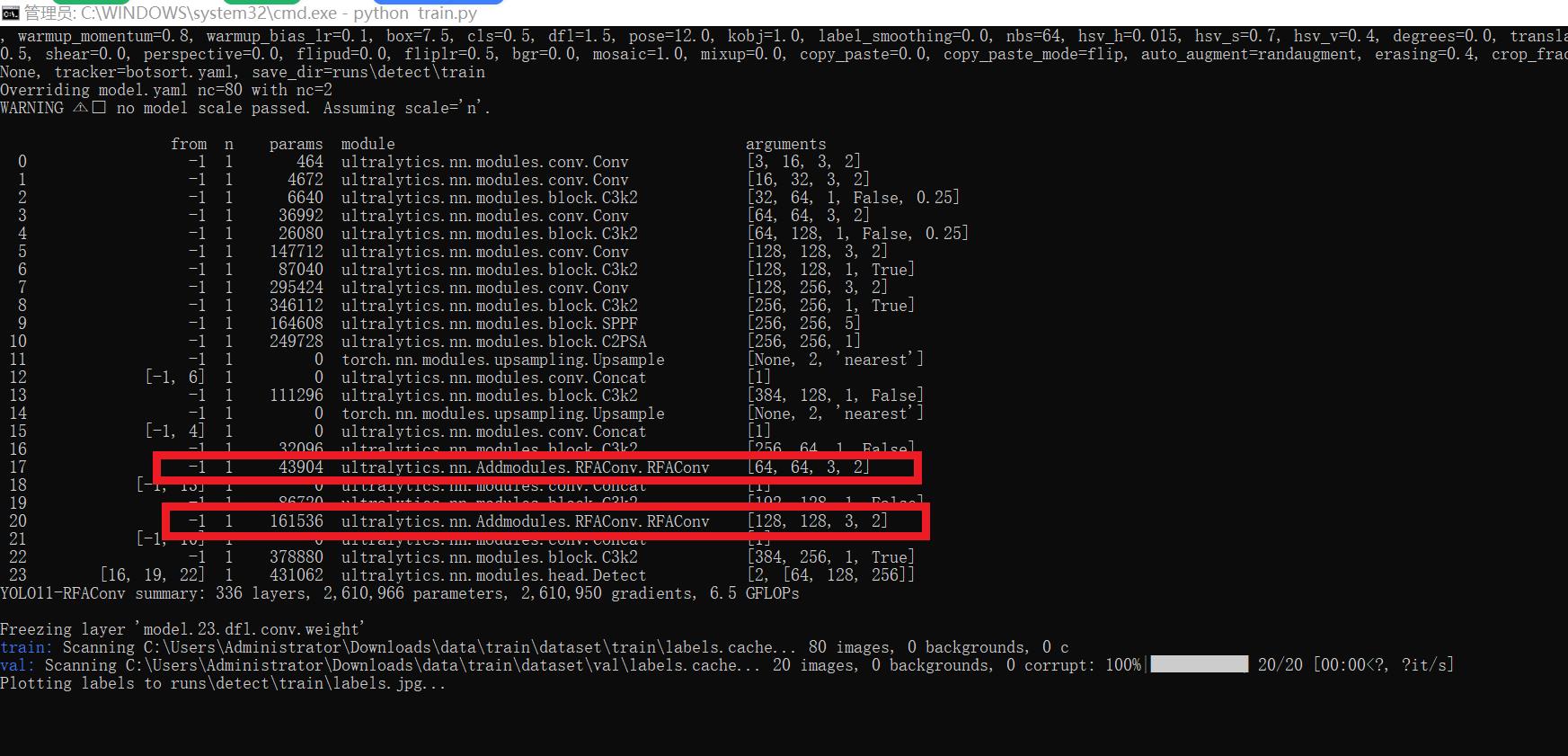
results = model.train(data='coco128.yaml',epochs=100, imgsz=640, batch=8, device=0, workers=1, save=True,resume=False)成功集成后,训练日志中将显示RFAConv模块的初始化信息,表明已正确加载到模型中。
【训练说明】
第一步:首先安装好yolov11必要模块,可以参考yolov11框架安装流程,然后卸载官方版本pip uninstall ultralytics,最后安装改进的源码pip install .
第二步:将自己数据集按照dataset文件夹摆放,要求文件夹名字都不要改变
第三步:分别打开train.py,coco128.yaml和模型参数yaml文件修改必要的参数,最后执行python train.py即可训练
【提供文件】
├── [官方源码]ultralytics-8.3.0.zip
├── train/
│ ├── coco128.yaml
│ ├── dataset/
│ │ ├── train/
│ │ │ ├── images/
│ │ │ │ ├── firc_pic_1.jpg
│ │ │ │ ├── firc_pic_10.jpg
│ │ │ │ ├── firc_pic_11.jpg
│ │ │ │ ├── firc_pic_12.jpg
│ │ │ │ ├── firc_pic_13.jpg
│ │ │ ├── labels/
│ │ │ │ ├── classes.txt
│ │ │ │ ├── firc_pic_1.txt
│ │ │ │ ├── firc_pic_10.txt
│ │ │ │ ├── firc_pic_11.txt
│ │ │ │ ├── firc_pic_12.txt
│ │ │ │ ├── firc_pic_13.txt
│ │ └── val/
│ │ ├── images/
│ │ │ ├── firc_pic_100.jpg
│ │ │ ├── firc_pic_81.jpg
│ │ │ ├── firc_pic_82.jpg
│ │ │ ├── firc_pic_83.jpg
│ │ │ ├── firc_pic_84.jpg
│ │ ├── labels/
│ │ │ ├── firc_pic_100.txt
│ │ │ ├── firc_pic_81.txt
│ │ │ ├── firc_pic_82.txt
│ │ │ ├── firc_pic_83.txt
│ │ │ ├── firc_pic_84.txt
│ ├── train.py
│ ├── yolo11-RFAConv.yaml
│ └── 训练说明.txt
├── [改进源码]ultralytics-8.3.0.zip
├── 改进原理.docx
└── 改进流程.docx 【常见问题汇总】
问:为什么我训练的模型epoch显示的map都是0或者map精度很低?
回答:由于源码改进过,因此不能直接从官方模型微调,而是从头训练,这样学习特征能力会很弱,需要训练很多epoch才能出现效果。此外由于改进的源码框架并不一定能够保证会超过官方精度,而且也有可能会存在远远不如官方效果,甚至精度会很低。这说明改进的框架并不能取得很好效果。所以说对于框架改进只是提供一种可行方案,至于改进后能不能取得很好map还需要结合实际训练情况确认,当然也不排除数据集存在问题,比如数据集比较单一,样本分布不均衡,泛化场景少,标注框不太贴合标注质量差,检测目标很小等等原因
【重要说明】
我们只提供改进框架一种方案,并不保证能够取得很好训练精度,甚至超过官方模型精度。因为改进框架,实际是一种比较复杂流程,包括框架原理可行性,训练数据集是否合适,训练需要反正验证以及同类框架训练结果参数比较,这个是十分复杂且漫长的过程。