上一节讲了string的模拟实现,string的出现时间比vector靠前,所以一些函数给的也比较冗余,而后来的vector、list等在此基础上做了优化。这节讲一讲vector的模拟实现,vector与模板具有联系,而string的底层就是vector的一个特例,元素是char。
1.基本函数和成员变量
vector的成员变量有_start、_finish、_endofstorage。用来表示元素起始、终止、容量终止的三个位置。类模板的用途就类似于函数,给定参数,在类的定义中使用这个参数。和string一样先给出基本函数和成员变量,直接给出迭代器的定义,以及无参的默认构造函数。并得到size和capacity的值:
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
vector()
:_start(0),
_finish(0),
_endofstorage(0)
{
}
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
size_t size() const
{
return _finish - _start;
}
const_iterator begin()const
{
return _start;
}
const_iterator end()const
{
return _finish;
}
size_t capacity() const
{
return _endofstorage - _start;
}
private:
iterator _start;
iterator _finish;
iterator _endofstorage;
};2.增删查改
reserve、resize

void reserve(int n)
{
if (n > capacity())
{
int sz = size();
int cp = capacity();
T* tmp = new T[n];
if (_start)//防止拷贝空指针
{
memcpy(tmp, _start, sizeof(T) * size());
delete[] _start;
}
_start = tmp;
_finish = tmp + sz;
_endofstorage = tmp +n;
}
}
//切记,size()和capacity()要在资源释放之前保留下来,否则释放_start的空间后
//会导致原来的地址失效,而size和capacity的定义要用到之前的_start资源,就会
//导致使用野指针访问已经失效的位置。如果是一开始的时候,_start赋初值为0,这时不用
//再删除资源,直接赋值给start就行
void resize(size_t n, T value = T())
{
if (n > capacity())
{
reserve(n);
}
if (n > size())
{
while (_finish < _start + n)
{
*_finish = value;
_finish++;
}
}
else
{
_finish = _start + n;
}
}
//当多于capacity时,开辟空间;多于size时,将多余的部分都换成value,否则将finish向前移动
//这个就是,只管标识,而不释放资源。查
T& operator[](size_t pos)
{
if (pos < size())
{
return _start[pos];
}
}
const T& operator[](size_t pos) const
{
if (pos < size())
{
return _start[pos];
}
}
//当调用的是const对象,那么我们肯定也不希望它返回的值被修改,所以也应该是constinsert、push_back
push_back是insert的特例,写出来insert就可以。vector的参数为迭代器和插入值,插入值是引用,这也是为了防止调用拷贝构造造成浪费,因为T有可能是自定义的类型。
insert的画图示意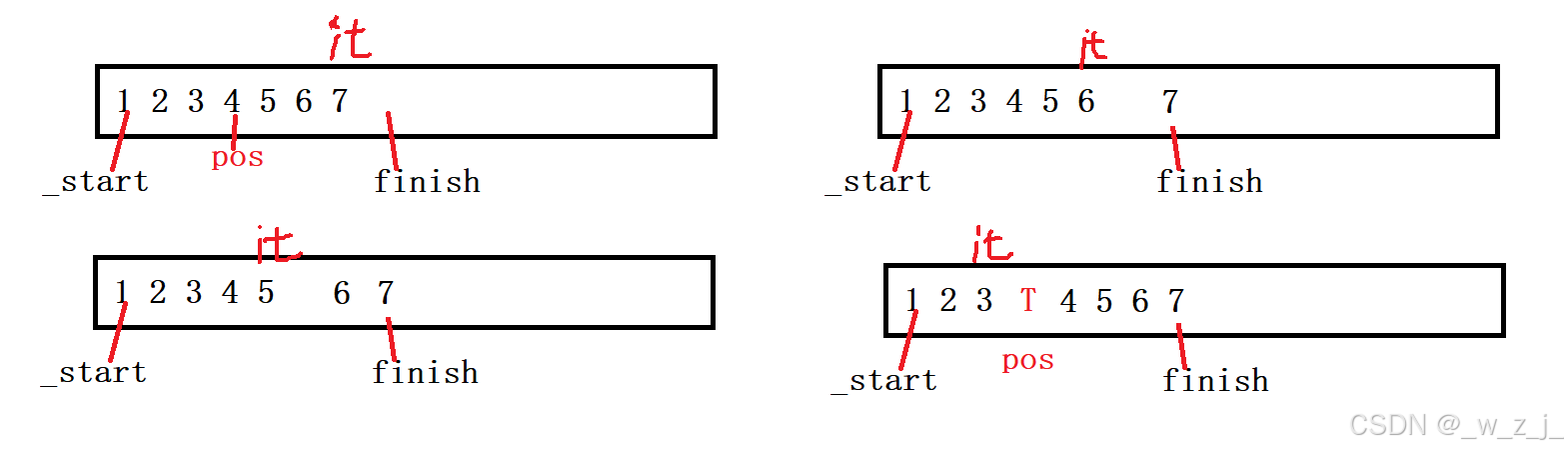
要注意容量是否足够,不足够记得开辟新空间。
void insert(iterator pos, const T& val)
{
if (pos >= _start and pos <= _finish)//位置
{
if (_finish == _endofstorage)//容量
{
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
}
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
end--;
}
*pos = val;
_finish++;
}
}迭代器失效
野指针
void test4()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
v1.insert(v1.end(), 5);
for (auto e : v1)
{
std::cout << e << " ";
}
}
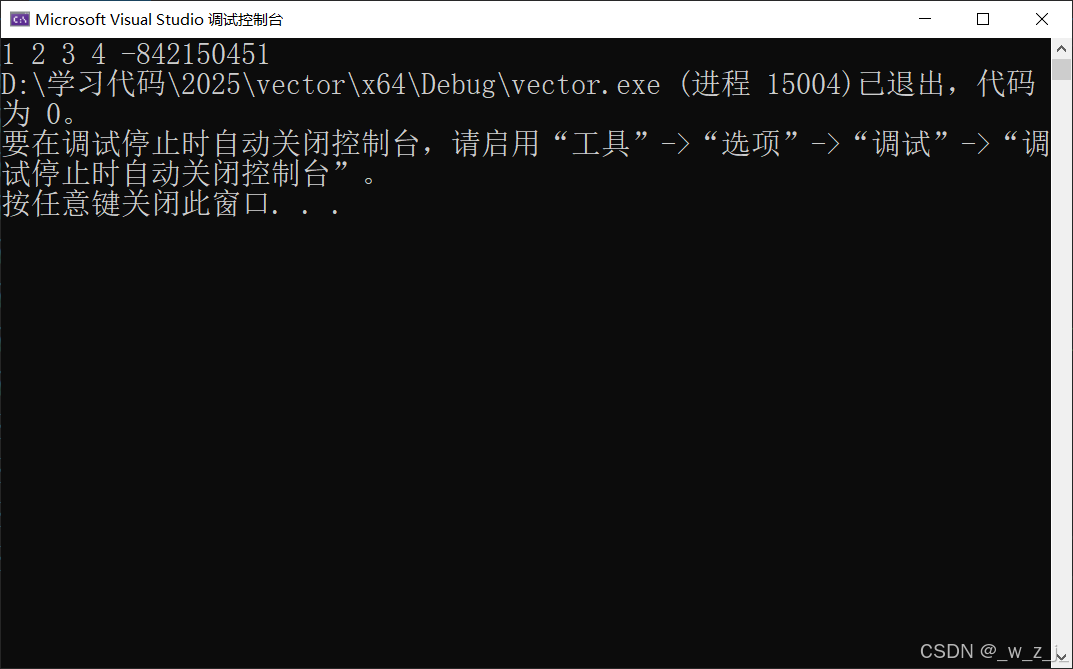
并没有出现5,这是怎么回事? 因为,要发生扩容,一开始给了4个位置空间,insert5时!发生了扩容,而pos还指向原来的位置,要在insert的扩容后面,更新一下pos:
void insert(iterator pos, const T& val)
{
if (pos >= _start and pos <= _finish)//位置
{
if (_finish == _endofstorage)//容量
{
size_t n = pos - _start;
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
pos = _start + n;//扩容后更新pos
}
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
end--;
}
*pos = val;
_finish++;
}接下来再看一种情况,在偶数位置插入10。
void test1()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
vector<int>::iterator it = v1.begin();
while (it != v1.end())
{
if (*it % 2 == 0)//偶数前面插入10
{
v1.insert(it, 10);
}
it++;
}
for (auto e : v1)
{
std::cout << e << " ";
}
}程序允许会出现异常,访问冲突。结合前面的例子,想一想为什么会出现访问错误问题?对了!这里的it,也就是上面的pos没有改变!那我们可不可以将insert中的pos改为引用呢?这样pos在insert函数改变了,it不也改变了?不可以!因为会出现比如insert(v.begin(),1)的调用情况,这时调用begin函数,得到返回值迭代器,由于返回的是值,不是引用,所以具有常性,const,而我们又要修改迭代器,这不是冲突了吗?而且在标准库中也没有使用引用,不符合使用规则。那么如何修改呢?给一个返回值就好。 每次在外面接收一下就ok了。
iterator insert(iterator pos, const T& val)
{
if (pos >= _start and pos <= _finish)//位置
{
if (_finish == _endofstorage)//容量
{
size_t n = pos - _start;
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
pos = _start + n;//扩容后更新pos
}
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
end--;
}
*pos = val;
_finish++;
}
return pos;
//使用标准库的实现方式,即不使用引用,而是直接返回一个新的迭代器。
//这样可以明确地告知调用者,原来的迭代器可能已经失效,应该使用返回的新迭代器。
}
void test1()
{
vector<int> v1;
//v1.reserve(10);//虽然容量够,不用扩容, 但是it指向的位置变了,导致重复插入10
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
vector<int>::iterator it = v1.begin();
while (it != v1.end())
{
if (*it % 2 == 0)//偶数前面插入10
{
it=v1.insert(it, 10);//pos虽然改变了,但是是传值引用,不改变it,扩容后it还是原来的位置
}
it++;
}
for (auto e : v1)
{
std::cout << e << " ";
}
}指向位置意义改变
但是,运行上面的程序,仍然有问题。陷入了死循环,经过调试发现了问题,pos每次返回的都是插入后的位置,这就导致了1 10 2 3 4,每次it++后到2,又对2进行检查,又插入10......循环往复,所以不会停止,这就是令一种迭代器失效的情况--迭代器指向位置意义改变了。所以我们应该在插入后就++一次。
void test1()
{
vector<int> v1;
//v1.reserve(10);//虽然容量够,不用扩容, 但是it指向的位置变了,导致重复插入10
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
vector<int>::iterator it = v1.begin();
while (it != v1.end())
{
if (*it % 2 == 0)//偶数前面插入10
{
it=v1.insert(it, 10);//pos虽然改变了,但是是传值引用,不改变it,扩容后it还是原来的位置
it++;
}
it++;
}
for (auto e : v1)
{
std::cout << e << " ";
}
}这时insert大功告成,而push_back调用一下也行,自己写一下也行:
void push_back(const T& ch)
{
if (_finish==_endofstorage)
{
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
}
*_finish = ch;
_finish++;
}
void push_back(const T& ch)
{
insert(end(),ch);
}erase、pop_back
注意erase返回删除位置元素的迭代器就好,虽然看起来没什么大用,但是如果使用者想写一个缩容方案的erase就有用了!不过一般不考虑缩容,现在的硬件内存都比较便宜了,一般不太会拿时间换空间了。
void pop_back()
{
if (_start < _finish)
{
--_finish;
}
}
iterator erase(iterator pos)//返回原位置
{
assert(pos >= _start and pos < _finish);
iterator it = pos + 1;
while (it != _finish)
{
*(it - 1) = *it;
it++;
}
_finish--;
return pos;
}在vs2019下,对迭代器失效检查的比较严格,而在linux下检查的比较宽松。但是使用时,一定要注意迭代器失效问题。
3.构造函数、析构函数、拷贝构造函数
析构函数
~vector()
{
if (_start)
{
delete[]_start;
}
_start = _finish = _endofstorage = nullptr;
}拷贝构造函数和构造函数
拷贝构造函数有经典版的:这里使用memcpy复制内容,逐字节复制
vector(const vector<T>& v)
{
_start = new T[v.capacity()];
_finish = _start + v.size();
_endofstorage = _start + v.capacity();
memcpy(_start, v._start, size()*sizeof(T));
}也可以使用现代版的(string有提到,让别人去构造,窃取劳动果实),但是构造函数就要再重载几个,不能用无参的默认构造函数为现代版的拷贝构造使用。
有作为范围使用的,有给个数填充的:给范围使用的,告诉我们,在类模板中,照样可以嵌套函数模板使用!只要给的参数正确合理即可
vector(size_t n, const T& val = T())
{
reserve(n);
for (int i = 0; i < n; i++)
{
push_back(val);
}
}
template <class InputIterator>
vector(InputIterator first, InputIterator last )
:_start(0),
_finish(0),
_endofstorage(0)
{
while (first != last)
{
push_back(*(first++));
}
}使用举例:
void test5()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
v1.insert(v1.end(), 5);
v1.insert(v1.end(), 6);
vector<int> v2(v1.begin(), v1.end());
for (auto e : v2)
{
std::cout << e << " ";
}
string s1("123456789");
vector<char> v3(s1.begin(), s1.end());
for (auto e : v3)
{
std::cout << e << " ";
}
}
参数最优匹配问题:当我们想调用填充构造函数时,会发现报编译错误
void test6()
{
vector<int> v(5, 1);
for (auto e : v)
{
std::cout << e << " ";
}
}
我们发现它调用了范围构造函数!这是不对的,或者用排除法(出现错误的代码段分成几段,注释,编译,看看哪一部分编译不通过)找到错误!为什么呢?你看我们的参数是两个int,非常整齐,而 vector(size_t n, const T& val = T());前一个是size_t,与int不匹配需要转换才行,所以选择了参数更为整齐的vector(InputIterator first, InputIterator last )函数。有什么解决方法吗?源码中给出了又一个函数重载vector(int n, const T& val = T()),这样就不会报错了。
构造函数的弄好了,接下来搞一下拷贝构造的现代版本:
void swap(vector<T>& v)
{
std::swap(this->_start,v._start);
std::swap(this->_finish, v._finish);
std::swap(this->_endofstorage, v._endofstorage);
}
//首先要写一个swap函数用来交换vector内部资源
vector(const vector<T>& v)
{
vector<T> tmp(v.begin(), v.end());
swap(tmp);
}
//tmp用构造函数干的活得到的资源,被this窃取了!
vector<T>& operator=(vector<T> v)
{
swap(v);
return *this;
}
//而重载等于号就更简单了,由于不用使用引用传值
//连奴隶都不用重新找了,直接对传过来的奴隶窃取果实即可4.vector深浅拷贝问题
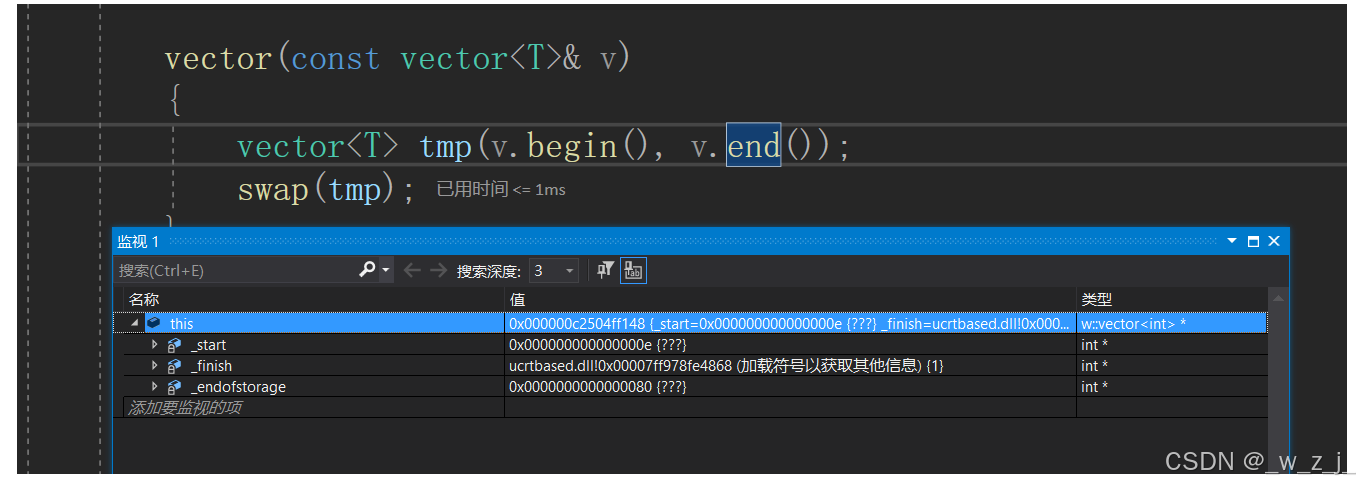
讲一个有意思的事情,我在用自己实现的vector写一个杨辉三角时,出现了问题。以下是杨辉三角的解决代码。在解决时,我发现执行到push_back时,自己实现的版本会出bug,而复用insert的就不会。经过调试发现vv.push_back(v);时,运行到*_finish = ch;时首先调用了拷贝构造函数,并没有先调用赋值函数,应该是在vs2019下先拷贝一个临时对象,然后再把临时对象赋值给finish,目的是为了防止赋值时出错从而使ch发生改动。接着有意思的地方就出现了,正常来说这个临时对象的未初始化资源(对象是vector<int>)应该是nullptr(有坑),但是在用自己写的push_back时调用拷贝构造时出现了下图的情况,该临时对象的_start不为nullptr,所以在拷贝构造结束后,tmp被交换得到了临时对象的资源,而其_start又不为空,所以在调用析构函数时出现了访问未分配资源的问题!后来才知道其实应该给拷贝构造函数赋初值操作。但是当时我复用insert时就不会出现这种情况,如图。应该是函数栈帧的构建导致编译器对内存的分配恰好使得分配的内存_start为nullptr。但是就是因为这两个一个可以用一个不可以用困扰了我好久。最后才发现给资源赋为空就行!我一开始还纳闷临时对象的初始资源是谁给的呢?调用拷贝构造之前调用构造??哈哈,后来上网查询才知道要自己赋初值。
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param num int整型
* @return int整型vector<vector<>>
*/
vector<vector<int> > generate(int num) {
vector<vector<int>> vv;
for (int i = 0; i < num; i++)
{
vector<int> v;
for (int j = 0; j < i + 1; j++)
{
if (j == 0 || j == i)
v.push_back(1);
else
v.push_back(vv[i - 1][j - 1] + vv[i - 1][j]);
}
vv.push_back(v);
}
return vv;
}
};
void test7()
{
Solution s;
vector<vector<int>> vv = s.generate(5);
for (int i = 0; i < vv.size(); i++)
{
vector<int> v = vv[i];
for (int j = 0; j < v.size(); j++)
{
cout << v[j];
}
printf("\n");
}
}
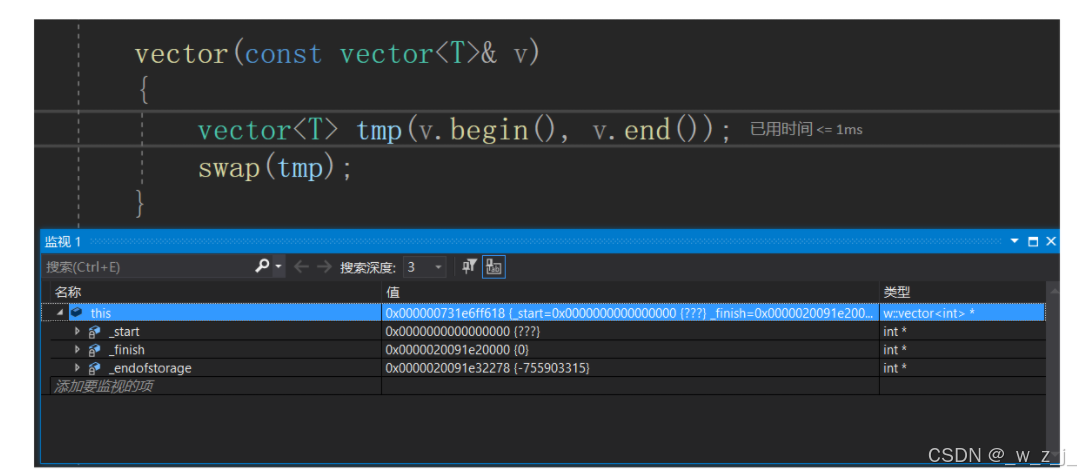
vector(const vector<T>& v)
: _start(nullptr), _finish(nullptr), _endofstorage(nullptr)
{
vector<T> tmp(v.begin(), v.end());
swap(tmp);
}解决了这个问题后,其实仍然有问题没有解决。执行程序会出现问题,具体体现在扩容之后。
vector<vector<int> > generate(int num) {
vector<vector<int>> vv;
for (int i = 0; i < num; i++)
{
vector<int> v;
for (int j = 0; j < i + 1; j++)
{
if (j == 0 || j == i)
v.push_back(1);
else
v.push_back(vv[i - 1][j - 1] + vv[i - 1][j]);
}
vv.push_back(v);
}
for (int i = 0; i < vv.size(); i++)
{
vector<int> v = vv[i];
for (int j = 0; j < v.size(); j++)
{
cout << v[j]<<endl;
}
printf("\n");
}
return vv;
}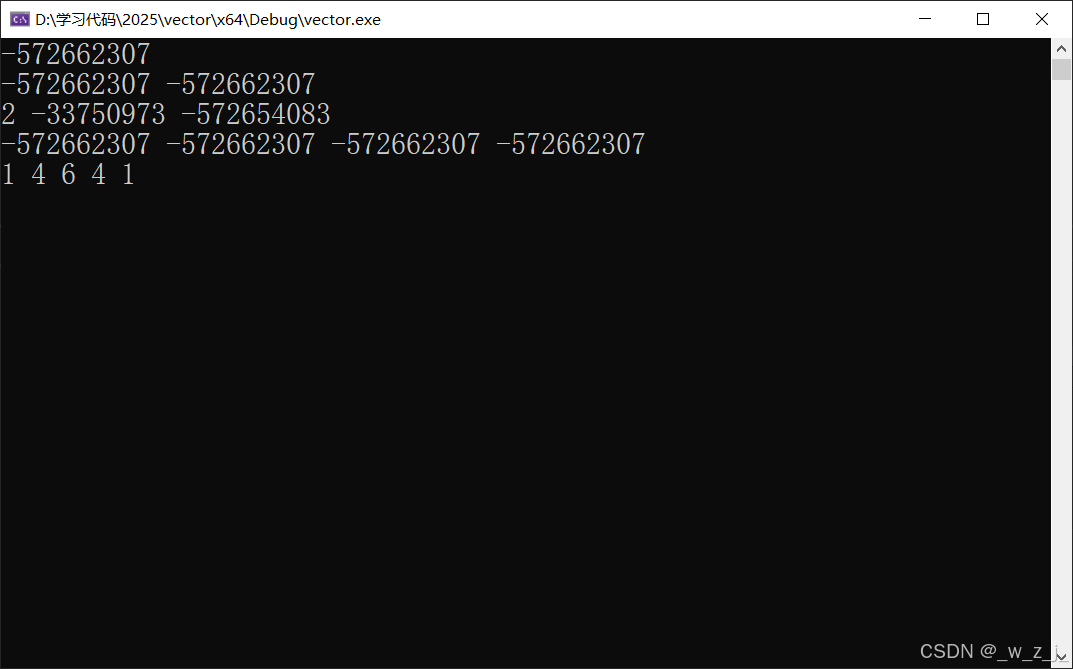 因为在reserve时,对原有的资源进行memcpy,而vv是一个vector<int>数组,它里面存放的是vector对象:所以会导致浅拷贝问题,就是我们已经把原来的释放了,但是新开辟的指针仍然指向被释放的空间就会出现bug,比如二次释放、访问野指针问题。
因为在reserve时,对原有的资源进行memcpy,而vv是一个vector<int>数组,它里面存放的是vector对象:所以会导致浅拷贝问题,就是我们已经把原来的释放了,但是新开辟的指针仍然指向被释放的空间就会出现bug,比如二次释放、访问野指针问题。
未reserve前的四个vector
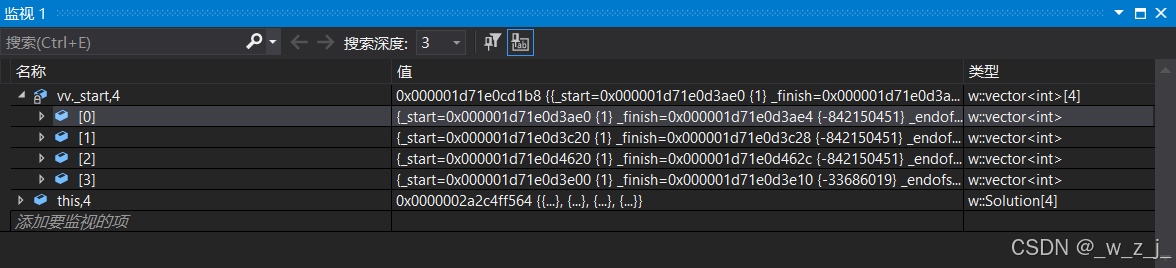
reserve后的四个vector的资源被释放了!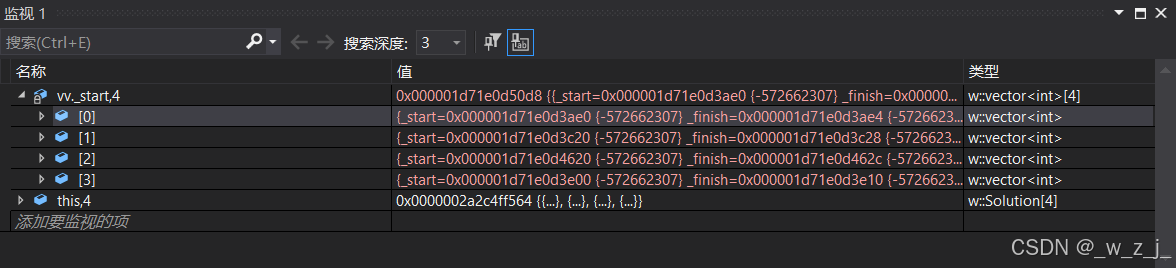
图中的红框中前四个vector的内容已经被释放了!由于前面的被释放了,他们又指向同一位置
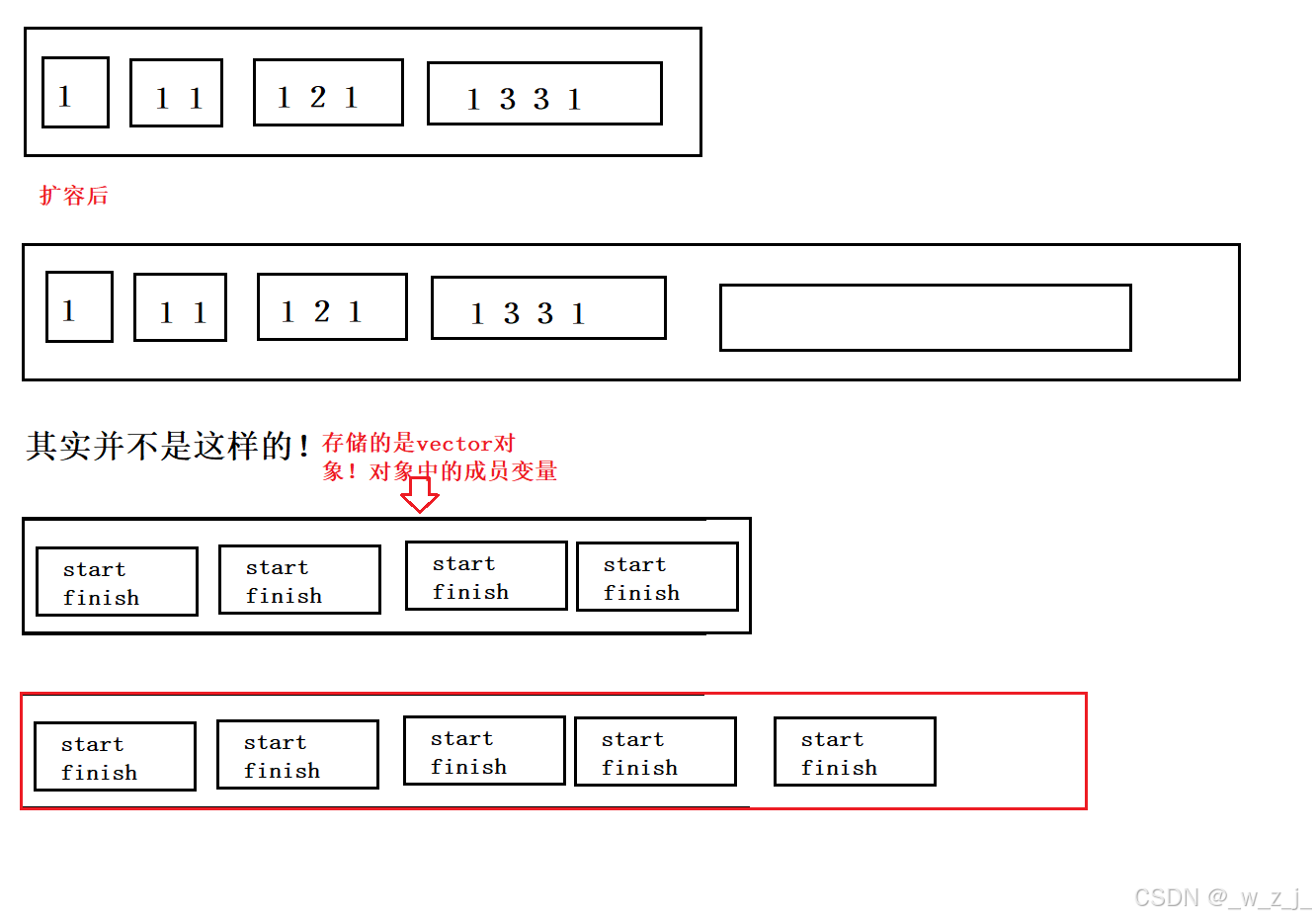
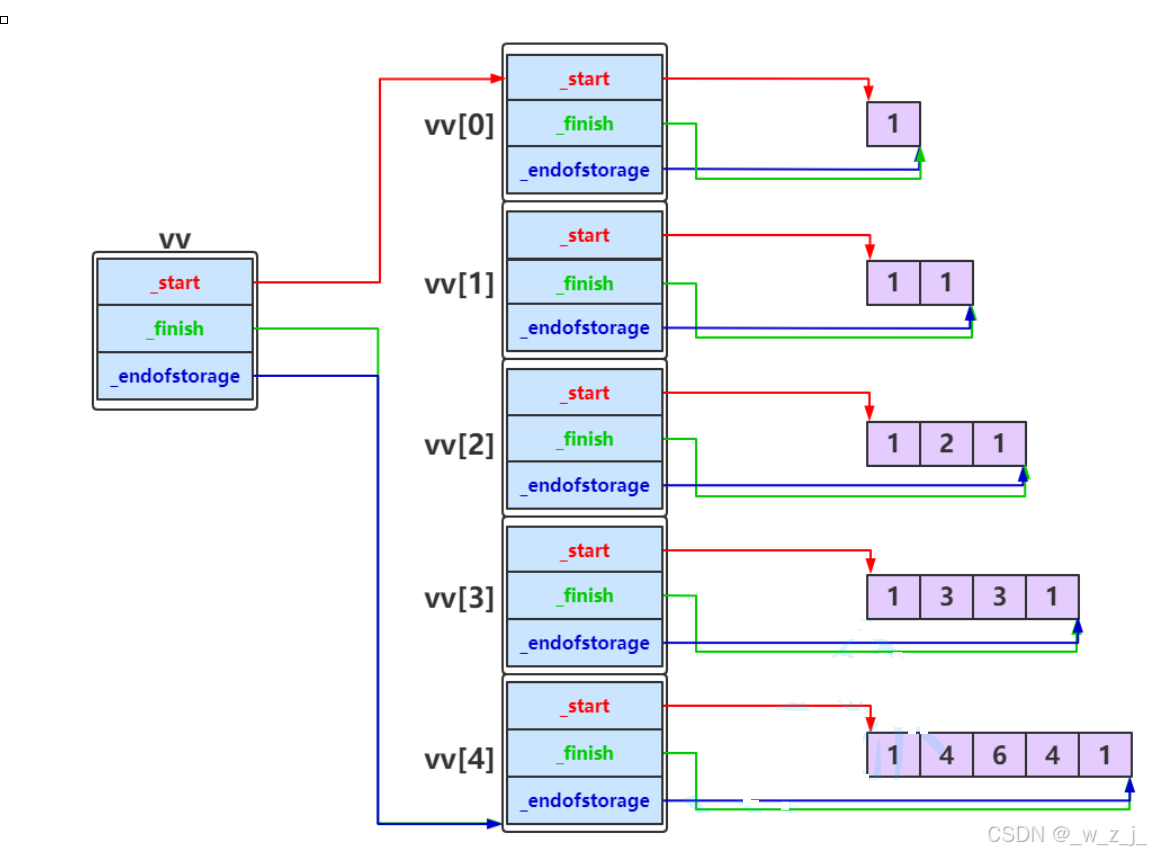
所以在reserve时,应该修改成
void reserve(int n)
{
int sz = size();
if (n > capacity())
{
T* tmp = new T[n];
if (_start)//防止拷贝空指针
{
memcpy(tmp, _start, sizeof(T) * size());
for (int i = 0; i < size(); i++)
{
tmp[i] = _start[i];
}
delete[] _start;
}
_start = tmp;
}
_finish = _start + sz;
_endofstorage = _start + n;
}所以以后在书写自定义类型的拷贝时,一定要注意不要使用memcpy。
完整代码
namespace w
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
vector()
:_start(0),
_finish(0),
_endofstorage(0)
{
}
vector(int n, const T& val = T())
{
reserve(n);
for (int i = 0; i < n; i++)
{
push_back(val);
}
}
vector(size_t n, const T& val = T())
{
reserve(n);
for (int i = 0; i < n; i++)
{
push_back(val);
}
}
template <class InputIterator>
vector(InputIterator first, InputIterator last )
:_start(0),
_finish(0),
_endofstorage(0)
{
while (first != last)
{
push_back(*(first++));
}
}
~vector()
{
if (_start)
{
delete[]_start;
}
_start = _finish = _endofstorage = nullptr;
}
void swap(vector<T>& v)
{
std::swap(this->_start,v._start);
std::swap(this->_finish, v._finish);
std::swap(this->_endofstorage, v._endofstorage);
}
//vector(const vector<T>& v)
//{
// _start = new T[v.capacity()];
// _finish = _start + v.size();
// _endofstorage = _start + v.capacity();
// memcpy(_start, v._start, size()*sizeof(T));
//}
vector(const vector<T>& v)
: _start(nullptr), _finish(nullptr), _endofstorage(nullptr)
{
vector<T> tmp(v.begin(), v.end());
swap(tmp);
}
vector<T>& operator=(vector<T> v)
{
swap(v);
return *this;
}
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
size_t size() const
{
return _finish - _start;
}
const_iterator begin()const
{
return _start;
}
const_iterator end()const
{
return _finish;
}
size_t capacity() const
{
return _endofstorage - _start;
}
void reserve(int n)
{
int sz = size();
if (n > capacity())
{
T* tmp = new T[n];
if (_start)//防止拷贝空指针
{
//memcpy(tmp, _start, sizeof(T) * size());
for (int i = 0; i < size(); i++)
{
tmp[i] = _start[i];
}
delete[] _start;
}
_start = tmp;
}
_finish = _start + sz;
_endofstorage = _start + n;
}
void push_back(const T& ch)
{
//insert(end(), ch);
if (_finish==_endofstorage)
{
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
}
*_finish = ch;
_finish++;
}
void pop_back()
{
if (_start < _finish)
{
--_finish;
}
}
//void insert(iterator& pos, const T& val) 为什么一般不使用引用:
//
// 1.迭代器失效的定义:在C++标准中,迭代器失效是指迭代器的值变得无效,
// 而不是指迭代器变量本身被销毁。即使你更新了it,在reserve操作之后,
//原来的迭代器值已经失效,你只是通过重新计算给了它一个新的值。这可能会导致调用者对迭代器失效的误解。
// 2.调用者的期望:调用者可能期望insert方法不会修改传入的迭代器it,
// 而是返回一个新的迭代器。如果insert方法修改了it,这可能会违反调用者的期望,
// 导致潜在的错误。
//如果是v.insert(v.begin(),t);那么调用begin,返回参数,具有常性,无法调用insert
//迭代器失效:1.野指针,重新扩容后pos指针没变;2.没有扩容,但是指向意义发生变化
//返回值为插入位置的指针,就是为了防止迭代器失效,指向没有意义的地方,pos不可以用引用,因为你不知道传的是不是常量
iterator insert(iterator pos, const T& val)
{
if (pos >= _start and pos <= _finish)//位置
{
if (_finish == _endofstorage)//容量
{
size_t n = pos - _start;
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
pos = _start + n;//扩容后更新pos
}
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
end--;
}
*pos = val;
_finish++;
}
return pos;
//使用标准库的实现方式,即不使用引用,而是直接返回一个新的迭代器。
//这样可以明确地告知调用者,原来的迭代器可能已经失效,应该使用返回的新迭代器。
}
iterator erase(iterator pos)//返回原位置
{
assert(pos >= _start and pos < _finish);
iterator it = pos + 1;
while (it != _finish)
{
*(it - 1) = *it;
it++;
}
_finish--;
return pos;
}
void resize(size_t n, T value = T())
{
if (n > capacity())
{
reserve(n);
}
if (n > size())
{
while (_finish < _start + n)
{
*_finish = value;
_finish++;
}
}
else
{
_finish = _start + n;
}
}
T& operator[](size_t pos)
{
if (pos < size())
{
return _start[pos];
}
}
const T& operator[](size_t pos) const
{
if (pos < size())
{
return _start[pos];
}
}
private:
iterator _start;
iterator _finish;
iterator _endofstorage;
};
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param num int整型
* @return int整型vector<vector<>>
*/
vector<vector<int> > generate(int num) {
vector<vector<int>> vv;
for (int i = 0; i < num; i++)
{
vector<int> v;
for (int j = 0; j < i + 1; j++)
{
if (j == 0 || j == i)
v.push_back(1);
else
v.push_back(vv[i - 1][j - 1] + vv[i - 1][j]);
}
vv.push_back(v);
}
for (int i = 0; i < vv.size(); i++)
{
vector<int> v = vv[i];
for (int j = 0; j < v.size(); j++)
{
cout << v[j]<<" ";
}
printf("\n");
}
return vv;
}
};
void test7()
{
Solution s;
vector<vector<int>> vv = s.generate(5);
for (int i = 0; i < vv.size(); i++)
{
vector<int> v = vv[i];
for (int j = 0; j < v.size(); j++)
{
cout << v[j];
}
printf("\n");
}
}
![[25-cv-05718]BSF律所代理潮流品牌KAWS公仔(商标+版权)](https://i-blog.csdnimg.cn/direct/5738f0510cf24da0be4807324a02e776.png)