本实战任务通过Spark RDD实现学生成绩的分组排行榜。首先,准备包含学生成绩的原始数据文件,并将其上传至HDFS。接着,利用Spark的交互式环境或通过创建Maven项目的方式,读取HDFS中的成绩文件生成RDD。通过map操作将数据映射为二元组形式,再使用groupByKey按学生姓名分组。之后,对每个学生的成绩列表进行降序排列并取前3名,最终按照指定格式输出结果。整个过程涉及RDD的基本操作,包括数据读取、转换和聚合,展示了Spark在处理分组TopN问题时的高效性和灵活性。

3.8.4 利用RDD实现分组排行榜
news2026/4/14 3:39:04
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2387442.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

python web flask专题-Flask入门指南:从安装到核心功能详解
Flask入门指南:从安装到核心功能详解
Flask作为Python最流行的轻量级Web框架之一,以其简洁灵活的特性广受开发者喜爱。本文将带你从零开始学习Flask,涵盖安装配置、项目结构、应用实例、路由系统以及请求响应处理等核心知识点。
1. Flask安…

【HW系列】—web组件漏洞(Strtus2和Apache Log4j2)
本文仅用于技术研究,禁止用于非法用途。 文章目录 Struts2Struts2 框架介绍Struts2 历史漏洞汇总(表格)Struts2-045 漏洞详解 Log4j2Log4j2 框架介绍Log4j2 漏洞原理1. JNDI 注入2. 利用过程 Log4j2 历史漏洞JNDILDAP 反弹 Shell 流程 Strut…

机器学习知识体系:从“找规律”到“做决策”的全过程解析
你可能听说过“机器学习”,觉得它很神秘,像是让电脑自己学会做事。其实,机器学习的本质很简单:通过数据来自动建立规则,从而完成预测或决策任务。
这篇文章将用通俗的语言为你梳理机器学习的知识体系,帮助…
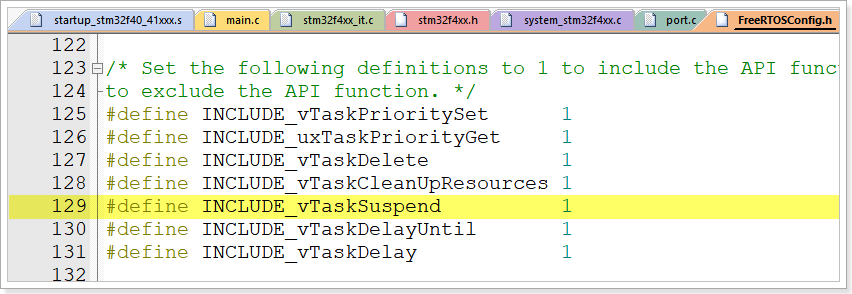
STM32之FreeRTOS移植(重点)
RTOS的基本概念
实时操作系统(Real Time Operating System)的简称就叫做RTOS,是指具有实时性、能支持实时控制系统工作的操作系统,RTOS的首要任务就是调度所有可以利用的资源来完成实时控制任务的工作,其次才是提高工…

R语言科研编程-标准偏差柱状图
生成随机数据
在R中,可以使用rnorm()生成正态分布的随机数据,并模拟分组数据。以下代码生成3组(A、B、C)随机数据,每组包含10个样本:
set.seed(123) # 确保可重复性
group_A <- rnorm(10, mean50, sd…
OpenGL Chan视频学习-11 Uniforms in OpenGL
bilibili视频链接:
【最好的OpenGL教程之一】https://www.bilibili.com/video/BV1MJ411u7Bc?p5&vd_source44b77bde056381262ee55e448b9b1973
函数网站:
docs.gl
说明:
1.之后就不再单独整理网站具体函数了,网站直接翻译…

GitLab 从 17.10 到 18.0.1 的升级指南
本文分享从 GitLab 中文本 17.10.0 升级到 18.0.1 的完整过程。
升级前提
查看当前安装实例的版本。有多种方式可以查看:
方式一: /help页面
可以直接在 /help页面查看当前实例的版本。以极狐GitLab SaaS 为例,在浏览器中输入 https://ji…
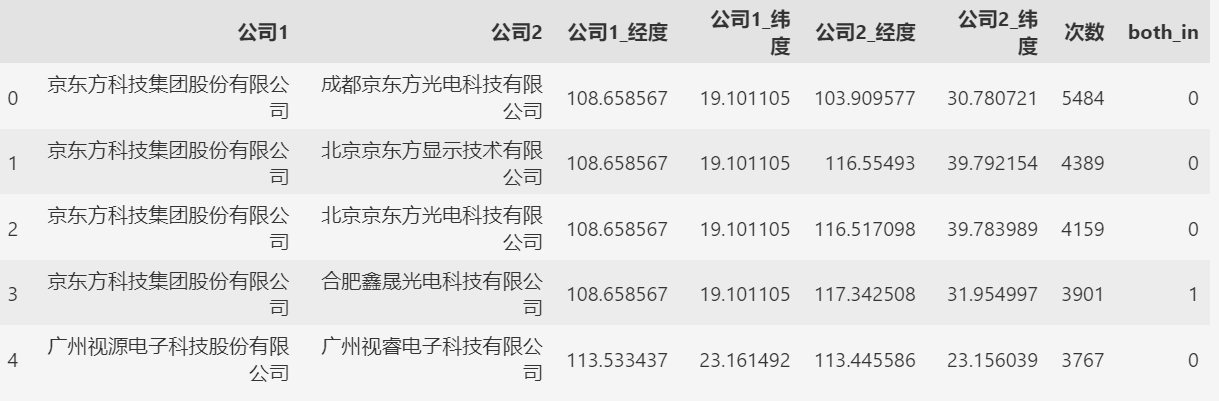
产业集群间的专利合作关系
需要准备的文件:
全国的专利表目标集群间的企业名单
根据专利的共同申请人,判断这两家企业之间存在专利合作关系。
利用1_filter_patent.py,从全国的3000多万条专利信息中,筛选出与目标集群企业相关的专利。 只要专利的申请人包…
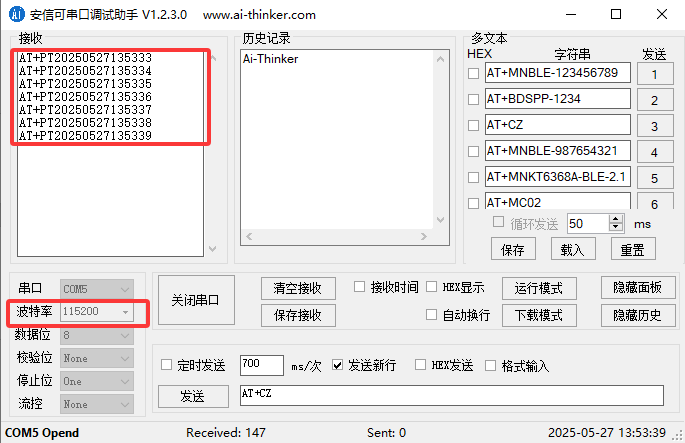
KT6368A通过蓝牙芯片获取手机时间详细说明,对应串口指令举例
一、功能简介
KT6368A双模蓝牙芯片支持连接手机,获取手机的日期、时间信息,可以同步RTC时钟
1、无需安装任何app,直接使用系统蓝牙即可实现
2、同时它不影响音频蓝牙,还支持一些简单的AT指令进行操作
3、实现的方式࿱…
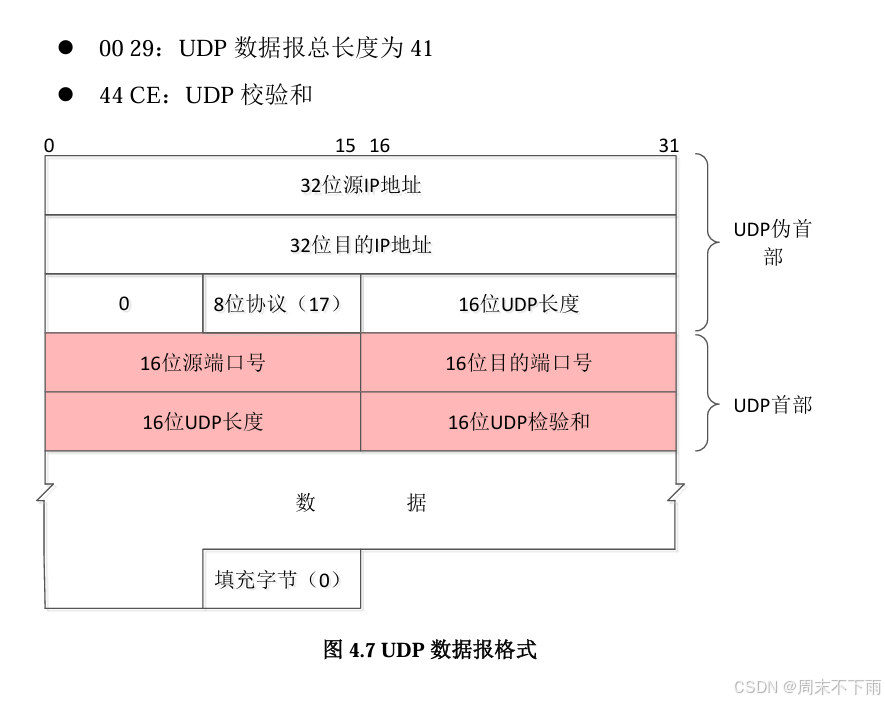
计算机网络实验课(二)——抓取网络数据包,并实现根据条件过滤抓取的以太网帧,分析帧结构
文章目录 一、添加控件二、代码分析2.1 代码2.2 控件初始化2.3 打开和关闭设备2.4 开始和结束捕获2.5 设置捕获条件2.6 捕获数据包 三、运行程序四、结果分析 提要:如果你通过vs打开.sln文件,然后代码界面或者前端界面都没找到,视图里面也没找…

78. Subsets和90. Subsets II
目录
78.子集
方法一、迭代法实现子集枚举
方法二、递归法实现子集枚举
方法三、根据子集元素个数分情况收集
方法四、直接回溯法
90.子集二
方法一、迭代法实现子集枚举
方法二、递归法实现子集枚举
方法三、根据子集元素个数分情况收集
方法四、直接回溯法 78.子集…
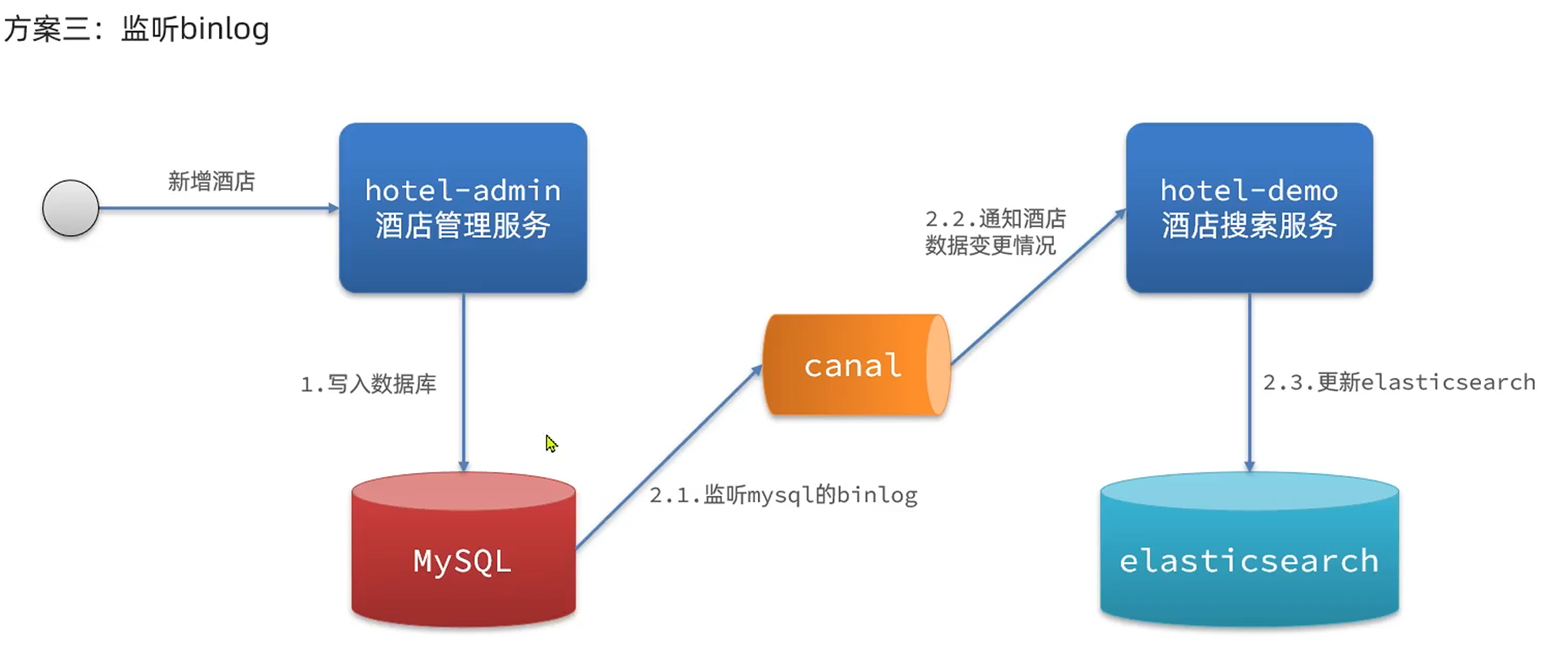
ElasticSearch整合SpringBoot
ElasticSearch 整合SpringBoot
ES官方提供了各种不同语言的客户端。用来操作ES。这些客户端的本质就是组装DSL语句,通过HTTP请求发送给ES。
设计索引库
跟据数据库的表结构进行ES索引库的创建时。如果字段需要进行倒排索引的时候请为它指定分词器。如果该字段不是…

2025上半年软考高级系统架构设计师经验分享
笔者背景 笔者在成都工作近7年, 一直担任研发大头兵,平日工作主要涵盖应用开发(Java)与数仓开发,对主流数据库、框架等均有涉猎,但谈不上精通。 最近有一些职业上的想法,了解到软考有那么一丁点…

uni-app学习笔记十二-vue3中创建组件
通过组件,可以很方便地实现页面复用,减少重复页面的创建,减少重复代码。一个页面可以引入多个组件。下面介绍在HBuilder X中创建组件的方法:
一.组件的创建
1.选中项目,右键-->新建目录(文件夹),并将文…
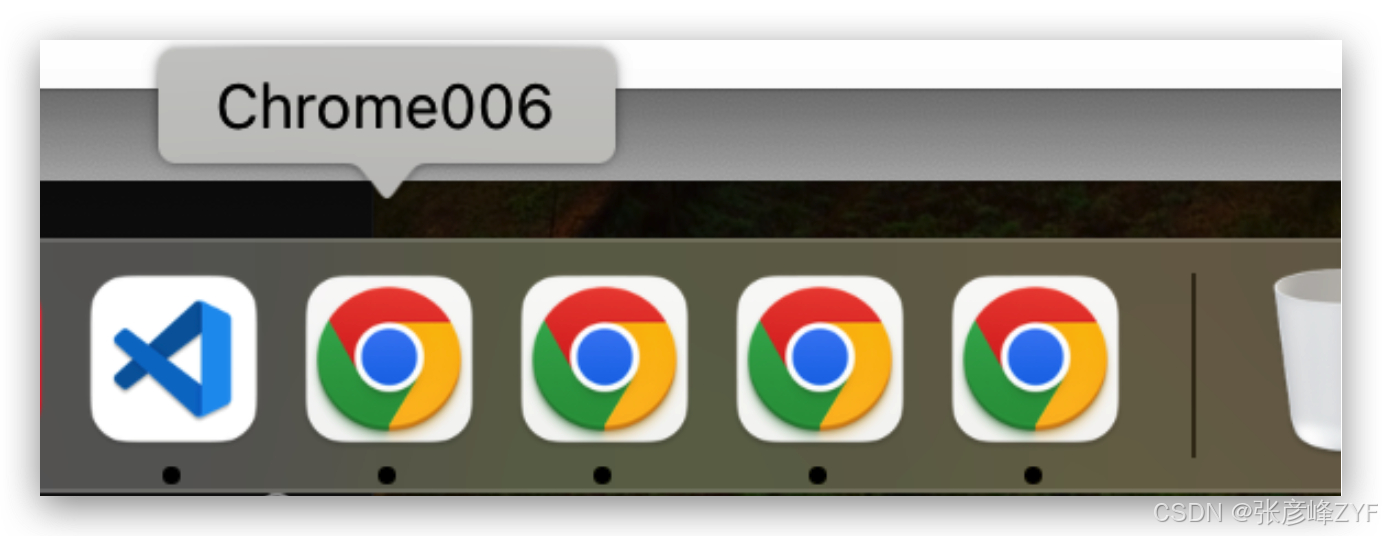
一键启动多个 Chrome 实例并自动清理的 Bash 脚本分享!
目录
一、📦 脚本功能概览
二、📜 脚本代码一览
三、🔍 脚本功能说明
(一)✅ 支持批量启动多个 Chrome 实例
(二)✅ 每个实例使用独立用户数据目录
(三)✅ 启动后自…
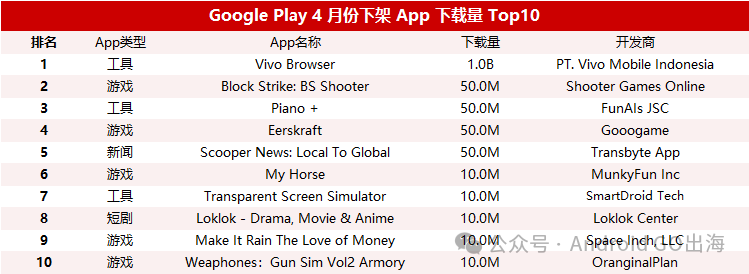
4 月 62100 款 App 被谷歌下架!环比增长 28%
大家好,我是牢鹅!上周刚刚结束的 2025 年 Google I/O 开发者大会, Google Play 带来了一系列的更新,主要围绕提升优质 App 的"发现"、"互动"和"收入"三大核心内容。
这或许正是谷歌生态的一个侧影…
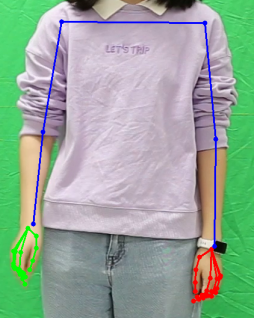
mediapipe标注视频姿态关键点(基础版加进阶版)
前言
手语视频流的识别有两种大的分类,一种是直接将视频输入进网络,一种是识别了关键点之后再进入网络。所以这篇文章我就要来讲讲如何用mediapipe对手语视频进行关键点标注。
代码
需要直接使用代码的,我就放这里了。环境自己配置一下吧&…
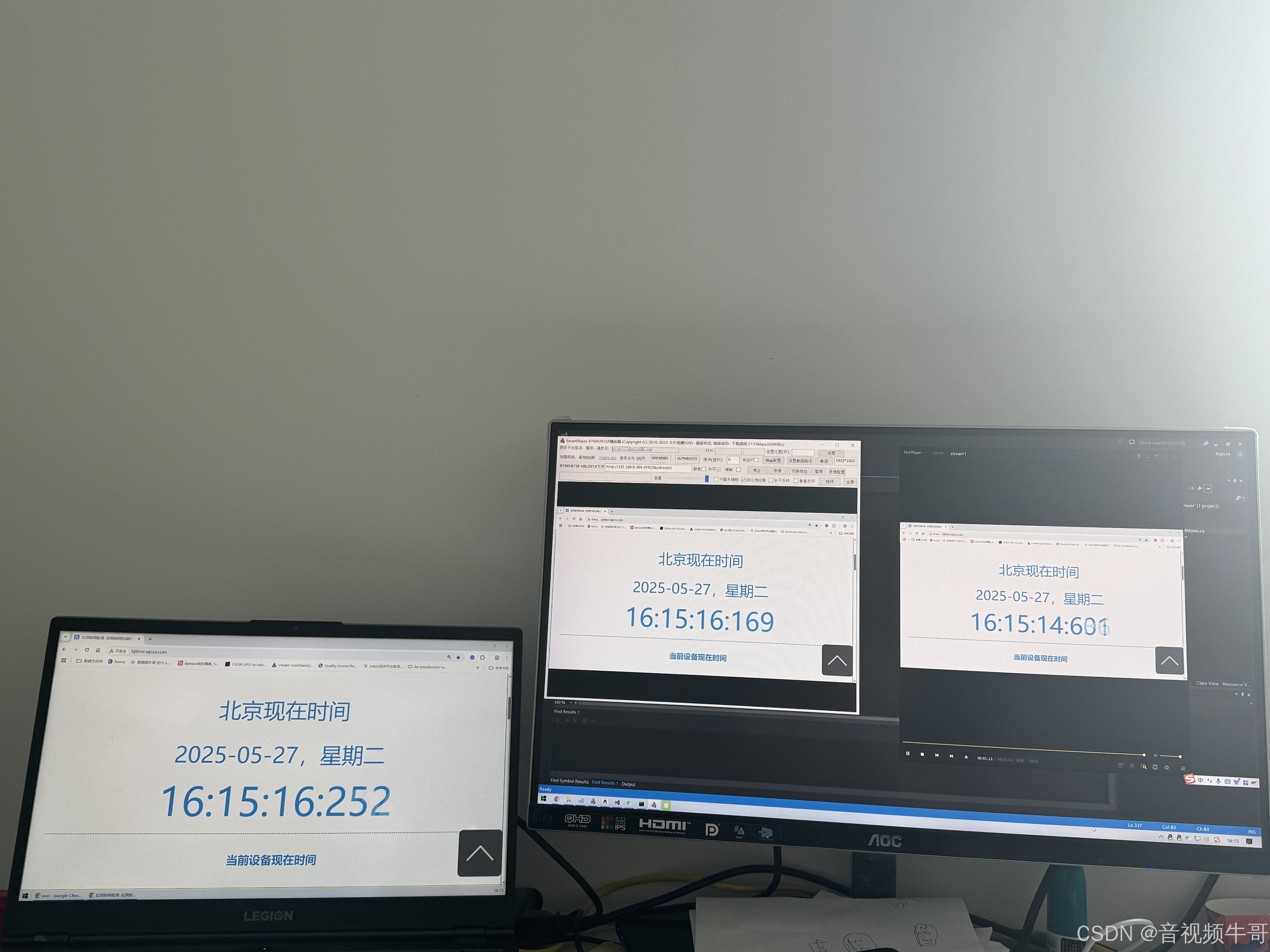
SmartPlayer与VLC播放RTMP:深度对比分析延迟、稳定性与功能
随着音视频直播技术的发展,RTMP(实时消息传输协议)成为了广泛应用于实时直播、在线教育、视频会议等领域的重要协议。为了确保优质的观看体验,RTMP播放器的选择至关重要。大牛直播SDK的SmartPlayer和VLC都是在行业中广受欢迎的播放…
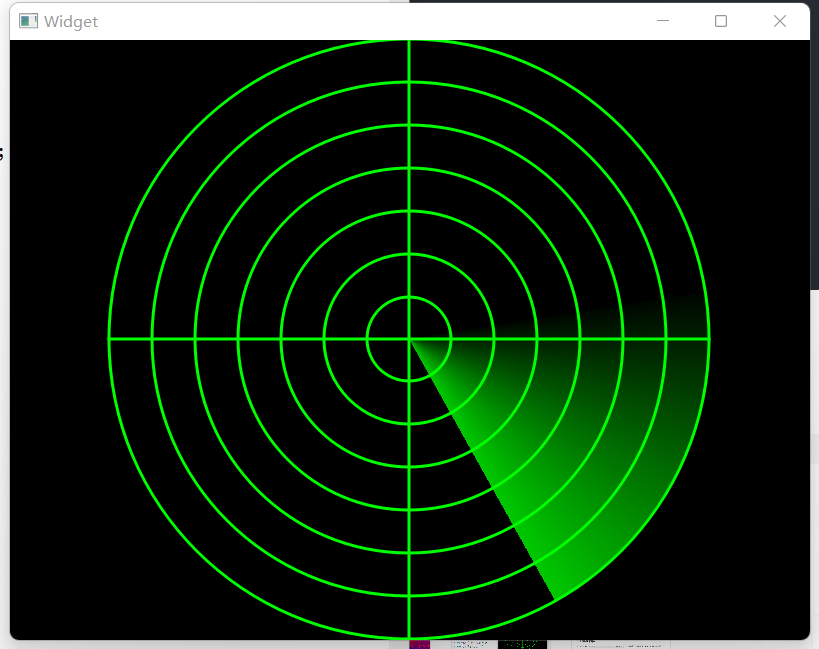
Qt QPaintEvent绘图事件painter使用指南
绘制需在paintEvent函数中实现 用图片形象理解 如果加了刷子再用笔就相当于用笔画过的区域用刷子走 防雷达:
源文件
#include "widget.h"
#include "ui_widget.h"
#include <QDebug>
#include <QPainter>
Widget::Widget(QWidget…