模型可视化
深度学习模型可视化是理解、调试和优化模型的关键技术,涉及模型结构、参数、层输出、数据流动、训练过程等多维度分析。
一、可视化的核心作用
- 模型理解
- 解析复杂模型的网络架构(如CNN的层级连接、Transformer的注意力机制)。
- 揭示模型如何从输入数据中提取特征(如卷积层的激活模式)。
- 调试与优化
- 定位层间信息流动异常(如梯度消失/爆炸、特征图空白)。
- 分析过拟合/欠拟合原因(如训练曲线震荡、验证集性能骤降)。
- 可解释性增强
- 向非技术人员展示模型决策逻辑(如图像分类中的关键像素区域)。
- 符合医疗、金融等敏感领域的合规性要求(如欧盟《人工智能法案》的透明性要求)。
- 数据与特征分析
- 验证数据预处理效果(如图像归一化、文本分词正确性)。
- 发现数据分布偏差(如类别不平衡、异常样本)。
二、可视化的核心维度
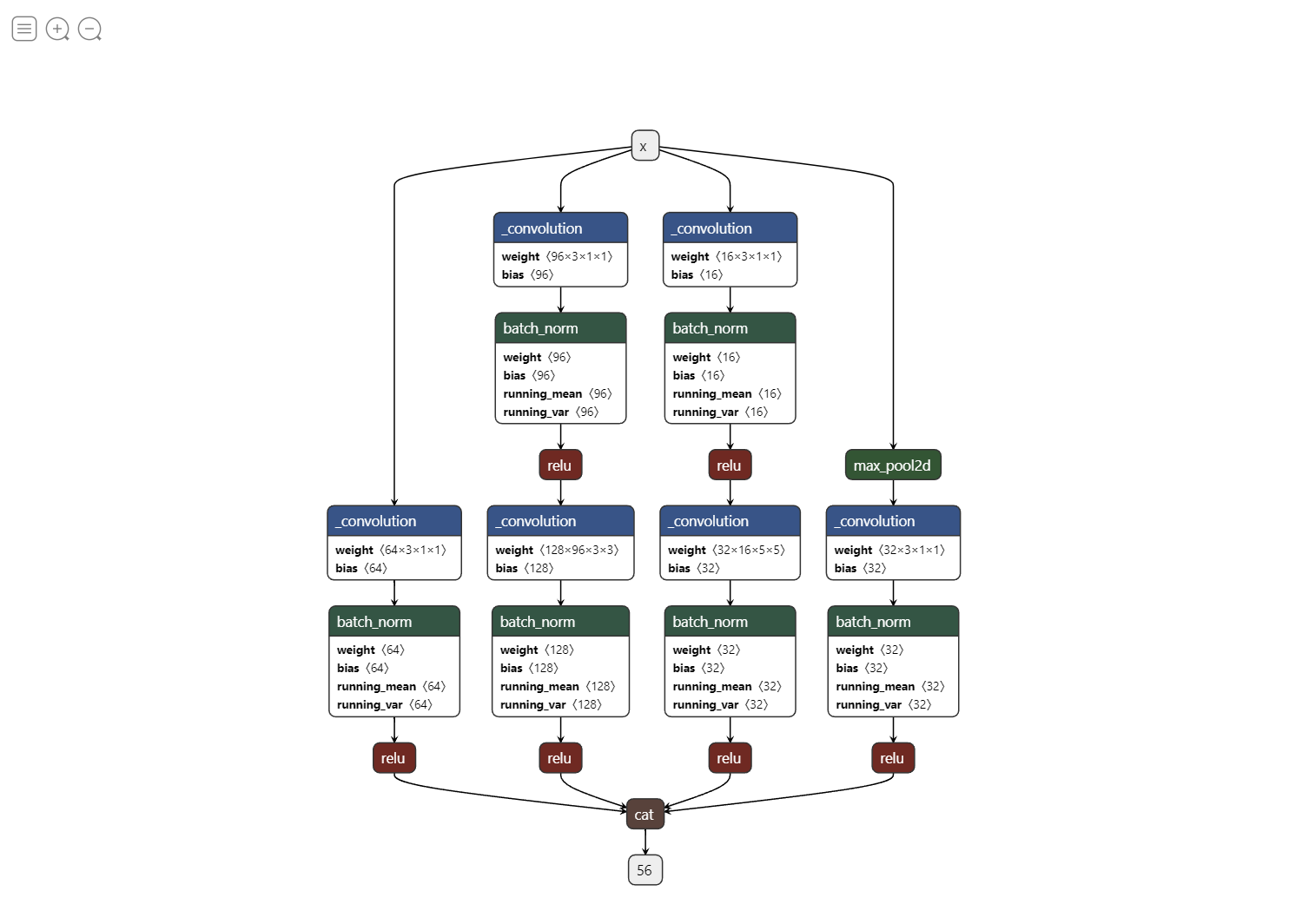
1. 模型结构可视化
- 目标:展示网络层连接关系、参数规模、计算流程。
- 适用场景:
- 新模型设计验证(如检查残差连接是否正确)。
- 模型压缩对比(如剪枝前后的层数量变化)。
- 技术方法:
- 框架原生工具:
- PyTorch:
torchsummary打印层结构,torchviz生成计算图。 - TensorFlow/Keras:
tf.keras.utils.plot_model绘制模型图,TensorBoard的Graphs模块。 - MXNet:
mxnet.viz.plot_network可视化符号图。
- PyTorch:
- 通用工具:
- Netron:支持PyTorch(
.pt/.pth)、TensorFlow(.pb/.h5)、ONNX、TensorRT等多种格式模型的交互式结构渲染,支持缩放、层参数查看(如卷积核尺寸、通道数),ONNX解释比较好。 - Graphviz:通过DOT语言自定义绘制计算图,适合学术论文配图。
- Netron:支持PyTorch(
- 示例代码(PyTorch+Netron):
import torch model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=True) torch.save(model.state_dict(), 'resnet50.pth') # 保存模型 # 用Netron打开resnet50.pth,可视化结构
- 框架原生工具:
2. 层激活与特征可视化
- 目标:观察中间层输出(特征图),验证层是否提取有效信息。
- 适用场景:
- CNN调试:判断卷积层是否捕获边缘、纹理等基础特征,或高层语义(如“猫脸”)。
- 异常检测:定位特征图全零或噪声过大的层(可能由梯度消失或参数初始化错误导致)。
- 技术方法:
- 特征图可视化:
- 直接可视化:提取层输出,缩放到[0,255]后保存为图像(适用于低维特征图,如CNN的前几层)。
# PyTorch示例:可视化ResNet的第一层卷积输出 from torchvision import models, transforms import matplotlib.pyplot as plt model = models.resnet50(pretrained=True).eval() layer_name = 'conv1' # 第一层卷积层名称 features = [] def hook_fn(module, input, output): features.append(output.cpu().detach()) handle = model._modules[layer_name].register_forward_hook(hook_fn) img = transforms.ToTensor()(plt.imread('cat.jpg'))[None, :] # 输入图像 _ = model(img) handle.remove() # 绘制前8个特征图 fig, axes = plt.subplots(2, 4, figsize=(12, 6)) for i in range(8): axes[i//4, i%4].imshow(features[0][0,i], cmap='gray') - 特征图反卷积:通过反卷积网络(如DeconvNet)将高层特征图映射回像素空间,直观显示特征对应的输入区域(代表工具:DeconvNet、CAM(类激活图))。
- CAM变种:Grad-CAM(使用梯度加权)、Score-CAM(使用特征图加权),适用于无全连接层的模型(如CNN+GAP)。
- 直接可视化:提取层输出,缩放到[0,255]后保存为图像(适用于低维特征图,如CNN的前几层)。
- 特征向量降维可视化:
- 对高维特征(如词嵌入、CNN全连接层输出)使用PCA、t-SNE、UMAP降维后绘制散点图,观察类别可分性。
# 使用UMAP可视化BERT的句子嵌入 from transformers import BertTokenizer, BertModel import umap import numpy as np tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertModel.from_pretrained('bert-base-uncased') texts = ["I love AI", "I hate boring tasks", "This is a test"] inputs = tokenizer(texts, padding=True, truncation=True, return_tensors='pt') outputs = model(**inputs).last_hidden_state.mean(dim=1) # 句子嵌入 reducer = umap.UMAP(n_components=2) embeddings_2d = reducer.fit_transform(outputs.detach().numpy()) plt.scatter(embeddings_2d[:,0], embeddings_2d[:,1], c=['blue', 'red', 'green'])
- 特征图可视化:

在此推荐一篇文章实际例子
Pytorch特征可视化实例(热力图)
3. 参数可视化
- 目标:分析权重矩阵分布、初始化合理性、更新趋势。
- 适用场景:
- 诊断参数初始化问题(如全零/全一初始化导致对称性破缺)。
- 观察训练中参数是否更新(如冻结层的权重应保持不变)。
- 技术方法:
- 权重矩阵可视化:
- 将卷积核、全连接层权重绘制成热力图,观察参数分布(如是否接近高斯分布、是否存在离群值)。
# 可视化卷积核(假设第一层为Conv2d) conv_layer = model.conv1 # 假设模型第一层是卷积层 weights = conv_layer.weight.detach().cpu() # 形状为[out_channels, in_channels, kernel_h, kernel_w] # 对输入通道求平均,绘制每个输出通道的卷积核 for i in range(weights.shape[0]): kernel = weights[i].mean(dim=0) # 对输入通道求平均,得到单通道核 plt.subplot(2, 4, i+1) plt.imshow(kernel, cmap='viridis') plt.title(f'Kernel {i}') - 参数更新监控:
- 记录训练过程中参数的范数(如L2范数)、梯度均值/方差,通过曲线观察更新稳定性(工具:TensorBoard、Weights & Biases)。
# PyTorch中记录参数范数到TensorBoard from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter() for epoch in range(num_epochs): for name, param in model.named_parameters(): writer.add_scalar(f'weights/{name}_norm', param.norm(), epoch) if param.grad is not None: writer.add_scalar(f'gradients/{name}_mean', param.grad.mean(), epoch)
- 权重矩阵可视化:
4. 注意力机制可视化
- 目标:解释Transformer类模型(如BERT、ViT)的决策逻辑,定位关键输入元素。
- 适用场景:
- 自然语言处理:分析句子中哪些词对分类结果影响最大(如情感分析中的“love”“hate”)。
- 计算机视觉:显示图像中模型关注的区域(如目标检测中的物体边界)。
- 技术方法:
- 多头注意力可视化:
- 提取注意力矩阵,按头(head)或层(layer)绘制热力图,数值越高表示相关性越强。
# 可视化BERT的注意力头(以第一层为例) inputs = tokenizer("Hello, my name is John", return_tensors='pt') outputs = model(**inputs, output_attentions=True) # 输出注意力权重 attentions = outputs.attentions[0] # 第一层注意力,形状为[batch, heads, seq_len, seq_len] head_idx = 0 # 选择第一个头 attn_map = attentions[0, head_idx].detach().cpu() # 形状[seq_len, seq_len] plt.matshow(attn_map, cmap='viridis') plt.xticks(range(len(inputs['input_ids'][0])), tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])) plt.yticks(range(len(inputs['input_ids'][0])), tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])) - 跨模态注意力可视化:
- 在多模态模型(如CLIP、ALBEF)中,可视化文本与图像区域的交互关系。
- 多头注意力可视化:
5. 数据与训练过程可视化
- 数据可视化:
- 图像/视频:绘制样本分布、增强后的效果对比(如旋转、缩放后的图像)。
- 文本:词频统计、句子长度分布、词嵌入空间聚类。
- 表格数据:特征相关性矩阵热力图、缺失值可视化(如用Seaborn的
heatmap)。
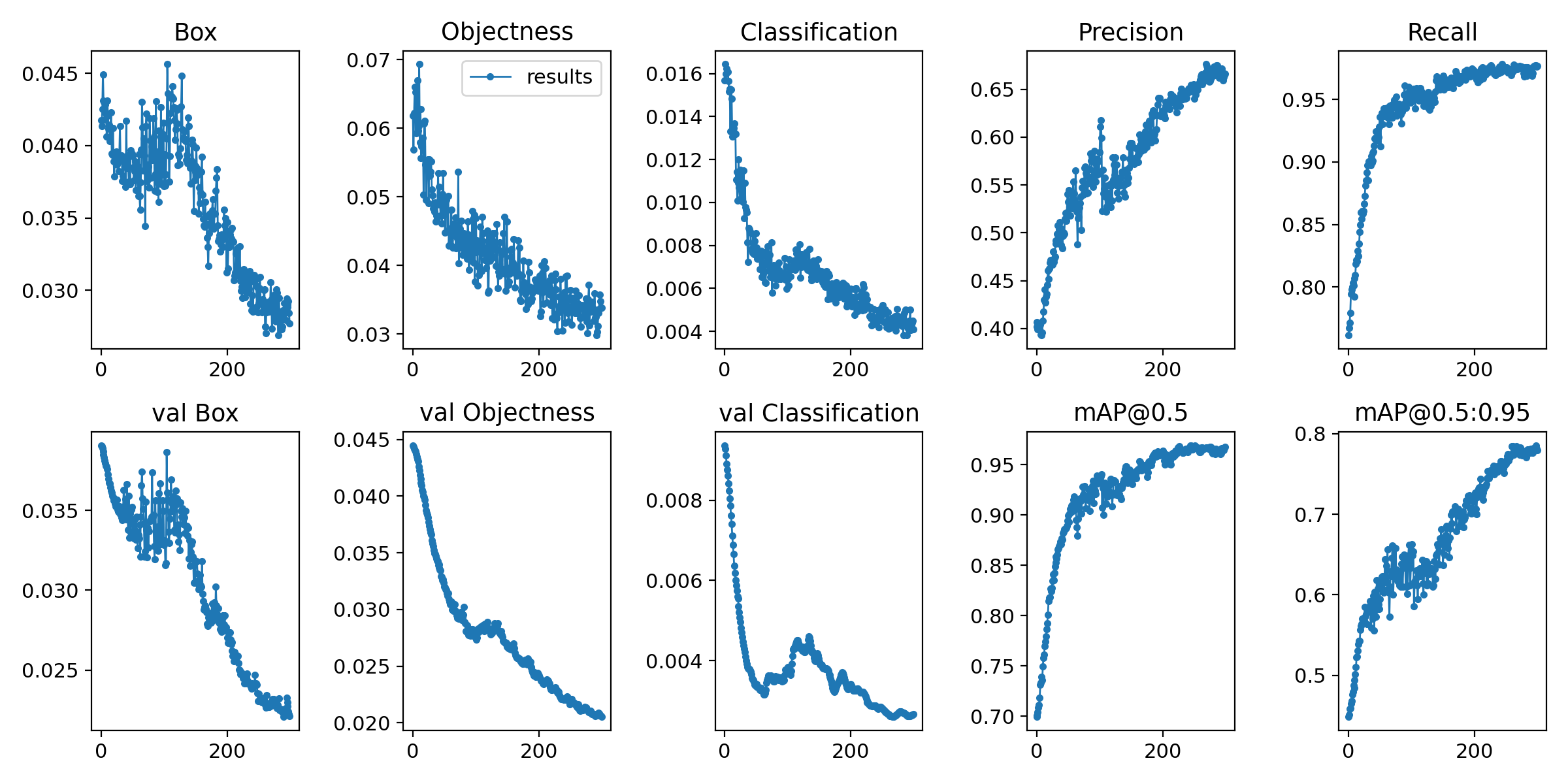
- 训练过程可视化:
- 核心指标:损失函数(训练/验证)、准确率/召回率、学习率曲线。
- 高级指标:混淆矩阵、F1分数、ROC-AUC曲线、样本预测概率分布。
- 工具:
- TensorBoard:支持标量、图像、直方图、PR曲线等,集成于TensorFlow/PyTorch(需配合
torch.utils.tensorboard)。 - Weights & Biases (W&B):云端可视化平台,支持超参数调优对比、模型版本管理。
- Visdom:PyTorch生态的实时可视化工具,适合动态监控训练。
- TensorBoard:支持标量、图像、直方图、PR曲线等,集成于TensorFlow/PyTorch(需配合
- 示例代码(TensorBoard记录损失曲线):
writer = SummaryWriter(log_dir='runs/resnet50') for epoch in range(100): train_loss = train(model, train_loader) val_loss = validate(model, val_loader) writer.add_scalars('Loss', {'train': train_loss, 'val': val_loss}, epoch)
6. 模型解释性可视化
- 目标:用人类可理解的方式解释黑盒模型的预测结果。
- 技术方法:
- 局部解释:
- LIME(局部可解释模型无关解释):通过扰动输入样本,训练线性模型近似黑盒行为,可视化特征重要性。
- SHAP(SHapley Additive exPlanations):基于博弈论计算每个特征的贡献度,支持全局/局部解释,输出特征重要性排名、依赖图。
- 全局解释:
- 特征重要性直方图(如随机森林的
feature_importances_)。 - 决策树可视化(
graphviz绘制CART树结构)。
- 特征重要性直方图(如随机森林的
- 局部解释:
三、主流工具对比与选型
| 工具/库 | 核心功能 | 支持框架 | 优势 | 局限性 |
|---|---|---|---|---|
| Netron | 模型结构交互式可视化(支持ONNX/PyTorch等) | 跨框架 | 轻量、多格式兼容、浏览器端交互 | 仅支持结构,不涉及训练过程 |
| TensorBoard | 训练指标、特征图、计算图可视化 | TensorFlow/PyTorch | 深度集成、功能全面 | 配置较繁琐,实时性一般 |
| Weights & Biases | 实验跟踪、可视化、超参数调优 | 全框架 | 云端协作、美观图表 | 免费版有存储限制 |
| Visdom | 实时数据可视化(标量、图像、3D) | PyTorch | 实时更新、自定义程度高 | 学习成本较高,社区支持较少 |
| PyTorch Lightning + Logger | 统一日志接口(支持TensorBoard/W&B等) | PyTorch Lightning | 模块化设计,简化日志配置 | 依赖Lightning框架 |
| Matplotlib/Seaborn | 基础绘图(特征图、统计图表) | 全框架 | 高度自定义、灵活性强 | 非交互式,需编写代码 |
四、高级技巧与前沿方向
- 3D可视化
- 用
plotly或matplotlib的3D模块可视化3D卷积层特征、点云数据的特征分布。
- 用
- 交互式可视化
- 使用
ipywidgets在Jupyter中添加滑动条、按钮等控件,动态调整可视化参数(如选择不同的注意力头)。
- 使用
- 模型压缩可视化
- 对比剪枝前后的模型结构(如Netron显示层删除)、参数稀疏性热力图(用
sparse库绘制权重矩阵的零值分布)。
- 对比剪枝前后的模型结构(如Netron显示层删除)、参数稀疏性热力图(用
- 对抗样本可视化
- 绘制原始样本与对抗样本的差异图(像素级变化),分析模型鲁棒性弱点。
- 多模态可视化
- 在图文检索模型中,可视化文本嵌入与图像特征在联合空间中的距离分布(如用UMAP降维后标注文本-图像对)。
五、最佳实践与注意事项
- 分层调试策略
- 先可视化输入数据确保预处理正确,再逐层检查特征图,最后分析参数更新和注意力分布。
- 计算资源优化
- 对大模型(如千亿参数的Transformer),采样部分层或头进行可视化,避免内存溢出。
- 结果解读陷阱
- 特征图有响应≠特征有效(需结合任务目标判断,如边缘检测对分类可能不重要)。
- 注意力高≠因果关系(可能是虚假相关性,需结合领域知识验证)。
- 版本管理
- 保存可视化配置脚本(如Jupyter Notebook),便于复现不同训练阶段的结果。
六、典型场景案例
案例1:图像分类模型调优
- 问题:ResNet50在CIFAR-10上准确率停滞在70%。
- 可视化步骤:
- 结构检查:用Netron确认残差连接正确,无层顺序错误。
- 特征图分析:发现高层卷积层特征图模糊,怀疑激活函数饱和→更换ReLU为Swish。
- 梯度监控:用TensorBoard发现浅层梯度消失→增加跳跃连接数量。
- 结果:准确率提升至85%。
案例2:NLP模型可解释性
- 任务:分析BERT对“这部电影虽然剧情简单,但演员演技出色”的情感分类(正向/负向)。
- 可视化方法:
- 注意力热力图:显示“演技出色”对应的词与分类令牌(
[CLS])的注意力权重最高。 - SHAP值:“出色”“演技”的正贡献值最大,“简单”的负贡献被“但”转折词抵消。
- 注意力热力图:显示“演技出色”对应的词与分类令牌(
七、总结
深度学习模型可视化是连接理论设计与工程实践的桥梁,其核心在于分层拆解问题(从结构→层→参数→数据→决策逻辑)和工具链整合(根据场景选择Netron、TensorBoard、W&B等)。随着可解释AI(XAI)的重要性提升,未来可视化技术将更注重交互式分析(如实时参数调整)和跨模态融合(如图文联合解释),帮助研究者和工程师更高效地理解复杂模型。