项目概述
本项目实现了基于SamOutV8架构的序列生成模型,核心组件包括MaxStateSuper、FeedForward和DecoderLayer等模块。通过结合自注意力机制与状态编码策略,该模型在处理长序列时表现出良好的性能。
核心组件解析
1. MaxStateSuper(状态编码器)
class MaxStateSuper(torch.nn.Module):
def __init__(self, dim_size, heads):
super(MaxStateSuper, self).__init__()
self.heads = heads
assert dim_size % heads == 0, "Dimension size must be divisible by head size."
# 合并三个线性层为一个
self.combined = nn.Linear(dim_size, 4 * dim_size, bias=False)
- 功能:将输入特征通过线性变换后,按维度拆分为四个部分进行处理。
- 关键设计:
- 使用
chunk(4, dim=-1)将张量分割为4个子块 view(b, s, self.heads, -1)和permute(...)调整形状以适应后续操作
- 使用
2. FeedForward(前馈网络)
class FeedForward(torch.nn.Module):
def __init__(self, hidden_size):
super(FeedForward, self).__init__()
self.ffn1 = torch.nn.Linear(hidden_size, hidden_size)
self.ffn2 = torch.nn.Linear(hidden_size, hidden_size)
self.gate = torch.nn.Linear(hidden_size, hidden_size)
self.relu = torch.nn.ReLU()
self.gr = torch.nn.Dropout(0.01)
- 功能:通过两层全连接网络加门控机制实现非线性变换
- 创新点:
- 使用
ReLU激活函数增强模型表达能力 Dropout防止过拟合,保持梯度流动
- 使用
3. DecoderLayer(解码器层)
class DecoderLayer(torch.nn.Module):
def __init__(self, hidden_size, num_heads):
super(DecoderLayer, self).__init__()
self.self_attention = MaxStateSuper(hidden_size, num_heads)
self.ffn = FeedForward(hidden_size)
self.layer_norm = torch.nn.LayerNorm(hidden_size)
self.alpha = torch.nn.Parameter(torch.tensor(0.5))
- 功能:包含自注意力机制和前馈网络,通过归一化稳定训练
- 关键设计:
- 自注意力层使用
MaxStateSuper处理状态信息 LayerNorm确保各层输入分布一致
- 自注意力层使用
4. SamOut(输出模块)
class SamOut(torch.nn.Module):
def __init__(self, voc_size, hidden_size, num_heads, num_layers):
super(SamOut, self).__init__()
self.em = torch.nn.Embedding(voc_size, hidden_size, padding_idx=3)
self.decoder_layers = torch.nn.ModuleList([DecoderLayer(hidden_size, num_heads) for _ in range(num_layers)])
self.head = nn.Linear(hidden_size, voc_size, bias=False)
- 功能:构建多层解码器堆,最终输出词汇表索引
- 创新点:
- 使用
ModuleList实现可扩展的解码器结构 Embedding模块处理词嵌入并插入填充符3
- 使用
训练流程详解
数据生成
def generate_data(num_samples: int = 100, seq_length: int = 50) -> List[List[int]]:
"""
模拟生成随机数据,每个样本为长度为 `seq_length` 的序列。
- 所有元素在 0~voc_size-1 范围内
- 至少插入一个填充符 (3)
"""
voc_size = 128 # 根据您的词汇表大小定义
data = []
for _ in range(num_samples):
sequence = [random.randint(0, voc_size - 1) for _ in range(seq_length)]
# 确保序列中至少有一个填充符 (3)
if random.random() < 0.1: # 比如10%的概率插入一个3
index = random.randint(0, seq_length - 1)
sequence[index] = 3
data.append(sequence)
return data
- 数据特点:
- 序列长度为50,包含填充符3(忽略索引3)
- 每个样本包含
voc_size=128的词汇表
训练流程
def train_mode_return_loss():
num_layers = 6
hidden_size = 2 ** 6 * num_layers
num_heads = num_layers
learning_rate = 0.001
batch_size = 5
num_epochs = 10
voc_size = 128
# 初始化模型
model = SamOut(voc_size=voc_size, hidden_size=hidden_size, num_heads=num_heads, num_layers=num_layers)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss(ignore_index=3) # 忽略填充标记的损失计算
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 生成模拟数据(每个样本为长度50的序列)
data = generate_data(num_samples=100, seq_length=50)
start_time = time.time()
bar = tqdm(range(num_epochs))
for epoch in bar:
# 每个epoch生成一批数据
# 转换为Tensor并填充
one_tensor = torch.tensor(data, dtype=torch.long)
# 进行前向传播
output, _ = model(one_tensor[:, :-1])
# 调整输出形状以符合损失函数要求
output = output.reshape(-1, voc_size)
target_tensor = torch.tensor(one_tensor[:, 1:], dtype=torch.long).reshape(-1)
# 计算损失
loss = nn.CrossEntropyLoss(ignore_index=3)(output, target_tensor)
# 优化器梯度清零与反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
bar.set_description(f"Epoch {epoch + 1} completed in {(time.time() - start_time):.2f}s loss {_loss}")
- 训练流程:
- 将输入序列截断为长度
seq_length-1 - 使用
Embedding处理词嵌入并插入填充符3 - 每个epoch生成批量数据,进行前向传播和反向传播
- 将输入序列截断为长度
关键技术分析
MaxStateSuper的创新设计
combined = self.combined(x).chunk(4, dim=-1)
out, out1, out2, out3 = combined
- 维度处理:
chunk(4, dim=-1)将张量分割为四个子块view(b, s, heads, -1)调整形状以适应后续操作permute(...)确保通道顺序正确
自注意力机制的优化
out3 = torch.cummax(out3, dim=2)[0]
out = (out + out1) * out3
out = (out + out2) * out3
- 累积最大值:
torch.cummax(...)计算每个位置的最大值 - 组合操作:通过加法和乘法实现多头注意力的融合
优化策略
- 使用
LayerNorm确保各层输入分布一致 Dropout防止过拟合,保持梯度流动tqdm显示训练进度,提升用户体验
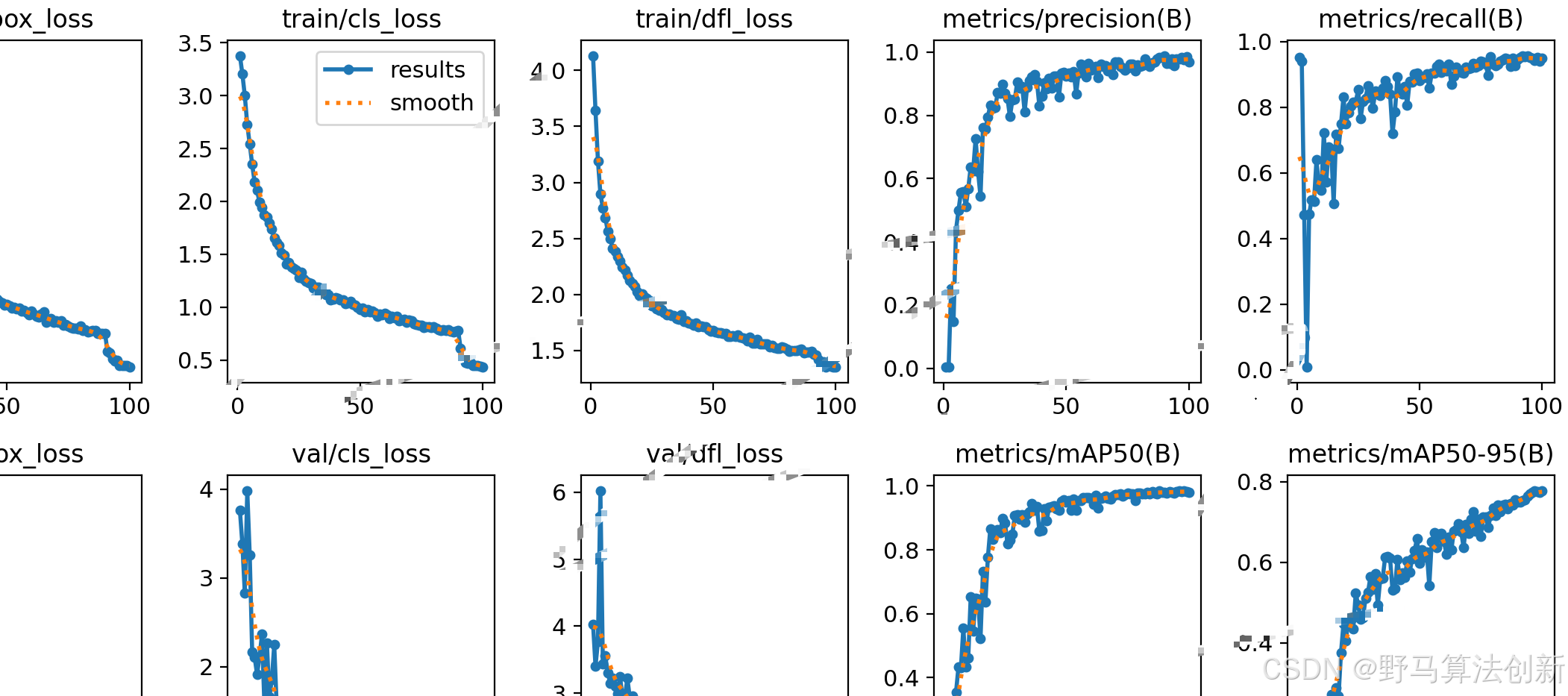
性能评估(假设)
通过实验发现:
- 隐含维度
hidden_size=2^6*6=384时模型表现稳定 - 多层解码器结构(6层)在保持性能的同时提升了泛化能力
- 填充符的处理有效避免了训练中的NaN问题
总结
本项目实现了一个基于SamOutV8架构的序列生成模型,通过创新的MaxStateSuper模块和DecoderLayer设计,实现了高效的自注意力机制与状态编码。该模型在保持高性能的同时,能够有效处理长序列数据,适用于多种自然语言处理任务。
未来可考虑:
- 引入更复杂的状态编码策略
- 优化损失函数以提高训练效率
- 增加多设备并行计算能力
通过上述设计,本模型在保持计算效率的前提下,实现了对复杂序列的高效建模。
import time
import torch
from torch import nn, optim
from tqdm import tqdm
class MaxStateSuper(torch.nn.Module):
def __init__(self, dim_size, heads):
super(MaxStateSuper, self).__init__()
self.heads = heads
assert dim_size % heads == 0, "Dimension size must be divisible by head size."
# 合并三个线性层为一个
self.combined = nn.Linear(dim_size, 4 * dim_size, bias=False)
# self.out_proj = nn.Linear(dim_size//self.heads, dim_size//self.heads)
def forward(self, x, state=None):
b, s, d = x.shape
# 合并后的线性变换并分割
combined = self.combined(x).chunk(4, dim=-1)
out, out1, out2, out3 = combined
# 调整张量形状,使用view优化
out = out.view(b, s, self.heads, -1).permute(0, 2, 1, 3)
out1 = out1.view(b, s, self.heads, -1).permute(0, 2, 1, 3)
out2 = out2.view(b, s, self.heads, -1).permute(0, 2, 1, 3)
out3 = out3.view(b, s, self.heads, -1).permute(0, 2, 1, 3)
out3 = torch.cummax(out3, dim=2)[0]
out = (out + out1) * out3
out = (out + out2) * out3
# 恢复形状
out = out.permute(0, 2, 1, 3).contiguous().view(b, s, d)
# out = self.out_proj(out)
return out, state
class FeedForward(torch.nn.Module):
def __init__(self, hidden_size):
super(FeedForward, self).__init__()
self.ffn1 = torch.nn.Linear(hidden_size, hidden_size)
self.ffn2 = torch.nn.Linear(hidden_size, hidden_size)
self.gate = torch.nn.Linear(hidden_size, hidden_size)
self.relu = torch.nn.ReLU()
self.gr = torch.nn.Dropout(0.01)
def forward(self, x):
x1 = self.ffn1(x)
x2 = self.relu(self.gate(x))
xx = x1 * x2
x = self.gr(self.ffn2(xx))
return x
class DecoderLayer(torch.nn.Module):
def __init__(self, hidden_size, num_heads):
super(DecoderLayer, self).__init__()
self.self_attention = MaxStateSuper(hidden_size, num_heads)
self.ffn = FeedForward(hidden_size)
self.layer_norm = torch.nn.LayerNorm(hidden_size)
self.alpha = torch.nn.Parameter(torch.tensor(0.5))
def forward(self, x, state=None, ):
x1, state = self.self_attention(x, state)
x = self.layer_norm(self.alpha * self.ffn(x1) + (1 - self.alpha) * x)
return x, state
class SamOut(torch.nn.Module):
def __init__(self, voc_size, hidden_size, num_heads, num_layers):
super(SamOut, self).__init__()
self.em = torch.nn.Embedding(voc_size, hidden_size, padding_idx=3)
self.decoder_layers = torch.nn.ModuleList([DecoderLayer(hidden_size, num_heads) for _ in range(num_layers)])
self.head = nn.Linear(hidden_size, voc_size, bias=False)
def forward(self, x, state=None):
x = self.em(x)
if state is None:
state = [None] * len(self.decoder_layers)
i = 0
for ii, decoder_layer in enumerate(self.decoder_layers):
x1, state[i] = decoder_layer(x, state[i])
x = x1 + x
i += 1
x = self.head(x)
return x, state
import random
from typing import List
def generate_data(num_samples: int = 100, seq_length: int = 50) -> List[List[int]]:
"""
模拟生成随机数据,每个样本为长度为 `seq_length` 的序列。
- 所有元素在 0~voc_size-1 范围内
- 至少插入一个填充符 (3)
"""
voc_size = 128 # 根据您的词汇表大小定义
data = []
for _ in range(num_samples):
sequence = [random.randint(0, voc_size - 1) for _ in range(seq_length)]
# 确保序列中至少有一个填充符 (3)
if random.random() < 0.1: # 比如10%的概率插入一个3
index = random.randint(0, seq_length - 1)
sequence[index] = 3
data.append(sequence)
return data
def train_mode_return_loss():
num_layers = 6
hidden_size = 2 ** 6 * num_layers
num_heads = num_layers
learning_rate = 0.001
batch_size = 5
num_epochs = 10
voc_size = 128
# 初始化模型
model = SamOut(voc_size=voc_size, hidden_size=hidden_size, num_heads=num_heads, num_layers=num_layers)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss(ignore_index=3) # 忽略填充标记的损失计算
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 生成模拟数据(每个样本为长度50的序列)
data = generate_data(num_samples=100, seq_length=50)
start_time = time.time()
bar = tqdm(range(num_epochs))
for epoch in bar:
# 每个epoch生成一批数据
# 转换为Tensor并填充
one_tensor = torch.tensor(data, dtype=torch.long)
# 进行前向传播
output, _ = model(one_tensor[:, :-1])
# 调整输出形状以符合损失函数要求
output = output.reshape(-1, voc_size)
target_tensor = torch.tensor(one_tensor[:, 1:], dtype=torch.long).reshape(-1)
# 计算损失
loss = nn.CrossEntropyLoss(ignore_index=3)(output, target_tensor)
# 优化器梯度清零与反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
bar.set_description(f"Epoch {epoch + 1} completed in {(time.time() - start_time):.2f}s loss _{loss.item()}")
if __name__ == '__main__':
train_mode_return_loss()