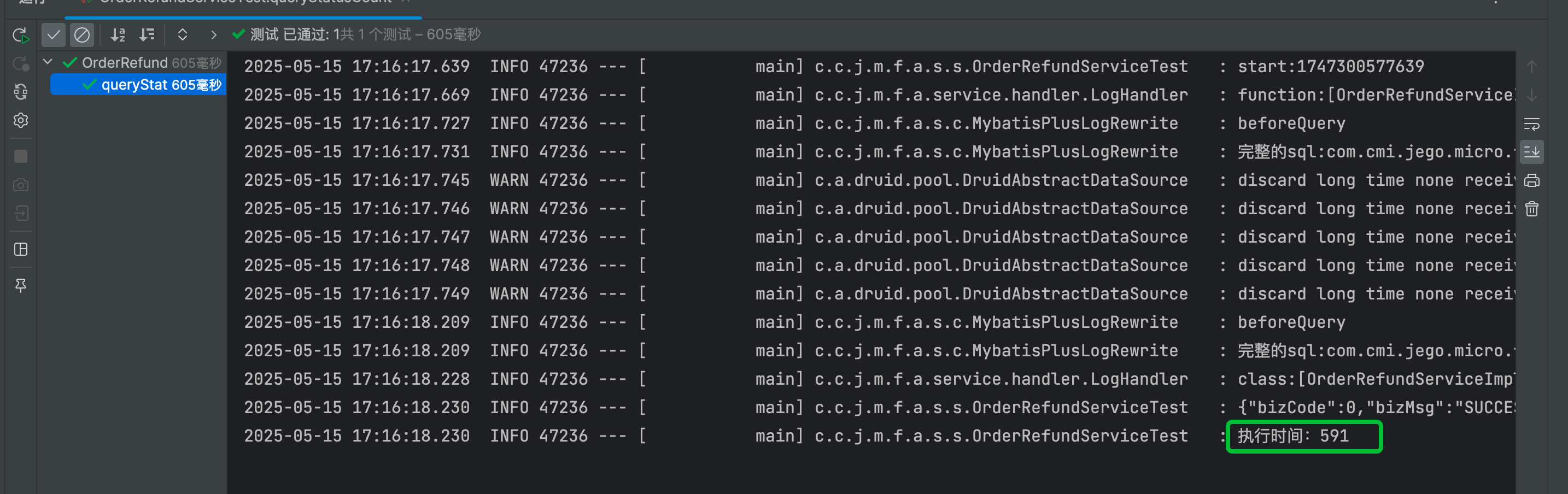
本文聚焦如何通过 Kafka + Flink + Spark 构建一套稳定、可扩展、可插拔的实时数仓体系。覆盖从数据接入、实时清洗、指标计算,到离线补数、数据一致性保障的完整链路设计,结合实践样例提供可复制的落地方法。
🧱 一、架构总览
┌────────────┐
│ 数据源 │
│ CDC / API │
└────┬───────┘
│
[Kafka 多 Topic]
│
┌────────┴─────────┐
│ │
┌─────▼──────┐ ┌──────▼──────┐
│ Flink 实时层 │ │ Spark 离线层 │
│ - 数据清洗 │ │ - 离线补数 │
│ - 字段标准化 │ │ - 全量快照 │
│ - 指标聚合 │ │ - 批量校验 │
└─────┬──────┘ └──────┬──────┘
│ │
└────┬─────────────┘
│
┌────▼────┐
│ DWD/DWS │ ← 分层输出
└────┬────┘
│
┌───▼────┐
│