目录
Langchain是什么?
LangSmith是什么?
编辑
使用Python构建并使用AI大模型
数据解析器
提示模版
部署
记忆功能
Chat History -- 记忆
代码执行流程:
流式输出
构建向量数据库和检索器
检索器
代码执行流程
LLM使用检索器来对文档检索
构建代理
构建RAG的对话应用
读取数据库
检索YouTube视频字幕
提取结构化的数据
AI自动生成数据
Langchain是什么?
LangChain 是一个用于构建和部署基于语言模型(如 OpenAI 的 GPT 系列)的应用程序的框架。它旨在简化与大型语言模型(LLMs)的交互,并提供工具和组件,帮助开发者更高效地构建复杂的应用,如对话系统、知识库问答、文本生成等。
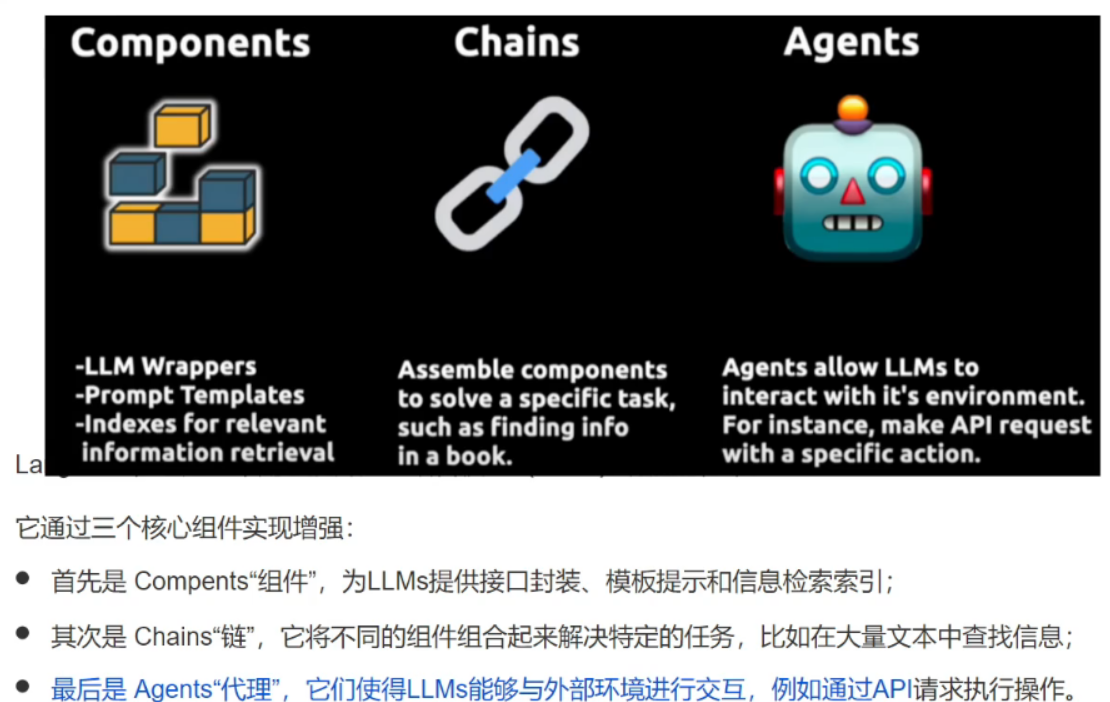
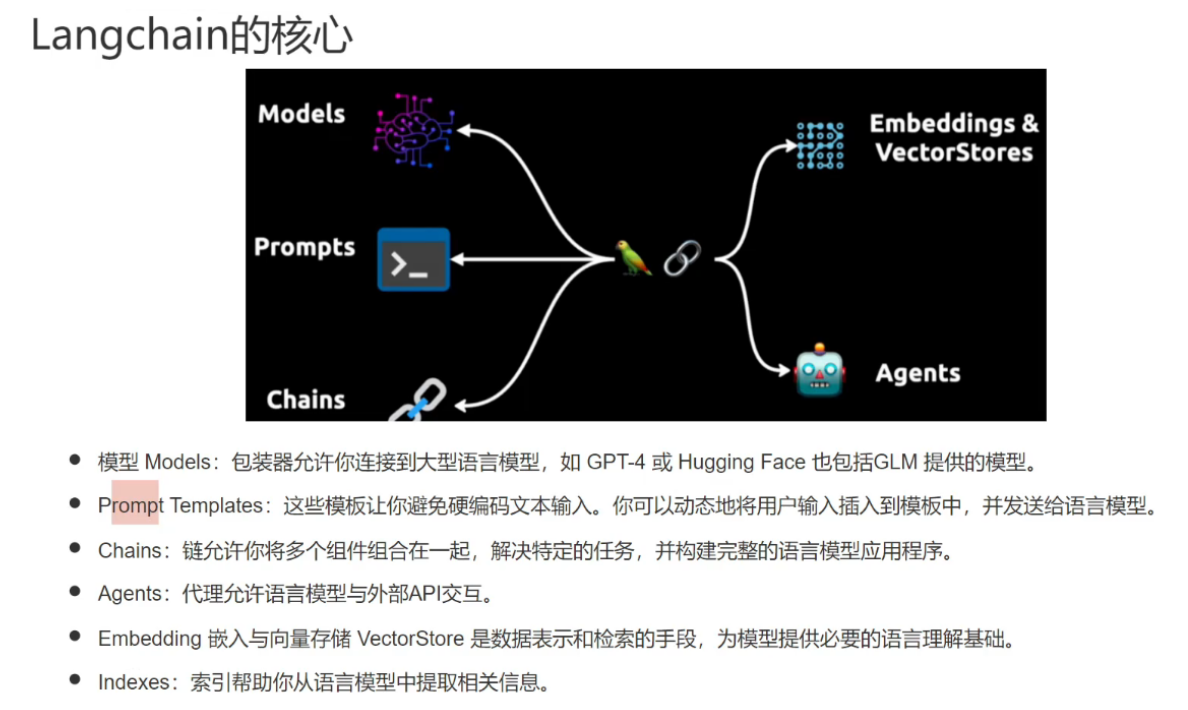
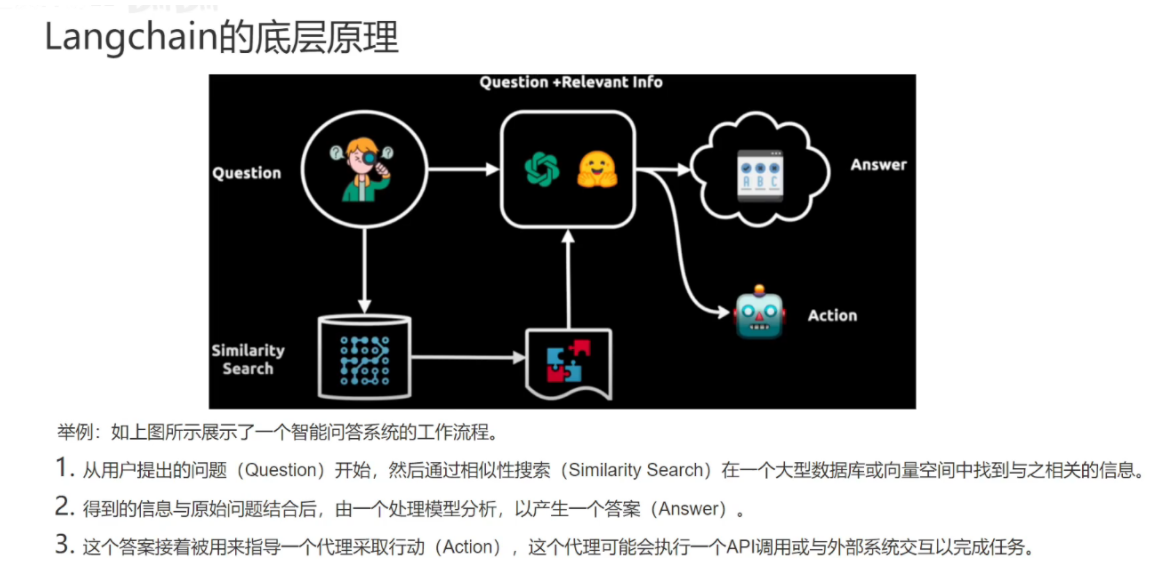
下面是Langchain链接:LangSmith
点击 Create an API Key 创建Key。
LangSmith是什么?

使用Python构建并使用AI大模型
下面是安装命令:
pip install langchain
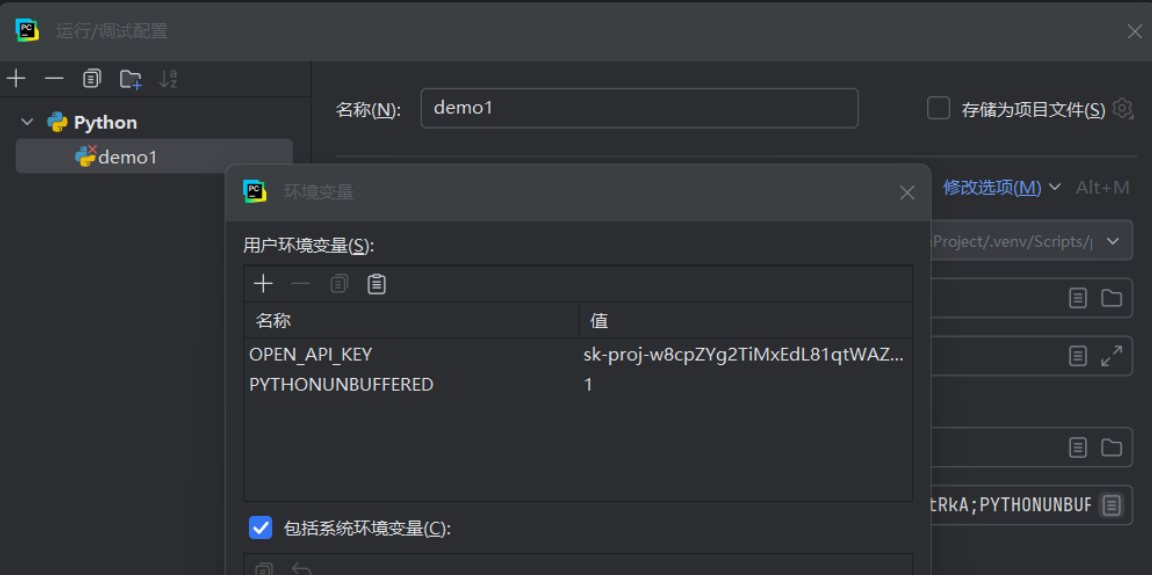
pip install langchain-openai然后再打开编辑配置,在环境配置中输入 OPENAI(想要调用的AI大模型的API_KEY) 的 key:
(也可以在代码中使用 api_key="" 去声明)
下面这段代码使用openai的大模型进行访问:
import os
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "输入LANGCHAIN_API_KEY"
# 调用大语言模型
model = ChatOpenAI(model='gpt-3.5-turbo', api_key="输入OPENAI_API_KEY") # 模型名称
msg = [
SystemMessage(content='请将以下内容翻译成日语'),
HumanMessage(content='你好,请问你要去哪里?') # 问题
]
result = model.invoke(msg) # 模型调用
print(result) # 输出模型分析的结果数据解析器
我们的输出结果可以更精进一些,加入数据解析器以此来直接输出结果:
(这里也可以使用链chain来调用,前提是这些对象类型是Runnable)
import os
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
# os.environ['http_proxy'] = '127.0.0.1:8118'
# os.environ['https_proxy'] = '127.0.0.1:8118'
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 启用 LangChain 的追踪功能。
os.environ["LANGCHAIN_API_KEY"] = "输入LANGCHAIN_API_KEY"
# 调用大语言模型
model = ChatOpenAI(model='gpt-3.5-turbo', api_key="输入OPENAI_API_KEY") # 模型名称
#################################################################
msg = [
SystemMessage(content='请将以下内容翻译成日语'),
HumanMessage(content='你好,请问你要去哪里?') # 问题
]
result = model.invoke(msg) # 模型调用
# 解析模型响应的数据
parser = StrOutputParser() # 创建返回的数据解析器
return_str = parser.invoke(result)
print(return_str)
# 也可以使用链来解析数据
# 得到链
chain = model | parser
# 直接使用chain来调用
print(chain.invoke(msg))下面介绍如何使用Langchain实现LLM应用程序:
提示模版
首先使用提示模版 PromptTemplate 来实现LLM:
import os
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "输入LANGCHAIN_API_KEY"
# 初始化大语言模型
model = ChatOpenAI(model='gpt-3.5-turbo', api_key="输入OPENAI_API_KEY") # 模型名称
#################################################################
# 解析模型响应的数据
parser = StrOutputParser() # 创建返回的数据解析器
# 定义提示模版
prompt_template = ChatPromptTemplate.from_messages([
('system', '请将以下内容翻译成{language}'),
('user',"text")
])
# 使用链来解析数据
# 得到链
chain = prompt_template | model | parser
# 直接使用chain来调用
print(chain.invoke({'language': 'English', 'text': '你好,请问你要去哪里?'}))部署
然后使用 LangServe 部署LLM:
在部署前需要运行下面命令安装 langserve:(如果安装不上就要把翻墙软件关闭)
pip install "langserve[all]"import os
from langserve import add_routes
from fastapi import FastAPI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 启用 LangChain 的追踪功能。
os.environ["LANGCHAIN_API_KEY"] = "输入LANGCHAIN_API_KEY"
# 初始化大语言模型
model = ChatOpenAI(model='gpt-3.5-turbo', api_key="输入OPENAI_API_KEY") # 模型名称
#################################################################
# 解析模型响应的数据
parser = StrOutputParser() # 创建返回的数据解析器
# 定义提示模版
prompt_template = ChatPromptTemplate.from_messages([
('system', '请将以下内容翻译成{language}'),
('user',"text")
])
# 使用链来解析数据
# 得到链
chain = prompt_template | model | parser
# 把我们的程序部署成服务
# 创建fastAPI的应用
app = FastAPI(title='我的Langchain服务', version='v1.0', description='使用Langchain翻译')
#添加路由
add_routes(
app,
chain,
path="/chainDemo"
)
if __name__ == '__main__':
import uvicorn
uvicorn.run(app, host='localhost', port=8000)然后我们可以再ApiPost测试:(注意!!!数据必须是 application/json 格式)
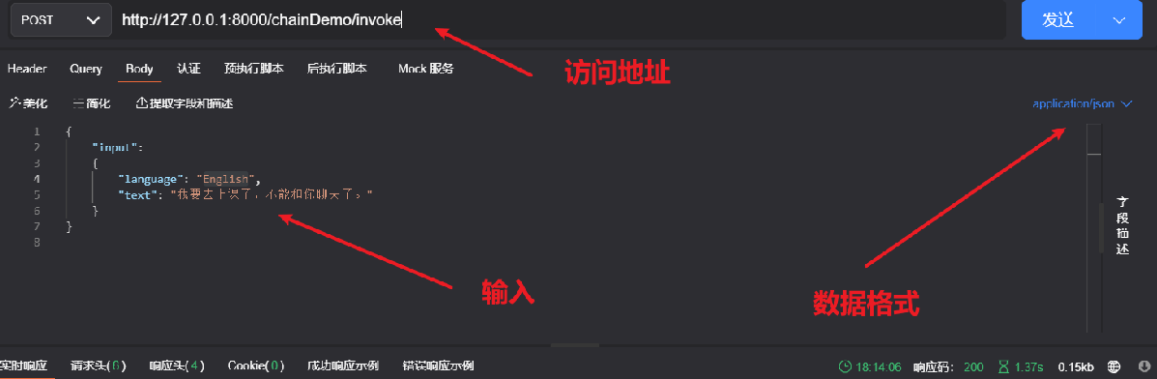
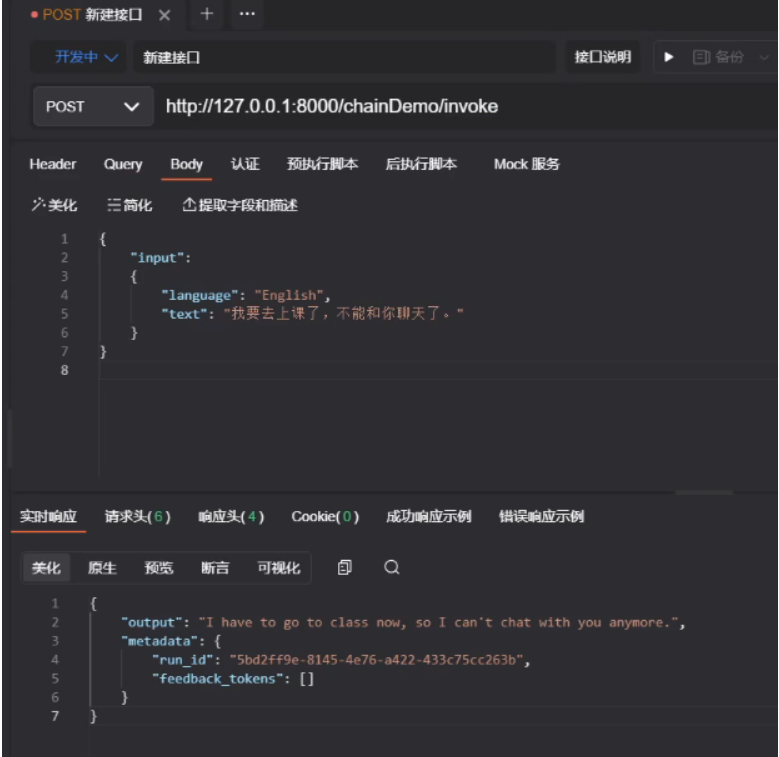
也可以编写代码去调用:
from langserve import RemoteRunnable
if __name__ == '__main__':
client = RemoteRunnable('http://127.0.0.1:8000/chainDemo/')
client.invoke({'language': 'English', 'text': '你好,请问你要去哪里?'})记忆功能
我们需要让这个聊天机器人能够进行对话并记住之前的互动。
需要安装:
pip install langchain_communityChat History -- 记忆
Chat History:它允许聊天机器人“记住”过去的互动,支持多轮对话,能够保存和管理聊天历史,并在回应后续问题时考虑它们。
代码执行流程:
下面是完整代码:
import os
from langchain_core.messages import HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 启用 LangChain 的追踪功能。
os.environ["LANGCHAIN_API_KEY"] = "输入LANGCHAIN_API_KEY"
# 调用大语言模型
model = ChatOpenAI(model='gpt-3.5-turbo', api_key="输入OPENAI_API_KEY") # 模型名称
#################################################################
# 聊天机器人案例
# 定义提示模版
prompt_template = ChatPromptTemplate.from_messages([
('system', '你是一个乐于助人的助手,用{language}尽你所能回答所有问题。'),
MessagesPlaceholder(variable_name='my_msg') # 历史消息记录,去掉后可以将模型变成单轮对话
])
# 使用链来解析数据
# 得到链
chain = prompt_template | model
# 保存历史聊天记录
store = {} # 所有用户的聊天记录都保存在store。 key: sessionId,value: 历史聊天记录对象
# 此函数预期将接收一个session_id并返回一个消息历史记录对象
def get_session_history(session_id: str):
if session_id not in store:
store[session_id] = {}
return store[session_id]
# 创建带聊天历史的链
do_message = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key='my_msg', # 每次聊天时候发送msg的key
)
# config 字典定义了当前对话的 session_id,用于标识不同的用户会话。
config = {'configurable': {'session_id': 'zs123'}} # 给当前对话定义一个sessionId
######################################################
# 第一轮聊天
resp = do_message.invoke(
{
'my_msg': [HumanMessage(content='你好呀,我是Eleven')],
'language': '中文'
},
config=config,
)
print(resp.content)
######################################################
# 第二轮聊天
resp = do_message.invoke(
{
'my_msg': [HumanMessage(content='请问我的名字是什么?')],
'language': '中文'
},
config=config,
)
print(resp.content)流式输出
使用stream流来完成:
for resp in do_message.stream(
{
'my_msg': [HumanMessage(content='请问我的名字是什么?')],
'language': '中文'
},
config=config,
):
# 每一层resp都是一个token
print(resp.content, end='-') # 每一个token之间有一个"-"下面是完整代码:
import os
from langchain_core.messages import HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 启用 LangChain 的追踪功能。
os.environ["LANGCHAIN_API_KEY"] = "输入LANGCHAIN_API_KEY"
# 调用大语言模型
model = ChatOpenAI(model='gpt-3.5-turbo', api_key="输入OPENAI_API_KEY") # 模型名称
#################################################################
# 聊天机器人案例
# 定义提示模版
prompt_template = ChatPromptTemplate.from_messages([
('system', '你是一个乐于助人的助手,用{language}尽你所能回答所有问题。'),
MessagesPlaceholder(variable_name='my_msg') # 历史消息记录,去掉后可以将模型变成单轮对话
])
# 使用链来解析数据
# 得到链
chain = prompt_template | model
# 保存历史聊天记录
store = {} # 所有用户的聊天记录都保存在store。 key: sessionId,value: 历史聊天记录对象
# 此函数预期将接收一个session_id并返回一个消息历史记录对象
def get_session_history(session_id: str):
if session_id not in store:
store[session_id] = {}
return store[session_id]
do_message = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key='my_msg', # 每次聊天时候发送msg的key
)
# config 字典定义了当前对话的 session_id,用于标识不同的用户会话。
config = {'configurable': {'session_id': 'zs123'}} # 给当前对话定义一个sessionId
######################################################
# 第三轮聊天:返回的数据是流式的
for resp in do_message.stream(
{
'my_msg': [HumanMessage(content='请问我的名字是什么?')],
'language': '中文'
},
config=config,
):
# 每一层resp都是一个token
print(resp.content, end='-') # 每一个token之间有一个"-"
print(resp.content)构建向量数据库和检索器
支持从向量数据库和其他来源检索数据,以便与LLM(大型语言模型)工作流程集成。它们对于应用程序来说非常重要,这些应用程序需要获取数据以作为模型推理的一部分进行推理,就像检索增强生成(RAG)的情况一样需要安装 langchain-chroma:
pip install langchain-chromaChroma可以理解成Langchain内置的向量数据库。
我们可以先准备测试数据如下:
# 准备测试数据,假设我们提供的文档数据如下:
documents = [
Document(
page_content="狗是伟大的伴侣,以其忠诚和友好而闻名。",
metadata={"source": "哺乳动物宠物文档"},
),
Document(
page_content="猫是独立的宠物,通常喜欢自己的空间。",
metadata={"source": "哺乳动物宠物文档"},
),
Document(
page_content="金鱼是初学者的流行宠物,需要相对简单的护理。",
metadata={"source": "鱼类宠物文档"},
),
Document(
page_content="鹦鹉是聪明的鸟类,能够模仿人类的语言。",
metadata={"source": "鸟类宠物文档"},
),
Document(
page_content="兔子是社交动物,需要足够的空间跳跃。",
metadata={"source": "哺乳动物宠物文档"},
),
]其中 page_content 内放入一些论文文字,而 metadata 代表源数据(文档的摘要或文章的作者等),source是随意设置的一个key值。
然后我们就要对这个数据向量化,然后将其存储到向量数据库中:
import os
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 启用 LangChain 的追踪功能。
os.environ["LANGCHAIN_API_KEY"] = "输入LANGCHAIN_API_KEY"
# 调用大语言模型
model = ChatOpenAI(model='gpt-3.5-turbo', api_key="输入OPENAI_API_KEY") # 模型名称
#################################################################
# 准备测试数据,假设我们提供的文档数据如下:
documents = [
Document(
page_content="狗是伟大的伴侣,以其忠诚和友好而闻名。",
metadata={"source": "哺乳动物宠物文档"},
),
Document(
page_content="猫是独立的宠物,通常喜欢自己的空间。",
metadata={"source": "哺乳动物宠物文档"},
),
Document(
page_content="金鱼是初学者的流行宠物,需要相对简单的护理。",
metadata={"source": "鱼类宠物文档"},
),
Document(
page_content="鹦鹉是聪明的鸟类,能够模仿人类的语言。",
metadata={"source": "鸟类宠物文档"},
),
Document(
page_content="兔子是社交动物,需要足够的空间跳跃。",
metadata={"source": "哺乳动物宠物文档"},
),
]
# 实例化一个向量数据库(向量空间)
vector_store = Chroma.from_documents(documents, embedding=OpenAIEmbeddings()) # 参数(文档,向量化技术)
# 相似度查询:返回相似的分值,分数越低相似度越高
print(vector_store.similarity_search_with_score('咖啡猫'))检索器
# 实例化一个向量数据库(向量空间)
vector_store = Chroma.from_documents(documents, embedding=OpenAIEmbeddings()) # 参数(文档,向量化技术)
# 相似度查询:返回相似的分值,分数越低相似度越高
print(vector_store.similarity_search_with_score('咖啡猫'))
# 创建检索器,bind(k=1)返回相似度最高的第一个
# 将方法包装成一个可执行的任务链,并通过 bind(k=1) 设置每次只返回相似度最高的一个结果。
retriever = RunnableLambda(vector_store.similarity_search).bind(k=1)
# 批量查询,对多个查询词("咖啡猫" 和 "鲨鱼")进行批量匹配,返回每个查询词的最相似文档
retriever.batch(['咖啡猫','鲨鱼']) 代码执行流程
下面是完整代码:
import os
from warnings import simplefilter
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 启用 LangChain 的追踪功能。
os.environ["LANGCHAIN_API_KEY"] = "输入LANGCHAIN_API_KEY"
# 调用大语言模型
model = ChatOpenAI(model='gpt-3.5-turbo', api_key="输入OPENAI_API_KEY") # 模型名称
#################################################################
# 准备测试数据,假设我们提供的文档数据如下:
documents = [
Document(
page_content="狗是伟大的伴侣,以其忠诚和友好而闻名。",
metadata={"source": "哺乳动物宠物文档"},
),
Document(
page_content="猫是独立的宠物,通常喜欢自己的空间。",
metadata={"source": "哺乳动物宠物文档"},
),
Document(
page_content="金鱼是初学者的流行宠物,需要相对简单的护理。",
metadata={"source": "鱼类宠物文档"},
),
Document(
page_content="鹦鹉是聪明的鸟类,能够模仿人类的语言。",
metadata={"source": "鸟类宠物文档"},
),
Document(
page_content="兔子是社交动物,需要足够的空间跳跃。",
metadata={"source": "哺乳动物宠物文档"},
),
]
# 实例化一个向量数据库(向量空间)
vector_store = Chroma.from_documents(documents, embedding=OpenAIEmbeddings()) # 参数(文档,向量化技术)
# 相似度查询:返回相似的分值,分数越低相似度越高
print(vector_store.similarity_search_with_score('咖啡猫'))
# 创建检索器,bind(k=1)返回相似度最高的第一个
# 将方法包装成一个可执行的任务链,并通过 bind(k=1) 设置每次只返回相似度最高的一个结果。
retriever = RunnableLambda(vector_store.similarity_search).bind(k=1)
# 批量查询,对多个查询词("咖啡猫" 和 "鲨鱼")进行批量匹配,返回每个查询词的最相似文档
retriever.batch(['咖啡猫','鲨鱼']) LLM使用检索器来对文档检索
在上面我们讲述了创建文档以及构建向量空间,但是我们还没有将文档和LLM联合起来,所以我们需要将给定的问题与检索到的上下文要结合起来:
首先定义一个提示模版:
message = """
使用提供的上下文仅回答这个问题:
{question}
上下文:
{content}
"""之后创建一个 ChatPromptTemplate 对象,用于定义聊天模型的输入提示:
prompt_temp = ChatPromptTemplate.from_messages([('human', message)])在然后创建一个字典,用于构建一个任务链(chain):
chain = {'question': RunnablePassthrough(), 'context': retriever}在上面使用 RunnablePassthrough()方法允许之后将用户的问题传入再传给prompt和model。
最后在调用任务链 chain,并传入用户输入 '请给我介绍一下猫' 作为问题:
resp = chain.invoke('请给我介绍一下猫')下面是完整代码
import os
from warnings import simplefilter
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 启用 LangChain 的追踪功能。
os.environ["LANGCHAIN_API_KEY"] = "输入LANGCHAIN_API_KEY"
# 调用大语言模型
model = ChatOpenAI(model='gpt-3.5-turbo', api_key="输入OPENAI_API_KEY") # 模型名称
# 准备测试数据,假设我们提供的文档数据如下:
documents = [
Document(
page_content="狗是伟大的伴侣,以其忠诚和友好而闻名。",
metadata={"source": "哺乳动物宠物文档"},
),
Document(
page_content="猫是独立的宠物,通常喜欢自己的空间。",
metadata={"source": "哺乳动物宠物文档"},
),
Document(
page_content="金鱼是初学者的流行宠物,需要相对简单的护理。",
metadata={"source": "鱼类宠物文档"},
),
Document(
page_content="鹦鹉是聪明的鸟类,能够模仿人类的语言。",
metadata={"source": "鸟类宠物文档"},
),
Document(
page_content="兔子是社交动物,需要足够的空间跳跃。",
metadata={"source": "哺乳动物宠物文档"},
),
]
#################################################################
# 实例化一个向量数据库(向量空间)
vector_store = Chroma.from_documents(documents, embedding=OpenAIEmbeddings()) # 参数(文档,向量化技术)
# 创建检索器,bind(k=1)返回相似度最高的第一个
# 将方法包装成一个可执行的任务链,并通过 bind(k=1) 设置每次只返回相似度最高的一个结果。
retriever = RunnableLambda(vector_store.similarity_search).bind(k=1)
# 提示模版
message = """
使用提供的上下文仅回答这个问题:
{question}
上下文:
{content}
"""
prompt_temp = ChatPromptTemplate.from_messages([('human', message)])
# RunnablePassthrough()方法允许之后将用户的问题传入再传给prompt和model
chain = {'question': RunnablePassthrough(), 'context': retriever}
resp = chain.invoke('请给我介绍一下猫')构建代理
语言模型本身无法执行动作,它们只能输出文本。代理是使用大型语言模型(LLM)作为推理引擎来确定要执行的操作以及这些操作的输入应该是什么。然后,这些操作的结果可以反馈到代理中,代理将决定是否需要更多的操作,或者是否可以结束。 用来创建代理的API:
pip install langgraph而Langchain可以轻松的使用Tavily这个搜索引擎去搜索数据。
首先去Tavily AI获取Tavily的API_KEY:
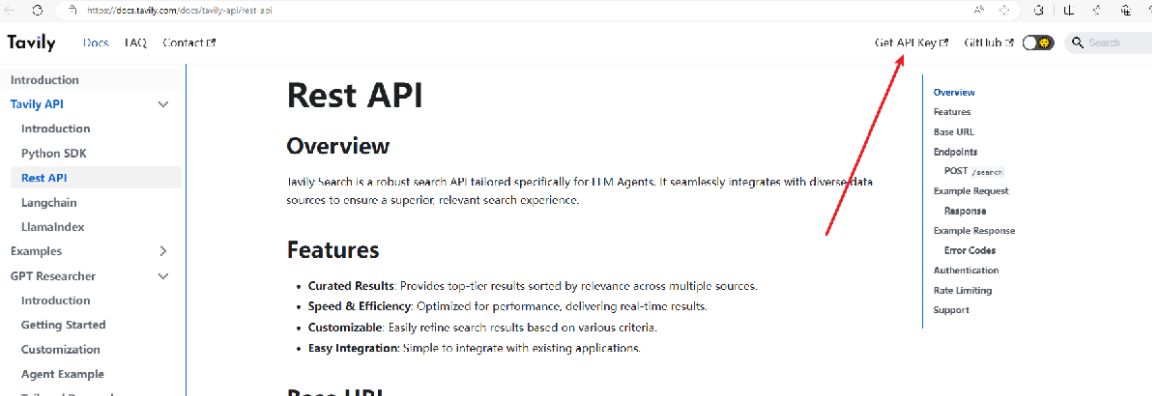
下面代码是使用Tavily搜索引擎搜索相关数据:
import os
from langchain_community.tools import TavilySearchResults
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 启用 LangChain 的追踪功能。
os.environ["LANGCHAIN_API_KEY"] = "输入LANGCHAIN_API_KEY"
os.environ["TAVILY_API_KEY"] = '输入TAVILY_API_KEY' #输入TAVILY_API_KEY
# 调用大语言模型
model = ChatOpenAI(model='gpt-3.5-turbo', api_key="输入OPENAI_API_KEY") # 模型名称
#################################################################
# 没有代理的情况下
# result = model.invoke([HumanMessage(content='北京的天气怎么样?')])
# print(result)
# Langchain可以轻松的使用Tavily这个搜索引擎去搜索数据
search = TavilySearchResults(max_results=2) # max_results:只返回两个结果
print(search.invoke('北京的天气怎么样?'))
# 让模型绑定工具
model.bind_tools([search])我们通过下面代码可以确认,LLM可以自动根据需求来选择是否需要调用工具:
import os
from langchain_community.tools import TavilySearchResults
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 启用 LangChain 的追踪功能。
os.environ["LANGCHAIN_API_KEY"] = "输入LANGCHAIN_API_KEY"
os.environ["TAVILY_API_KEY"] = '输入TAVILY_API_KEY' #输入TAVILY_API_KEY
# 调用大语言模型
model = ChatOpenAI(model='gpt-3.5-turbo', api_key="输入OPENAI_API_KEY") # 模型名称
#################################################################
# 没有代理的情况下
# result = model.invoke([HumanMessage(content='北京的天气怎么样?')])
# print(result)
# Langchain可以轻松的使用Tavily这个搜索引擎去搜索数据
search = TavilySearchResults(max_results=2) # max_results:只返回两个结果
print(search.invoke('北京的天气怎么样?'))
# 让模型绑定工具
model_with_tools = model.bind_tools([search])
# 模型可以自动推理:是否需要调用工具去完成用户的答案
resp = model_with_tools.invoke([HumanMessage(content='中国的首都是哪个城市?')])
print(f'Model_Result_Content: {resp.content}') # 中国的首都是北京。
print(f'Tools_Result_Content: {resp.tool_calls}') # []
resp2 = model_with_tools.invoke([HumanMessage(content='北京天气怎么样?')])
print(f'Model_Result_Content: {resp2.content}') # 空的
print(f'Tools_Result_Content: {resp2.tool_calls}') # [{'name': 'tavily_search_result_json','args': {'query': '北京当前天气'}, 'id': 'id值'}]下面是构建代理来让LLM进行调用搜索引擎:
创建代理(Agent)的主要目的是为了将多个组件(如大语言模型、工具、外部服务等)集成在一起,形成一个智能系统,能够根据用户输入自动选择合适的工具或模型来完成任务。代理的核心思想是让系统具备决策能力,能够根据上下文和任务需求动态调用不同的功能模块。
import os
from langchain_community.tools import TavilySearchResults
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import chat_agent_executor
os.environ["LANGCHAIN_TRACING_V2"] = "true" # 启用 LangChain 的追踪功能。
os.environ["LANGCHAIN_API_KEY"] = "输入LANGCHAIN_API_KEY"
os.environ["TAVILY_API_KEY"] = '输入TAVILY_API_KEY' #输入TAVILY_API_KEY
# 调用大语言模型
model = ChatOpenAI(model='gpt-3.5-turbo', api_key="输入OPENAI_API_KEY") # 模型名称
#################################################################
# Langchain可以轻松的使用Tavily这个搜索引擎去搜索数据
search = TavilySearchResults(max_results=2) # max_results:只返回两个结果
print(search.invoke('北京的天气怎么样?'))
# 让模型绑定工具
#model_with_tools = model.bind_tools([search])
tools = [search]
# 创建代理
agent_executor = chat_agent_executor.create_tool_calling_executor(model, tools)
# resp = model_with_tools.invoke([HumanMessage(content='中国的首都是哪个城市?')])
resp = agent_executor.invoke({'messages': [HumanMessage(content='中国的首都是哪个城市?')]})
print(resp['messages'])
resp2 = agent_executor.invoke({'messages': [HumanMessage(content='北京天气怎么样?')]})
print(resp2['messages'])
print(resp2['messages'][2].content)构建RAG的对话应用
RAG是一种增强大型语言模型(LLM)知识的方法,它通过引入额外的数据来实现。
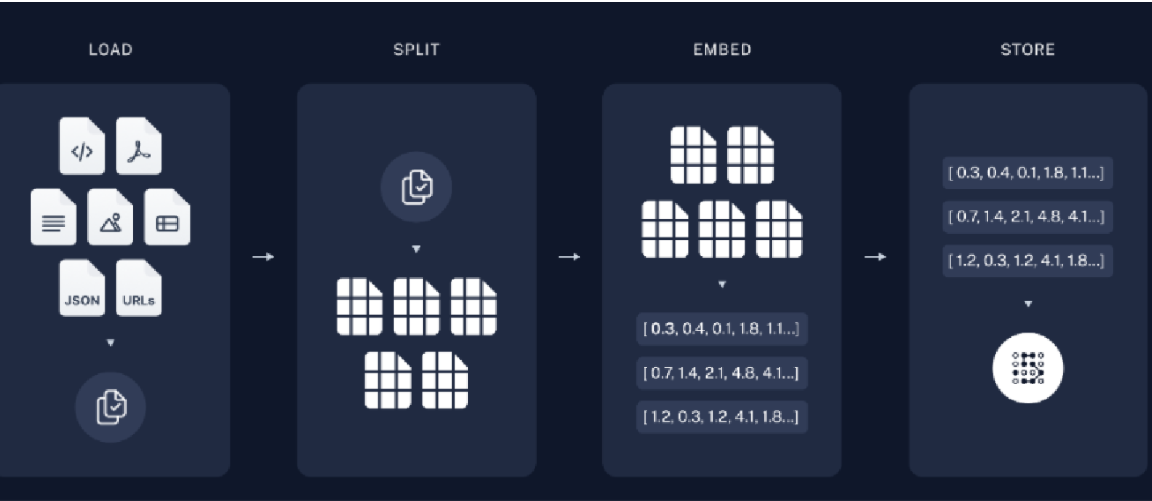
根据上图解析:
首先加载数据,可能是数据库内的、本地文本以及网上的资源等,然后将大文本进行切割(SPLIT)成小文本,之后将其向量化(Embedding)后存储到向量空间内。然后的内容如下图 ->
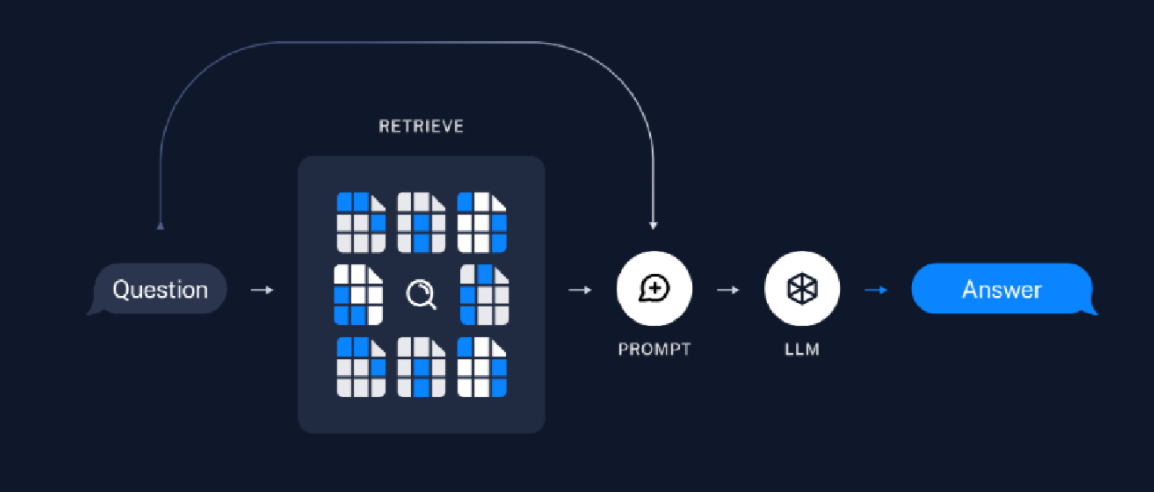
根据上图分析:
在上图,RETRIEVE就是根据上面的向量空间得到的检索器,我们的问题(Question)通过检索器检索出来后并结合提示词(PROMPT),交给LLM后在得出答案。
本案例是:复杂的问答 (Q&A) 聊天机器人。应用程序可以回答有关特定源信息的问题。使用一种称为检索增强生成 (RAG) 的技术。
用来创建代理的API:
pip install langgraph实现思路:
下面是完整代码:
import os
import bs4
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.history_aware_retriever import create_history_aware_retriever
from langchain.chains.retrieval import create_retrieval_chain
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
os.environ['http_proxy'] = '127.0.0.1:7890'
os.environ['https_proxy'] = '127.0.0.1:7890'
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "LangchainDemo"
os.environ["LANGCHAIN_API_KEY"] = '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'
# os.environ["TAVILY_API_KEY"] = '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'
# 聊天机器人案例
# 创建模型
model = ChatOpenAI(model='gpt-4-turbo')
##############################################################
# 1、加载数据: 一篇博客内容数据
loader = WebBaseLoader(
web_paths=['https://lilianweng.github.io/posts/2023-06-23-agent/'],
bs_kwargs=dict( # bs4:解析网页标签的解析器
parse_only=bs4.SoupStrainer(class_=('post-header', 'post-title', 'post-content')) # 解析哪些类
)
)
# 将解析的博客内容变成文档
docs = loader.load()
# print(len(docs)) # 查看解析后的文本数据列表内的数量(1)
# print(docs) # 查看解析后的文本数据
##############################################################
# 2、大文本的切割
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) # 参数:(每个片段包含多少个字符, 允许重复多少个字符【为了保证每段话的完整性】)
splits = splitter.split_documents(docs)
# 分段打印切割后的文本数据
# for s in splits:
# print(s, end="\n")
# 存储到向量空间(向量化存储)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings()) # OpenAIEmbeddings() 用于生成文本的嵌入向量
# 3、根据向量空间得到检索器
retriever = vectorstore.as_retriever()
##############################################################
# 整合
# 创建一个问题的模板:告诉AI要做什么事
system_prompt = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer
the question. If you don't know the answer, say that you
don't know. Use three sentences maximum and keep the answer concise.\n
{context}
"""
# 将系统提示、聊天历史和用户输入整合成一个完整的提示模板
prompt = ChatPromptTemplate.from_messages( # 提问和回答的 历史记录 模板
[
("system", system_prompt), # 定义了系统提示模板,指示模型如何回答问题
MessagesPlaceholder("chat_history"), # 聊天历史
("human", "{input}"), # 用户输入
]
)
# 得到chain(创建一个链,用于处理文档和生成回答)
chain1 = create_stuff_documents_chain(model, prompt)
chain2 = create_retrieval_chain(retriever, chain1)
resp = chain2.invoke({'input': "What is Task Decomposition?"}
print(resp['answer'])但是我们一般在查询历史记录的时候,不光是提示模版,我们的检索器也要对上下文进行理解。
下面是实现步骤:
下面是完整代码:
import os
import bs4
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.history_aware_retriever import create_history_aware_retriever
from langchain.chains.retrieval import create_retrieval_chain
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
os.environ['http_proxy'] = '127.0.0.1:7890'
os.environ['https_proxy'] = '127.0.0.1:7890'
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "LangchainDemo"
os.environ["LANGCHAIN_API_KEY"] = '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'
# os.environ["TAVILY_API_KEY"] = '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'
# 聊天机器人案例
# 创建模型
model = ChatOpenAI(model='gpt-4-turbo')
##############################################################
# 1、加载数据: 一篇博客内容数据
loader = WebBaseLoader(
web_paths=['https://lilianweng.github.io/posts/2023-06-23-agent/'],
bs_kwargs=dict( # bs4:解析网页标签的解析器
parse_only=bs4.SoupStrainer(class_=('post-header', 'post-title', 'post-content')) # 解析哪些类
)
)
# 将解析的博客内容变成文档
docs = loader.load()
# print(len(docs)) # 查看解析后的文本数据列表内的数量(1)
# print(docs) # 查看解析后的文本数据
##############################################################
# 2、大文本的切割
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) # 参数:(每个片段包含多少个字符, 允许重复多少个字符【为了保证每段话的完整性】)
splits = splitter.split_documents(docs)
# 存储到向量空间(向量化存储)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings()) # OpenAIEmbeddings() 用于生成文本的嵌入向量
##############################################################
# 3、根据向量空间得到检索器
retriever = vectorstore.as_retriever()
##############################################################
# 整合
# 创建一个问题的模板:告诉AI要做什么事
system_prompt = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer
the question. If you don't know the answer, say that you
don't know. Use three sentences maximum and keep the answer concise.\n
{context}
"""
# 将系统提示、聊天历史和用户输入整合成一个完整的提示模板
prompt = ChatPromptTemplate.from_messages( # 提问和回答的 历史记录 模板
[
("system", system_prompt), # 定义了系统提示模板,指示模型如何回答问题
MessagesPlaceholder("chat_history"), # 聊天历史
("human", "{input}"), # 用户输入
]
)
# 得到chain(创建一个链,用于处理文档和生成回答)
chain1 = create_stuff_documents_chain(model, prompt)
'''
注意:
一般情况下,我们构建的链(chain)直接使用输入问答记录来关联上下文。但在此案例中,查询检索器也需要对话上下文才能被理解。
解决办法:
添加一个子链(chain),它采用最新用户问题和聊天历史,并在它引用历史信息中的任何信息时重新表述问题。这可以被简单地认为是构建一个新的“历史感知”检索器。
这个子链的目的:让检索过程融入了对话的上下文。
'''
# 创建一个子链
# 子链的提示模板(定义了历史感知检索器的提示模板,用于将用户问题和聊天历史整合成一个独立的问题。)
contextualize_q_system_prompt = """Given a chat history and the latest user question
which might reference context in the chat history,
formulate a standalone question which can be understood
without the chat history. Do NOT answer the question,
just reformulate it if needed and otherwise return it as is."""
# 创建历史感知检索器,用于根据上下文检索相关文档
retriever_history_temp = ChatPromptTemplate.from_messages(
[
('system', contextualize_q_system_prompt),
MessagesPlaceholder('chat_history'),
("human", "{input}"),
]
)
# 创建一个子链
history_chain = create_history_aware_retriever(model, retriever, retriever_history_temp)
# 管理聊天历史
# 保持问答的历史记录(用于存储不同会话的聊天历史)
store = {}
# 函数根据会话 ID 获取或创建聊天历史
def get_session_history(session_id: str):
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
# 创建父链chain: 把前两个链整合(将历史感知检索器和文档处理链整合成一个完整的链)
chain = create_retrieval_chain(history_chain, chain1)
# 用于管理聊天历史,并将其整合到链中
result_chain = RunnableWithMessageHistory(
chain, # 父链
get_session_history, # 历史记录含数据
input_messages_key='input', # 用户输入问题参数
history_messages_key='chat_history', # 保存历史记录
output_messages_key='answer' # 返回结果
)
# 第一轮对话
resp1 = result_chain.invoke(
{'input': 'What is Task Decomposition?'},
config={'configurable': {'session_id': 'zs123456'}}
)
print(resp1['answer']) # 打印返回结果
# 第二轮对话
resp2 = result_chain.invoke(
{'input': 'What are common ways of doing it?'},
config={'configurable': {'session_id': 'ls123456'}}
)
print(resp2['answer'])读取数据库
本案例介绍在数据库中表格数据上的问答系统的基本方法,将涵盖使用链(chains)和代理(agents)的实现,通过查询数据库中的数据并得到自然语言答案。两者之间的主要区别在于:
实现思路:
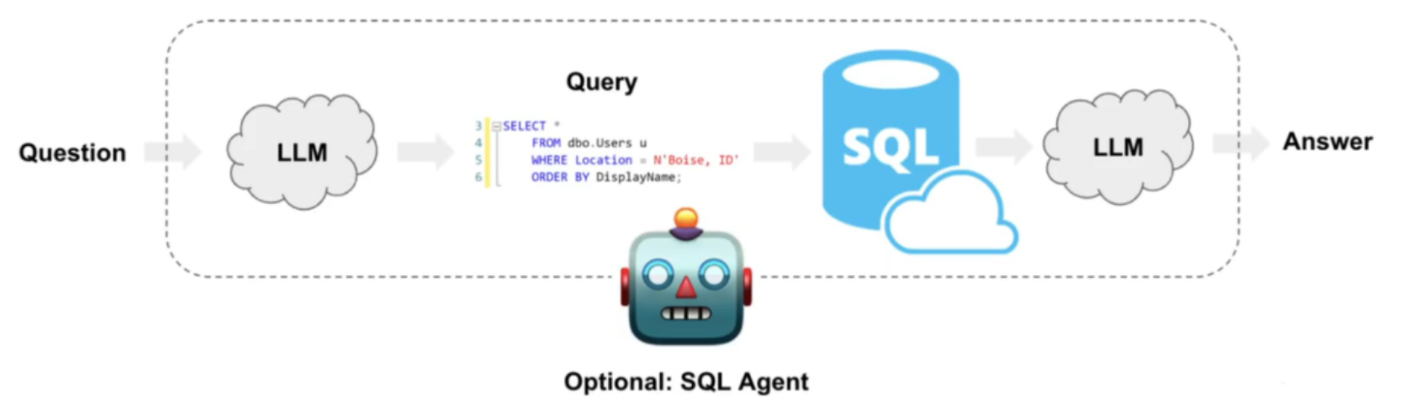
由上图分析:
我们将问题(Question)交给LLM,之后LLM根据问题并结合数据库中的表字段来自动生成SQL语句操作数据库,随后将查到的数据再次交给LLM处理,得到结果Answer。
如何连接数据库?
在Langchain一般使用SQLAlchemy来连接数据库,SQLAlchemy 是一个强大的 Python SQL 工具包,支持多种数据库(如 SQLite、MySQL、PostgreSQL 等)。
pip install langchain-sql sqlalchemy mysqlclient使用 SQLAlchemy 连接数据库:
from sqlalchemy import create_engine
# 连接到 MySQL 数据库
engine = create_engine("mysql+pymysql://user:password@localhost/dbname")其中的数据库URL格式如下:数据库方言+数据库驱动://用户名:密码@主机名/数据库名
# sqlalchemy 初始化MySQL数据库的连接
USERNAME = 'root' # 替换为你的数据库用户名
PASSWORD = '1234' # 替换为你的数据库密码
HOSTNAME = 'localhost' # 替换为你的数据库主机名或 IP 地址
PORT = 3306 # 替换为你的数据库端口(默认是 3306)
DATABASE = 'dbname' # 替换为你的数据库名称
# mysqlclient驱动URL
MYSQL_URI = 'mysql+mysqldb://{}:{}@{}:{}/{}?charset=utf8mb4'.format(USERNAME, PASSWORD, HOSTNAME, PORT, DATABASE)
# 使用 LangChain 的 SQLDatabase 连接数据库
db = SQLDatabase.from_uri(MYSQL_URI)
#################################################################
# 测试连接是否成功
print(db.get_usable_table_names())
print(db.run('select * from t_emp limit 10;'))下面代码直接将大模型和数据库整合:
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "LangchainDemo"
os.environ["LANGCHAIN_API_KEY"] = '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'
# 聊天机器人案例
# 创建模型
model = ChatOpenAI(model='gpt-3.5-turbo')
# sqlalchemy 初始化MySQL数据库的连接
USERNAME = 'root' # 替换为你的数据库用户名
PASSWORD = '1234' # 替换为你的数据库密码
HOSTNAME = 'localhost' # 替换为你的数据库主机名或 IP 地址
PORT = 3306 # 替换为你的数据库端口(默认是 3306)
DATABASE = 'dbname' # 替换为你的数据库名称
# mysqlclient驱动URL
MYSQL_URI = 'mysql+mysqldb://{}:{}@{}:{}/{}?charset=utf8mb4'.format(USERNAME, PASSWORD, HOSTNAME, PORT, DATABASE)
# 使用 LangChain 的 SQLDatabase 连接数据库
db = SQLDatabase.from_uri(MYSQL_URI)
#################################################################
# 直接使用大模型和数据库整合, 只能根据你的问题生成SQL
# 初始化生成SQL的chain(创建一个链,用于将自然语言问题转换为 SQL 查询)
test_chain = create_sql_query_chain(model, db)
resp = test_chain.invoke({'question': '请问:员工表中有多少条数据?'})
print(resp) # 输出一段SQL语句下面是输出结果:

下面是LLM使用链(chain)读取数据库回答的代码:
import os
from operator import itemgetter
import bs4
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.history_aware_retriever import create_history_aware_retriever
from langchain.chains.retrieval import create_retrieval_chain
from langchain.chains.sql_database.query import create_sql_query_chain
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.tools import QuerySQLDataBaseTool
from langchain_community.utilities import SQLDatabase
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder, PromptTemplate
from langchain_core.runnables import RunnableWithMessageHistory, RunnablePassthrough
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "LangchainDemo"
os.environ["LANGCHAIN_API_KEY"] = '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'
# 聊天机器人案例
# 创建模型
model = ChatOpenAI(model='gpt-3.5-turbo')
# sqlalchemy 初始化MySQL数据库的连接
USERNAME = 'root' # 替换为你的数据库用户名
PASSWORD = '1234' # 替换为你的数据库密码
HOSTNAME = 'localhost' # 替换为你的数据库主机名或 IP 地址
PORT = 3306 # 替换为你的数据库端口(默认是 3306)
DATABASE = 'dbname' # 替换为你的数据库名称
# mysqlclient驱动URL
MYSQL_URI = 'mysql+mysqldb://{}:{}@{}:{}/{}?charset=utf8mb4'.format(USERNAME, PASSWORD, HOSTNAME, PORT, DATABASE)
# 使用 LangChain 的 SQLDatabase 连接数据库
db = SQLDatabase.from_uri(MYSQL_URI)
#################################################################
# 直接使用大模型和数据库整合, 只能根据你的问题生成SQL
# 初始化生成SQL的chain
test_chain = create_sql_query_chain(model, db)
# 定义了一个提示模板,用于将用户问题、SQL 查询和查询结果整合为自然语言回答
answer_prompt = PromptTemplate.from_template(
"""给定以下用户问题、SQL语句和SQL执行后的结果,回答用户问题。
Question: {question}
SQL Query: {query}
SQL Result: {result}
回答: """
)
# 使用 QuerySQLDataBaseTool 创建一个工具,用于执行 SQL 查询
execute_sql_tool = QuerySQLDataBaseTool(db=db)
# 使用 RunnablePassthrough 构建一个链,流程如下:
# 1.将用户问题传递给 test_chain,生成 SQL 查询。
# 2.使用 execute_sql_tool 执行 SQL 查询,获取结果。
# 3.将问题、SQL 查询和结果传递给 answer_prompt,生成自然语言回答。
# 4.使用 model 生成最终回答,并通过 StrOutputParser 解析为字符串。
# 1、生成SQL,2、执行SQL
# 2、模板
chain = (RunnablePassthrough.assign(query=test_chain).assign(result=itemgetter('query') | execute_sql_tool)
| answer_prompt # 提示模板
| model # 定义的模型
| StrOutputParser() # 最终的数据流是一个字符串形式的回答
)
rep = chain.invoke(input={'question': '请问:员工表中有多少条数据?'})
print(rep)而现在我们使用的是链(chain)的形式将各种模块整合起来实现的LLM读取数据库,但是使用代理(agent)将会很大程度上简化代码:
import os
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_community.utilities import SQLDatabase
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import chat_agent_executor
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "LangchainDemo"
os.environ["LANGCHAIN_API_KEY"] = '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'
# 聊天机器人案例
# 创建模型
model = ChatOpenAI(model='gpt-4-turbo')
# sqlalchemy 初始化MySQL数据库的连接
USERNAME = 'root' # 替换为你的数据库用户名
PASSWORD = '1234' # 替换为你的数据库密码
HOSTNAME = 'localhost' # 替换为你的数据库主机名或 IP 地址
PORT = 3306 # 替换为你的数据库端口(默认是 3306)
DATABASE = 'dbname' # 替换为你的数据库名称
# mysqlclient驱动URL
MYSQL_URI = 'mysql+mysqldb://{}:{}@{}:{}/{}?charset=utf8mb4'.format(USERNAME, PASSWORD, HOSTNAME, PORT, DATABASE)
# 使用 LangChain 的 SQLDatabase 连接数据库
db = SQLDatabase.from_uri(MYSQL_URI)
#################################################################
# 创建工具(使用 SQLDatabaseToolkit 创建一个工具包,包含与数据库交互的工具)
toolkit = SQLDatabaseToolkit(db=db, llm=model)
# tools 是一个工具列表,代理可以使用这些工具执行 SQL 查询
tools = toolkit.get_tools()
# 使用agent完整整个数据库的整合
# 定义了一个系统提示,指导代理如何与数据库交互
system_prompt = """
您是一个被设计用来与SQL数据库交互的代理。
给定一个输入问题,创建一个语法正确的SQL语句并执行,然后查看查询结果并返回答案。
除非用户指定了他们想要获得的示例的具体数量,否则始终将SQL查询限制为最多10个结果。
你可以按相关列对结果进行排序,以返回MySQL数据库中最匹配的数据。
您可以使用与数据库交互的工具。在执行查询之前,你必须仔细检查。如果在执行查询时出现错误,请重写查询SQL并重试。
不要对数据库做任何DML语句(插入,更新,删除,删除等)。
首先,你应该查看数据库中的表,看看可以查询什么。
不要跳过这一步。
然后查询最相关的表的模式。
"""
system_message = SystemMessage(content=system_prompt)
# 创建代理
# 使用 chat_agent_executor.create_tool_calling_executor 创建一个代理执行器
agent_executor = chat_agent_executor.create_tool_calling_executor(model, tools, system_message)
# 用户输入问题后代理根据问题生成 SQL 查询,执行查询并返回结果。
resp = agent_executor.invoke({'messages': [HumanMessage(content='哪个部门下面的员工人数最多?')]})
result = resp['messages']
print(result)
print(len(result))
# 最后一个才是真正的答案
print(result[len(result)-1])检索YouTube视频字幕
创建一个简单的搜索引擎,将原始用户问题传递给该搜索系统,实现保存并加载向量数据库。
pydantic是一个用于数据验证和设置管理的 Python 库,广泛用于定义数据模型、解析和验证输入数据。
它的核心功能是确保数据的结构和类型符合预期,并在数据不符合要求时提供清晰的错误信息。eg:
from pydantic import BaseModel
class User(BaseModel):
id: int
name: str
age: Optional[int] = None # 可选字段
is_active: bool = True # 默认值安装依赖:
pip install youtube-transcript-api pytube实现保存并加载向量数据库步骤:
总结:
下面是实现保存并加载向量数据库的完整代码:
import datetime
import os
from typing import Optional, List
from langchain_chroma import Chroma
from langchain_community.document_loaders import YoutubeLoader
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from pydantic.v1 import BaseModel, Field
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "LangchainDemo"
os.environ["LANGCHAIN_API_KEY"] = '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'
####################################################################
# 聊天机器人案例
# 创建模型
model = ChatOpenAI(model='gpt-4-turbo')
# 初始化一个OpenAI的嵌入模型,使用 text-embedding-3-small
embeddings = OpenAIEmbeddings(model='text-embedding-3-small')
# 存放向量数据库的目录
persist_dir = 'chroma_data_dir' # 指定向量数据库持久化存储的目录
# 加载YouTube视频并生成文档
# 一些YouTube的视频连接
urls = [
"https://www.youtube.com/watch?v=HAn9vnJy6S4",
"https://www.youtube.com/watch?v=dA1cHGACXCo",
"https://www.youtube.com/watch?v=ZcEMLz27sL4",
"https://www.youtube.com/watch?v=hvAPnpSfSGo",
"https://www.youtube.com/watch?v=EhlPDL4QrWY",
"https://www.youtube.com/watch?v=mmBo8nlu2j0",
"https://www.youtube.com/watch?v=rQdibOsL1ps",
"https://www.youtube.com/watch?v=28lC4fqukoc",
"https://www.youtube.com/watch?v=es-9MgxB-uc",
"https://www.youtube.com/watch?v=wLRHwKuKvOE",
"https://www.youtube.com/watch?v=ObIltMaRJvY",
"https://www.youtube.com/watch?v=DjuXACWYkkU",
"https://www.youtube.com/watch?v=o7C9ld6Ln-M",
]
docs = [] # document的数组,存储所有视频生成的文档
for url in urls:
# 从YouTube视频中提取字幕信息并生成文档,一个Youtube的视频对应一个document
docs.extend(YoutubeLoader.from_youtube_url(url, add_video_info=True).load())
print(len(docs))
print(docs[0])
# 给doc添加额外的元数据: 视频发布的年份
for doc in docs:
doc.metadata['publish_year'] = int( # 为每个文档添加publish_year元数据,表示视频发布的年份
datetime.datetime.strptime(doc.metadata['publish_date'], '%Y-%m-%d %H:%M:%S').strftime('%Y'))
print(docs[0].metadata)
print(docs[0].page_content[:500]) # 第一个视频的字幕,内容截取前 500 个字符。
# 根据多个doc构建向量数据库
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=30) # 将文档分割成较小的块,便于后续处理
# 使用分割后的文档和嵌入模型构建向量数据库,并将其持久化到指定目录
split_doc = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(split_doc, embeddings, persist_directory=persist_dir) # 向量数据库的持久化,并且把向量数据库持久化到磁盘
# 从磁盘加载之前持久化的向量数据库
vectorstore = Chroma(persist_directory=persist_dir, embedding_function=embeddings)
# 测试向量数据库的相似检索
# similarity_search_with_score: 在向量数据库中进行相似性检索,返回与查询最相似的文档及其相似度分数
result = vectorstore.similarity_search_with_score('how do I build a RAG agent')
print(result[0])
print(result[0][0].metadata['publish_year'])
# 定义系统提示和Pydantic数据模型
system = """You are an expert at converting user questions into database queries. \
You have access to a database of tutorial videos about a software library for building LLM-powered applications. \
Given a question, return a list of database queries optimized to retrieve the most relevant results.
If there are acronyms or words you are not familiar with, do not try to rephrase them."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
# pydantic
class Search(BaseModel): # 使用Pydantic定义的数据模型,包含查询字符串和发布年份
"""
定义了一个数据模型
"""
# 内容的相似性和发布年份
query: str = Field(None, description='Similarity search query applied to video transcripts.')
publish_year: Optional[int] = Field(None, description='Year video was published')
# 构建一个链,将用户问题传递给提示模板,然后调用模型生成结构化输出
chain = {'question': RunnablePassthrough()} | prompt | model.with_structured_output(Search)
# 调用链并传入用户问题,返回结构化结果
resp1 = chain.invoke('how do I build a RAG agent?')
print(resp1)
resp2 = chain.invoke('videos on RAG published in 2023')
print(resp2)
# 根据查询和发布年份进行检索,返回相关文档
def retrieval(search: Search) -> List[Document]:
_filter = None
if search.publish_year:
# 根据publish_year,存在得到一个检索条件
# "$eq"是Chroma向量数据库的固定语法
_filter = {'publish_year': {"$eq": search.publish_year}}
return vectorstore.similarity_search(search.query, filter=_filter)
# 将之前的链与检索函数结合,形成新的链
new_chain = chain | retrieval
# 下面代码等价于这行:result = new_chain.invoke('videos on RAG published in 2023')
result = new_chain.invoke('RAG tutorial')
print([(doc.metadata['title'], doc.metadata['publish_year']) for doc in result])提取结构化的数据
在这个案例中国,我们将构建一个链来从非结构化的文本中提取结构化信息。在自然语言处理(NLP)中,表格数据抽取是一个重要的任务,他涉及到从文本中提取结构化数据。
首先使用pydantic来定义数据:
# pydantic: 处理数据,验证数据, 定义数据的格式, 虚拟化和反虚拟化,类型转换等等。
# 定义数据
class Person(BaseModel):
"""
关于一个人的数据模型
"""
name: Optional[str] = Field(default=None, description='表示人的名字') # 可选字段
hair_color: Optional[str] = Field(
default=None, description="如果知道的话,这个人的头发颜色"
) # 可选字段
height_in_meters: Optional[str] = Field(
default=None, description="以米为单位测量的高度"
) # 可选字段
class ManyPerson(BaseModel):
"""
数据模型类: 代表多个人
"""
people: List[Person]之后定义一个提示模版:
# 定义自定义提示以提供指令和任何其他上下文。
# 1) 我们可以在提示模板中添加示例以提高提取质量
# 2) 引入额外的参数以考虑上下文(例如,包括有关提取文本的文档的元数据。)
prompt = ChatPromptTemplate.from_messages(
[
# 指导模型从文本中提取信息,如果无法提取则返回 null
(
"system",
"你是一个专业的提取算法。只从未结构化文本中提取相关信息。如果你不知道要提取的属性的值,返回该属性的值为null。",
),
# 请参阅有关如何使用参考记录消息历史的案例
# MessagesPlaceholder('examples'),
# 将用户提供的文本({text})传递给模型
("human", "{text}"),
]
)然后使用链式调用进行处理得到结构化对象:
chain = {'text': RunnablePassthrough()} | prompt | model.with_structured_output(schema=ManyPerson)model.with_structured_output**:调用模型并将输出解析为 ManyPerson 对象。在这里是处理多个对象,如果想要处理单个对象将数据类型ManyPerson换成Person即可。
最后打印结构化对象结果:
text = "My name is Jeff, my hair is black and i am 6 feet tall. Anna has the same color hair as me."
resp = chain.invoke(text)
print(resp)下面是完整代码:
import os
from typing import Optional, List
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
from pydantic.v1 import BaseModel, Field
os.environ['http_proxy'] = '127.0.0.1:7890'
os.environ['https_proxy'] = '127.0.0.1:7890'
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "LangchainDemo"
os.environ["LANGCHAIN_API_KEY"] = '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'
# 聊天机器人案例
# 创建模型
model = ChatOpenAI(model='gpt-4-turbo')
###########################################################
# pydantic: 处理数据,验证数据, 定义数据的格式, 虚拟化和反虚拟化,类型转换等等。
# 定义数据
class Person(BaseModel):
"""
关于一个人的数据模型
"""
name: Optional[str] = Field(default=None, description='表示人的名字')
hair_color: Optional[str] = Field(
default=None, description="如果知道的话,这个人的头发颜色"
)
height_in_meters: Optional[str] = Field(
default=None, description="以米为单位测量的高度"
)
class ManyPerson(BaseModel):
"""
数据模型类: 代表多个人
"""
people: List[Person]
# 定义自定义提示以提供指令和任何其他上下文。
# 1) 你可以在提示模板中添加示例以提高提取质量
# 2) 引入额外的参数以考虑上下文(例如,包括有关提取文本的文档的元数据。)
prompt = ChatPromptTemplate.from_messages(
[
# 指导模型从文本中提取信息,如果无法提取则返回 null
(
"system",
"你是一个专业的提取算法。只从未结构化文本中提取相关信息。如果你不知道要提取的属性的值,返回该属性的值为null。",
),
# 请参阅有关如何使用参考记录消息历史的案例
# MessagesPlaceholder('examples'),
# 将用户提供的文本({text})传递给模型
("human", "{text}"),
]
)
# with_structured_output 模型的输出是一个结构化的数据
chain = {'text': RunnablePassthrough()} | prompt | model.with_structured_output(schema=ManyPerson)
# text = '马路上走来一个女生,长长的黑头发披在肩上,大概1米7左右,'
# text = "马路上走来一个女生,长长的黑头发披在肩上,大概1米7左右。走在她旁边的是她的男朋友,叫:刘海;比她高10厘米。"
text = "My name is Jeff, my hair is black and i am 6 feet tall. Anna has the same color hair as me."
resp = chain.invoke(text)
print(resp)AI自动生成数据
AI 自动生成数据 是指利用人工智能(AI)技术,通过算法和模型自动创建数据的过程。这些数据可以是文本、图像、音频、视频或结构化数据(如表格、JSON 等),具体取决于所使用的 AI 模型和应用场景。AI 自动生成数据的核心思想是让机器模仿人类的能力,从已有的数据中学习规律,并生成新的、符合特定要求的数据。
安装依赖:
pip install langchain_experimental首先我们创建链:
chain = create_data_generation_chain(model)然后基于给定的关键词,使用 AI 模型随机生成一句话:
# 基于给定的关键词(如“蓝色”和“黄色”),使用 AI 模型随机生成一句话
result = chain( # 给于一些关键词, 随机生成一句话
{
"fields": ['蓝色', '黄色'], # 提供关键词(如“蓝色”和“黄色”),用于指导生成内容
"preferences": {} # 可以用于指定生成文本的风格或其他偏好(如语气、长度等),这里为空字典表示没有额外偏好
}
)
print(result) # 打印结果,生成文本在text字段内下面是完整代码:
import os
from langchain_experimental.synthetic_data import create_data_generation_chain
from langchain_openai import ChatOpenAI
os.environ['http_proxy'] = '127.0.0.1:7890'
os.environ['https_proxy'] = '127.0.0.1:7890'
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "LangchainDemo"
os.environ["LANGCHAIN_API_KEY"] = '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'
# 聊天机器人案例
# 创建模型
model = ChatOpenAI(model='gpt-3.5-turbo', temperature=0.8) #为了生成多样数据,这里将temperature设置为0.8,最高是1.0
##########################################################
# 创建链
chain = create_data_generation_chain(model)
# 基于给定的关键词(如“蓝色”和“黄色”),使用 AI 模型随机生成一句话
# result = chain( # 给于一些关键词, 随机生成一句话
# {
# "fields": ['蓝色', '黄色'], # 提供关键词(如“蓝色”和“黄色”),用于指导生成内容
# "preferences": {} # 可以用于指定生成文本的风格或其他偏好(如语气、长度等),这里为空字典表示没有额外偏好
# }
# )
# print(result)
result = chain( # 给于一些关键词, 随机生成一句话
{
"fields": {"颜色": ['蓝色', '黄色']},
"preferences": {"style": "让它像诗歌一样。"}
}
)
print(result)-
调用语言模型
model = ChatOpenAI(model='gpt-3.5-turbo', api_key="输入OPENAI_API_KEY") # 模型名称
-
使用OutputParsers: 输出解析器
parser = StrOutputParser() # 创建返回的数据解析器
-
使用PromptTemplate: 提示模板
prompt_template = ChatPromptTemplate.from_messages([ ('system', '请将以下内容翻译成{language}'), ('user',"text") ]) -
使用LangSmish追踪你的应用程序
-
使用LangServe部署你的应用程序
-
初始化模型和提示模板。
ChatPromptTemplate.from_messages([ ('system', '你是一个乐于助人的助手,用{language}尽你所能回答所有问题。'), MessagesPlaceholder(variable_name='my_msg') # 历史消息记录,去掉后可以将模型变成单轮对话 ]) -
构建链并设置历史记录功能。
chain = prompt_template | model
-
管理聊天历史:
# 所有用户的聊天记录都保存在store。 key: sessionId,value: 历史聊天记录对象 store = {} # 此函数预期将接收一个session_id并返回一个消息历史记录对象 def get_session_history(session_id: str): if session_id not in store: store[session_id] = {} return store[session_id] -
创建带聊天历史的链并定义会话ID:
# 创建带聊天历史的链 do_message = RunnableWithMessageHistory( chain, get_session_history, input_messages_key='my_msg', # 每次聊天时候发送msg的key ) # 定义会话ID config = {'configurable': {'session_id': 'zs123'}} # 给当前对话定义一个sessionId -
可多轮聊天,每次聊天都会保存和读取历史记录。
resp = do_message.invoke( { 'my_msg': [HumanMessage(content='你好呀,我是Eleven')], 'language': '中文' }, config=config, # 会话ID ) -
打印出聊天机器人的回复。
print(resp.content)
-
do_message.stream:使用stream方法以流式方式调用模型,逐 token 返回结果。 -
for resp in ...:遍历流式输出的每个 token。 -
print(resp.content, end='-'):打印每个 token,并在 token 之间添加分隔符-。
-
实例化一个向量数据库: Chroma.from_documents(documents, embedding=OpenAIEmbeddings()),(向量数空间)
-
相似度查询:vector_store.similarity_search_with_score('咖啡猫'),返回相似的分值,分数越低相似度越高
-
初始化模型和向量数据库。
documents = [ Document( page_content="狗是伟大的伴侣,以其忠诚和友好而闻名。", metadata={"source": "哺乳动物宠物文档"}, ), # ... ] -
将测试文档转换为向量并存储在
Chroma中。vector_store = Chroma.from_documents(documents, embedding=OpenAIEmbeddings())
-
对查询词
"咖啡猫"进行相似度搜索,并打印结果。(方法)print(vector_store.similarity_search_with_score('咖啡猫')) -
创建检索器,设置每次只返回一个最相似的结果。
retriever = RunnableLambda(vector_store.similarity_search).bind(k=1)
-
对
["咖啡猫", "鲨鱼"]进行批量查询,返回每个查询词的最相似文档。retriever.batch(['咖啡猫','鲨鱼'])
-
加载:首先我们需要加载数据。这是通过DocumentLoaders完成的。
# 1、加载数据: 一篇博客内容数据 loader = WebBaseLoader( web_paths=['https://lilianweng.github.io/posts/2023-06-23-agent/'], bs_kwargs=dict( # bs4:解析网页标签的解析器 parse_only=bs4.SoupStrainer(class_=('post-header', 'post-title', 'post-content')) # 解析哪些类 ) ) # 将解析的博客内容变成文档 docs = loader.load() -
分割: Text splitters将大型文档分割成更小的块。这对于索引数据和将其传递给模型很有用,因为大块数据更难搜索,并且不适合模型的有限上下文窗口。
# 2、大文本的切割 splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) # 参数:(每个片段包含多少个字符, 允许重复多少个字符【为了保证每段话的完整性】) splits = splitter.split_documents(docs) # 分段打印切割后的文本数据 # for s in splits: # print(s, end="\n") -
存储:我们需要一个地方来存储和索引我们的分割,以便以后可以搜索。这通常使用VectorStore和Embeddings模型完成。
# 存储到向量空间(向量化存储) vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings()) # OpenAIEmbeddings() 用于生成文本的嵌入向量 # 3、根据向量空间得到检索器 retriever = vectorstore.as_retriever() -
检索:给定用户输入,使用检索器从存储中检索相关分割。
# 创建一个问题的模板:告诉AI要做什么事 system_prompt = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, say that you don't know. Use three sentences maximum and keep the answer concise.\n {context} """ # 将系统提示、聊天历史和用户输入整合成一个完整的提示模板 prompt = ChatPromptTemplate.from_messages( # 提问和回答的 历史记录 模板 [ ("system", system_prompt), # 定义了系统提示模板,指示模型如何回答问题 MessagesPlaceholder("chat_history"), # 聊天历史 ("human", "{input}"), # 用户输入 ] ) -
生成:ChatModel / LLM使用包括问题和检索到的数据的提示生成答案。
# 得到chain(创建一个链,用于处理文档和生成回答) chain1 = create_stuff_documents_chain(model, prompt) chain2 = create_retrieval_chain(retriever, chain1) resp = chain2.invoke({'input': "What is Task Decomposition?"} print(resp['answer']) -
定义子链的提示模板:将用户问题和聊天历史整合成一个独立的问题,使得检索器能够理解上下文。
contextualize_q_system_prompt = """ Given a chat history and the latest user question which might reference context in the chat history, formulate a standalone question which can be understood without the chat history. Do NOT answer the question, just reformulate it if needed and otherwise return it as is. """ -
创建历史感知检索器的提示模板:
retriever_history_temp = ChatPromptTemplate.from_messages( [ ('system', contextualize_q_system_prompt), MessagesPlaceholder('chat_history'), ("human", "{input}"), ] ) -
创建子链:将用户问题和聊天历史整合成一个独立的问题,用于检索。
history_chain = create_history_aware_retriever(model, retriever, retriever_history_temp) -
管理聊天历史:管理不同会话的聊天历史。
store = {} def get_session_history(session_id: str): if session_id not in store: store[session_id] = ChatMessageHistory() return store[session_id] -
创建父链:将历史感知检索器(
history_chain)和文档处理链(chain1)整合成一个完整的链。chain = create_retrieval_chain(history_chain, chain1)
-
整合聊天历史:将父链与聊天历史管理功能整合。
result_chain = RunnableWithMessageHistory( chain, # 父链 get_session_history, # 获取聊天历史的函数 input_messages_key='input', # 用户输入问题的键 history_messages_key='chat_history', # 聊天历史的键 output_messages_key='answer' # 返回结果的键 ) -
执行对话:
resp1 = result_chain.invoke( {'input': 'What is Task Decomposition?'}, config={'configurable': {'session_id': 'zs123456'}} ) print(resp1['answer'])
-
链(Chains):直接生成 SQL 查询并返回结果,适用于简单的单次查询。
-
代理(Agents):可以根据需要多次循环查询数据库,适用于复杂的多步查询。
-
将问题转换为DSL查询:模型将用户输入转换为SQL查询
-
执行SQL查询:执行查询
-
回答问题:模型使用查询结果响应用户输入
-
初始化向量数据库和嵌入模型:
# 初始化一个OpenAI的嵌入模型,使用 text-embedding-3-small embeddings = OpenAIEmbeddings(model='text-embedding-3-small') # 存放向量数据库的目录 persist_dir = 'chroma_data_dir' # 指定向量数据库持久化存储的目录 -
加载 YouTube 视频并生成文档:
docs = [] # document的数组,存储所有视频生成的文档 for url in urls: # 从YouTube视频中提取字幕信息并生成文档,一个Youtube的视频对应一个document docs.extend(YoutubeLoader.from_youtube_url(url, add_video_info=True).load())YoutubeLoader:从 YouTube 视频中提取字幕信息并生成Document对象,每个视频对应一个Document。 -
添加元数据:
for doc in docs: doc.metadata['publish_year'] = int( # 为每个文档添加publish_year元数据,表示视频发布的年份 datetime.datetime.strptime(doc.metadata['publish_date'], '%Y-%m-%d %H:%M:%S').strftime('%Y'))为每个
Document添加publish_year元数据,表示视频发布的年份。 -
分割文档并构建向量数据库:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=30) # 将文档分割成较小的块,便于后续处理 split_doc = text_splitter.split_documents(docs) vectorstore = Chroma.from_documents(split_doc, embeddings, persist_directory=persist_dir) # 向量数据库的持久化,并且把向量数据库持久化到磁盘-
text_splitter将文档分割成较小的块,便于后续处理。 -
Chroma.from_documents使用分割后的文档和嵌入模型构建向量数据库,并将其持久化到指定目录persist_dir。
-
-
从磁盘加载向量数据库:
vectorstore = Chroma(persist_directory=persist_dir, embedding_function=embeddings)Chroma从指定目录persist_dir加载之前持久化的向量数据库。 -
测试向量数据库的相似检索:
result = vectorstore.similarity_search_with_score('how do I build a RAG agent') print(result[0]) print(result[0][0].metadata['publish_year'])similarity_search_with_score在向量数据库中进行相似性检索,返回与查询最相似的文档及其相似度分数。 -
定义系统提示和 Pydantic 数据模型:
pydantic: 处理数据,验证数据, 定义数据的格式, 虚拟化和反虚拟化,类型转换等等。
# 定义了系统提示,用于指导模型如何将用户问题转换为数据库查询。 # 提示模型是一个专家,能够将用户问题优化为数据库查询,强调不要尝试重新解释不熟悉的缩写或单词。 system = """You are an expert at converting user questions into database queries. \ You have access to a database of tutorial videos about a software library for building LLM-powered applications. \ Given a question, return a list of database queries optimized to retrieve the most relevant results. If there are acronyms or words you are not familiar with, do not try to rephrase them.""" # 使用 ChatPromptTemplate 创建一个提示模板 prompt = ChatPromptTemplate.from_messages( [ ("system", system), ("human", "{question}"), ] ) # 使用Pydantic定义的数据模型,包含查询字符串和发布年份 class Search(BaseModel): """ 定义了一个数据模型 """ # 内容的相似性和发布年份 # query:表示用户问题的查询字符串 query: str = Field(None, description='Similarity search query applied to video transcripts.') # publish_year:表示视频的发布年份(可选) publish_year: Optional[int] = Field(None, description='Year video was published')system是系统提示,用于指导模型如何将用户问题转换为数据库查询。prompt是聊天提示模板,包含系统提示和用户问题。Search是使用 Pydantic 定义的数据模型,包含查询字符串和发布年份:-
query字段是一个字符串类型 (str),默认值为None。Field函数用于为该字段提供额外的描述信息。 -
publish_year字段是一个可选的整数类型 (Optional[int]),默认值为None。同样使用Field函数为该字段提供描述信息。
-
-
构建链并调用模型:
# 使用 RunnablePassthrough 将用户输入直接传递到下一步。 chain = {'question': RunnablePassthrough()} | prompt | model.with_structured_output(Search) resp1 = chain.invoke('how do I build a RAG agent?') print(resp1) resp2 = chain.invoke('videos on RAG published in 2023') print(resp2)-
chain使用RunnablePassthrough**直接传递用户输入,随后将用户输入与系统提示结合传递给提示模板prompt,生成适合模型处理的输入,然后将prompt的输出传递给模型生成结构化输出(将输出解析为Search对象)。 -
with_structured_output(Search)表示模型需要将输出解析为Search数据模型的结构化对象。 -
invoke调用链并传入用户问题,返回结构化结果。
-
-
根据用户查询问题和发布年份进行检索:
# 根据 Search 对象从向量数据库中检索文档 def retrieval(search: Search) -> List[Document]: _filter = None # 用于存储检索的过滤条件,初始化为 None, if search.publish_year: # 根据publish_year,存在得到一个检索条件 # "$eq"是Chroma向量数据库的固定语法,表示“等于” _filter = {'publish_year': {"$eq": search.publish_year}} return vectorstore.similarity_search(search.query, filter=_filter)-
retrieval函数根据查询和发布年份进行检索,返回相关文档。 -
vectorstore.similarity_search:调用向量数据库的similarity_search方法,根据查询字符串search.query进行相似性搜索。 -
filter=_filter:将过滤条件传递给similarity_search方法,用于进一步筛选结果。
-
-
结合链与检索函数:
new_chain = chain | retrieval result = new_chain.invoke('RAG tutorial') print([(doc.metadata['title'], doc.metadata['publish_year']) for doc in result])new_chain将之前的链与检索函数结合,形成新的链:invoke调用新的链并传入用户问题,返回相关文档的标题和发布年份:-
chain:之前的链式处理流程,将用户输入转换为结构化的Search对象。 -
retrieval:之前定义的检索函数,根据Search对象从向量数据库中检索文档。 -
new_chain:新的链式流程,依次执行chain和retrieval,最终返回检索到的文档列表。 -
doc.metadata['title']:从文档的元数据中提取标题。 -
doc.metadata['publish_year']:从文档的元数据中提取发布年份。 -
列表推导式:遍历
result中的每个文档,提取其标题和发布年份,并组成一个元组列表。
-
-
保存数据库:通过
Chroma.from_documents将分割后的文档和嵌入模型构建的向量数据库持久化到指定目录persist_dir。 -
加载数据库:通过
Chroma(persist_directory=persist_dir, embedding_function=embeddings)从指定目录persist_dir加载之前持久化的向量数据库。 -
检索和问答:结合 LangChain 和 Chroma 向量数据库,实现基于用户问题的相似性检索和结构化输出。