作者:IvanCodes
日期:2025年5月24日
专栏:Zookeeper教程

我们这次教程将以 hadoop01 (192.168.121.131), hadoop02 (192.168.121.132), hadoop03 (192.168.121.133) 三台Linux服务器为例,搭建一个ZooKeeper 3.8.4集群。
一、下载ZooKeeper软件包 (在 hadoop01 操作)
- 访问官方发布页面:
- 首先,请打开您的浏览器,访问 Apache ZooKeeper官方发布页面:
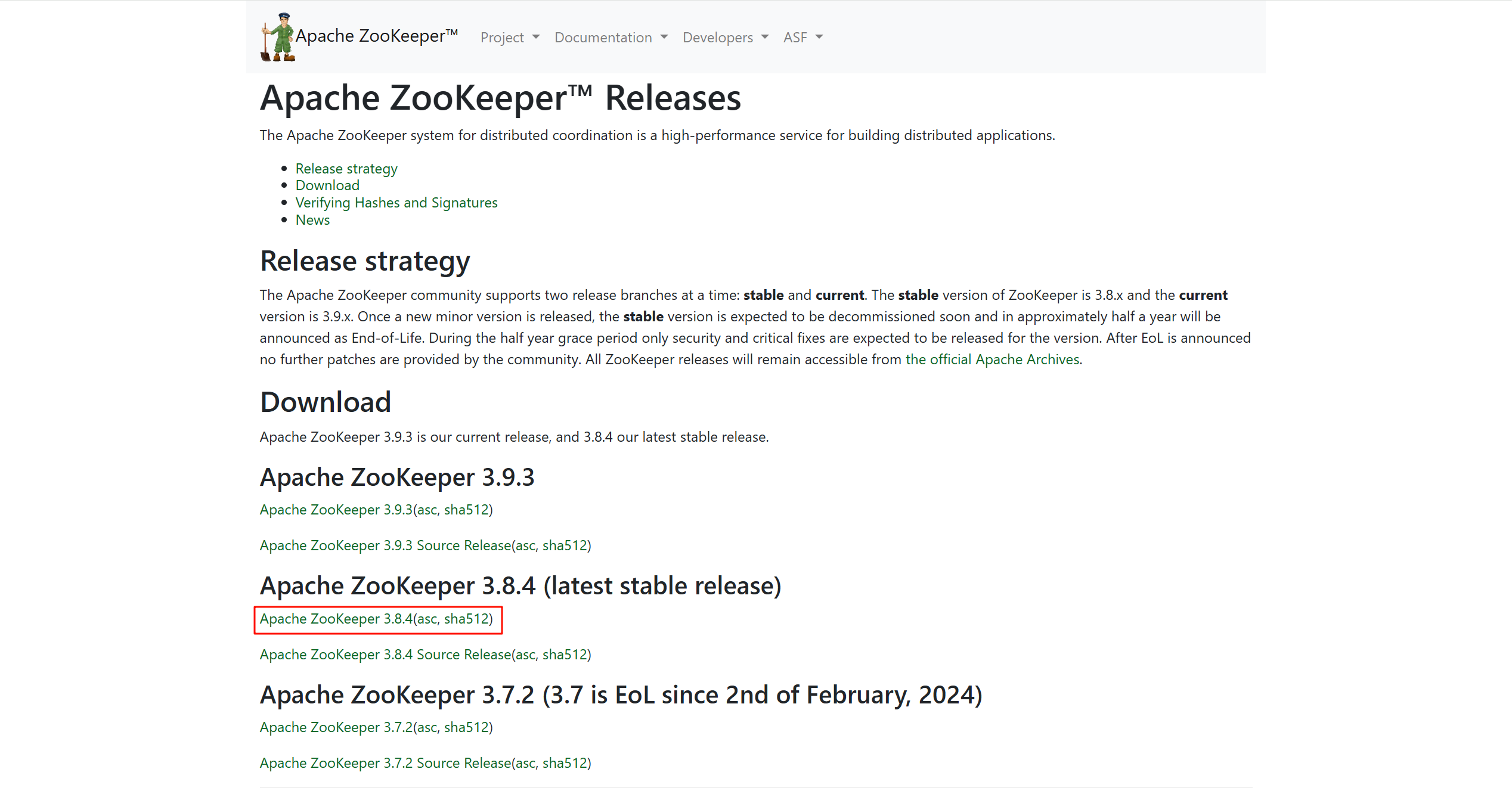
- 定位并下载指定版本:
- 在打开的页面中,找到 “Download” 部分。
- 您需要选择 Apache ZooKeeper 3.8.4 版本。点击对应的下载链接。通常,您会看到一个建议的下载镜像链接。
- 从上图所示的镜像站点下载 二进制包 (binary package),文件名通常为
apache-zookeeper-3.8.4-bin.tar.gz。 - 将下载好的
apache-zookeeper-3.8.4-bin.tar.gz文件上传到hadoop01服务器的/export/softwares目录下 (如果该目录不存在,请先创建:mkdir -p /export/softwares)。
二、解压与准备 (在 hadoop01 操作)
- 解压ZooKeeper安装包:
- 目标安装路径为
/export/server。
- 目标安装路径为
在 hadoop01 上执行:
cd /export/softwares
tar -zxvf apache-zookeeper-3.8.4-bin.tar.gz -C /export/server/
cd /export/server
mv apache-zookeeper-3.8.4-bin zookeeper
三、配置环境变量 (所有节点:hadoop01, hadoop02, hadoop03)
为了方便全局使用ZooKeeper命令,需要在所有三个节点上配置环境变量。
在 hadoop01, hadoop02, hadoop03 上分别执行以下命令:
echo 'export ZOOKEEPER_HOME=/export/server/zookeeper' >> /etc/profile
echo 'export PATH=$PATH:/export/server/zookeeper/bin' >> /etc/profile
source /etc/profile
如何查看环境变量是否配置成功? (在任一节点执行)
echo $ZOOKEEPER_HOME
# 应输出 /export/server/zookeeper
echo $PATH
# 应能看到 /export/server/zookeeper/bin 在路径中
zkServer.sh version
# 如果PATH配置正确,此命令会显示ZooKeeper版本信息
四、同步ZooKeeper至其他节点 (在 hadoop01 操作)
在 hadoop01 上完成解压后,将配置好的 /export/server/zookeeper 目录同步到 hadoop02 和 hadoop03。(其他节点此时也应已完成步骤三的环境变量配置)。
在 hadoop01 上执行:
scp -r /export/server/zookeeper root@hadoop02:/export/server/
scp -r /export/server/zookeeper root@hadoop03:/export/server/
提示:确保 hadoop01 对 hadoop02 和 hadoop03 有SSH免密登录权限,或在执行 scp 时按提示输入密码。
五、创建数据目录与配置myid (各节点分别操作)
ZooKeeper集群中每个节点都需要一个唯一的ID号 (myid),存储在其数据目录下的 myid 文件中。
在 hadoop01 上执行:
mkdir -p /export/data/zookeeper
echo "1" > /export/data/zookeeper/myid
在 hadoop02 上执行:
mkdir -p /export/data/zookeeper
echo "2" > /export/data/zookeeper/myid
在 hadoop03 上执行:
mkdir -p /export/data/zookeeper
echo "3" > /export/data/zookeeper/myid
六、修改核心配置文件zoo.cfg (在 hadoop01 操作后分发)
ZooKeeper的主要配置文件是 zoo.cfg。我们先在 hadoop01 上创建并修改,然后分发到其他节点以保持配置一致。
在 hadoop01 上执行:
cd /export/server/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
使用文本编辑器 vim 修改 /export/server/zookeeper/conf/zoo.cfg 文件,确保内容如下:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/export/data/zookeeper
clientPort=2181
# autopurge.snapRetainCount=3
# autopurge.purgeInterval=1
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
4lw.commands.whitelist=stat,ruok,conf,srvr,mntr
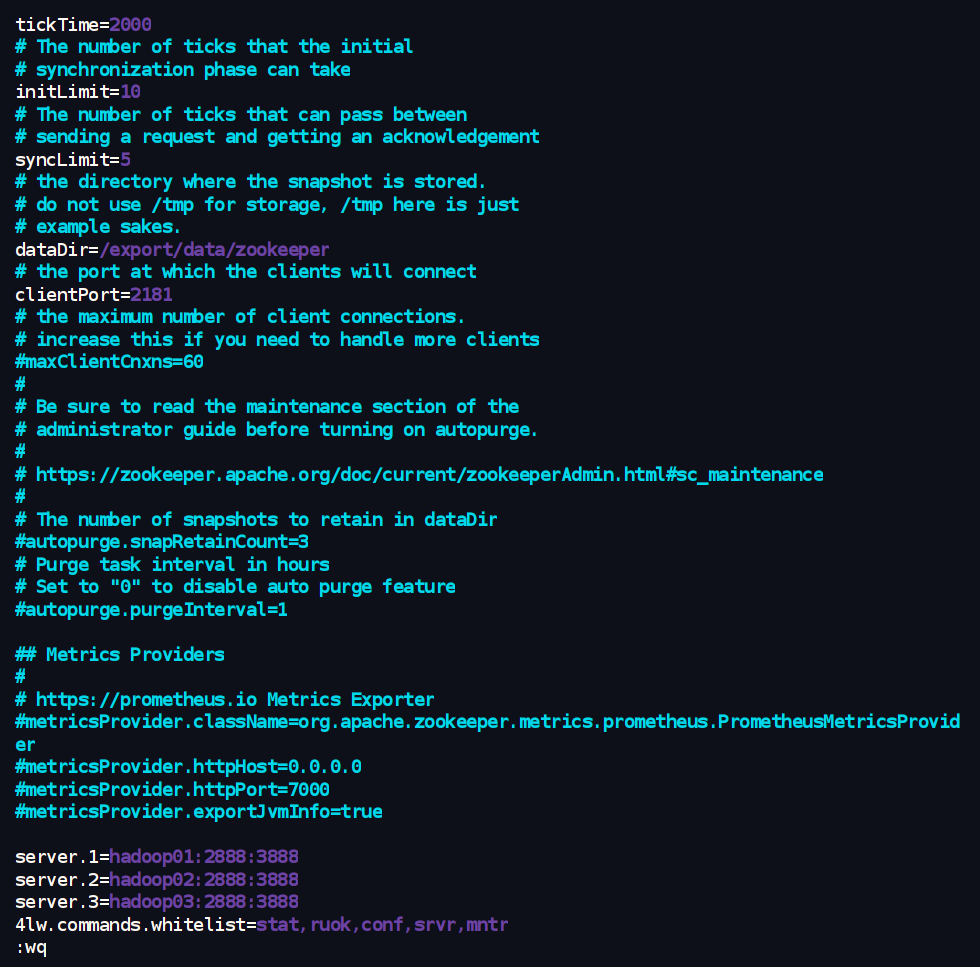
配置项重点:
dataDir=/export/data/zookeeper:指向您在步骤五中创建的数据目录。server.X=hostname:peerPort:leaderPort:X对应各节点的myid文件内容。hostname使用您的实际主机名 (hadoop01,hadoop02,hadoop03)。2888是集群内节点间通信端口。3888是Leader选举端口。
- 客户端将通过
clientPort=2181连接。
分发修改好的 zoo.cfg 文件 (在 hadoop01 上执行):
scp /export/server/zookeeper/conf/zoo.cfg root@hadoop02:/export/server/zookeeper/conf/
scp /export/server/zookeeper/conf/zoo.cfg root@hadoop03:/export/server/zookeeper/conf/
七、启动ZooKeeper集群服务 (所有节点均需操作)
在每一个节点 (hadoop01, hadoop02, hadoop03) 上启动ZooKeeper服务。
在 hadoop01, hadoop02, hadoop03 上分别执行:
zkServer.sh start
提示:建议逐个启动,并在每个节点启动后间隔几秒,以便集群有时间进行初始化和选举。
八、验证集群状态
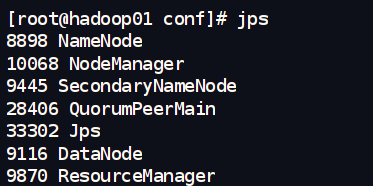
- 查看Java进程 (在任一节点执行):
jps
正常情况下,会看到一个名为 QuorumPeerMain 的Java进程。
- 查看节点角色 (在每个节点分别执行):
zkServer.sh status
此命令将显示当前节点是 Mode: leader 还是 Mode: follower。一个正常的3节点集群会有一个Leader和两个Follower。



九、常用ZooKeeper服务命令
这些命令通常在 ZOOKEEPER_HOME/bin 目录下,如果环境变量设置正确,可以直接执行。
# 启动ZooKeeper服务
zkServer.sh start
# 停止ZooKeeper服务
zkServer.sh stop
# 查看ZooKeeper服务状态(角色)
zkServer.sh status
# 重启ZooKeeper服务
zkServer.sh restart
# 在前台启动ZooKeeper服务(日志会直接输出到控制台)
zkServer.sh start-foreground
部署完成! ZooKeeper 集群现已配置完毕并准备就绪