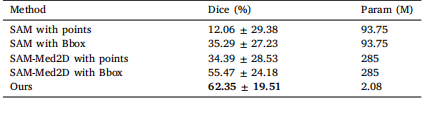
推荐深蓝学院的《深度神经网络加速:cuDNN 与 TensorRT》,课程面向就业,细致讲解CUDA运算的理论支撑与实践,学完可以系统化掌握CUDA基础编程知识以及TensorRT实战,并且能够利用GPU开发高性能、高并发的软件系统,感兴趣可以直接看看链接:深蓝学院《深度神经网络加速:cuDNN 与 TensorRT》

核心思想
论文的核心思想是针对传统 k k k-means++算法在大规模数据处理中的低效性和初始化敏感性问题,提出了一种基于MapReduce框架的高效 k k k-means++初始化方法。传统 k k k-means++通过概率选择初始中心来提高聚类质量,但其顺序性导致在大规模数据上需要多次数据扫描,计算开销大且难以并行化。论文通过设计仅使用一次MapReduce作业的初始化算法,将标准 k k k-means++初始化(Mapper阶段)和加权 k k k-means++初始化(Reducer阶段)结合,大幅减少通信和I/O成本,同时保持较好的聚类质量。此外,论文引入了基于三角不等式的剪枝策略,进一步减少冗余距离计算,从而提升算法效率。该方法特别适合处理海量数据(如TB或PB级),并在理论上证明了其对 k k k-means最优解的 O ( α 2 ) O(\alpha^2) O(α2)近似保证。
目标函数
k k k-means算法的目标是通过最小化平方误差和(Sum of Squared Error, SSE)来划分数据点到 k k k个簇。给定数据集 X = { x 1 , x 2 , … , x n } X = \{x_1, x_2, \ldots, x_n\} X={x1,x2,…,xn},其中 x i ∈ R d x_i \in \mathbb{R}^d xi∈Rd,目标是找到 k k k个中心集合 C = { c 1 , c 2 , … , c k } C = \{c_1, c_2, \ldots, c_k\} C={c1,c2,…,ck},使SSE最小:
SSE ( C ) = ∑ x ∈ X min c ∈ C ∥ x − c ∥ 2 \operatorname{SSE}(C) = \sum_{x \in X} \min_{c \in C} \|x - c\|^2 SSE(C)=x∈X∑c∈Cmin∥x−c∥2
其中, ∥ x − c ∥ \|x - c\| ∥x−c∥表示 x x x和 c c c之间的欧几里得距离。令 C OPT C_{\text{OPT}} COPT表示最优中心集合, S S E OPT SSE_{\text{OPT}} SSEOPT为其对应的SSE。一个解 C C C被称为 α \alpha α近似解,若满足:
SSE ( C ) ≤ α ⋅ S S E OPT \operatorname{SSE}(C) \leq \alpha \cdot SSE_{\text{OPT}} SSE(C)≤α⋅SSEOPT
传统 k k k-means++通过概率选择初始中心,达到 O ( α ) O(\alpha) O(α)近似保证。论文提出的MapReduce k k k-means++算法继承了这一目标函数,但在初始化阶段通过MapReduce框架优化中心选择过程,理论上证明其达到 O ( α 2 ) O(\alpha^2) O(α2)近似保证。
目标函数的优化过程
MapReduce k k k-means++算法的优化过程主要集中在初始化阶段,通过一次MapReduce作业选择 k k k个初始中心,然后结合标准的 k k k-means迭代优化SSE。优化过程分为Mapper阶段和Reducer阶段,具体如下:
-
Mapper阶段(标准 k k k-means++初始化):
- 输入:数据集 X = { x 1 , x 2 , … , x n } X = \{x_1, x_2, \ldots, x_n\} X={x1,x2,…,xn},簇数 k k k。
- 过程:
- 随机均匀选择第一个中心 c 1 c_1 c1,加入中心集合 C C C。
- 对于剩余的 k − 1 k-1 k−1个中心,计算每个点 x ∈ X x \in X x∈X到最近已选中心的距离 D ( x ) D(x) D(x),按概率 D ( x ) 2 ∑ x ∈ X D ( x ) 2 \frac{D(x)^2}{\sum_{x \in X} D(x)^2} ∑x∈XD(x)2D(x)2选择下一个中心,加入 C C C。
- 遍历所有数据点,计算每个点到最近中心的分配,并记录每个中心 c i c_i ci代表的点数 n u m [ i ] num[i] num[i]。
- 输出:键值对 ⟨ n u m [ i ] , c i ⟩ \langle num[i], c_i \rangle ⟨num[i],ci⟩,表示每个中心的点数和中心位置。
- 时间复杂度: O ( k n d ) O(knd) O(knd),其中 n n n是数据点数, d d d是维度。
-
Reducer阶段(加权 k k k-means++初始化):
- 输入:Mapper阶段输出的 ⟨ n u m [ i ] , c i ⟩ \langle num[i], c_i \rangle ⟨num[i],ci⟩集合。
- 过程:
- 随机均匀选择第一个中心,加入 C C C。
- 对于剩余的 k − 1 k-1 k−1个中心,计算每个点 x x x(来自Mapper输出的中心)到最近已选中心的距离 D ( x ) D(x) D(x),按加权概率 n u m ⋅ D ( x ) 2 ∑ x ∈ X n u m ⋅ D ( x ) 2 \frac{num \cdot D(x)^2}{\sum_{x \in X} num \cdot D(x)^2} ∑x∈Xnum⋅D(x)2num⋅D(x)2选择下一个中心,加入 C C C。
- 输出:最终的 k k k个中心集合 C = { c 1 , c 2 , … , c k } C = \{c_1, c_2, \ldots, c_k\} C={c1,c2,…,ck}。
- 目的:通过加权概率,考虑Mapper阶段每个中心的代表性(点数),提高中心选择的质量。
-
后续 k k k-means迭代:
- 使用Reducer阶段得到的初始中心,执行标准的
k
k
k-means算法(Lloyd迭代),即:
- 将每个数据点分配到最近的中心,更新簇。
- 计算每个簇的质心作为新的中心。
- 重复直到中心稳定或达到最大迭代次数。
- 使用Reducer阶段得到的初始中心,执行标准的
k
k
k-means算法(Lloyd迭代),即:
-
剪枝策略(改进版本):
- 基于三角不等式,减少距离计算:
- 定理2:若已有中心 o o o代表点集 B B B,新中心 c c c满足 ∥ o − c ∥ 2 ≥ 2 ∥ o − b ∥ 2 \|o - c\|^2 \geq 2\|o - b\|^2 ∥o−c∥2≥2∥o−b∥2( b b b是 B B B中最远的点),则 B B B中的点无需计算到 c c c的距离,仍属于 o o o。
- 推论1:若 ∥ o − c ∥ 2 < 2 ∥ o − b ∥ 2 \|o - c\|^2 < 2\|o - b\|^2 ∥o−c∥2<2∥o−b∥2,可找到点 d ∈ B d \in B d∈B,满足 ∥ o − c ∥ 2 = 2 ∥ o − d ∥ 2 \|o - c\|^2 = 2\|o - d\|^2 ∥o−c∥2=2∥o−d∥2,则距离 o o o小于等于 ∥ o − d ∥ 2 \|o - d\|^2 ∥o−d∥2的点无需计算到 c c c的距离。
- 这些规则通过几何约束(圆形区域)避免冗余计算,显著降低计算开销。
- 基于三角不等式,减少距离计算:
-
理论保证:
- 论文证明算法的SSE满足:
∑ x ∈ X min c ∈ C ∥ x − c ∥ 2 ≤ ( α 2 + 2 α ) ∑ x ∈ X min c ∈ C OPT ∥ x − c ∥ 2 \sum_{x \in X} \min_{c \in C} \|x - c\|^2 \leq (\alpha^2 + 2\alpha) \sum_{x \in X} \min_{c \in C_{\text{OPT}}} \|x - c\|^2 x∈X∑c∈Cmin∥x−c∥2≤(α2+2α)x∈X∑c∈COPTmin∥x−c∥2
即 O ( α 2 ) O(\alpha^2) O(α2)近似。证明基于三角不等式,考虑Mapper和Reducer阶段的中心选择误差。
- 论文证明算法的SSE满足:
主要的贡献点
- 高效MapReduce初始化:
- 提出仅用一次MapReduce作业选择 k k k个初始中心的算法,相比传统 k k k-means++的 2 k 2k 2k次MapReduce作业,大幅减少通信和I/O成本。
- 理论近似保证:
- 证明算法达到 O ( α 2 ) O(\alpha^2) O(α2)近似,略低于 k k k-means++的 O ( α ) O(\alpha) O(α),但仍优于随机初始化,且适合大规模数据。
- 剪枝策略:
- 引入基于三角不等式的剪枝方法,显著减少冗余距离计算,尤其在高维和大规模数据上效果明显。
- 实验验证:
- 在真实(Oxford Buildings)和合成数据集上验证了算法的高效性和近似质量,优于随机初始化和部分并行 k k k-means++实现。
- 系统实现:
- 在Hadoop上实现,解决了全局信息通信(通过Job Configuration和Distributed Cache)和数据流处理(通过cleanup函数)等技术问题。
实验结果
实验在一个由12台机器组成的Hadoop集群上进行(1主节点,11从节点,每节点2核CPU、8GB内存),使用Hadoop 0.20.2,数据集包括:
- Oxford Buildings数据集:5062张图像,提取17M+个128维SIFT特征,5.67GB。
- 合成数据集:20M+个128维点,围绕5000个中心生成,15GB。
主要实验结果如下:
-
效率比较(MapReduce k k k-means++ vs 可扩展 k k k-means++):
- MapReduce k k k-means++仅需一次MapReduce作业,而可扩展 k k k-means++需要多次作业,导致更高的通信和I/O成本。单机迭代替换多机迭代显著提升效率。
-
近似质量(MR-KMI vs MR-RI):
- 在Oxford数据集上,MR-KMI的SSE比MR-RI低约 10 11 10^{11} 1011( k = 1000 k=1000 k=1000至5000),且更稳定。
- 在合成数据集上,MR-KMI的SSE比MR-RI低2个数量级( 10 10 10^{10} 1010 vs 10 12 10^{12} 1012),当 k = 5000 k=5000 k=5000时,MR-KMI的SSE约为MR-RI的1/13(表2)。
- MR-KMI的初始化更接近最终解,Oxford数据集上SSE初始化/SSE迭代=5为1.41(MR-KMI)vs 1.53(MR-RI),合成数据集为1.96 vs 47.39。
-
近似质量(MR-KM++ vs MR-KM):
- 在Oxford数据集上,MR-KM++的SSE在5次迭代后比MR-KM低,最大差距在第一次迭代( 3 × 10 10 3 \times 10^{10} 3×1010)。
- 在合成数据集上,MR-KM++的SSE约为MR-KM的1/10(第一次迭代),且在3-5次迭代后稳定(约 1.02 × 10 10 1.02 \times 10^{10} 1.02×1010,表3),显示更快收敛。
-
剪枝策略效率(IMR-KMI vs MR-KMI):
- 在合成数据集上,IMR-KMI在Reducer阶段减少99%的距离计算,Mapper阶段减少96%(表5)。
- 在Oxford数据集上,减少幅度较小,但随 k k k增加更显著,最大减少18.6%(Mapper, k = 5000 k=5000 k=5000)和22.4%(Reducer, k = 5000 k=5000 k=5000,表4)。
- 剪枝效果在合成数据集上更强,可能因其点分布更规则。
算法的实现过程
以下是MapReduce k k k-means++算法的详细实现过程,结合伪代码说明:
Input: 数据集 X = {x_1, x_2, ..., x_n}, 簇数 k
Output: 初始中心集合 C = {c_1, c_2, ..., c_k}
1. Mapper阶段:
for 每个 Mapper 任务 do
// 初始化
C ← ∅
随机均匀选择 x ∈ X 作为第一个中心,C ← C ∪ {x}
num[i] ← 0, ∀i=1,...,k
// 选择 k 个中心
while |C| < k do
计算 D(x) = min_{c ∈ C} ||x - c||^2, ∀x ∈ X
按概率 P(x) = D(x)^2 / Σ_{x ∈ X} D(x)^2 选择 x
C ← C ∪ {x}
// 分配点并计数
for 每个 x_i ∈ X do
找到最近的中心 c_j ∈ C
num[j] ← num[j] + 1
输出 <num[j], c_j>, ∀j=1,...,k
end
2. Reducer阶段:
// 初始化
C ← ∅
随机均匀选择 x ∈ {<num, c>} 作为第一个中心,C ← C ∪ {x}
// 选择 k 个中心
while |C| < k do
计算 D(x) = min_{c ∈ C} ||x - c||^2, ∀x ∈ {<num, c>}
按加权概率 P(x) = num * D(x)^2 / Σ_{x} num * D(x)^2 选择 x
C ← C ∪ {x}
输出 C
3. 剪枝策略(IMR-KMI):
for 每个新中心 c do
for 每个已有中心 o 及其点集 B do
找到 B 中最远点 b,满足 ||o - b||^2 最大
if ||o - c||^2 ≥ 2 ||o - b||^2 then
B 中的点无需计算到 c 的距离,仍属于 o
else
找到 d 满足 ||o - c||^2 = 2 ||o - d||^2
对 B 中满足 ||o - x||^2 ≤ ||o - d||^2 的点,无需计算到 c 的距离
end
end
end
4. k-means迭代:
使用 C 执行标准 k-means:
分配每个点到最近中心,更新簇
计算簇质心作为新中心
重复直到收敛
实现细节:
- Hadoop实现:
- 使用Job Configuration传递小量全局信息,Distributed Cache传递大数据。
- 通过cleanup函数处理Mapper和Reducer中的顺序计算,解决数据流式处理的限制。
- Mapper阶段:
- 每个Mapper处理64MB数据块,独立运行 k k k-means++初始化。
- 输出中心及其代表点数,供Reducer使用。
- Reducer阶段:
- 使用加权概率整合Mapper结果,选择最终 k k k个中心。
- 剪枝策略:
- 在Mapper和Reducer阶段应用定理2和推论1,基于几何约束(圆形区域)跳过不必要的距离计算。
- 时间复杂度:
- Mapper阶段: O ( k n d ) O(knd) O(knd),Reducer阶段: O ( k m d ) O(kmd) O(kmd)( m m m是Mapper输出中心数, m ≪ n m \ll n m≪n)。
- 剪枝策略显著降低实际计算量,尤其在合成数据集上。
总结
MapReduce k k k-means++算法通过一次MapReduce作业实现高效初始化,结合剪枝策略和理论证明,解决了传统 k k k-means++在大规模数据上的低效问题。其在真实和合成数据集上的实验结果验证了其高效性和良好的近似质量,特别适合云计算环境下的海量数据聚类任务。