目录
一、蜂窝热力地图
1. 特点
(1)优点
(2)缺点
2. 应用场景
3.python代码实现
(1)代码
(2)实现结果
二、变形地图
1. 特点
(1)优点
(2)缺点
2. 应用场景
3.python代码实现
(1)代码
(2)实现结果
三、关联地图
1. 特点
(1)优点
(2)缺点
2. 应用场景
3.python代码实现
(1)代码
(2)实现结果
四、气泡地图
1.特点
(1)优点
(2)缺点
2.应用场景
3.python代码实现
(1)代码
(2)实现结果
五、三维地形图
1.图表特点
(1)优点
(2)缺点
2.应用场景
3.python代码实现
(1)代码
(2)实现结果
六、河流和水系分布图
1.图表特点
(1)优点
(2) 缺点
2.应用场景
3.python代码实现
(1)代码
(2)实现结果
七、总结
一、蜂窝热力地图
1. 特点
蜂窝热力地图通过六边形(蜂窝)网格来展示数据的密度和强度,而不是传统的矩形网格。每个六边形区域的颜色深浅表示数据的密度或强度。该地图常用于展示大量数据点的分布,尤其是在较为密集的区域中。与点图相比,蜂窝热力图能够有效避免重叠和数据的丢失。
(1)优点
-
减少点重叠:蜂窝网格比矩形网格更加均匀,能够避免因数据点过多而导致的重叠。
-
平滑展示数据:蜂窝热力图可以通过颜色强度平滑地展示数据,特别适合处理大量数据点的可视化。
-
直观性:相比传统的热力图,蜂窝热力图能提供更清晰的空间分布感知,使得热区或热点区域一目了然。
-
灵活性:可以灵活调整网格大小,改变数据密度和展示效果,适应不同的数据分布特点。
(2)缺点
-
计算复杂度:蜂窝热力图需要在构建过程中计算六边形网格的中心点和周围的邻接关系,相比点图可能更为复杂。
-
适用性限制:对于较少或分布稀疏的数据,蜂窝热力图的效果可能不如点图直观,因为六边形网格的布局会导致一些空间的浪费。
-
较难解释:某些用户可能不熟悉六边形网格,相较于矩形网格,它可能需要额外的解释和说明。
2. 应用场景
蜂窝热力图适用于那些空间分布较为密集的数据集,可以帮助展示数据密度的变化,常见的应用场景包括:
-
城市交通流量分析:分析城市道路的交通密度,通过蜂窝网格来展示不同区域的交通状况。
-
地理数据可视化:例如,展示人口分布、疾病传播、商店位置等。
-
环境监测:如展示某地区的空气质量、污染物分布、温度变化等。
-
电商数据分析:在电商平台分析用户点击、购买行为等,展示某一商品或区域的热度。
-
物理实验数据分析:例如,粒子运动的分布,或者卫星图像的处理。
3.python代码实现
(1)代码
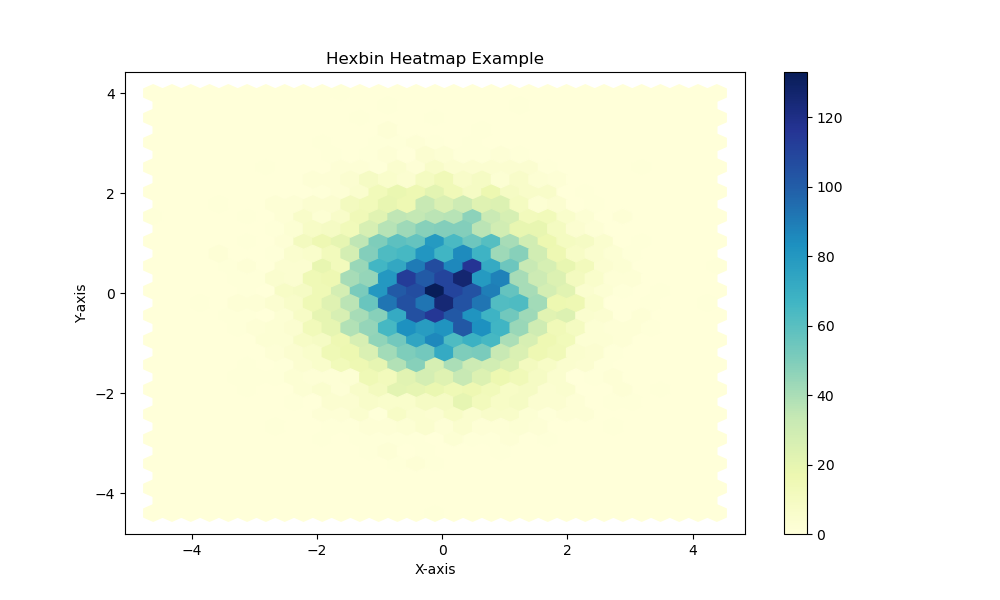
import numpy as np
import matplotlib.pyplot as plt
# 生成模拟数据:10000个随机点
x = np.random.randn(10000)
y = np.random.randn(10000)
# 创建一个六边形网格,使用hexbin函数
plt.figure(figsize=(10, 6))
hb = plt.hexbin(x, y, gridsize=30, cmap='YlGnBu') # gridsize 控制蜂窝大小,cmap 控制颜色
plt.colorbar(hb) # 显示颜色条,表示密度
plt.title("Hexbin Heatmap Example")
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
# 显示热力图
plt.show()
(2)实现结果
二、变形地图
变形地图是一种通过调整地图的形状,使其地理区域的大小与某一特定数据(如人口、GDP、选票数等)成比例的地图。变形地图可以有效地展示区域之间在某些数据维度上的差异,而不仅仅是地理位置和面积的显示。它的核心思想是通过数据变形让用户更直观地感知数据的分布。
1. 特点
变形地图通过缩放、拉伸或压缩地图区域来反映某一特定数据值,使地图的空间格局按照数据的变化进行调整。
(1)优点
-
直观展示数据差异:变形地图能够突出展示不同区域之间的相对差距,尤其是在人口、GDP、选举结果等数据差异较大的情况下。
-
减少地理因素干扰:通过将区域大小与数据值挂钩,变形地图让用户能够专注于数据本身,而非地理形状。
-
有效传达大范围的差异:特别适合展示那些相同区域尺度下数据差距巨大的情况,传统地图可能无法清楚地表达这些差异。
(2)缺点
-
失真:由于地图区域会被变形,地图的地理准确性会受到影响,可能导致用户对地图的空间关系产生误解。
-
视觉难度:变形地图有时较为抽象,可能让某些用户(尤其是没有空间数据背景的人)难以理解。
-
信息过载:如果地图上的变形程度过大,可能会导致数据解读的困难,影响地图的可读性。
2. 应用场景
变形地图在许多领域中都有广泛应用,特别是在需要突出展示某些数据差异或强调数据关系的场景中。
-
选举结果分析:变形地图常用于展示各选区的得票比例、人口分布等,尤其在美国总统选举中经常看到。例如,通过变形地图展示每个州的选举结果,可以更直观地反映选票的分布和强弱。
-
人口分布:可以根据人口数量对各地区的大小进行调整,突出人口密度较高的区域。
-
经济分析:如展示各国或各地区的GDP、收入等经济指标,通过地图变形突出经济强国或地区。
-
资源分布:可以展示能源、资源的分布情况,例如各国或各省的煤炭、石油储量,或是全球水资源的分布。
-
疾病传播分析:在公共卫生研究中,变形地图可以显示某些地区的病例数、传染病流行程度等,帮助更直观地理解疫情的影响范围。
3.python代码实现
数据来源:Natural Earth - Free vector and raster map data at 1:10m, 1:50m, and 1:110m scales![]() https://www.naturalearthdata.com/
https://www.naturalearthdata.com/
(1)代码
import geopandas as gpd
import matplotlib.pyplot as plt
import numpy as np
# 直接读取本地shapefile文件
world = gpd.read_file(
"G:/数据可视化技术/地理特征类可视化图像总结/ne_110m_admin_0_countries/ne_110m_admin_0_countries.shp")
# 过滤掉南极洲(如果存在)
if 'continent' in world.columns:
world = world[world.continent != 'Antarctica']
else:
print("警告:数据中未找到'continent'列,无法过滤南极洲")
# 确保人口数据是数值类型
if 'pop_est' in world.columns:
world['pop_est'] = world['pop_est'].astype(float)
else:
# 如果数据中没有pop_est列,尝试使用其他可能的人口列
pop_col = None
for col in ['POP_EST', 'population', 'pop']:
if col in world.columns:
pop_col = col
break
if pop_col:
world['pop_est'] = world[pop_col].astype(float)
else:
raise ValueError("数据中找不到人口估计列,请检查数据")
# 创建简化的变形地图 - 基于比例缩放
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 10))
# 原始地图
world.plot(ax=ax1, column='pop_est', cmap='OrRd', legend=True,
legend_kwds={'label': "Population Estimate"})
ax1.set_title('Original World Map')
# 创建变形地图 - 简化的比例缩放方法
world_scaled = world.copy()
scale_factor = np.sqrt(world['pop_est'] / world['pop_est'].mean())
world_scaled = world.copy() # 创建副本用于缩放
# 对每个几何图形应用缩放
from shapely.affinity import scale
world_scaled['geometry'] = [scale(geom, xfact=sf, yfact=sf, origin='center')
for geom, sf in zip(world.geometry, scale_factor)]
# 绘制变形地图
world.plot(ax=ax2, color='lightgray', edgecolor='none')
world_scaled.plot(ax=ax2, column='pop_est', cmap='OrRd', legend=True)
ax2.set_title('Simplified Population Cartogram')
plt.tight_layout()
plt.show()
(2)实现结果

三、关联地图
关联地图(也叫色块图、分级地图)是一种常见的地理可视化图形,它通过将数据值的不同范围映射到地图上的不同颜色,用以展示空间数据的分布情况。这类地图通常用于展示某些区域的统计数据,如人口密度、收入水平、选举结果等。
1. 特点
(1)优点
-
直观性强:通过颜色的深浅或饱和度,关联地图能够直观地展示各区域数据的差异。
-
数据展示清晰:颜色的渐变帮助观众快速识别出某个区域的相对强度(如人口密度高低、经济水平等)。
-
易于理解:对于大多数人而言,颜色变化是一种直观的信号,能够快速理解数据分布。
-
广泛应用:常用于展示行政区划(如国家、省份、市区)的各种数据,尤其是在地理上存在明显差异时,效果尤为突出。
(2)缺点
-
颜色选择依赖:不恰当的颜色选择可能导致地图的可读性差,尤其是在色盲用户中。
-
数据分布问题:如果数据分布不均,可能导致某些区域过于突出,而其他区域的信息被隐藏。
-
细节缺失:如果区域内的数据差异很小,可能很难通过颜色变化来区分。
-
误导性:如果分级过粗或过细,可能导致错误的解读,影响数据的准确性。
2. 应用场景
-
人口统计:例如,展示不同国家或省份的人口数量、人口密度等。
-
经济分析:展示各地区的GDP、收入水平或失业率等经济指标。
-
选举结果:展示不同选区的选举得票情况,通常使用颜色深浅来区分不同的得票比例。
-
气候变化:展示不同地区的气温变化、降水量等环境数据。
-
公共卫生:展示某种疾病的发病率或疫苗接种率,帮助决策者制定策略。
-
犯罪率:展示不同地区的犯罪率或其他社会现象的发生频率。
3.python代码实现
数据来源:Natural Earth - Free vector and raster map data at 1:10m, 1:50m, and 1:110m scales![]() https://www.naturalearthdata.com/
https://www.naturalearthdata.com/
(1)代码
import geopandas as gpd
import matplotlib.pyplot as plt
from matplotlib import font_manager
# 加载Shapefile文件
world = gpd.read_file(r"G:\数据可视化技术\地理特征类可视化图像总结\ne_110m_admin_0_countries\ne_110m_admin_0_countries.shp")
# 查看所有列名,确认合适的列名
print(world.columns)
# 查看数据框的前几行,确认合适的列名
print(world.head())
# 绘制一个基于 'SOVEREIGNT' 列的地图
fig, ax = plt.subplots(figsize=(12, 8))
# 绘制颜色,使用 'SOVEREIGNT' 列,并且启用图例
world.plot(column='SOVEREIGNT',
cmap='Set3',
linewidth=0.8,
ax=ax,
edgecolor='0.8',
legend=True,
legend_kwds={'title': 'Countries', 'loc': 'center left',
'bbox_to_anchor': (1, 0.5)})
# 设置图例为2列(使用ncol参数)
legend = ax.get_legend()
legend.set_bbox_to_anchor((1.05, 0.5)) # 图例位置,避免与地图重叠
legend.set_title("Countries") # 设置图例标题
# 设置图例字体大小
for label in legend.get_texts():
label.set_fontsize(10)
# 设置图例列数为2
legend.set_ncols(2)
# 添加标题
plt.title("Map of Countries", fontsize=16)
# 调整图表右边距以避免图例被裁剪
plt.subplots_adjust(right=0.85) # 增加右边距
# 显示图像
plt.show()
(2)实现结果

四、气泡地图
气泡地图是一种非常适合展示地理分布和数值关系的可视化方法,特别适用于展示数量差异较大的数据。但在使用时,需要注意气泡重叠、失真等问题,并确保数据的可视化效果清晰且不产生误导。
1.特点
(1)优点
-
直观易懂:气泡地图通过不同大小的气泡来展示数据量的大小,能够直观地展示不同地区或类别之间的数据差异。
-
展示多维数据:除了地理位置,气泡的大小通常还代表数据的数量或比率,部分气泡地图还可以通过颜色来表示另一种属性,允许同时展示两个变量。
-
互动性强:气泡地图适合在交互式图表中使用,用户可以点击或悬浮查看具体信息,提供丰富的用户体验。
-
突出重点:通过气泡大小的变化,可以非常清楚地展示某些地区或类别的重要性或突出数据。
(2)缺点
-
易于混淆:当多个气泡重叠或距离很近时,可能导致数据难以准确阅读,尤其是当气泡之间的间距过小或数据量非常大的时候。
-
可能失真:气泡的大小在视觉上可能不完全等比,特别是当数据量的差异很大时,视觉上可能给人造成误导。
-
需要合适的数据:气泡地图的效果依赖于地理数据和对应的数值数据,如果数据不完整或者没有很好的地理分布,效果可能不理想。
-
无法表示极小的差异:气泡地图在展示非常小的差异时可能不够精确,因为气泡大小的可视化受限于显示屏分辨率。
2.应用场景
-
人口分布:气泡地图可以用来展示世界各国或城市的总人口数量,或者某个特定区域内的密度情况。
-
销售数据分析:公司可以使用气泡地图来展示不同地区的销售额、市场份额或客户数量等,帮助决策者了解市场状况。
-
疾病传播:气泡地图可用于展示疾病病例分布情况,气泡的大小表示病例数量,气泡的位置表示感染的地理区域。
-
天气数据:展示不同地区的天气信息,如降水量、气温等,气泡大小可表示降水量的多少或温度的高低。
-
经济数据:例如展示各个国家或地区的GDP、失业率、资源消耗量等,气泡可以很容易地展示这些数据的差异。
3.python代码实现
(1)代码
import plotly.express as px
import pandas as pd
# 示例数据 - 你可以替换为自己的数据
data = {
'City': ['北京', '上海', '广州', '深圳', '成都', '重庆', '武汉', '西安', '杭州', '南京'],
'Lat': [39.9042, 31.2304, 23.1291, 22.5431, 30.5728, 29.5630, 30.5928, 34.3416, 30.2741, 32.0603],
'Lon': [116.4074, 121.4737, 113.2644, 114.0579, 104.0668, 106.5516, 114.3052, 108.9398, 120.1551, 118.7969],
'Population': [2171, 2424, 1404, 1303, 1658, 3102, 1121, 1233, 1036, 850], # 单位:万人
'GDP': [3610, 3870, 2363, 2244, 1701, 2295, 1562, 1002, 1611, 1482] # 单位:十亿元
}
df = pd.DataFrame(data)
# 创建气泡地图
fig = px.scatter_geo(df,
lat='Lat',
lon='Lon',
size='Population', # 气泡大小由人口决定
color='GDP', # 气泡颜色由GDP决定
hover_name='City', # 悬停时显示城市名
projection='natural earth', # 地图投影类型
title='中国主要城市人口与GDP气泡地图',
size_max=50, # 最大气泡大小
scope='asia') # 地图范围为亚洲
# 自定义布局
fig.update_geos(
resolution=50,
showcoastlines=True,
coastlinecolor="RebeccaPurple",
showland=True,
landcolor="LightGreen",
showocean=True,
oceancolor="LightBlue",
showlakes=True,
lakecolor="Blue",
showrivers=True,
rivercolor="Blue"
)
# 显示图表
fig.show()
# 如果需要保存为HTML文件
# fig.write_html("bubble_map.html")(2)实现结果
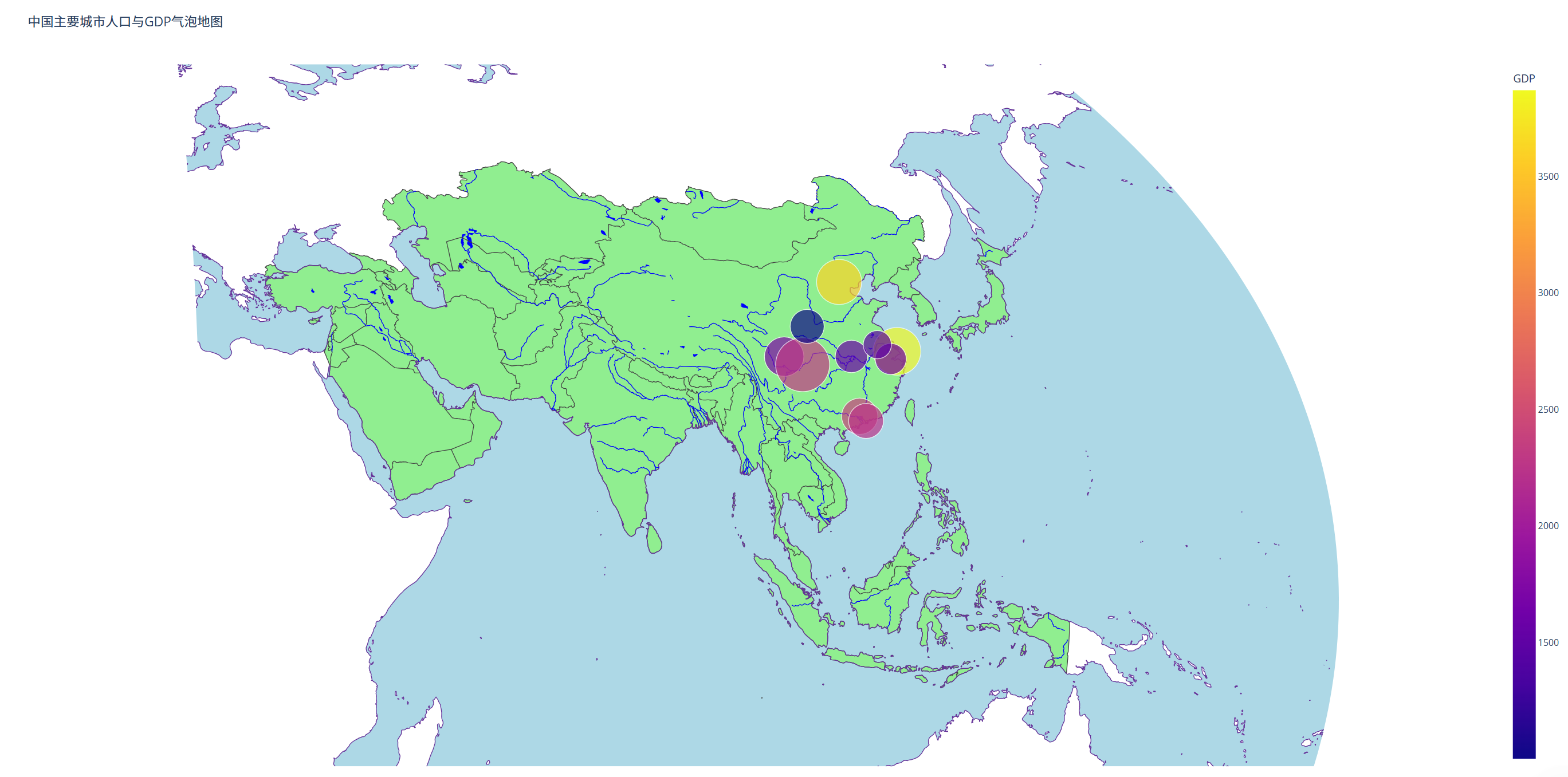
五、三维地形图
三维地形图是一种用于可视化地表高程信息的图表类型,通过三维坐标系展现地形的起伏变化,横轴表示地理空间位置(通常为经度和纬度或 X、Y),纵轴表示高程或海拔(Z轴)。 三维地形图是地理信息可视化中的核心工具之一,它弥补了二维地图在地貌表现上的不足,使用户能够更加直观地理解地形结构和空间关系。
1.图表特点
(1)优点
-
直观表达地貌特征:可清晰反映山脉、盆地、丘陵等地貌形态。
-
增强空间感知:三维视角提升对地形空间关系的理解。
-
可融合多源数据:如叠加降水、植被、土地利用等信息进行综合分析。
-
支持交互探索:旋转、缩放视角便于从不同角度审视地貌结构(尤其使用 Plotly、Cesium 等工具)。
(2)缺点
-
渲染性能要求高:高精度 DEM 数据处理和三维渲染对内存和图形处理器要求较高。
-
交互复杂度增加:相比平面图表,用户需要操作三维交互界面理解数据信息。
-
误读风险:若没有比例控制,垂直 exaggeration(垂直夸张)可能导致对地形高度误解。
-
数据获取和处理门槛高:需获取高质量 DEM 数据,处理可能涉及 GIS 专业工具。
2.应用场景
-
自然地理与环境分析:山地形态分析、流域划分;土壤侵蚀、洪水淹没模拟。
-
城市与区域规划:建筑选址、交通线路设计;可视域分析、遮挡分析。
-
工程地质与灾害预警:滑坡危险区划、地震断层展示;道路/铁路沿线稳定性分析。
-
旅游与文化展示:景区全貌展示、沉浸式导航系统;虚拟仿真导览(如数字黄山)。
3.python代码实现
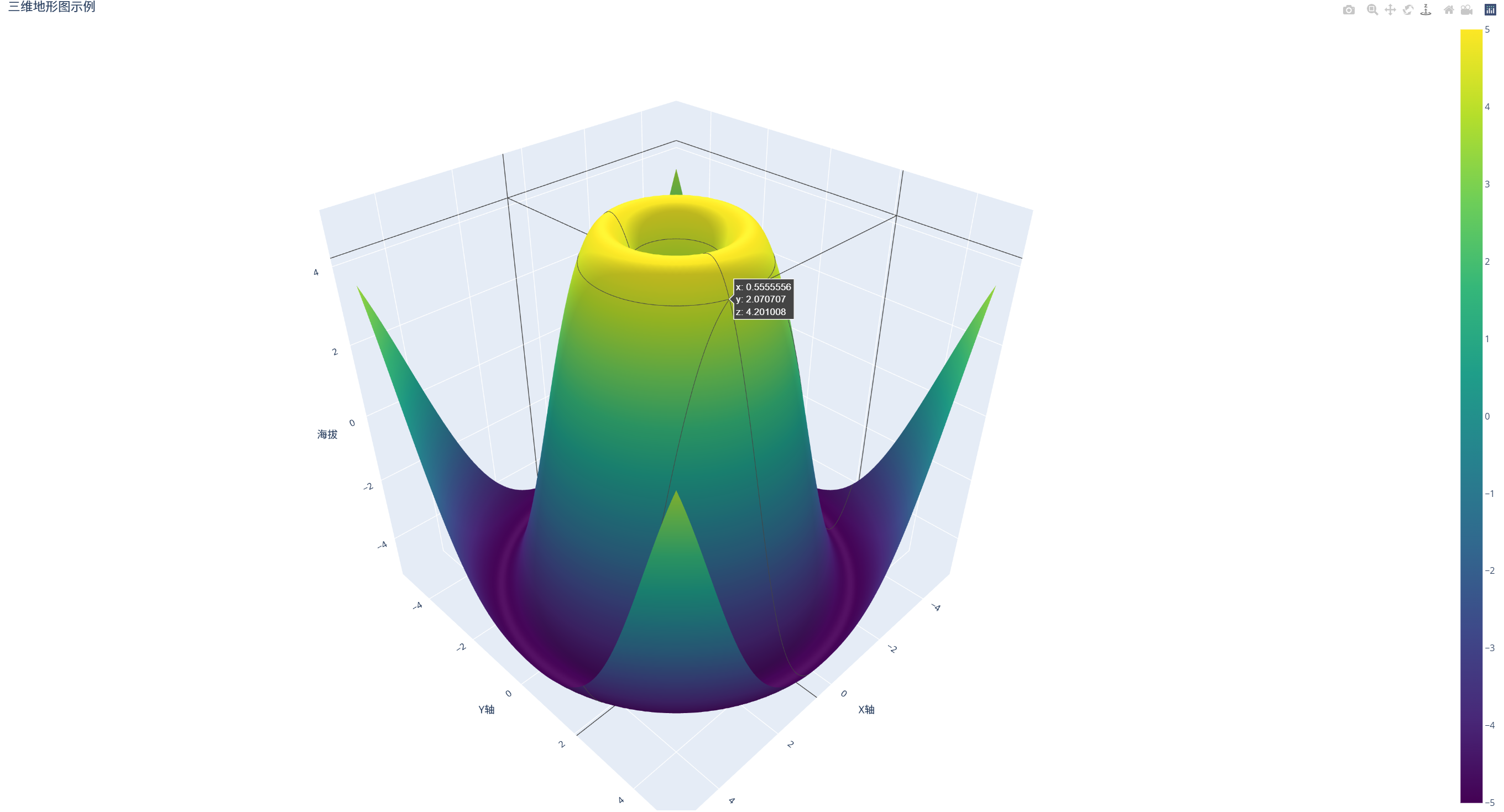
(1)代码
import numpy as np
import plotly.graph_objects as go
# 创建模拟的山地地形数据
x = np.linspace(-5, 5, 100)
y = np.linspace(-5, 5, 100)
x, y = np.meshgrid(x, y)
z = np.sin(np.sqrt(x**2 + y**2)) * 5 # 模拟地形起伏
# 绘制三维地形图
fig = go.Figure(data=[go.Surface(z=z, x=x, y=y, colorscale='Viridis')])
# 配置图表参数
fig.update_layout(
title='三维地形图示例',
scene=dict(
xaxis_title='X轴',
yaxis_title='Y轴',
zaxis_title='海拔',
),
autosize=True,
margin=dict(l=0, r=0, b=0, t=30)
)
# 展示图表
fig.show()
import numpy as np
import plotly.graph_objects as go
# 创建更复杂的地形数据
x = np.linspace(-6, 6, 200)
y = np.linspace(-6, 6, 200)
x, y = np.meshgrid(x, y)
# 更复杂的地形函数(山谷+山脊+波动)
z = (
np.sin(x) * np.cos(y) * 3 +
np.exp(-(x**2 + y**2) / 10) * 5 +
np.sin(x * y / 2)
)
# 绘制三维地形图
fig = go.Figure(data=[
go.Surface(
z=z, x=x, y=y,
colorscale='Turbo',
contours={"z": {"show": True, "usecolormap": True, "highlightcolor": "limegreen", "project_z": True}},
lighting=dict(ambient=0.5, diffuse=0.8, specular=0.5, roughness=0.9, fresnel=0.1),
lightposition=dict(x=100, y=200, z=100)
)
])
# 配置图表
fig.update_layout(
title='三维模拟地形图',
scene=dict(
xaxis_title='X 坐标',
yaxis_title='Y 坐标',
zaxis_title='海拔',
aspectratio=dict(x=1, y=1, z=0.5)
),
margin=dict(l=0, r=0, t=40, b=0)
)
# 显示图表
fig.show()
(2)实现结果
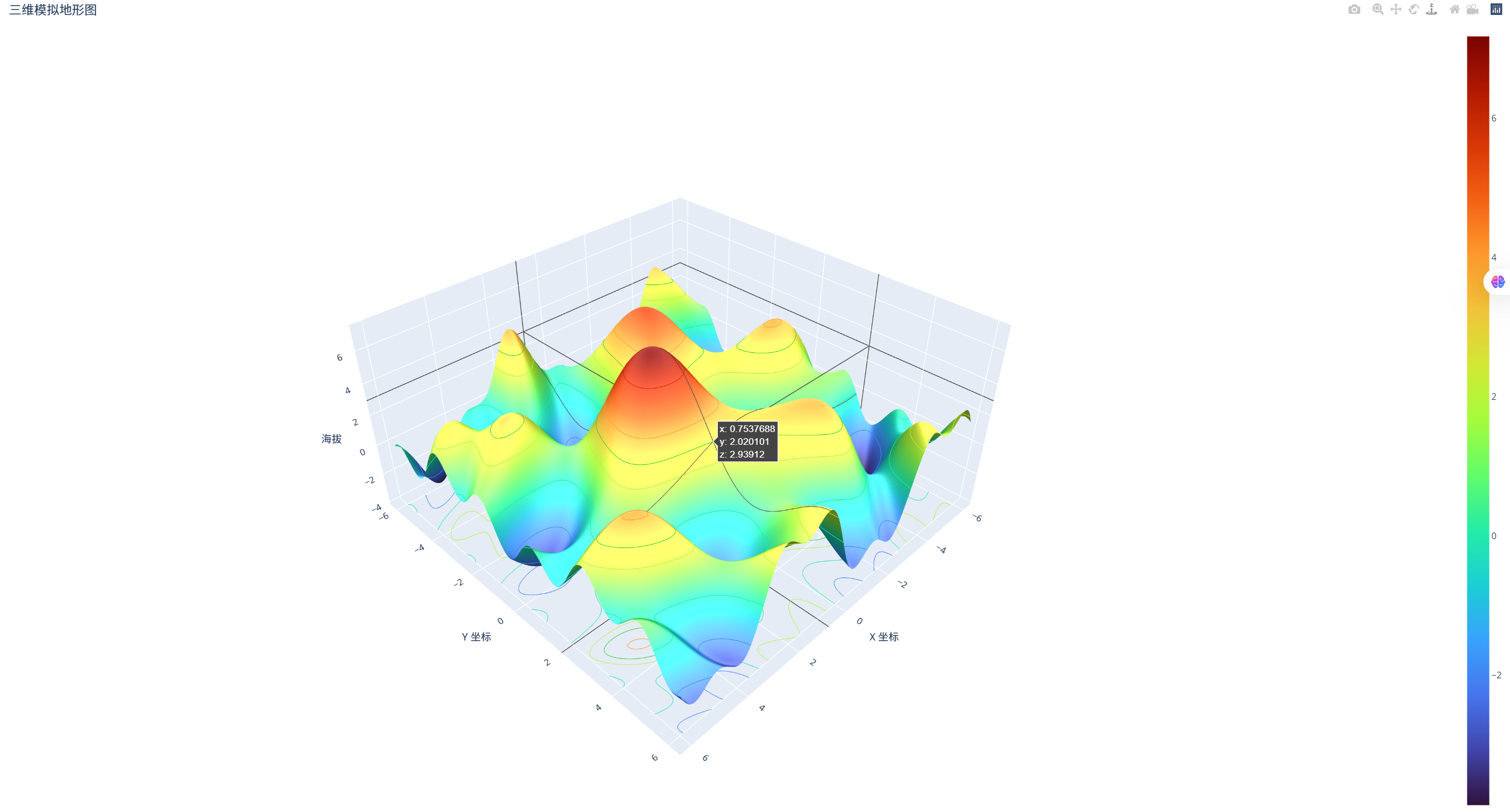
六、河流和水系分布图
河流和水系分布图是一种以地理信息为基础、展示河流、支流、湖泊、水库等水文要素的地图。它可以是二维静态地图,也可以叠加在数字高程模型上形成三维水文可视化。 河流与水系分布图是一种在环境、工程、生态、水文等领域应用广泛的地理图表。它能够反映自然水文格局,辅助资源管理与环境保护决策。配合地形和人口数据使用,其价值在空间分析中尤为突出。
1.图表特点
(1)优点
-
空间布局清晰:能直观表现主河道、支流、湖泊和流域结构。
-
支持水文分析:可用于流域划分、径流路径分析、水资源估算等。
-
可结合其他图层:如叠加地形图、土地利用图、人口分布图,辅助决策。
-
图形表达多样:线状(河流)、面状(湖泊、湿地)表达自然贴合。
(2) 缺点
-
依赖高质量数据:需要准确的水文矢量数据或遥感提取结果。
-
动态模拟受限:静态地图难以表现水流变化(需与建模软件结合)。
-
空间尺度局限:过大区域下支流细节会丢失,过小区域缺乏整体性。
-
表现复杂水文结构时混乱:交叉支流、湖网分布较难理清层次。
2.应用场景
-
水资源管理与规划:水利工程选址与设计(如水库、灌渠);水资源调度与跨流域引水方案评估。
-
生态保护与流域管理:生态流量分析、水生态连通性研究;流域综合治理与土地规划。
-
防洪与灾害预警:洪水路径模拟、积水易发区定位;山洪灾害风险区划。
-
遥感与水体监测:基于卫星数据的水体识别与时序变化分析;干旱监测与水位估测。
-
地理教育与展示:河流类型教学(顺直型、曲流型、分汊型);流域分级与水文循环示意 。
3.python代码实现
(1)代码
import geopandas as gpd
import matplotlib.pyplot as plt
# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 或 ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取河流矢量数据
river_path = "G:\\数据可视化技术\\地理特征类可视化图像总结\\342a8-main\\342a8-main\\全国河流矢量shp文件\\全国河流.shp"
rivers = gpd.read_file(river_path)
# 读取省界矢量数据
province_path = "G:\\数据可视化技术\\地理特征类可视化图像总结\\中国行政区划shp数据\\中国行政区划shp数据\\中国行政区划shp数据-2023年2月12日版\\中国行政区划shp数据-2023年2月12日版\\2023年\\2023年省级\\省级.shp"
provinces = gpd.read_file(province_path)
# 创建图形
fig, ax = plt.subplots(figsize=(12, 12), facecolor='whitesmoke')
# 绘制省界
provinces.boundary.plot(ax=ax, edgecolor='black', linewidth=0.8)
# 绘制河流
rivers.plot(ax=ax, color='deepskyblue', linewidth=1)
# 设置标题和背景
ax.set_title('中国河流与水系分布图', fontsize=18, fontweight='bold')
ax.set_facecolor('aliceblue')
ax.set_axis_off()
plt.tight_layout()
plt.show()
(2)实现结果

七、总结
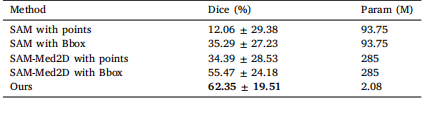
| 序号 | 图表类型 | 主要特点 | 应用场景 | Python实现库/方法 |
| 1 | 蜂窝热力图 | 1.避免数据点重叠,展示密度变化直观,图形简洁 2.网格划分影响精度,可能掩盖个别极端值 | 城市人流热区、共享单车聚集区、交通流量、商业密集分布 | matplotlib.hexbin() |
| 2 | 变形地图 | 1.直观反映数值差异,增强对抽象数据的理解 2.地理形状失真,难以定位实际地理位置 | 按人口、GDP重新绘制国家、省份图,用于选举结果、资源分布等 | geopandas.plot(column=...) |
| 3 | 关联地图 | 1.显示地理单位间属性差异,颜色识别度高 2.颜色选择敏感,视觉误差可能误导 | 人口密度图、选举结果图、疫情分布、空气质量指数 | geopandas.plot() with colormap |
| 4 | 气泡地图 | 1.强调数值差异,美观可视化空间关系 2.气泡重叠影响阅读,面积与感知不线性 | 城市人口、资源点分布、事故地点、经济产值 | plotly.express.scatter_geo() |
| 5 | 三维地形图 | 1.展示真实地形,模拟光影增强沉浸感 2.渲染成本高,交互性依赖强 | 地貌分析、工程规划、环境模拟、洪水预测 | plotly.graph_objects.Surface() |
| 6 | 河流分布图 | 1.反映水系结构,可叠加图层 2.需高质量矢量数据,静态图交互性差 | 水文研究、水资源规划、生态评估、环境监测 | geopandas + matplotlib |