新建项目 创建一个新的虚拟环境
- 创建新的虚拟环境(大多数时候都需要指定python的版本号才能顺利创建):
conda create -n bert_classification python=3.9
- 激活虚拟环境:
conda activate myenv
PS:虚拟环境可以避免权限问题,并隔离项目依赖
权限问题的报错:
ERROR: Could not install packages due to an OSError: [WinError 5] 拒绝访问。: 'd:\\anaconda3\\lib\\site-package
s\\__pycache__\\typing_extensions.cpython-39.pyc'
Consider using the `--user` option or check the permissions.
WARNING: Ignoring invalid distribution -ip (d:\anaconda3\lib\site-packages)
WARNING: Ignoring invalid distribution -ip (d:\anaconda3\lib\site-packages)
WARNING: Ignoring invalid distribution -ip (d:\anaconda3\lib\site-packages)
在项目中进行配置

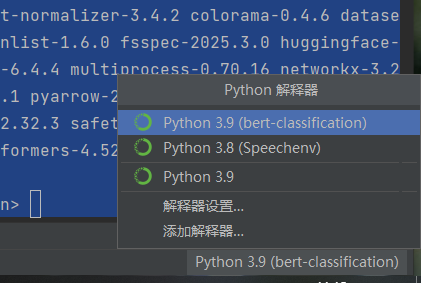
配置相关的库
pip install transformers datasets evaluate torch
训练脚本(train_bert.py)如下:
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
import evaluate
import numpy as np
# 加载数据集
dataset = load_dataset('csv', data_files={
'train': 'D:/pyx/Five_data/train.csv',
'validation': 'D:/pyx/Five_data/val.csv',
'test': 'D:/pyx/Five_data/test.csv'
})
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese')
# 预处理函数
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=128)
# 应用预处理
tokenized_datasets = dataset.map(preprocess_function, batched=True)
tokenized_datasets.set_format(type='torch', columns=['input_ids', 'token_type_ids', 'attention_mask', 'label'])
# 加载模型
model = AutoModelForSequenceClassification.from_pretrained(
"bert-base-chinese",
num_labels=5,
ignore_mismatched_sizes=True
)
# 定义评估指标
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# 训练参数
training_args = TrainingArguments(
output_dir="./results",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
metric_for_best_model="accuracy",
push_to_hub=False,
)
# 创建Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
compute_metrics=compute_metrics,
)
# 训练模型
trainer.train()
trainer.save_model("./best_model")
# 评估模型
results = trainer.evaluate(tokenized_datasets["test"])
print(f"Test Results: {results}")
上面这个脚本不够完善,遇到了很多报错如下:
报错一
datasets.table.CastError: Couldn't cast
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>: string
__index_level_0__: string
__index_level_1__: string
__index_level_2__: string
__index_level_3__: string
__index_level_4__: string
__index_level_5__: string
__index_level_6__: string
__index_level_7__: string
-- schema metadata --
pandas: '{"index_columns": ["__index_level_0__", "__index_level_1__", "__' + 1534
to
{'<?xml version="1.0" encoding="UTF-8" standalone="yes"?>': Value(dtype='string', id=None)}
because column names don't match
During handling of the above exception, another exception occurred:
检查训练的数据集train.csv等是不是编码有问题,打开是不是乱码,如果是用表格整理的数据,最好是用WPS保存时选择另存为.csv文件
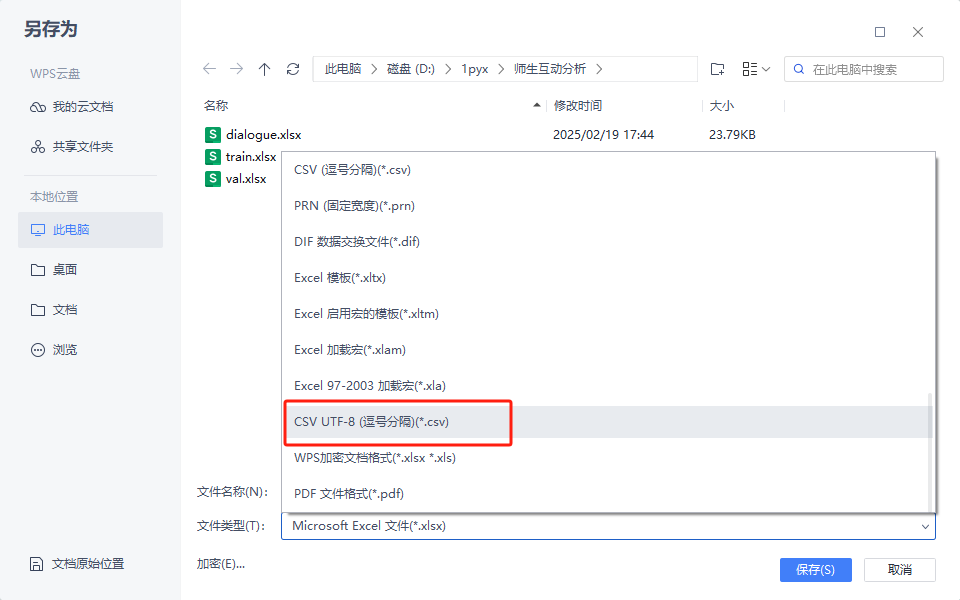
报错2:
Traceback (most recent call last):
File "D:\pyx\pythonProject\pythonProject\bert-classification\train_bert.py", line 33, in <module>
metric = evaluate.load("accuracy")
File "D:\anaconda3\envs\bert-classification\lib\site-packages\evaluate\loading.py", line 748, in load
evaluation_module = evaluation_module_factory(
File "D:\anaconda3\envs\bert-classification\lib\site-packages\evaluate\loading.py", line 681, in evaluation_module_factory
raise FileNotFoundError(
FileNotFoundError: Couldn't find a module script at D:\pyx\pythonProject\pythonProject\bert-classification\accuracy\accuracy.py. Module 'accuracy' doesn't exist on the Hugging Face Hub either.
定位到有问题的代码片段:
# 定义评估指标
metric = evaluate.load("accuracy")
方法二尝试提高库的版本可以适用于这些参数
但是我的还是报错所以重新修改参数 不使用这些模块 并且让AI帮我添加了很多调试信息,改进部分如下:
# 5. 定义训练参数(完全兼容transformers旧版本)
training_args = TrainingArguments(
output_dir="./results",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
# 移除所有新版本特有的参数
logging_steps=50,
save_steps=len(tokenized_datasets["train"]) // 3, # 每轮保存3次
save_total_limit=3, # 最多保存3个检查点
logging_dir="./train_logs",
disable_tqdm=False,
dataloader_num_workers=4,
)
# 6. 自定义计算指标函数
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
accuracy = compute_accuracy(predictions, labels)
return {"accuracy": accuracy}
# 7. 创建带监控的Trainer(修改为普通Trainer)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
compute_metrics=compute_metrics,
)
# 8. 开始训练(手动管理验证过程)
logger.info("\n===== 开始训练 =====")
train_result = trainer.train()
# 9. 手动执行验证
logger.info("\n===== 验证模型 =====")
eval_results = trainer.evaluate()
for key, value in eval_results.items():
logger.info(f" {key}: {value:.4f}")
# 10. 保存模型
logger.info(f"\n保存模型至: {training_args.output_dir}")
trainer.save_model(training_args.output_dir)
# 11. 评估测试集
logger.info("\n===== 评估测试集 =====")
test_results = trainer.evaluate(tokenized_datasets["test"])
logger.info(f"测试集准确率: {test_results['eval_accuracy']:.4f}")
# 12. 打印训练统计信息(需要手动计算)
logger.info(f"\n训练总步数: {train_result.global_step}")
logger.info(f"训练总耗时: {train_result.metrics['train_runtime']:.2f}秒")
logger.info(f"训练平均速度: {train_result.metrics['train_samples_per_second']:.2f}样本/秒")
然后还需要
pip install 'accelerate>=0.26.0'
成功开始训练