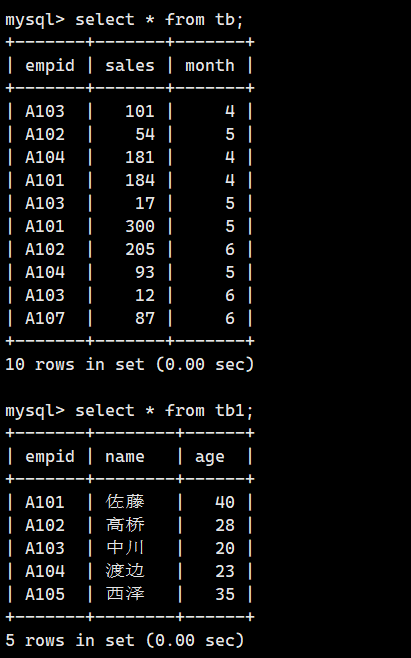
迈向2025年,开源大型语言模型(LLM)生态系统已不再仅仅是闭源模型的补充,而是成为推动AI创新与民主化的核心引擎。其技术全景展现了一个高度模块化、协作共生且快速演进的复杂网络。以下是对提供的蓝图进行更细致的解读,深入探讨各个层面及其关键技术:
🏗️ 基础设施与底层加速 Infrastructure & Processing
核心目标: 极致压榨硬件性能,尤其是GPU,以应对大模型训练和推理的巨大计算需求。
- GPU内核/库 GPU Kernel/Libs: 这是性能优化的最前线。
- FlashAttention v1/v2/v3: 革命性的注意力机制实现。它通过IO感知(IO-Awareness),智能地在GPU的不同层级缓存(SRAM、HBM)之间读写数据,大幅减少了昂贵的HBM读写次数,从而在不牺牲(甚至提升)精度的前提下,显著提升速度(2-4倍)并降低显存消耗。这已成为训练和推理的标准配置。
- Triton: OpenAI开发的Python方言,专为编写高性能GPU内核而生。它让开发者无需深入钻研CUDA C++,也能编写出接近甚至超越手动优化性能的计算内核,极大地提高了GPU编程的效率和可移植性。许多高性能推理库(如vLLM)都大量使用了Triton。
- CUTLASS / FlashInfer: NVIDIA官方提供的高性能CUDA C++模板库,专注于矩阵乘法(GEMM)等基础运算,是构建深度学习框架和推理引擎的基石。FlashInfer则更侧重于推理场景的特定优化。
- NCCL: NVIDIA集合通信库,是实现高效分布式训练的关键。它提供了优化的多GPU/多节点通信原语(如AllReduce, Broadcast),确保数据和梯度在不同设备间快速同步。
- OpenXLA: 谷歌领导的项目,旨在提供一个统一的AI编译器栈。它能将PyTorch/TensorFlow等框架的模型编译成针对不同硬件(GPU, TPU, CPU)的高度优化的代码,实现硬件无关性和性能提升。
💾 数据层 Data Layer
核心目标: 构建高质量、可信赖、易于访问的数据管道,为LLM提供“营养丰富”且“干净”的食粮。
- 数据集成 Data Integration: 应对数据来源多样化和流程复杂化的挑战。
- Airbyte / Airflow / Prefect / dagster: 这些工具负责ETL/ELT流程的编排与调度。它们帮助自动化地从数据库、API、文件系统等抽取数据,进行转换,并加载到目标系统(如数据湖或向量数据库)。Airflow是老牌霸主,而Airbyte专注于连接器(EL),Prefect/dagster则提供了更现代的工作流定义和可观察性。
- 数据转换与处理 Data Transformation: LLM时代,非结构化数据的处理尤为重要。
- Unstructured / Datachain / Unstract: 这些工具是非结构化数据处理的利器。它们能解析PDF、HTML、Word、图像等复杂格式,提取纯文本、表格、元数据,并进行清洗和分块(Chunking),这是构建高质量RAG知识库和准备训练语料的关键步骤。
- dbt Core: 专注于数据仓库/湖内的数据转换(T)。它通过SQL和Jinja模板,让数据分析师能以软件工程的方式构建、测试和文档化数据模型,确保数据的一致性和可靠性。
- 数据标注 Data Labeling: 为监督学习和人类反馈提供支撑。
- Label Studio: 开源且功能强大的标注平台。它支持文本分类、实体识别、对话标注、图像分割等多种任务和数据类型,并提供协作功能,是构建指令微调(SFT)数据集、偏好数据集(DPO/RLHF)和评估集的重要工具。
- 数据治理 Data Governance: 确保数据的质量、可追溯性和合规性。
- Iceberg / Paimon 原Flink Table Store / Hudi: 这些开源数据湖存储格式是现代数据栈的核心。它们为存储在对象存储(如S3)上的数据提供了ACID事务、快照隔离、时间旅行(版本回溯)、模式演化等数据库级的能力,极大地提升了处理大规模LLM数据集的可靠性和可管理性。
- DataHub / Gravitino: 元数据管理平台。它们帮助企业构建数据目录,实现数据的发现、血缘追溯、访问控制和质量监控,这对于理解和治理用于LLM的庞大数据资产至关重要。
🛠️ 模型层 Model Layer
核心目标: 实现从零开始训练、高效微调、快速评估到大规模部署的全生命周期管理。
- 预训练框架 Pre-train Frameworks:
- PyTorch / TensorFlow / PaddlePaddle: 深度学习的基石,提供了张量运算、自动微分、神经网络层等核心功能。PyTorch凭借其灵活性和易用性在LLM研究和开发中占据主导地位。
- NeMo: NVIDIA的对话式AI和LLM工具包,集成了预训练脚本、模型架构(如GPT, BERT)和微调技术,并针对NVIDIA硬件进行了深度优化。
- 分布式训练 Distributed Training: 训练万亿参数模型的必备技术。
- DeepSpeed / Megatron-LM / Colossal-AI: 这些库实现了复杂的3D并行策略:数据并行(将数据分发到不同GPU)、张量并行(将模型层内的计算分割到不同GPU)、流水线并行(将模型按层分割到不同GPU)。它们还集成了**ZeRO(零冗余优化器)**等显存优化技术,使得在现有硬件上训练更大模型成为可能。
- Ray / VolcEngine Volcano: 分布式计算框架和调度系统。Ray提供了简单的API来构建和扩展分布式应用,而Volcano则专注于AI/ML场景的批处理调度,确保大规模训练任务在Kubernetes集群上高效运行。
- 训练/微调 Training/Fine-tuning: 让模型适应特定任务或领域。
- LLaMA-Factory / Unsloth / OpenRLHF: 2025年的趋势是高效且易用的微调。LLaMA-Factory提供了一站式微调界面,支持多种模型和PEFT方法。Unsloth通过手写Triton内核,实现了比Hugging Face快2倍以上、显存消耗减半的LoRA/QLoRA微调。OpenRLHF则专注于强化学习对齐(RLHF/DPO)的开源实现。
- PEFT Parameter-Efficient Fine-Tuning: LoRA、QLoRA、DoRA等技术是主流,它们通过只训练模型的一小部分参数(适配器),大幅降低了微调的计算和显存成本。
- 服务/推理 Serving/Inference: 将模型推向应用的关键瓶颈。
- vLLM / SGL / LMDeploy / TensorRT-LLM: 专为LLM设计的高性能推理引擎。vLLM的PagedAttention机制是其核心,它像操作系统管理虚拟内存一样管理KV Cache,显著减少了内存碎片和浪费,实现了近乎理论极限的吞吐量。TensorRT-LLM是NVIDIA的官方方案,提供极致优化。SGL和LMDeploy也提供了各有特色的优化方案。
- Ollama / GPT4All / OpenVINO: 追求易用性和本地部署。Ollama通过简单的命令就能在Mac/Linux/Windows上运行多种开源模型。GPT4All专注于CPU推理。OpenVINO是Intel的工具包,优化在Intel硬件上的运行。
- Triton Inference Server / KServe / BentoML / SkyPilot: 企业级模型服务平台。它们提供模型版本管理、动态批处理、多模型部署、自动扩展、监控和API网关等功能,支持构建生产级的LLM服务。BentoML尤其强调打包和部署的灵活性。
- 评估平台 Evaluation Platforms: 衡量模型能力的标准。
- OpenCompass 开放司南: 由上海AI Lab牵头,提供全面的LLM评测基准和工具链,覆盖了从基础能力到专业领域的多种评测维度。
- Chatbot Arena: Vicuna团队创建的基于人类偏好的盲评平台。通过让用户匿名比较两个模型的回答,利用Elo评分系统为不同模型进行排名,成为衡量聊天机器人“体感”性能的重要参考。
⚙️ MLOps
核心目标: 将软件工程的最佳实践引入ML生命周期,实现LLM开发、部署和运维的自动化、标准化和可信赖。
- MLflow / Weights & Biases W&B / MLRun / ZenML / DeepFloW / Flyte / Metaflow: 这些平台提供了端到端的解决方案:
- 实验跟踪: 记录每次训练/微调的参数、指标、模型文件和环境,确保可复现性(W&B, MLflow)。
- 模型注册表: 管理和版本化训练好的模型,方便部署和回滚(MLflow, W&B)。
- 工作流编排: 定义、调度和监控从数据处理到模型部署的复杂流水线(Flyte, Metaflow, ZenML, Kubeflow Pipelines)。
- 数据/模型版本控制: 结合DVC或数据湖格式,实现数据和模型的版本管理。
- 监控与可观察性: 监控部署后模型的性能、漂移和资源消耗。
- LLM时代,MLOps需要特别关注提示工程(Prompt Engineering)的管理、评估数据集的管理、以及RAG管道的监控。
🧩 应用层与集成 Application Layer & Integration
核心目标: 构建能解决实际问题的LLM应用,并将其无缝融入现有软件生态。
- SDK/开发套件 SDK/Development Kit: 应用开发的“操作系统”。
- LangChain: 最早普及的框架,提供了丰富的**“链”(Chains)和“代理”(Agents)概念,以及大量的工具集成。LangGraph则引入了图结构**来构建更复杂、可循环的代理行为。
- LlamaIndex: 专注于RAG,提供了强大的数据索引、查询和合成能力,尤其擅长处理复杂文档和知识库。
- AutoGen: 微软出品,专注于多代理(Multi-Agent)协作,让多个LLM代理可以互相交流、分工合作来完成复杂任务,是Agentic Workflow的代表。
- Semantic Kernel: 微软的另一个框架,更强调与企业应用和微软生态的集成。
- CrewAI / CAMEL / Agent-Verse: 更多新兴的专注于代理和多代理的框架,反映了2025年LLM应用向自主化、智能化发展的趋势。
- 工作流/RAG Workflow/RAG/Flow: 低代码/无代码构建LLM应用。
- Flowise AI / Dify / FastGPT / MaxKB: 这些平台提供了可视化拖拽界面或简单的配置方式,让非专业开发者也能快速构建RAG问答系统、智能客服、内容生成等应用,极大地降低了LLM应用开发的门槛。Dify和FastGPT等还集成了后端即服务(BaaS)能力。
- 搜索 Search:
- Perplexity AI Search / SearXNG: 展示了LLM如何革新搜索体验,从返回链接列表到提供直接、有来源依据的答案。SearXNG是可定制的元搜索引擎。
- 编码助手 Coding Assistants:
- Continue / OpenHands / Aider / Cody / Tabby: 开源社区对GitHub Copilot的回应。它们提供代码补全、生成、调试、重构、PR审查等功能,旨在成为开发者的“结对编程伙伴”,显著提升开发效率。Tabby尤其关注自托管和本地部署。
- 统一接口/协议 Unified Interface/Protocol:
- LiteLLM / One API: 它们提供了一个中间层,用统一的API格式来调用OpenAI, Anthropic, Google以及各种开源模型(通过Ollama或vLLM等)。这使得应用可以轻松切换底层模型,进行成本/性能优化或实现容灾。
- 用户界面/交互 UI/Interface:
- Open WebUI / SillyTavern / Chatbox: 提供了类似ChatGPT的聊天前端,可以连接到各种本地或远程LLM后端。Text generation web UI Oobabooga / ComfyUI / Stable Diffusion web UI则更多地用于与文生图模型交互,ComfyUI以其节点式工作流著称。
- 应用框架 APP Framework:
- Streamlit / Gradio: Python库,让开发者能用几行代码就构建出交互式的Web应用,非常适合快速展示LLM Demo、数据看板和内部工具。
- 向量数据库 Vector Database: RAG的绝对核心。
- Milvus / Weaviate / Qdrant / Chroma / LanceDB / OpenSearch / Elasticsearch / pgvector: 它们专门用于存储和高效检索高维向量(Embeddings)。当用户提问时,RAG系统先将问题转换为向量,然后在向量数据库中进行近似最近邻(ANN)搜索,找到最相关的文档块(Chunks),再将这些信息连同问题一起喂给LLM生成答案。它们在性能、可扩展性、过滤能力、云原生支持等方面各有侧重。Chroma和LanceDB轻量级,适合本地;Milvus和Weaviate则更适合大规模生产部署。pgvector将向量搜索能力带入了PostgreSQL。
✨
2025年的开源大模型技术图谱呈现出高度的专业化分工与紧密的协同合作。
- 趋势: 效率(训练/推理/微调)、易用性(低代码/UI)、智能体(Agents)、RAG的深化、数据质量与治理、多模态支持以及MLOps的成熟是主要方向。
- 挑战: 算力成本、模型安全与对齐、评估的标准化、以及复杂Agentic系统的可靠性仍是需要攻克的难关。
这个生态系统的繁荣,得益于全球开发者的无私贡献。它不仅加速了技术的迭代,更重要的是,它确保了这项变革性技术能够被更广泛的人群所接触、使用和塑造,共同构建一个更加智能和普惠的未来。
为了帮助大家更好的理解大模型工程。我可以使用文本和代码块(特别是 Mermaid 语法,许多平台可以将其渲染成可视化图表)来描述开源大模型生态中的几个关键流程。
以下是几个核心流程的描述:
1. RAG Retrieval-Augmented Generation 流程图
这是当前构建知识密集型LLM应用最主流的方式,它将LLM的生成能力与外部知识库的检索能力结合起来。
流程解读:
- 离线处理: 将原始文档(PDF、网页等)经过清洗、分割成合适的“块”(Chunks),然后使用Embedding模型将这些块转换成向量,存入向量数据库。
- 用户提问: 用户输入一个问题。
- 问题向量化: 使用与文档相同的Embedding模型将用户问题转换成向量。
- 向量搜索: 在向量数据库中搜索与问题向量最相似的文档块向量。
- 检索文档: 获取最相关的几个文档块。
- 构建提示: 将原始问题和检索到的相关文档块组合成一个更丰富的提示(Prompt)。
- LLM生成: 将构建好的提示发送给LLM。
- 生成答案: LLM基于提供的上下文信息生成答案。
- 返回用户: 将生成的答案呈现给用户。
2. LLM 微调 Fine-tuning 流程图
微调是指在一个已经预训练好的基础模型上,使用特定领域或任务的数据进行进一步训练,使其更适应特定需求。
流程解读:
- 选择基础模型: 根据任务需求和计算资源选择一个合适的开源预训练模型。
- 数据准备: 收集原始数据,进行清洗、格式化,并构造成微调所需的格式(如指令-回答对用于SFT,或人类偏好对用于对齐)。
- 进行微调:
- SFT: 使用指令数据集训练模型,让其学会遵循指令进行回答。常使用LoRA等PEFT技术以节省资源。
- 对齐: (可选)使用偏好数据集进一步训练模型,使其输出更符合人类的价值观和偏好(如DPO - 直接偏好优化)。
- 模型评估: 使用预留的评估集或标准基准测试(如OpenCompass)来评估微调后模型的性能。
- 决策:
- 如果模型性能满足要求,则进入部署阶段。
- 如果不满足,则返回数据准备或微调阶段,调整数据、超参数或方法进行迭代。
3. LLM 服务/推理 Serving/Inference 流程图
这是将训练好的模型部署为在线服务,供用户或其他应用调用的过程。
流程解读:
- 用户请求: 用户通过API发送请求。
- 网关/负载均衡: 请求首先到达API网关或负载均衡器,负责路由、认证和分发流量。
- 推理服务器: 请求被转发到具体的推理服务器(如vLLM)。服务器管理模型加载、批处理(Batching)和请求调度。
- 推理引擎:
- 预处理: 将输入的文本转换成模型能理解的Token ID。
- KV Cache 管理: 高效地管理注意力机制中的Key-Value缓存,这是LLM推理性能的关键。
- 模型计算: 在GPU上执行模型的前向传播。
- Token 生成: 逐个生成输出Token,并根据采样策略(如Greedy, Top-k)选择下一个Token。
- 后处理: 将生成的Token ID转换回人类可读的文本。
- 返回响应: 将生成的文本通过API返回给用户。
- 模型仓库/监控: 推理服务器从模型仓库加载模型,并向监控系统报告性能指标。
希望这些基于文本的流程图能帮助更清晰地理解开源大模型生态中的关键工作流程!
除了上层应用的流程,我想把底层的关键流程也分享给大家。
好的,我们来探讨一下大型模型训练中涉及的一些关键底层分布式流程,并用Mermaid流程图来呈现它们。这些流程是实现万亿参数级别模型训练的核心技术。
1. 数据并行 Data Parallelism - DP 流程图
这是最基础的分布式训练策略,通过将数据分发到多个计算节点来加速训练。
流程解读:
- 模型复制: 将完整的模型副本分发到每个参与训练的GPU上。
- 数据拆分: 将一个大的训练批次(Global Batch)切分成多个小的微批次(Micro-batch)。
- 数据分发: 每个GPU获取一个微批次的数据。
- 并行计算: 每个GPU独立地在其数据上执行前向传播和反向传播,计算出梯度。
- 梯度同步 AllReduce: 这是数据并行的关键通信步骤。所有GPU通过高速互联(如NVLink/NCCL)将其计算出的梯度进行聚合(通常是求平均值),并确保每个GPU都收到完全相同的、聚合后的梯度。
- 模型更新: 每个GPU使用相同的梯度来更新其本地的模型副本。由于梯度相同,更新后的模型参数在所有GPU上保持一致。
- 循环: 重复此过程,直到训练完成。
优点: 实现简单,易于扩展。
缺点: 每个GPU需要存储完整的模型参数和优化器状态,显存开销大。
2. 流水线并行 Pipeline Parallelism - PP 流程图
这种策略将模型的不同层(Stages)放置在不同的GPU上,数据像流水线一样依次通过这些GPU。
流程解读:
- 模型切分: 将整个模型按层切分成多个连续的部分(Stages)。
- GPU分配: 每个Stage分配给一个或一组GPU。
- 微批次流水: 训练数据被切分成更小的微批次。第一个微批次进入Stage 1,计算完成后其输出(激活值)传递给Stage 2,同时第二个微批次进入Stage 1。
- 稳态运行: 经过短暂的“填充”(Fill)阶段后,流水线达到稳态,所有Stage都在并行处理不同的微批次。
- 反向传播: 当一个微批次完成前向传播并计算损失后,它开始反向传播,梯度沿着流水线反向传递。
- 流水线刷新: 最后一个微批次通过所有Stage后,流水线进入“排空”(Drain)阶段。
- 参数更新: 梯度累积完成后进行参数更新。
优点: 允许训练超出单GPU显存的模型,降低了单个GPU的显存需求。
缺点: 存在“流水线气泡”(Pipeline Bubble),即填充和排空阶段GPU未能满负荷运行,降低了效率。需要复杂的调度(如GPipe, PipeDream)来优化。
3. 张量并行 Tensor Parallelism - TP 流程图
这种策略将模型中的大张量(如权重矩阵)切分到不同的GPU上,并在计算过程中通过通信来整合结果。
流程解读 以Transformer中的MLP层列并行为例 :
- 权重切分: 将MLP层中的第一个权重矩阵
W按列切分,W_a存放在 GPU A,W_b存放在 GPU B。 - 输入复制/切分: 取决于具体实现 通常输入
X会被复制或按需传递。 - 并行计算:
- GPU A 计算
Y_a = X * W_a。 - GPU B 计算
Y_b = X * W_b。
- GPU A 计算
- 结果聚合 AllReduce: 由于
Y = X * W = X * [W_a, W_b] = [X * W_a, X * W_b] = [Y_a, Y_b],在这个例子中,实际上不需要聚合,而是拼接。但对于行并行或者Attention中的并行,AllReduce是必须的,这里用AllReduce代表跨GPU的通信和结果整合步骤。 - 输出: 得到完整的输出
Y。
优点: 进一步降低单个GPU的显存和计算压力,能与数据并行、流水线并行结合。
缺点: 引入了大量的通信开销,需要极高带宽的GPU互联。实现复杂。
4. ZeRO Zero Redundancy Optimizer 流程图 概念
ZeRO 旨在通过分区存储模型状态(参数、梯度、优化器状态),大幅减少数据并行时的显存冗余。
流程解读 ZeRO Stage 3 :
- 分区存储: 在训练开始前,模型的参数(P)、梯度(G)和优化器状态(O)都被平均分配到所有N个GPU上,每个GPU只持有完整状态的1/N。
- 前向传播:
- 当需要计算某一层时,所有GPU通过
AllGather操作,临时从其他GPU获取该层所需的全部参数。 - 执行该层的计算。
- 计算完成后,可以立即释放这些临时获取的参数,以节省显存。
- 当需要计算某一层时,所有GPU通过
- 反向传播:
- 同样,在计算梯度时,如果参数已被释放,需要再次
AllGather。 - 计算出梯度后,使用
ReduceScatter操作。这个操作会聚合所有GPU上关于某一部分参数的梯度,并将聚合后的结果只发送给负责存储这部分参数和对应优化器状态的那个GPU。
- 同样,在计算梯度时,如果参数已被释放,需要再次
- 参数更新: 每个GPU只使用它收到的梯度,来更新它所负责的那1/N的参数和优化器状态。
优点: 极大地降低了显存占用,使得在同等硬件下可以训练更大规模的模型。
缺点: 增加了通信量(AllGather 和 ReduceScatter),可能会影响训练速度,需要高效的通信网络。
这些流程图展示了实现大规模LLM训练所需的复杂分布式策略。像 DeepSpeed 和 Colossal-AI 这样的框架,就是将这些技术(DP, PP, TP, ZeRO)进行整合和优化,为开发者提供易于使用的接口来驾驭这种复杂性。
5. 详细的LLM数据预处理与治理流程图 用于预训练或大规模RAG知识库构建
这个流程结合了“数据层”中描述的多个方面。
graph TD
A[数据源 网络爬虫, APIs, 数据库, 文件] --> B[数据集成与提取];
B -- Airbyte, Airflow, Prefect --> C{原始数据存储 数据湖/对象存储};
C --> D[非结构化数据解析与转换];
D -- Unstructured, Datachain --> E[文本提取、表格识别、元数据获取];
E --> F[数据清洗与去重];
F -- dbt Core 用于结构化部分, 自定义脚本 --> G[数据过滤与质量评估];
G --> H[数据分块 Chunking];
H --> I[敏感数据处理/PII匿名化];
I --> J[数据标注 - 可选];
J -- Label Studio --> K[构建SFT/偏好/RAG评估数据集];
C --> L[数据湖格式管理];
L -- Iceberg, Paimon, Hudi --> M[ACID事务, 版本控制, Schema演化];
M --> N[元数据管理与数据目录];
N -- DataHub, Gravitino --> O[数据血缘追溯, 可发现性];
subgraph 输出
K --> P[用于微调的数据集]
H --> Q[用于RAG的干净文档块]
M --> R[用于预训练的高质量语料库]
end
style B fill:#cde,stroke:#333,stroke-width:2px
style D fill:#cde,stroke:#333,stroke-width:2px
style F fill:#cde,stroke:#333,stroke-width:2px
style L fill:#a2d5f2,stroke:#333,stroke-width:2px
style N fill:#a2d5f2,stroke:#333,stroke-width:2px
style P fill:#9c9,stroke:#333,stroke-width:2px
style Q fill:#9c9,stroke:#333,stroke-width:2px
style R fill:#9c9,stroke:#333,stroke-width:2px
流程解读:
- 数据源: 从多样化的来源收集原始数据。
- 数据集成与提取: 使用Airflow、Airbyte等工具将数据汇集到原始数据存储区(如S3上的数据湖)。
- 非结构化数据解析: 使用Unstructured等工具处理PDF、HTML等,提取纯文本和结构化信息。
- 数据清洗与去重: 应用规则和算法去除噪声、重复内容。dbt Core可用于处理已结构化的数据。
- 数据过滤与质量评估: 进一步筛选数据,确保符合LLM训练或RAG的要求。
- **数据分块 Chunking **: 将长文档切分为适合Embedding和LLM上下文长度的小块。
- 敏感数据处理: 进行PII识别和匿名化/脱敏。
- **数据标注 可选 **: 使用Label Studio等工具为特定任务(如SFT、RLHF、RAG评估)创建标注数据。
- 数据湖格式管理: 使用Iceberg, Paimon, Hudi等格式管理数据湖中的数据,提供事务、版本控制等能力。
- 元数据管理: 使用DataHub, Gravitino等平台构建数据目录,实现数据血缘、发现和治理。
- 输出: 生成可用于预训练、RAG知识库构建或微调的高质量数据集。
6. MLOps 全生命周期管理流程图 LLM 特化版
这个流程图展示了LLM开发、部署和运维的端到端循环。
流程解读:
- 需求定义: 明确LLM应用的业务目标。
- 数据准备与版本控制: 收集、清洗、版本化用于训练/微调/RAG的数据 参考数据预处理流程 。
- 提示工程与管理: 设计、测试、版本化和优化Prompt,这是LLM应用的关键。
- 模型选择: 选择合适的基础模型进行微调或直接用于推理。
- 实验与微调: 使用MLflow, W&B等跟踪实验,利用LLaMA-Factory, Unsloth等工具进行高效微调。
- 模型评估: 使用OpenCompass等平台和内部评估集全面评估模型能力。
- 模型注册表: 版本化和管理训练好的、经过验证的模型。
- 模型部署与服务: 将模型部署为API服务,可能涉及推理引擎优化和服务平台。
- RAG管道部署与监控: 如果是RAG应用,整个检索增强生成管道都需要部署和监控。
- 持续监控: 监控模型的性能、漂移、资源消耗、成本和潜在的偏见/安全问题。
- 反馈收集: 从用户或应用日志中收集反馈,用于模型改进。
- 迭代: 根据监控和反馈,决定是否需要返回数据准备、微调或提示工程阶段进行迭代。
- 应用集成: 将LLM服务集成到最终用户应用中。
- 贯穿环节: 代码版本控制、工作流编排工具以及安全合规始终是MLOps的核心组成部分。
7. 多智能体协作 Multi-Agent Workflow 流程图 基于AutoGen/CrewAI等
这反映了提到的Agentic Workflow趋势。
流程解读:
-
任务定义: 用户提供一个复杂的、需要多步骤或多领域知识才能完成的任务。
-
**主协调智能体 Orchestrator **: 接收任务,初始化协作流程。在AutoGen中可能是
GroupChatManager或自定义的协调逻辑;在CrewAI中,Crew本身定义了流程。 -
任务分解与智能体选择: 协调者(或预定义的流程)将复杂任务分解为子任务,并选择合适的专业智能体来执行。
-
子任务分配: 将子任务分配给选定的智能体。
-
智能体协作网络
:
- 专业智能体: 每个智能体专注于特定功能(如规划、编码、研究、审查)。
- 共享上下文/记忆: 智能体之间的通信和工作成果通过共享的上下文或消息历史进行传递,允许它们基于彼此的工作进行构建。
- 工具使用: 智能体可以调用外部工具(如搜索引擎、代码执行器、API)来获取信息或执行操作。
- 迭代与反馈: 智能体之间可能会有多轮对话、结果传递和修正。例如,审查智能体可能会将结果反馈给生成智能体进行修改。
-
结果汇总与决策: 协调智能体收集各个智能体的结果,判断任务是否完成。
-
最终输出/行动: 如果任务完成,则向用户提供最终结果或执行相应的行动。如果未完成或需要澄清,则可能返回任务分解阶段或与用户进一步交互。
8. FlashAttention 核心思想流程图
这个流程图旨在解释FlashAttention为何能提升效率。
流程解读:
- 传统注意力:
- Q, K, V 矩阵存储在GPU的高带宽显存 HBM 中。
- 计算
S = QKᵀ需要从HBM读取Q和K,并将中间结果S写回HBM。 - 计算
P = Softmax S需要从HBM读取S,并将P写回HBM。 - 计算
O = PV需要从HBM读取P和V,并将最终输出O写回HBM。 - 这个过程中涉及多次大规模的HBM读写,而HBM的带宽虽然高,但相比SRAM的延迟和带宽仍是瓶颈。
- **FlashAttention IO感知 **:
- Q, K, V 仍然主要在HBM中。
- 将Q, K, V **分块 Tiling **。
- 核心思想: 将计算注意力所需的一小块Q、K、V数据从HBM加载到速度极快但容量小的 SRAM GPU片上缓存 中。
- 在SRAM内部完成对这些小块的注意力计算(
S = QKᵀ,Softmax,O = PV等操作通过 **融合内核 Fused Kernel ** 一次性完成),而不需要将中间结果写回HBM。 - 通过精巧的算法(如在线Softmax的重新计算技巧),将各个块的计算结果正确地组合起来,得到最终的注意力输出。
- 结果: 大幅减少了对HBM的读写次数,主要计算在高速SRAM中进行,从而显著提升速度并降低显存消耗(因为中间结果不必长期占据HBM)。
希望这些新增的和细化的流程图能更好地帮助理解文档中描述的开源大模型生态系统!这些图表都采用了Mermaid语法,方便在支持的平台上渲染。
只有我们推动纯粹的技术发展才有可能让我们的孩子享受到真正的。就像孙中山先生那句天下为公。我整理这些资料就是希望更多的人可以享受到真正的科技改变生活。