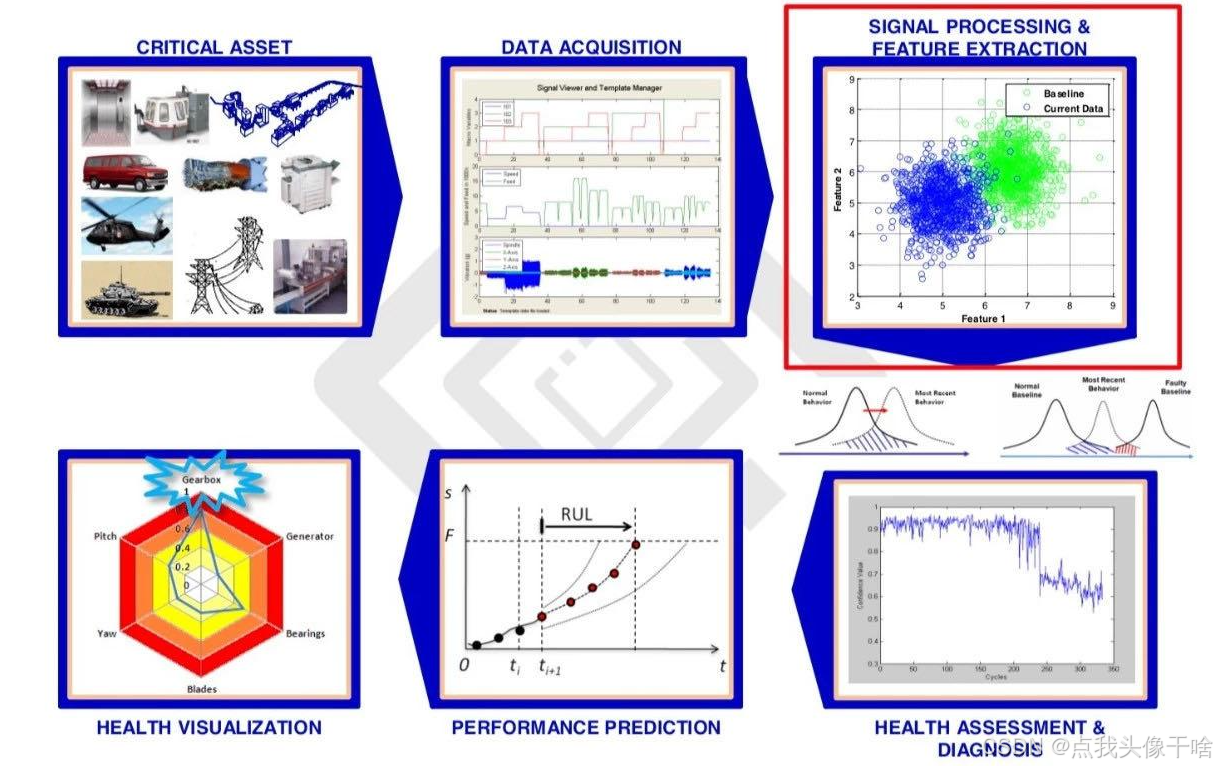
一、特征学习:从人工设计到智能发现的范式革新
1.1 核心定义与价值
特征学习的本质是让机器模仿人类大脑的认知过程 —— 例如,人类视觉系统通过视网膜→视神经→大脑皮层的层级处理,从像素中识别物体;特征学习则通过神经网络的卷积层、循环层或 Transformer 层,自动从原始数据中提取 “边缘→形状→物体”“音节→词汇→语义” 等层级特征。
- 关键对比:传统特征工程依赖 “专家经验 + 试错”,如金融风控中需手动设计 “交易频次”“异地消费占比” 等特征,耗时数周且易受主观影响;而特征学习通过算法自动发现 “交易时间间隔异常”“同类商户连续消费” 等隐性模式,效率提升 80% 以上。
1.2 核心优势:效率、精度、泛化三重跃升
- 效率革命:在图像领域,人工设计特征需逐像素分析纹理、颜色分布(如 SIFT 特征),而 CNN 通过卷积核自动捕捉边缘,单张图像特征提取时间从分钟级降至毫秒级。
- 精度突破:医学影像中,人工标注可能遗漏小于 3mm 的肺结节,而 3D-CNN 通过多层卷积可识别 1.5mm 的微小结节,结合注意力机制聚焦可疑区域,假阳性率降低 40%。
- 泛化能力:训练于 MNIST 手写数字的 CNN 模型,无需微调即可识别类似风格的阿拉伯数字,而传统 HOG 特征 + SVM 模型需重新设计特征参数。
1.3 技术演进:从传统算法到深度学习
- 传统机器学习阶段:
- 特征工程是核心壁垒,如文本分类依赖 TF-IDF(词频 - 逆文档频率)、LDA(主题模型)等,需结合词性标注、命名实体识别等 NLP 技术。
- 典型案例:早期垃圾邮件分类通过人工提取 “关键词频率”“发件人域名” 等特征,准确率约 75%。
- 深度学习初期:
- CNN 颠覆图像特征提取,AlexNet(2012 年)通过 5 层卷积 + 3 层全连接,将 ImageNet 分类准确率从 74% 提升至 85%,首次证明自动特征学习的潜力。
- RNN 主导语音识别,LSTM 网络通过记忆单元捕捉语音时序特征,使语音识别错误率从 30% 降至 15%。
- 深度学习进阶:
- Transformer 凭借自注意力机制,解决 RNN 的长距离依赖问题,BERT(2018 年)在 11 项 NLP 任务中刷新纪录,标志着通用特征学习的突破。
二、特征学习的技术分类与实战代码
2.1 监督学习:标签驱动的定向特征提取
核心原理:监督学习通过损失函数(如交叉熵)衡量预测与标签的差异,反向传播优化特征提取过程,确保学习到的特征具备强判别性。
-
CNN 图像分类进阶:
- 在第一层卷积中,32 个 3x3 卷积核可视为 32 个 “边缘检测器”,每个核学习特定方向的边缘(如水平、垂直、45 度斜线)。
- 第二层卷积通过组合第一层的边缘特征,形成 “角点”“T 型 junction” 等复杂图案,最终在全连接层整合为 “汽车”“飞机” 等整体概念。
-
代码扩展:添加数据增强
from tensorflow.keras.layers import RandomFlip, RandomRotation model = Sequential([ RandomFlip(mode='horizontal', input_shape=(32, 32, 3)), # 随机水平翻转 RandomRotation(0.2), # 随机旋转±20度 Conv2D(32, (3, 3), activation='relu'), # 后续层不变 ])作用:通过数据增强模拟真实场景变化,提升模型对旋转、翻转图像的泛化能力,准确率可再提升 3-5%。
2.2 无监督学习:数据驱动的自主特征发现
核心原理:无监督学习通过重构误差(如自动编码器)或聚类损失(如 K-Means),迫使模型学习数据的本质特征,适用于标签稀缺或探索性分析场景。
- 自动编码器的变种:
- 变分自动编码器(VAE):在编码阶段引入概率分布(如高斯分布),使隐特征具备连续性,可用于生成新样本(如生成虚拟用户行为数据)。
- 稀疏自动编码器:通过 L1 正则化迫使隐层少数神经元激活,提取最关键特征,适用于噪声数据(如工业传感器信号去噪)。
- 实战场景:用户分群进阶
- 结合 T-SNE 可视化隐特征:将压缩后的 10 维特征降维至 2 维,直观展示用户分群结构(如 “高频高消费用户”“低频低消费用户” 形成独立簇)。
2.3 多模态学习:跨领域特征对齐
核心挑战:不同模态数据(如文本的离散符号、图像的连续像素)需映射到统一特征空间。
-
CLIP 的对比学习机制:
- 训练时,模型将图像 - 文本对(如 “狗” 的图片 +“a photo of a dog” 文本)视为正样本,随机配对视为负样本。
- 通过最大化正样本特征相似度、最小化负样本相似度,实现跨模态对齐,使语义相关的图文在特征空间中距离小于 0.1(欧氏距离),无关图文距离大于 2.0。
-
代码扩展:多模态检索系统
# 构建图像特征库 image_features = [] for img_path in ["cat1.jpg", "dog1.jpg", "cat2.jpg"]: img = Image.open(img_path).convert("RGB") img_input = processor(images=img, return_tensors="pt", padding=True) img_feat = model.get_image_features(**img_input) image_features.append(img_feat) # 文本查询 text = "寻找猫咪图片" text_input = processor(text=text, return_tensors="pt", padding=True) text_feat = model.get_text_features(**text_input) # 计算余弦相似度 similarities = [torch.cosine_similarity(text_feat, img_feat) for img_feat in image_features] # 输出最相似图像索引 print(f"最相似图像索引:{torch.argmax(similarities).item()}")
三、特征学习的行业应用场景
3.1 计算机视觉:从像素到语义的智能解析
- 医学影像诊断全流程:
- 数据预处理:使用 U-Net 网络对 CT 影像进行器官分割,提取肺部 ROI(感兴趣区域)。
- 特征学习:3D-CNN 逐层提取 “肺泡结构”“血管分布”“结节边缘” 特征,结合 LSTM 分析多帧影像的动态变化。
- 临床决策:通过注意力热力图生成诊断报告,标注结节恶性概率及关键特征(如 “毛刺征阳性,恶性概率 89%”)。
- 工业质检的智能化升级:
- 传统方案:人工目检每分钟处理 10-15 件产品,漏检率 5%,人工成本占生产线 20%。
- 特征学习方案:
- 硬件:线阵相机采集产品表面图像,分辨率达 2048 像素 / 行。
- 算法:YOLOv5s 模型实时检测划痕、缺料等 6 类缺陷,检测速度 50ms / 件,准确率 99.5%,部署后人工成本降至 5%。
3.2 自然语言处理:从单词到语境的深度理解
-
智能客服的技术演进:
- 规则引擎阶段:基于关键词匹配(如 “退款”→跳转售后),无法处理 “订单未收到,申请退货” 等变体表述,意图识别准确率 68%。
- 传统机器学习阶段:使用 TF-IDF+SVM 模型,手动提取 “情感词权重”“疑问词占比” 等特征,准确率提升至 82%,但需维护特征工程 pipeline。
- 特征学习阶段:BERT-base 模型通过 12 层 Transformer 学习语境特征,如 “快递丢失” 与 “延迟送达” 的语义差异,意图识别准确率达 92%,且支持零样本扩展新意图(如 “发票开具”)。
-
代码生成的生产力革命:
-
GitHub Copilot 分析注释 “# 计算斐波那契数列”,自动生成:
def fibonacci(n): if n <= 0: return 0 elif n == 1: return 1 else: return fibonacci(n-1) + fibonacci(n-2) -
统计显示,开发者使用 Copilot 后,编码时间减少 40%,专注于逻辑设计而非语法实现。
-
3.3 物联网与智能制造:时序特征的实时挖掘
设备故障预测的技术栈:
- 数据采集:振动传感器(如加速度计)以 10kHz 采样率采集机床振动信号,每分钟生成 600,000 个数据点。
- 特征学习:
- 短时傅里叶变换(STFT)将时域信号转为频域特征,识别异常频率(如齿轮磨损的 100Hz 谐波)。
- LSTM 网络捕捉时序依赖,如 “连续 30 分钟振动幅值超过阈值 + 频率出现异常分量” 预示轴承故障。
- 决策执行:通过 API 触发 PLC(可编程逻辑控制器)停机,结合工单系统自动派单维修,故障处理时间从 4 小时缩短至 30 分钟。
智能电网负荷预测:
- 传统 ARIMA 模型需人工设计 “工作日 / 周末模式”“季节因子” 等特征,预测误差率 15%。
- Transformer 模型自动学习 “温度 - 空调负荷”“节假日 - 商业用电” 等长距离依赖,误差率降至 11.5%,每年可减少弃电损失超千万元。
四、特征学习的挑战与应对策略
4.1 核心挑战与解决方案
- 数据质量依赖:垃圾进,垃圾出
- 案例:某自动驾驶数据集含 10% 标注错误的 “行人 - 汽车” 标签,导致 YOLO 模型将行人误检为汽车,碰撞预警准确率下降 25%。
- 解决方案:
- 数据清洗:使用 Deeplabv3 + 模型自动校验图像标注,如 “行人区域应包含四肢结构,汽车区域应包含轮胎”。
- 半监督学习:利用少量正确标签 + 大量未标注数据,通过伪标签(Pseudo-Labeling)技术提升模型鲁棒性。
- 计算资源瓶颈:算力成本与模型性能的权衡
- 案例:训练 GPT-3 需消耗 12,960,000 GPU 小时,电费超 450 万美元,中小企业难以承担。
- 解决方案:
- 模型压缩:知识蒸馏(如将 BERT-base 蒸馏为 DistilBERT)使参数减少 40%,推理速度提升 2 倍,而准确率仅下降 3-5%。
- 联邦学习:多家医院联合训练医疗影像模型,各机构本地存储数据,仅共享模型更新梯度,保护隐私的同时降低数据传输成本。
- 可解释性困境:深度学习的 “黑箱” 挑战
- 案例:某金融风控模型拒绝用户贷款申请,但无法解释 “为何判定为高风险”,引发合规争议。
- 解决方案:
- 注意力可视化:在 BERT 模型中,使用 TensorBoard 展示 “收入”“负债” 等关键词的注意力权重,如 “负债比例” 一词贡献 60% 的风险评分。
- 因果推理注入:结合规则引擎(如 “收入 < 负债→高风险”),强制模型决策符合业务逻辑,可解释性提升至 80% 以上。
4.2 工程化最佳实践:从实验室到生产的桥梁
-
特征重要性分析工具链:
- SHAP(SHapley Additive exPlanations):量化每个特征对预测结果的贡献,如 “交易金额> 5000 元” 使欺诈概率增加 25%。
- LIME(Local Interpretable Model-agnostic Explanations):对单个样本生成局部解释,如 “该图像被分类为狗,因包含‘耳朵’‘尾巴’特征”。
-
预训练模型微调策略:
- 冻结底层,微调上层:在医疗影像分类中,冻结 ResNet50 前 10 层(通用图像特征),仅微调后 5 层(医疗专用特征),收敛速度提升 3 倍,避免过拟合。
- 提示工程(Prompt Engineering):在 NLP 任务中,通过前缀提示 “请将以下文本分类为 {类别}:{文本}”,激活预训练模型的相关特征,零样本准确率提升 15%。
实时监控平台架构:
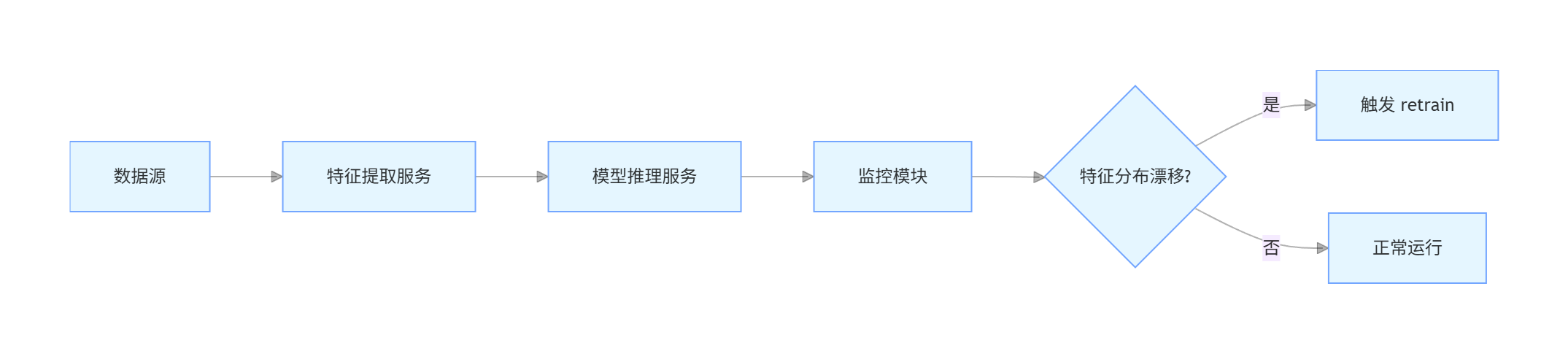
- 监控指标:特征均值 / 方差、SHAP 值分布、预测误差率,当漂移超过阈值(如均值变化 > 20%)时,自动触发模型重新训练。
五、总结
特征学习不仅是一项技术,更是一场关于 “如何让机器理解世界” 的认知革命。从早期人工设计特征的 “手工业” 模式,到深度学习自动提取特征的 “工业化” 范式,它彻底改变了机器学习的研发流程 —— 如今,开发者只需聚焦业务目标,而特征的发现、优化与迭代均可由算法自动完成。