简述
MiniMind-V 是一个超适合初学者的项目,让你用普通电脑就能训一个能看图说话的 AI。训练过程就像教小孩:先准备好图文材料(数据集),教它基础知识(预训练),再教具体技能(微调),最后测试它学会没。整个过程简单、便宜、快,1小时就能搞定,特别适合想玩 AI 又没大预算的人!
GitHub - jingyaogong/minimind-v: 🚀 「大模型」1小时从0训练26M参数的视觉多模态VLM!🌏 Train a 26M-parameter VLM from scratch in just 1 hours!🚀 「大模型」1小时从0训练26M参数的视觉多模态VLM!🌏 Train a 26M-parameter VLM from scratch in just 1 hours! - jingyaogong/minimind-v![]() https://github.com/jingyaogong/minimind-v
https://github.com/jingyaogong/minimind-v
MiniMind-V 是什么?
MiniMind-V 是一个开源项目,目标是让你从零开始训练一个视觉语言模型(VLM)。简单来说,VLM 是一种能同时理解文字和图片的 AI。比如,你给它一张狗的照片,问“这是啥?”,它能回答“这是只狗!”
这个项目的亮点是:
- 超轻量:只有2600万个参数(相比像 GPT-3 那样的模型有几十亿参数,简直是小巫见大巫)。
- 训练快:在一块不错的个人显卡(比如 NVIDIA 3090)上,1小时就能训好。
- 成本低:租个 GPU 服务器训练,费用大概1.3块钱(约0.2美元)。
- 适合新手:代码简单,硬件要求不高,普通电脑也能跑。
就像是打造一个能看图说话的小 AI 脑子,不需要超级计算机!想象 VLM 是一个有两种超能力的 AI:
- 文字能力:能像聊天机器人(比如 ChatGPT)一样理解和生成文字。
- 图像能力:能“看”图片,识别里面的内容。
MiniMind-V 是基于一个叫 MiniMind 的文字模型,加上一个视觉编码器(把图片变成 AI 能懂的数据),让它能同时处理文字和图片。简单来说,MiniMind-V 接收文字和图片,处理后生成回答。流程是这样的:
- 输入:你给它文字和图片。比如,问“图片里是什么?”并附上一张图。图片在代码里用特殊符号(像“@@@…@@@”)表示。
- 处理图片:图片被送进一个叫 CLIP-ViT-Base-Patch16 的视觉编码器。它把图片切成小块(像拼图),转化成一串数字(叫“令牌”),AI 就能理解了。
- 处理文字:你的问题(比如“图片里是什么?”)也被转成令牌。
- 融合图文:图片令牌通过简单的数学运算(线性变换)调整到跟文字令牌“说同一种语言”。这样 AI 就能同时处理两者。
- 输出:这些令牌被送进语言模型,生成回答,比如“图片里是一只狗在公园玩”。
这让 MiniMind-V 能描述图片、回答关于图片的问题,甚至同时聊多张图。
MiniMind-V的结构仅增加Visual Encoder和特征投影两个子模块,增加模态混合分支,以支持多种模态信息的输入,引用官方给的图来说明
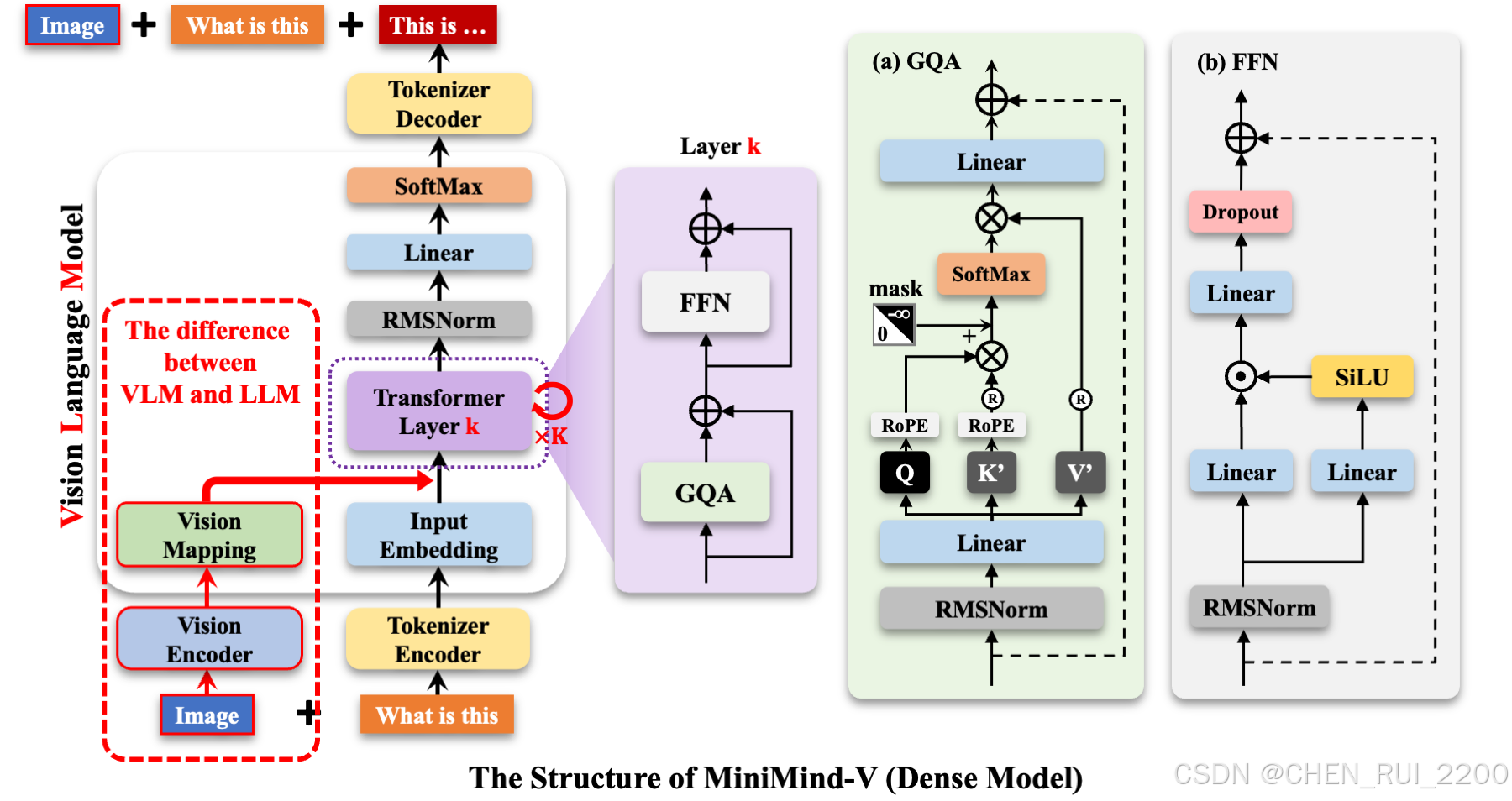
在minimind-v中,使用196个字符组成的 @@@...@@@ 占位符代替图像,之所以是196个字符,前面有所提及: 任何图像都被clip模型encoder为196×768维的token, 因此minimind-v的prompt为:
@@@......@@@\n这个图片描述的是什么内容?计算完embedding和projection,并对图像部分token替换后整个计算过程到输出则和LLM部分没有任何区别。
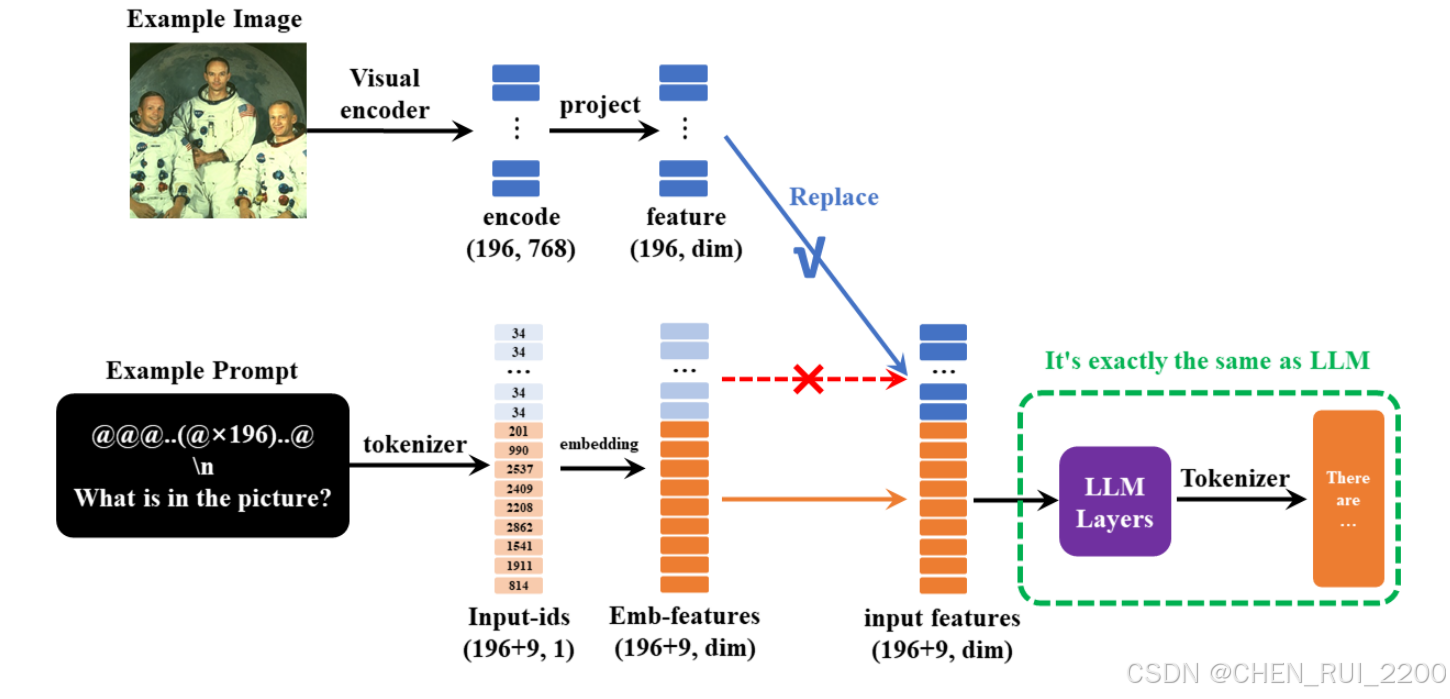
一次性多图的实现方法就是通过注入多个<image>图像占位符进行实现,不需要修改任何框架
MiniMind-V 怎么训练?
训练 VLM 就像教小孩学会看图说话。你得给它看很多例子(数据),慢慢引导它学会规律。以下是训练步骤,用最简单的语言解释:
1. 准备材料(数据和工具)
- 数据集:需要一堆图片和对应的文字说明或问题。比如,一张猫的图片配上“这是一只猫”或者“这是什么动物?”。MiniMind-V 的数据集(约5GB)包括图片和文字文件(JSONL 格式),放在 ./dataset 文件夹。你得下载并解压。
- 预训练语言模型:MiniMind-V 用一个叫 MiniMind 的文字模型作为基础。这个模型已经会聊天了,相当于给 AI 一个起点。你下载它的权重(预训练数据),放进 ./out 文件夹。
- 视觉编码器:用一个叫 CLIP 的预训练模型(clip-vit-base-patch16)来处理图片。CLIP 已经很会看图了,不用从头训。你下载它到 ./model/vision_model 文件夹。
- 软件环境:安装代码需要的 Python 库(列在 requirements.txt 里),就像做饭前把厨房工具准备好。
2. 预训练(学基础知识)
- 干啥:预训练是教 AI 怎么把图片和文字“连起来”。你给它看一大堆图文对(比如一棵树的图片配“这是一棵树”),让它学会图片和文字的关联。
- 咋做:运行代码 1-pretrain_vlm.py,把数据集喂给模型。CLIP 把图片转成令牌(每张图生成196个令牌,每个令牌是768个数字)。这些令牌跟文字令牌混在一起,模型学着预测接下来是什么(比如看到狗的图片和“这”之后,预测“是只狗”)。
- 时间和资源:用 NVIDIA 3090 显卡,大概1小时搞定。因为模型小(2600万参数),数据集也不大,跑得快。训练完会生成一个文件(比如 vlm_pretrain.pth),保存学到的东西。
- 可跳过:如果硬盘空间不够,你可以用项目提供的预训练权重跳过这一步,但自己训会让模型更强。
3. 监督微调(SFT)(教具体技能)
- 干啥:微调是教 AI 怎么回答具体问题或按指令办事。比如,你给它看一张日落图,问“这是啥?”,它得学会回答“这是日落”。
- 咋做:运行代码 train_sft_vlm.py,用一个包含问题-答案对(带图片)的数据集。模型反复练习生成正确答案,调整自己变得更聪明。就像考试前刷题一样。
- 输出:生成一个文件(比如 vlm_sft.pth),保存微调后的模型。这让 AI 在实际任务(比如聊图片)上表现更好。
- 为啥重要:微调让模型更实用,能真正帮你解决问题,而不是只会背图文对。
4. 测试模型(看看学得咋样)
- 干啥:训练完后,你可以用代码 3-test_vlm.py 测试模型。给它一张图和一个问题,看它回答得对不对。
- 例子:你上传一张狗的图片,问“这是啥?”,模型应该回答“这是只狗”。如果答错了,说明训练可能还得调调。
5 重点分析下
这个继承自语言模型的视觉语言模型
class MiniMindVLM(MiniMindForCausalLM):
config_class = VLMConfig
def __init__(self, params: VLMConfig = None, vision_model_path="./model/vision_model/clip-vit-base-patch16"):
super().__init__(params)
if not params: params = VLMConfig()
self.params = params
self.vision_encoder, self.processor = self.__class__.get_vision_model(vision_model_path)
self.vision_proj = VisionProj(hidden_size=params.hidden_size)
模型的整体功能
MiniMindVLM 是一个视觉语言模型,它的核心任务是:
- 输入:接收文本(以 input_ids 表示,类似分词后的文字编号)和/或图像(以 pixel_values 表示,类似像素数据)。
- 输出:生成预测结果(logits,表示每个词的概率分布),可以用来生成文本或回答问题。
- 额外功能:支持缓存(past_key_values)以加速生成,支持混合专家(MoE)机制(通过 aux_loss),并能处理视觉和文本的混合输入。
从代码看,模型的结构可以分为以下几个主要部分:
- 嵌入层(embed_tokens):将输入的文本 token 转为向量表示。
- 视觉编码器(vision_encoder):处理图像输入,生成图像特征。
- 变换器层(model.layers):核心的神经网络层,处理文本和图像特征。
- 输出头(lm_head):将处理后的特征转为预测结果。
- 辅助组件:如归一化(norm)、位置编码(freqs_cos 和 freqs_sin)和混合专家损失(aux_loss)。
forward方法
def forward(self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[Tuple[torch.Tensor, torch.Tensor]]] = None,
use_cache: bool = False,
logits_to_keep: Union[int, torch.Tensor] = 0,
pixel_values: Optional[torch.FloatTensor] = None,
**args):- input_ids:文本输入的 token ID(形状 [batch_size, seq_length]),表示分词后的文本序列。例如,“你好”可能被编码为 [101, 203, 102]。
- attention_mask:注意力掩码,标记哪些 token 需要关注(1 表示关注,0 表示忽略),用于处理变长序列。
- past_key_values:缓存的键值对,用于加速自回归生成(比如生成长文本时复用之前的计算结果)。
- use_cache:是否启用缓存,True 时返回 past_key_values。
- logits_to_keep:指定输出的 logits 范围(整数或索引),控制返回哪些位置的预测结果。
- pixel_values:图像输入(形状可能是 [batch_size, num_images, channels, height, width]),表示一批图片的像素数据。
- args:其他未使用的参数,增加灵活性。
模型支持同时处理文本和图像(pixel_values 可选),并且通过 past_key_values 和 use_cache 支持增量生成,说明这是一个自回归变换器模型(类似 GPT),但增加了视觉处理能力。
其中图像处理的方法
if pixel_values is not None and start_pos == 0:
if len(pixel_values.shape) == 6:
pixel_values = pixel_values.squeeze(2)
bs, num, c, im_h, im_w = pixel_values.shape
stack_dim = 1 if bs > 1 else 0
vision_tensors = torch.stack([
MiniMindVLM.get_image_embeddings(pixel_values[:, i, :, :, :], self.vision_encoder)
for i in range(num局化num)
], dim=stack_dim)
hidden_states = self.count_vision_proj(tokens=input_ids, h=hidden_states, vision_tensors=vision_tensors,
seqlen=input_ids.shape[1])- 形状调整:
- 如果 pixel_values 是 6 维(可能包含额外维度),用 squeeze(2) 移除第 2 维。
- 解析形状为 [batch_size, num_images, channels, height, width],表示每批有 num_images 张图片。
- 图像编码:
- 遍历每张图片(pixel_values[:, i, :, :, :]),用 self.vision_encoder(可能是 CLIP 模型)生成图像嵌入(get_image_embeddings)。
- 将所有图像嵌入堆叠为 vision_tensors(形状取决于批次大小)。
- 融合图像和文本:
- self.count_vision_proj:将图像嵌入(vision_tensors)与文本嵌入(hidden_states)融合,生成新的 hidden_states。
- 融合考虑了 input_ids 和序列长度(seqlen),可能通过投影层(线性变换)将图像特征映射到文本特征空间。
结构功能:
- vision_encoder 是一个独立的视觉编码器(这里使用的是CLIP-ViT-Base-Patch16),专门处理图像,输出固定维度的特征向量。
- count_vision_proj 是一个投影层,将图像特征与文本特征对齐,表明模型在结构上将视觉和语言信息融合到一个统一的表示空间。
- 图像处理只在序列开始(start_pos == 0)执行,说明图像特征在生成后续 token 时会被缓存(通过 past_key_values)。
位置编码
使用旋转位置编码(Rotary Position Embedding, RoPE)
position_embeddings = (
self.model.freqs_cos[start_pos:start_pos + seq_length],
self.model.freqs_sin[start_pos:start_pos + seq_length]
)归一化和混合专家损失
hidden_states = self.model.norm(hidden_states)
aux_loss = sum(
layer.mlp.aux_loss
for layer in self.model.layers
if isinstance(layer.mlp, MOEFeedForward)
)混合专家(MoE)损失:
- 检查每层的 mlp(前馈网络)是否是 MOEFeedForward 类型。
- 如果是,累加其 aux_loss(辅助损失,可能用于 MoE 的负载均衡)。
-
aux_loss 是 MoE 的正则化项,确保专家使用均衡,说明模型可能在性能和效率间做了优化。
6. 模型特点与设计亮点
- 视觉-语言融合:
- 通过 vision_encoder 和 count_vision_proj,模型将图像和文本特征统一到同一表示空间,支持多模态任务(如图像描述、视觉问答)。
- 图像处理只在序列开始执行,优化了增量生成的效率。
- 高效变换器:
- 使用旋转位置编码(RoPE),减少位置编码的内存开销。
- 支持 MoE 机制(MOEFeedForward),通过稀疏激活降低计算量,适合轻量模型(MiniMind-V 只有 2600 万参数)。
- 缓存机制(past_key_values)加速长序列生成。
- 灵活输出:
- logits_to_keep 允许控制输出范围,优化计算或生成特定长度的序列。
- self.OUT 提供多种输出(logits、hidden_states、past_key_values),支持多种下游任务。
- 轻量设计:
- 结合 Dropout 和 LayerNorm,模型训练稳定,适合在消费级 GPU上运行。
- MiniMind-V 的小规模(2600 万参数)和快速训练(1 小时)表明它在结构上做了大量优化。
模型训练
下载模型基座
下载clip模型到 ./model/vision_model 目录下,CLIP-ViT-Base-Patch16 像一个“图像翻译器”,把图片内容翻译成语言模型能懂的“数字语言”(特征向量)。语言模型像一个“讲故事的人”,根据文本和 CLIP 提供的图像信息,生成答案或描述。
git clone https://www.modelscope.cn/models/openai-mirror/clip-vit-base-patch16- CLIP:由 OpenAI 开发的全称是 “Contrastive Language-Image Pretraining”(对比式语言-图像预训练)。它是一个多模态模型,能够同时理解图像和文本,通过在大规模图文对数据上预训练,学会将图像和文本映射到同一个特征空间。
- ViT:表示 “Vision Transformer”,是 CLIP 的视觉部分,使用 Transformer 架构处理图像。
- Base:表示模型规模中等(相比 Small 或 Large)。
- Patch16:表示将图像分割成 16x16 像素的 patch(小块),作为输入处理。
下载纯语言模型权重到 ./out 目录下(作为训练VLM的基座语言模型)
wget -c https://huggingface.co/jingyaogong/MiniMind2-V-PyTorch/blob/main/lm_512.pth训练
下载数据集
minimind-v_dataset 是一个由 Jingyao Gong 提供的数据集,主要用于机器学习和计算机视觉任务。以下是该数据集的主要特点:
- 模态:图像
- 文件格式:imagefolder
- 数据集大小:小于 1K
- 相关文献:包含两篇 ArXiv 论文(arxiv: 2304.08485 和 arxiv: 2310.03744)
- 文件结构:
- 包含多个 JSONL 文件和压缩的图像文件,如
pretrain_images.zip和sft_images.zip。 - 还包括 README 文件,提供数据集的详细说明。
- 包含多个 JSONL 文件和压缩的图像文件,如
该数据集适合用于预训练和微调模型,特别是在视觉语言模型(VLM)相关的研究中。
from huggingface_hub import list_repo_files, hf_hub_download
import os
# 数据集的 repo_id
repo_id = "jingyaogong/minimind-v_dataset"
save_dir = "./dataset"
# 创建保存目录
os.makedirs(save_dir, exist_ok=True)
# 获取数据集中的所有文件列表
files = list_repo_files(repo_id=repo_id, repo_type="dataset")
print("Found files:", files)
# 下载每个文件
for file in files:
print(f"Downloading {file}...")
hf_hub_download(
repo_id=repo_id,
filename=file,
repo_type="dataset",
local_dir=save_dir,
local_dir_use_symlinks=False # 直接保存文件,避免符号链接
)
print(f"Saved {file} to {save_dir}")
print("All files downloaded!")
开启训练
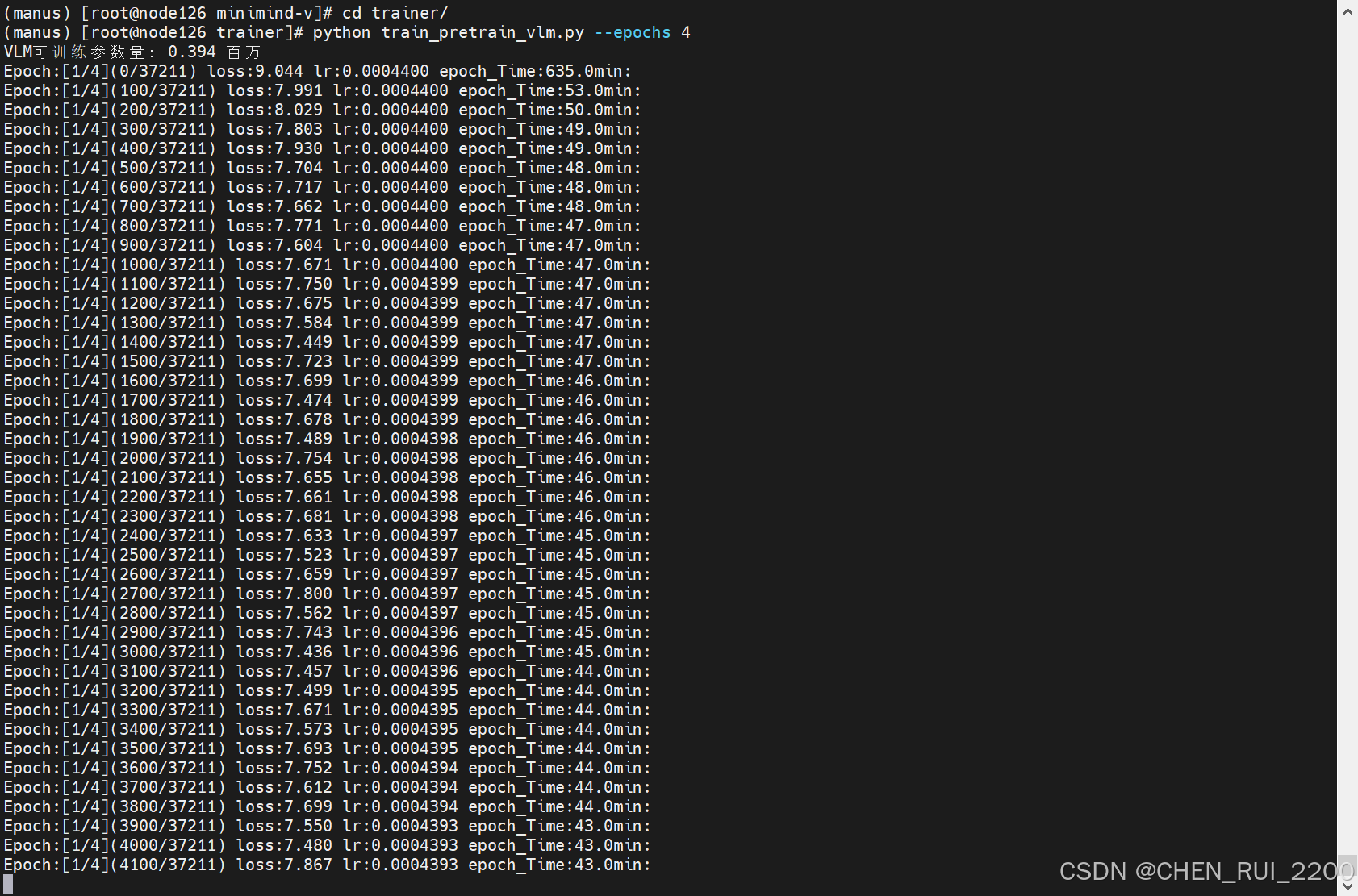
预训练(学图像描述)
预训练从595K条数据集中学习图片的通用知识,比如鹿是鹿,狗是狗。
torchrun --nproc_per_node 2 train_pretrain_vlm.py --epochs 4
监督微调(学看图对话方式)
指令微调从300K条真实对话数据集中学习对图片提问的真实问答格式,更符合与人类的交流习惯。训练时均冻结visual encoder也就是clip模型梯度, 只训练Projection和LLM两部分。 预训练中,只设置Projection和LLM的最后一层参数可学习。 指令微调中,设置Projection和LLM的全部参数可学习。SFT 代码里把下面注释代码放开冻结参数
# 只解冻注意力机制中的投影层参数
for name, param in model.model.named_parameters():
if any(proj in name for proj in ['q_proj', 'k_proj', 'v_proj', 'o_proj']):
param.requires_grad = True实际上作者是在保存模型权重的时候过滤 vision_encoder 参数
if (step + 1) % args.save_interval == 0 and (not ddp or dist.get_rank() == 0):
model.eval()
moe_path = '_moe' if model_config.use_moe else ''
...
clean_state_dict = {
key: value for key, value in state_dict.items() if not key.startswith('vision_encoder.')
}
clean_state_dict = {k: v.half() for k, v in clean_state_dict.items()} # 半精度保存
torch.save(clean_state_dict, ckp)- 保存模型权重时,显式过滤掉以 vision_encoder. 开头的参数(即 CLIP 模型的参数)。
- 这表明开发者假设 CLIP 模型的参数不需要保存,可能因为它们在训练中保持不变(冻结)或直接使用预训练权重。
-
虽然训练代码没有冻结 vision_encoder,但保存权重时过滤 vision_encoder 参数,暗示开发者可能预期 CLIP 模型不参与训练,或者认为它的权重不需要更新。
为什么需要冻结 CLIP 模型?
- 预训练优势:CLIP 模型(clip-vit-base-patch16)已经在大型图文数据集上预训练,特征提取能力强,无需进一步微调。
- 计算效率:CLIP 模型参数量较大(约 8600 万),冻结它可以减少显存占用和计算量,加速训练(MiniMind-V 强调轻量高效)。
- 任务需求:监督微调(SFT)阶段主要优化语言生成能力(LLM)和图文对齐(Projection),CLIP 的视觉特征通常保持不变。
模型转换
if __name__ == '__main__':
lm_config = VLMConfig(hidden_size=512, num_hidden_layers=16, max_seq_len=8192, use_moe=False)
torch_path = f"../out/sft_vlm_{lm_config.hidden_size}{'_moe' if lm_config.use_moe else ''}.pth"
transformers_path = '../MiniMind2-V'
convert_torch2transformers_minimind(torch_path, transformers_path)运行 web_demo
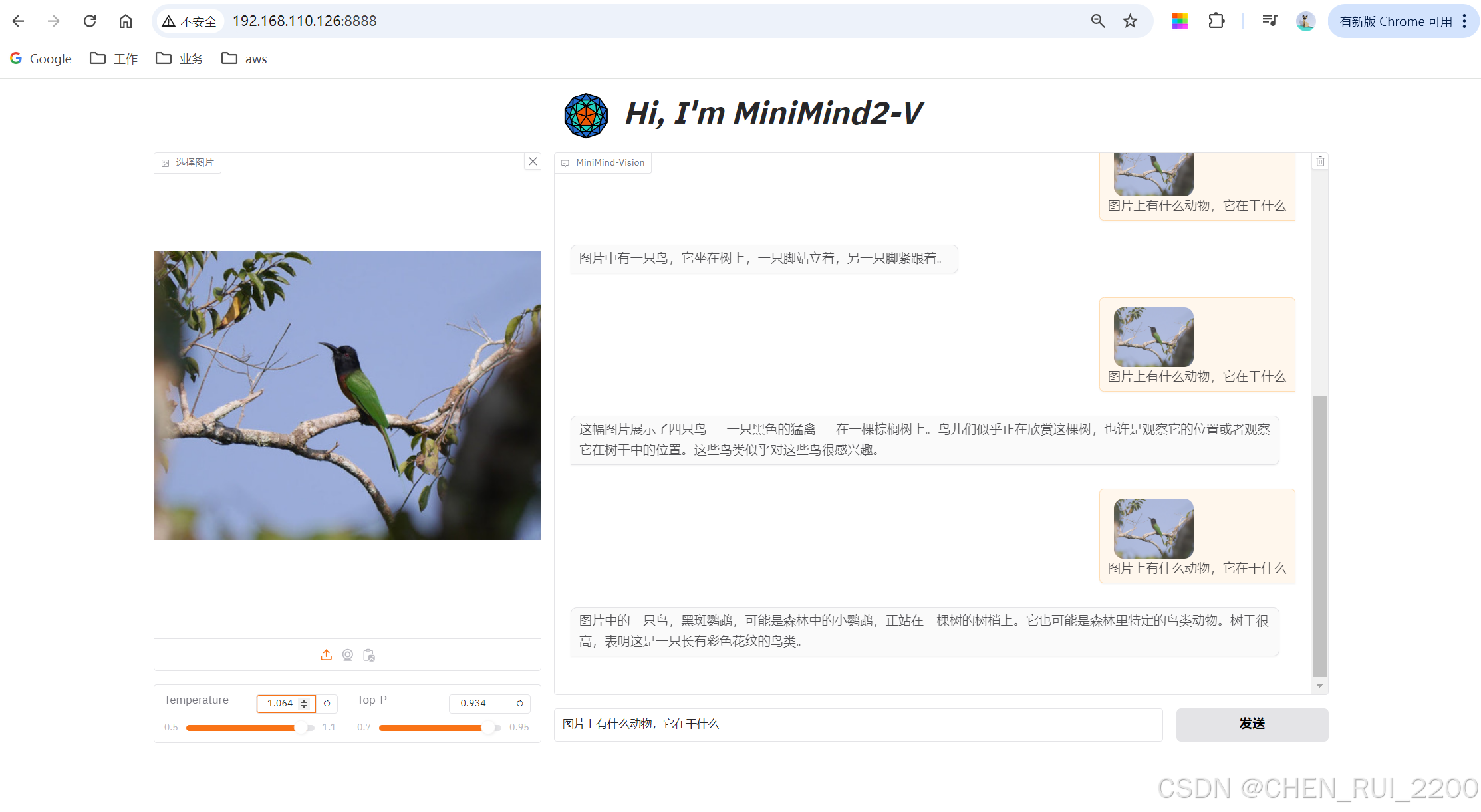
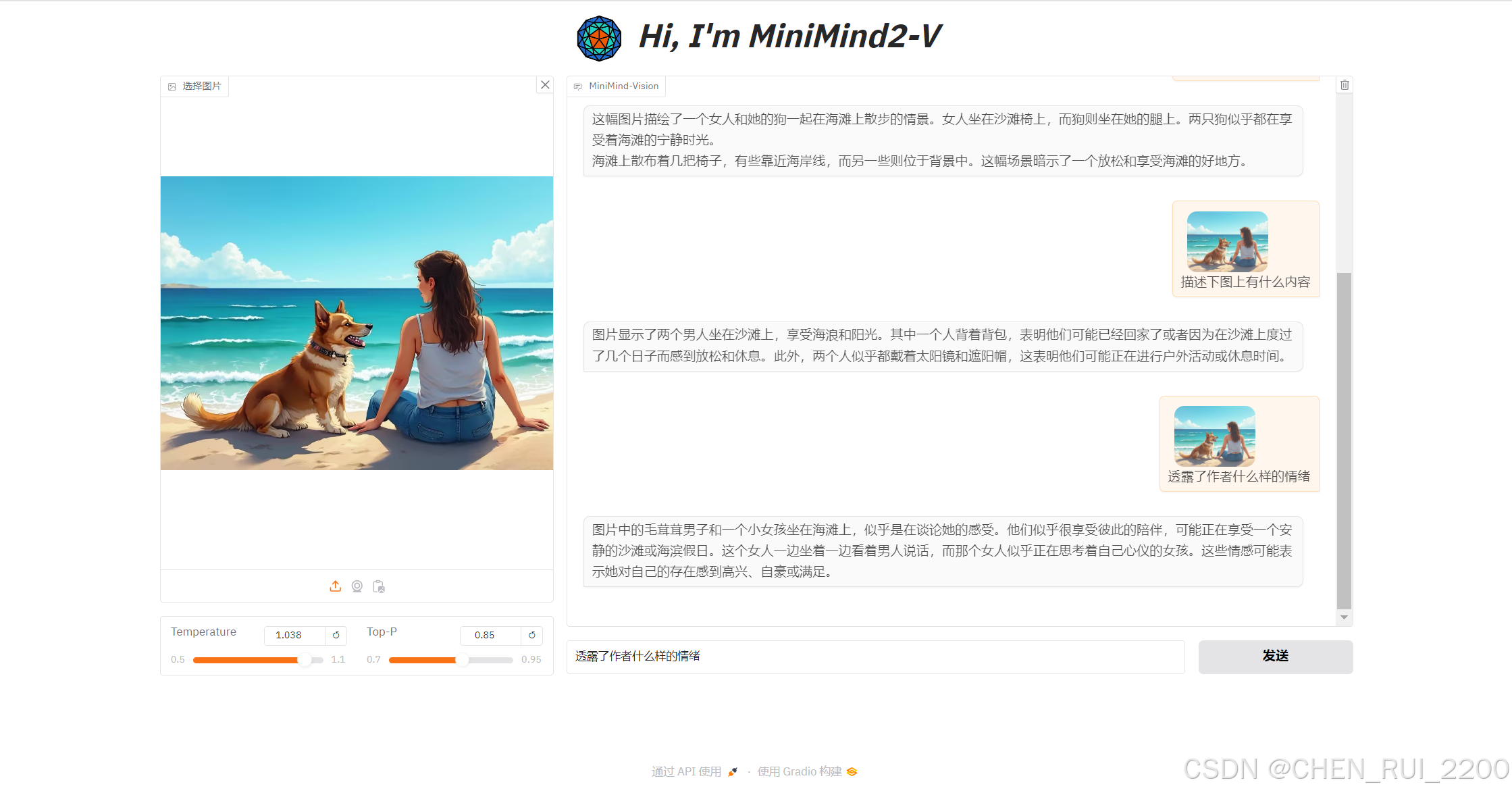
Transformers 库通过以下机制支持图像和文本的多模态功能(以 MiniMind-V 和 _generate 方法为上下文):model.generate 来生成文本输出,结合了文本(input_ids)和图像(pixel_values)输入,体现了一种多模态生成能力
model.generate(
inputs.input_ids,
max_new_tokens=args.max_seq_len,
do_sample=True,
temperature=temperature,
top_p=top_p,
attention_mask=inputs.attention_mask,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
streamer=streamer,
pixel_values=pixel_values
)