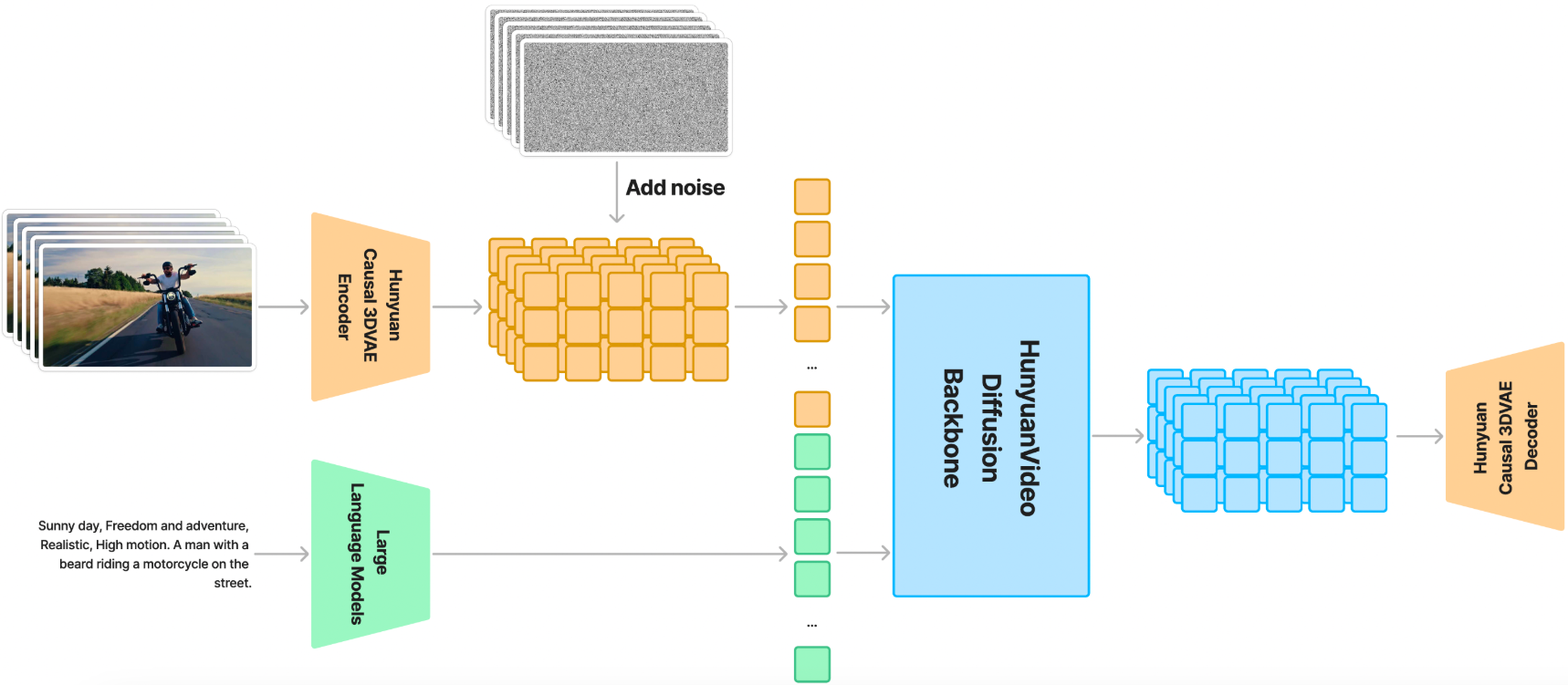
文章目录
- **一、前期诊断:定位性能瓶颈**
- **1. 数据现状分析**
- **2. 业务场景梳理**
- **二、基础优化:快速提升性能**
- **1. 索引精准优化**
- **2. 表结构优化(垂直分表)**
- **3. 读写分离与缓存策略**
- **三、架构升级:应对千万级数据**
- **1. 水平分表(单库内分表)**
- **2. 分库(分布式架构)**
- **3. 引入搜索引擎(Elasticsearch)**
- **四、长期维护与性能保障**
- **1. 数据归档与冷存储**
- **2. 监控与自动化运维**
- **3. 应急预案**
- **五、总结:优化路线图**
- **回答亮点总结**
- 补充:
当面试官询问数据库层面的订单优化改造时,需结合技术原理与落地步骤,分阶段阐述具体方案。以下是详细的结构化回答,涵盖 诊断分析→基础优化→架构升级→长期维护全流程,突出技术深度与项目落地思维:
一、前期诊断:定位性能瓶颈
1. 数据现状分析
- 核心指标采集:
- 单表数据量(如
orders表是否超过 500 万条)、日增量(判断增长趋势)。 - 字段数量(是否存在大字段如
detail_json导致行存储过大)。 - 主从延迟情况(读写分离场景下,从库复制是否滞后)。
- 单表数据量(如
- 慢查询捕捉:
- 开启数据库慢查询日志(如 MySQL 的
slow_query_log),设置阈值(如long_query_time=1s)。 - 使用工具分析慢查询语句(如
pt-query-digest),统计高频慢查询模式(例如:SELECT * FROM orders WHERE user_id=? AND status=? LIMIT 100000,10)。
- 开启数据库慢查询日志(如 MySQL 的
2. 业务场景梳理
- 区分热数据(近 30 天订单,高频查询 / 更新)与冷数据(历史订单,低频查询)。
- 明确查询特征:
- 列表页查询:主要条件(如
user_id+status+create_time分页)。 - 详情页查询:基于
order_id的单条查询。 - 复杂查询:模糊搜索订单号、多状态统计(如 “待支付 + 已取消” 订单总数)。
- 列表页查询:主要条件(如
二、基础优化:快速提升性能
1. 索引精准优化
- 覆盖索引解决分页慢问题:
- 问题场景:深分页(如
LIMIT 10000, 20)导致数据库扫描大量无用数据。 - 优化方案:
- 创建复合索引
(user_id, status, create_time, id),利用索引排序避免文件排序(EXPLAIN中type=range且Extra=Using index)。 - 改用Keyset 分页:记录最后一条数据的
id,下次查询用WHERE id > last_id AND user_id=? AND status=? LIMIT 20,减少偏移量计算。
- 创建复合索引
- 问题场景:深分页(如
- 复合索引替代单列索引:
- 对高频查询条件组合(如
user_id + status + create_time),创建索引(user_id, status, create_time),遵循最左匹配原则。
- 对高频查询条件组合(如
- 删除无效索引:
- 通过
SHOW INDEX FROM orders查看未使用的索引(可借助sys.schema_unused_indexes视图),删除冗余索引(如仅用于ORDER BY的单列索引,若已被复合索引覆盖则可删除)。
- 通过
2. 表结构优化(垂直分表)
-
大字段拆分:
-
将
detail、attachments等大字段迁移到单独表order_details,主表仅保留order_id和必要字段,减少主表行大小,提升SELECT性能。 -
示例:
-- 原表 CREATE TABLE orders ( id BIGINT PRIMARY KEY, user_id BIGINT, status TINYINT, create_time DATETIME, detail TEXT -- 大字段 ); -- 拆分后 CREATE TABLE orders ( id BIGINT PRIMARY KEY, user_id BIGINT, status TINYINT, create_time DATETIME ); CREATE TABLE order_details ( order_id BIGINT PRIMARY KEY, detail TEXT, FOREIGN KEY (order_id) REFERENCES orders(id) );
-
-
枚举字段优化:
- 将
status等固定值字段改为ENUM类型(如ENUM('待支付', '已支付', '已取消')),减少存储占用(从INT的 4 字节降至 1 字节)。
- 将
3. 读写分离与缓存策略
-
主从复制实现读负载分流:
- 配置 1 主 N 从架构(如 1 主 2 从),通过中间件(如
MyCat、ShardingSphere-JDBC)将查询请求路由到从库。 - 注意:对实时性要求高的查询(如刚创建的订单立即显示),可走主库或缓存(见下文)。
- 配置 1 主 N 从架构(如 1 主 2 从),通过中间件(如
-
热点数据缓存:
-
对高频查询的订单列表(如用户最近 100 条订单),使用 Redis 缓存:
// 缓存键设计:user:123:orders:recent:page1 String cacheKey = String.format("user:%d:orders:recent:%d", userId, pageNum); List<Order> cachedOrders = redisTemplate.opsForValue().get(cacheKey); if (cachedOrders == null) { cachedOrders = orderRepository.queryRecentOrders(userId, pageNum); // 数据库查询 redisTemplate.opsForValue().set(cacheKey, cachedOrders, 5, TimeUnit.MINUTES); // 5分钟过期 } return cachedOrders; -
缓存更新策略:订单状态变更时,删除对应缓存(如
redisTemplate.delete(cacheKey)),保证数据一致性。
-
三、架构升级:应对千万级数据
1. 水平分表(单库内分表)
- 分表策略选择:
- 按时间分表:适用于订单按年月查询的场景(如
orders_202312、orders_202401),缺点是跨月查询需 JOIN 多个表。 - 按用户 ID 分表:通过
user_id % 1024路由到不同表(如orders_0到orders_1023),优点是单用户查询仅命中一张表,缺点是跨用户统计需聚合所有表。
- 按时间分表:适用于订单按年月查询的场景(如
- 分表实现方案:
- 代码层路由:在 DAO 层通过
user_id计算表名(如orders_${user_id % 1024}),适合中小规模系统。 - 中间件路由:使用
ShardingSphere或MyCat,配置分表规则,对应用透明(推荐)。
- 代码层路由:在 DAO 层通过
- 分表后注意事项:
- 分布式 ID 生成:使用雪花算法(Snowflake)或数据库自增序列(如
orders_0自增从 1 开始,orders_1从 1000001 开始)保证全局唯一。 - 跨表查询:避免
SELECT * FROM orders WHERE status=?全表扫描,可通过搜索引擎(见下文)或定期汇总统计结果到汇总表。
- 分布式 ID 生成:使用雪花算法(Snowflake)或数据库自增序列(如
2. 分库(分布式架构)
- 分库场景:单库存储超过硬件瓶颈(如磁盘 IO、连接数),需将数据拆分到多个数据库实例。
- 分库策略:
- 按业务分库:订单库独立于用户库、商品库(垂直分库)。
- 按用户分库:将用户 ID 尾号 0-4 的订单放在库 1,5-9 的放在库 2(水平分库),每个库包含完整的表结构。
- 分库中间件:
- 使用
ShardingSphere-Proxy作为数据库代理层,处理跨库查询(如SELECT COUNT(*) FROM orders WHERE status=?需合并多个库的结果)。 - 引入分布式事务解决方案(如
Seata),保证跨库操作一致性(如订单创建时扣减库存需跨库事务)。
- 使用
3. 引入搜索引擎(Elasticsearch)
-
适用场景:模糊查询(如订单号包含
202401)、多条件组合查询(如 “北京地区 + 金额> 1000 + 待支付”)。 -
实施步骤:
-
数据同步:通过
Canal监听数据库 binlog,实时将订单数据同步到 ES(或使用定时任务批量同步)。 -
ES 索引设计:
{ "mappings": { "properties": { "order_id": {"type": "keyword"}, // 精确查询 "user_id": {"type": "long"}, "status": {"type": "keyword"}, // 枚举值 "create_time": {"type": "date", "format": "yyyy-MM-dd HH:mm:ss"}, "amount": {"type": "scaled_float", "scaling_factor": 100}, // 金额精确到分 "city": {"type": "keyword"} // 地理位置关键词 } } } -
查询流程:前端搜索请求→ES 快速检索
order_id列表→通过order_id批量从数据库查询完整订单数据(减少数据库压力)。
-
四、长期维护与性能保障
1. 数据归档与冷存储
-
定期归档历史数据:
-
每月将 3 个月前的订单数据迁移到归档表(如
orders_archive_2023)或冷存储(如 Hive、OSS),主表仅保留近 3 个月数据。 -
归档脚本示例(MySQL):
INSERT INTO orders_archive (SELECT * FROM orders WHERE create_time < '2024-01-01'); DELETE FROM orders WHERE create_time < '2024-01-01';
-
-
冷数据查询方案:
- 对归档数据使用大数据查询引擎(如 Presto)或定期生成统计报表,避免直接查询主库。
2. 监控与自动化运维
- 关键指标监控:
- 数据库层:QPS、TPS、慢查询数量、锁等待时间、主从延迟(如
Seconds_Behind_Master)。 - 应用层:缓存命中率、接口响应时间(如 95% 请求在 500ms 内返回)。
- 数据库层:QPS、TPS、慢查询数量、锁等待时间、主从延迟(如
- 自动化优化工具:
- 使用
AutoOptimize等工具自动分析索引使用情况,建议创建或删除索引。 - 基于数据量阈值自动触发分表扩容(如单表超过 1000 万条时,自动新增分表)。
- 使用
3. 应急预案
- 读写失败重试机制:对因锁竞争导致的写失败(如
Deadlock),在应用层添加重试逻辑(最多 3 次,间隔递增)。 - 流量削峰:在大促期间,通过消息队列(如 Kafka)异步处理订单写入,避免瞬时高并发压垮数据库。
五、总结:优化路线图
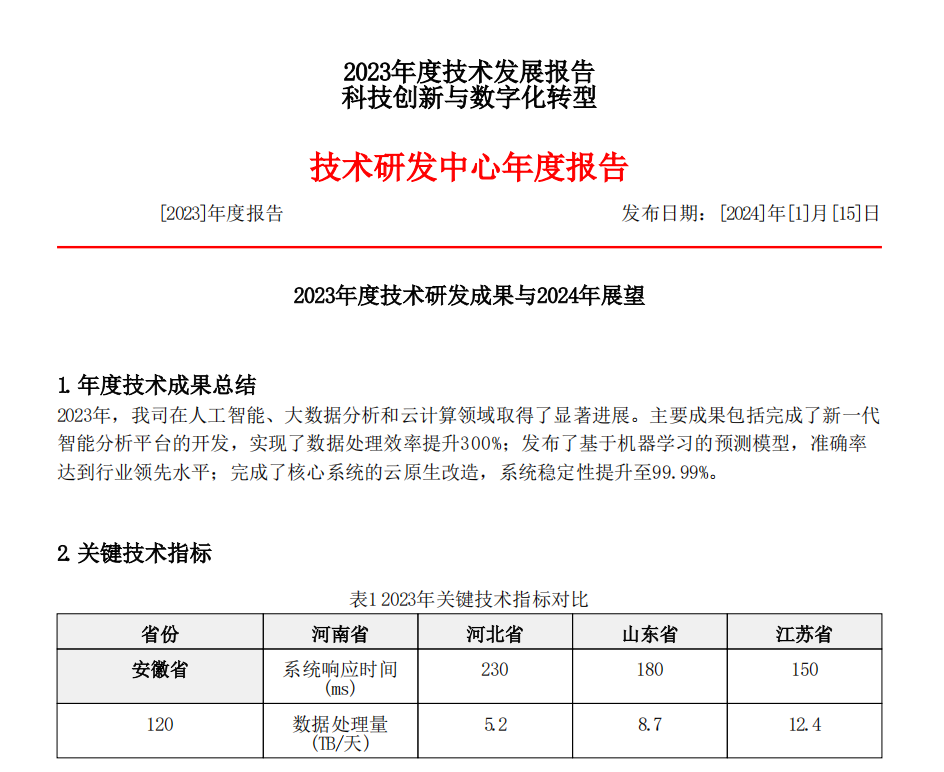
| 数据规模 | 阶段 | 核心优化手段 | 实施成本 | 耗时 |
|---|---|---|---|---|
| 10 万~100 万条 | 基础优化 | 索引优化、读写分离、缓存 | 低 | 1~2 周 |
| 100 万~1000 万条 | 分表分库 | 水平分表、垂直分库 | 中 | 2~4 周 |
| 1000 万~1 亿条 | 分布式架构 | 引入 ES、分库 + 分布式事务 | 高 | 4~8 周 |
| 亿级以上 | 云原生架构 | 云数据库(如 AWS Aurora)、Serverless | 极高 | 长期 |
回答亮点总结
- 分层思维:从诊断→优化→架构→维护层层递进,展示系统性解决方案。
- 技术落地细节:给出具体 SQL 示例、分表规则、缓存代码片段,体现工程实践能力。
- 成本意识:区分不同数据规模的优化策略,说明投入产出比(如先做低成本的索引优化,再逐步升级架构)。
- 前瞻性:提到数据归档、监控自动化、云原生架构,展现对长期性能维护的思考。
通过以上回答,既能体现对数据库优化原理的深入理解,又能展示从问题定位到方案落地的全流程把控能力,符合面试官对 “技术深度 + 项目落地” 的考察需求。
补充:
顺带一提:数据没有超过百万级别但是接口响应缓慢,大多情况下可以直接考虑:
- 前端的分页展示条数可以调小
- 解析SQL查看是否用到索引,是否是索引失效行锁升级为表锁,有无锁竞争情况
- 内存配置不足,数据库读写频繁,导致了I/O出现瓶颈
- 是否调用的外部接口,外部接口响应超时
- 高并发情况下,redis热点数据过期,大量请求打入到mysql,增加热点数据的有效期,避免同一时间失效
- 微服务下:a服务接口调用b服务接口,并且都修改了同一张表,导致事务出现死锁情况
大多情况下都是因为开发的代码不规范而导致