CogVideoX-5b:开启文本到视频生成的新纪元
- 项目背景与目标
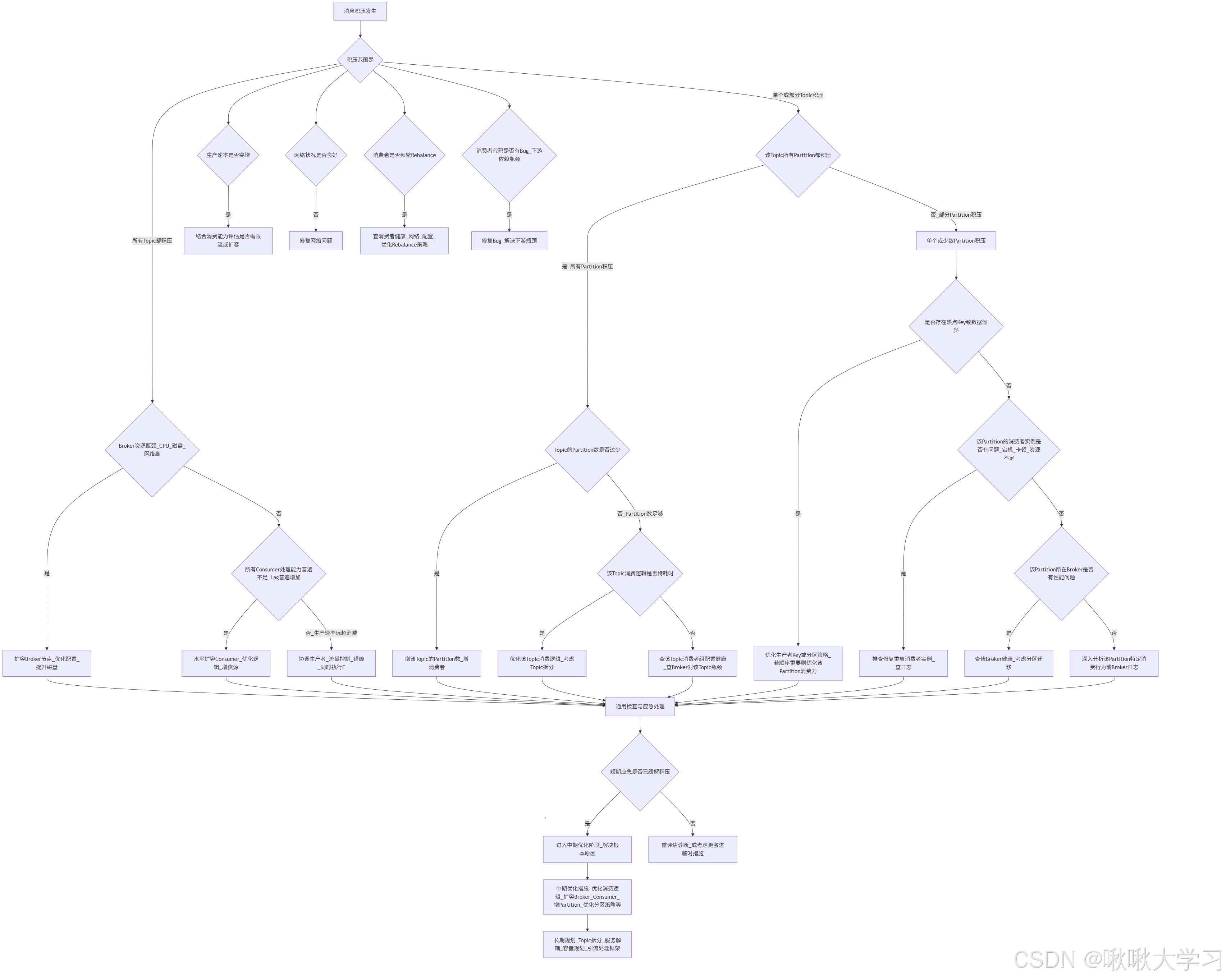
- 模型架构与技术亮点
- 项目运行方式与执行步骤
- 环境准备
- 模型加载与推理
- 量化推理
- 执行报错与问题解决
- 内存不足
- 模型加载失败
- 生成质量不佳
- 相关论文信息
- 总结
在人工智能领域,文本到视频生成技术一直是研究的热点和难点。它不仅需要模型理解复杂的语言指令,还要将其转化为具有连贯性和视觉吸引力的视频内容。CogVideoX-5b 是由清华大学团队开发的一种先进的开源文本到视频生成模型,它在这一领域取得了显著的突破,为研究人员和开发者提供了一个强大的工具。
项目背景与目标
随着深度学习技术的飞速发展,文本生成图像的技术已经取得了令人瞩目的成就。然而,将文本直接转化为视频内容面临着更多的挑战。视频生成不仅需要生成每一帧的图像,还需要确保这些图像在时间序列上具有连贯性,形成一个自然流畅的视频。CogVideoX-5b 的目标是通过引入专家 Transformer 架构,提升文本到视频生成的质量和效率,使其能够生成高质量、高分辨率的视频内容,同时降低运行成本和硬件要求。
模型架构与技术亮点
CogVideoX-5b 基于扩散模型(diffusion models)框架构建,它通过逐步去除噪声来生成视频内容。其核心架构包括以下几个关键部分:
-
文本编码器(Text Encoder):负责将输入的文本提示转化为语义向量,为视频生成提供语义指导。CogVideoX-5b 使用了 T5 编码器,这是一种基于 Transformer 的强大文本编码器,能够有效地捕捉文本中的语义信息。
-
专家 Transformer(Expert Transformer):这是 CogVideoX-5b 的核心创新之一。它专门用于处理视频生成任务中的时空信息,确保生成的视频在时间和空间上都具有连贯性。通过引入 3D RoPE(3D Rotary Positional Embedding)位置编码,模型能够更好地理解和生成具有深度和动态效果的视频内容。
-
解码器(Decoder):负责将文本编码器和专家 Transformer 的输出转化为具体的视频帧。CogVideoX-5b 使用了高效的解码器架构,能够快速生成高质量的视频内容。
-
优化与量化技术:为了提高模型的运行效率和降低硬件要求,CogVideoX-5b 引入了多种优化技术,如模型 CPU 卸载(model CPU offload)、VAE 分片(VAE tiling)等。此外,通过 PytorchAO 和 Optimum-quanto 进行量化,可以在不显著降低视频质量的情况下,大幅减少模型的内存占用,使其能够在资源受限的设备上运行。
项目运行方式与执行步骤
环境准备
在开始运行 CogVideoX-5b 之前,需要确保已经安装了必要的依赖库。以下是推荐的安装步骤:
pip install --upgrade transformers accelerate diffusers imageio-ffmpeg
这些库分别提供了模型加载、加速计算、视频生成等功能。
模型加载与推理
以下是一个简单的代码示例,展示如何使用 CogVideoX-5b 生成视频:
import torch
from diffusers import CogVideoXPipeline
from diffusers.utils import export_to_video
# 定义文本提示
prompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmosphere of this unique musical performance."
# 加载模型
pipe = CogVideoXPipeline.from_pretrained(
"THUDM/CogVideoX-5b",
torch_dtype=torch.bfloat16
)
# 启用优化
pipe.enable_model_cpu_offload()
pipe.vae.enable_tiling()
# 生成视频
video = pipe(
prompt=prompt,
num_videos_per_prompt=1,
num_inference_steps=50,
num_frames=49,
guidance_scale=6,
generator=torch.Generator(device="cuda").manual_seed(42),
).frames[0]
# 保存视频
export_to_video(video, "output.mp4", fps=8)
量化推理
为了在资源受限的设备上运行模型,可以使用 PytorchAO 进行量化。以下是一个量化推理的示例代码:
import torch
from diffusers import AutoencoderKLCogVideoX, CogVideoXTransformer3DModel, CogVideoXPipeline
from diffusers.utils import export_to_video
from transformers import T5EncoderModel
from torchao.quantization import quantize_, int8_weight_only
# 定义量化方式
quantization = int8_weight_only
# 加载并量化文本编码器
text_encoder = T5EncoderModel.from_pretrained("THUDM/CogVideoX-5b", subfolder="text_encoder", torch_dtype=torch.bfloat16)
quantize_(text_encoder, quantization())
# 加载并量化 Transformer
transformer = CogVideoXTransformer3DModel.from_pretrained("THUDM/CogVideoX-5b", subfolder="transformer", torch_dtype=torch.bfloat16)
quantize_(transformer, quantization())
# 加载并量化 VAE
vae = AutoencoderKLCogVideoX.from_pretrained("THUDM/CogVideoX-5b", subfolder="vae", torch_dtype=torch.bfloat16)
quantize_(vae, quantization())
# 创建管道并运行推理
pipe = CogVideoXPipeline.from_pretrained(
"THUDM/CogVideoX-5b",
text_encoder=text_encoder,
transformer=transformer,
vae=vae,
torch_dtype=torch.bfloat16,
)
pipe.enable_model_cpu_offload()
pipe.vae.enable_tiling()
# 生成视频
video = pipe(
prompt=prompt,
num_videos_per_prompt=1,
num_inference_steps=50,
num_frames=49,
guidance_scale=6,
generator=torch.Generator(device="cuda").manual_seed(42),
).frames[0]
# 保存视频
export_to_video(video, "output.mp4", fps=8)
执行报错与问题解决
在运行 CogVideoX-5b 时,可能会遇到一些常见的问题和报错。以下是一些常见的问题及其解决方法:
内存不足
如果在运行模型时遇到内存不足的问题,可以尝试以下方法:
- 启用优化:确保启用了模型 CPU 卸载和 VAE 分片等优化功能。这些优化可以显著减少 GPU 内存的使用量。
- 降低推理精度:将推理精度从
bfloat16降低到float16或int8,这可以在一定程度上减少内存占用,但可能会牺牲一些生成质量。 - 减少生成帧数:减少生成的视频帧数,例如将
num_frames从 49 降低到 24 或更低。
模型加载失败
如果在加载模型时遇到问题,可能是由于网络连接问题或模型文件损坏。可以尝试以下方法:
- 检查网络连接:确保网络连接正常,能够访问 Hugging Face 的模型仓库。
- 重新下载模型:如果模型文件损坏,可以尝试重新下载模型。
- 使用本地模型文件:如果网络连接不稳定,可以将模型文件下载到本地,然后从本地加载模型。
生成质量不佳
如果生成的视频质量不符合预期,可以尝试以下方法:
- 调整文本提示:优化文本提示,使其更加具体和详细。例如,明确描述场景中的物体、动作和氛围。
- 调整生成参数:调整生成参数,如
guidance_scale、num_inference_steps等,以找到最佳的生成效果。 - 使用更强大的硬件:如果硬件性能不足,可能会导致生成质量下降。可以尝试在更强大的 GPU 上运行模型。
相关论文信息
CogVideoX-5b 的相关研究发表在论文《CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer》中,论文链接为:arXiv:2408.06072。该论文详细介绍了模型的架构、训练方法和实验结果,为研究人员提供了深入理解 CogVideoX-5b 的理论基础。
总结
CogVideoX-5b 是一个强大的文本到视频生成模型,它通过引入专家 Transformer 架构和多种优化技术,在生成质量和运行效率上取得了显著的突破。通过本文的详细介绍,读者可以快速了解 CogVideoX-5b 的技术原理、运行方式和常见问题的解决方法。希望 CogVideoX-5b 能够为研究人员和开发者提供一个有力的工具,推动文本到视频生成技术的发展。


![[CSS3]百分比布局](https://i-blog.csdnimg.cn/img_convert/48e558efd47474a9ad03b7ffe2549e86.png)