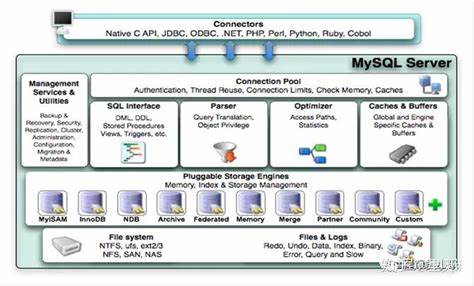
在 MongoDB 中设计文档结构是一个核心且重要的环节,它直接影响应用的性能、可扩展性和可维护性。
MongoDB 文档结构设计原则与方法
MongoDB 的核心思想是数据如何被应用访问,就如何存储它。
-
嵌入 (Embedding / Denormalization) vs. 引用 (Referencing / Normalization):
这是 MongoDB 设计中最关键的决策点。-
嵌入 (Embedding):
- 概念: 将相关联的数据直接存储在父文档内部,通常作为嵌套文档或数组。
- 优点:
- 读取性能高: 一次查询即可获取所有相关数据,无需额外的查询(类似 JOIN)。
- 原子性操作: 对单个文档的更新是原子的。如果嵌入的数据与父文档一起更新,可以保证操作的原子性。
- 缺点:
- 文档大小限制: 单个 BSON 文档最大为 16MB。如果嵌入的数据量巨大,可能超出限制。
- 数据冗余: 如果嵌入的数据也需要在其他地方独立访问或被多个父文档共享,会导致数据冗余和更新困难(需要更新所有包含该数据的文档)。
- 大型文档更新开销: 更新大型文档中的一小部分数据,可能比更新小型独立文档更耗时。
- 适用场景:
- “包含”关系 (contains relationship)。
- 一对一 (one-to-one) 或一对少量 (one-to-few) 关系,且子数据总是与父数据一起被访问。
- 数据不经常独立变化,或者变化时总是与父文档一起。
- 例如:博客文章及其评论(如果评论数量可控且随文章展示)。
-
引用 (Referencing):
- 概念: 类似于关系型数据库中的外键。在一个文档中存储另一个文档的
_id(或其他唯一标识符)。查询时需要通过额外的查询(或使用$lookup操作符)来获取关联数据。 - 优点:
- 数据规范化: 避免数据冗余,更新一个地方即可。
- 更小的文档: 父文档体积更小。
- 灵活性: 关联数据可以独立访问和更新。
- 缺点:
- 读取性能较低: 需要额外的查询(或
$lookup)来获取关联数据,增加了数据库的往返次数。 - 非原子性: 获取和更新关联数据通常需要多个操作,缺乏事务保证(虽然 MongoDB 4.0+ 支持多文档事务,但设计时仍需考虑)。
- 读取性能较低: 需要额外的查询(或
- 适用场景:
- 一对多 (one-to-many) 且“多”的一方数量巨大或无界。
- 多对多 (many-to-many) 关系。
- 关联数据经常独立更新或被多个父文档引用。
- 需要避免大型文档或数据冗余。
- 例如:订单及其关联的产品(产品是独立实体,被多个订单引用)。
- 概念: 类似于关系型数据库中的外键。在一个文档中存储另一个文档的
-
-
考虑数据访问模式 (Data Access Patterns):
- 读写比例: 如果应用是读密集型的,嵌入可以提高性能。如果是写密集型且嵌入数据经常变化,引用可能更好。
- 查询频率和类型: 哪些数据经常一起被查询?设计文档结构以匹配最常见的查询。
- 数据增长: 考虑数组或嵌套文档是否会无限增长,导致文档过大。
-
权衡数据冗余和查询性能:
- 在 MongoDB 中,适度的冗余是可以接受甚至推荐的,如果它能显著提高读取性能并简化查询。
- 例如,在订单文档中嵌入产品名称和价格,即使产品信息存储在单独的集合中。这样在显示订单列表时就不需要再去查询产品集合。但要注意,如果产品价格变动,需要机制去更新所有相关订单中的冗余数据(或接受历史订单价格不变的事实)。
-
原子性需求:
- 如果一组数据的更新必须是原子的,将它们放在同一个文档中。MongoDB 保证单个文档操作的原子性。
-
索引策略:
- 设计文档结构时,要考虑哪些字段会被频繁查询,并为这些字段创建索引。嵌入式文档的字段也可以被索引。
-
常见模式:
- 属性模式 (Attribute Pattern): 对于字段繁多但很多是稀疏的情况,可以将属性作为键值对数组存储。
- 桶模式 (Bucket Pattern): 用于时间序列数据,将一段时间内的数据分组到同一个文档中,减少索引条目。
- 多态模式 (Polymorphic Pattern): 同一个集合存储不同结构的文档,通过一个公共字段(如
type)来区分。
与关系型数据库表结构设计的核心不同
| 特性 | 关系型数据库 (RDBMS) | MongoDB |
|---|---|---|
| 核心思想 | 数据规范化,减少冗余,保证数据一致性。 | 数据如何被访问,就如何存储,优先考虑查询性能和开发便捷性。 |
| Schema | 严格模式 (Schema-on-Write):表结构预先定义,强制执行。 | 灵活模式 (Schema-on-Read):集合不强制文档结构,结构可变。 |
| 数据关系 | 通过外键和 JOIN 操作来表示和查询数据间的关系。 | 通过嵌入文档或引用(_id 或 $lookup)来表示关系。 |
| 范式 | 通常遵循第三范式 (3NF) 或 BCNF 来减少数据冗余。 | 经常使用反范式化(嵌入)来提高读取性能,接受一定程度的数据冗余。 |
| 数据完整性 | 通过外键约束、检查约束、触发器等在数据库层面强制执行。 | 主要依赖应用层面来保证数据完整性。MongoDB 本身约束较少。 |
| JOIN 操作 | SQL JOIN 是核心且高效的操作。 | $lookup 类似于左外连接,但通常性能不如 RDBMS 的 JOIN,设计上尽量避免。 |
| 原子性 | 支持跨多表的 ACID 事务。 | 单文档操作是原子的。多文档 ACID 事务从 4.0 版本开始支持,但设计时仍需权衡。 |
| 数据冗余 | 极力避免。 | 在特定情况下为了性能可以接受和鼓励。 |
| 设计驱动 | 主要由数据本身的逻辑关系驱动。 | 主要由应用程序的访问模式和性能需求驱动。 |
| 数据单元 | 行 (Row) 在表 (Table) 中。 | 文档 (Document) 在集合 (Collection) 中。 |
设计示例思考过程:博客系统
-
实体: 用户 (User), 文章 (Post), 评论 (Comment), 标签 (Tag)
-
关系型设计思路:
users表 (user_id, name, email, …)posts表 (post_id, user_id (FK), title, content, …)comments表 (comment_id, post_id (FK), user_id (FK), text, …)tags表 (tag_id, name)post_tags关联表 (post_id, tag_id)
-
MongoDB 设计思路:
-
Users Collection:
{ "_id": ObjectId("user1"), "name": "Alice", "email": "alice@example.com" } -
Posts Collection:
-
方案 A (嵌入评论和标签,如果量不大且总是随文章展示):
{ "_id": ObjectId("post1"), "title": "My First MongoDB Post", "content": "...", "author_id": ObjectId("user1"), // 引用作者 "author_name": "Alice", // 可选的冗余,用于快速显示 "tags": ["mongodb", "nosql", "database"], // 嵌入标签名 "comments": [ { "user_id": ObjectId("user2"), "user_name": "Bob", "text": "Great post!", "timestamp": ISODate("...") }, { "user_id": ObjectId("user3"), "user_name": "Charlie", "text": "Very informative.", "timestamp": ISODate("...") } ], "publication_date": ISODate("...") }- 考虑: 如果评论非常多,嵌入会导致文档过大,这时应考虑将评论作为独立集合并通过
post_id引用。
- 考虑: 如果评论非常多,嵌入会导致文档过大,这时应考虑将评论作为独立集合并通过
-
方案 B (评论作为独立集合,引用文章ID):
Posts Collection:{ "_id": ObjectId("post1"), "title": "My First MongoDB Post", "content": "...", "author_id": ObjectId("user1"), "author_name": "Alice", "tags": ["mongodb", "nosql", "database"], "publication_date": ISODate("...") }Comments Collection:
{ "_id": ObjectId("comment1"), "post_id": ObjectId("post1"), // 引用文章 "user_id": ObjectId("user2"), "user_name": "Bob", "text": "Great post!", "timestamp": ISODate("...") }
-
-
Tags Collection (如果需要对标签进行管理或聚合分析):
{ "_id": ObjectId("tag_mongo"), "name": "mongodb", "description": "About MongoDB NoSQL database" }文章中可以存储
tag_ids数组,或者像方案 A 那样直接嵌入标签名。如果嵌入标签名,可以通过对posts.tags字段创建多键索引来高效查询。
-
总结:
MongoDB 的文档设计是一个权衡的过程,没有一刀切的“正确”答案。最佳设计取决于具体的应用需求、数据访问模式、数据关系、性能要求和数据一致性要求。通常需要迭代的进行设计和优化。核心是理解嵌入和引用的优缺点,并根据你的应用场景做出明智的选择。