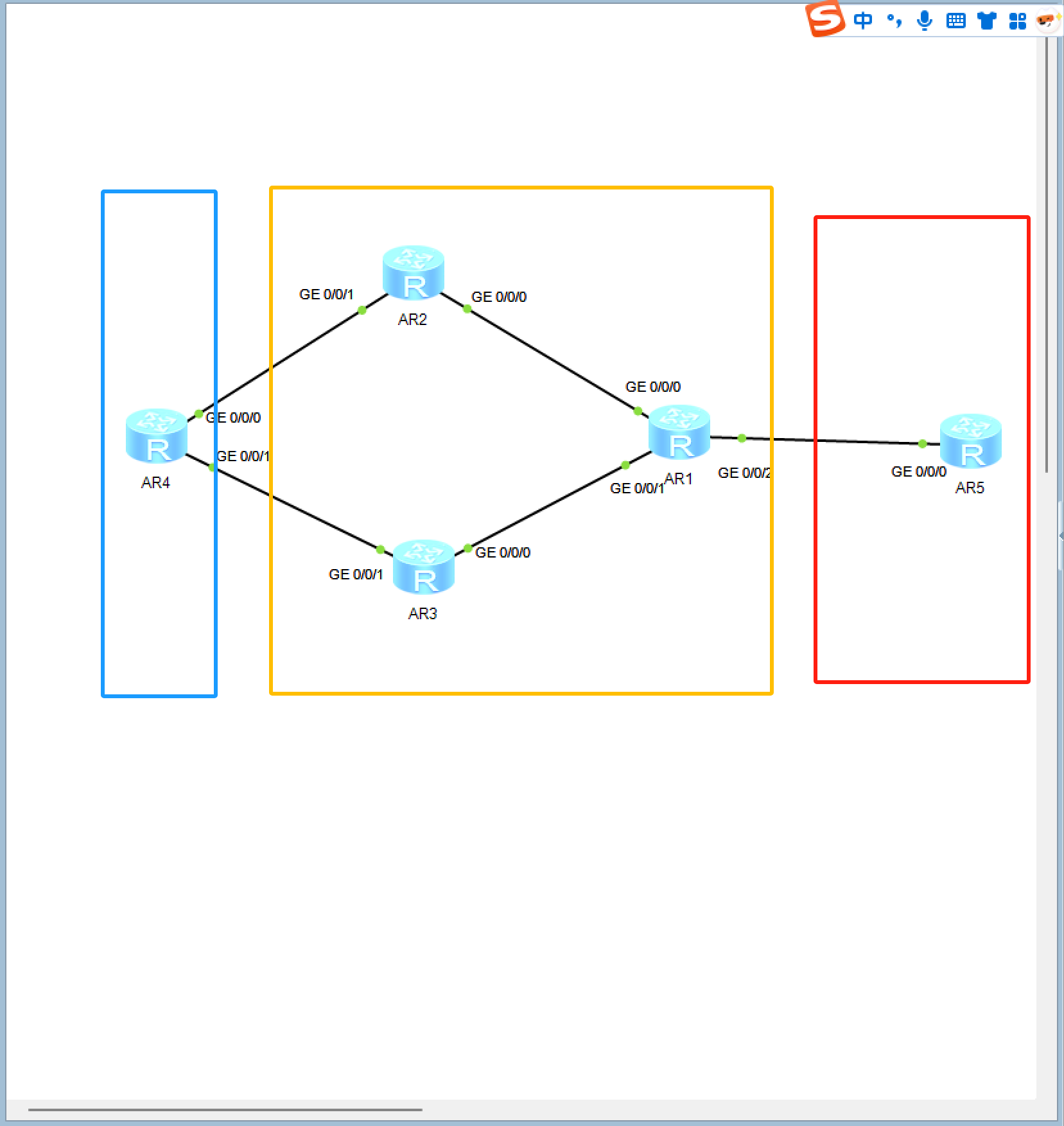
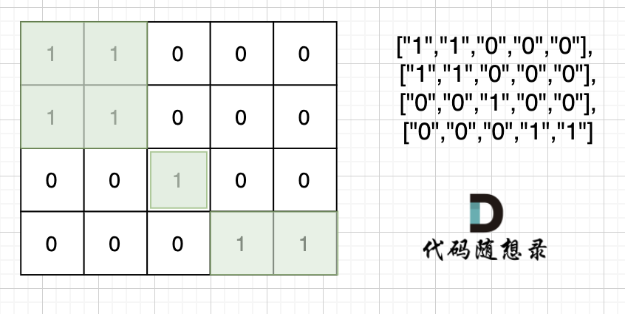
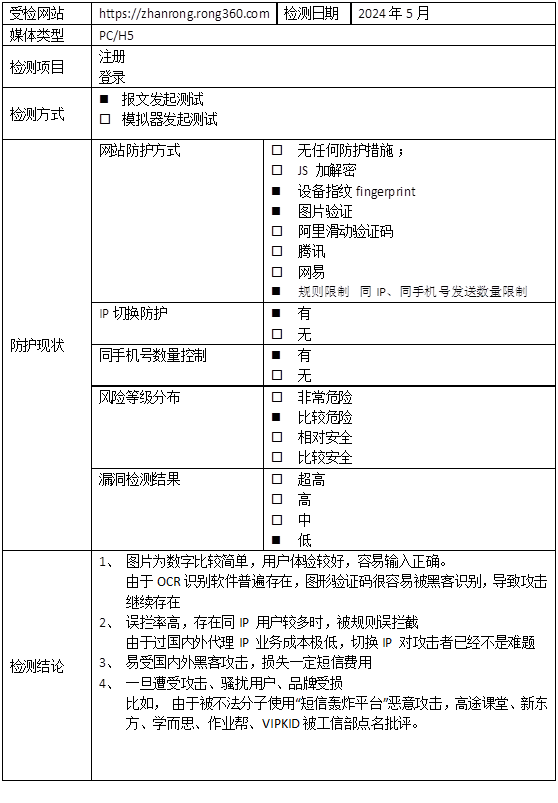
在 Elasticsearch(ES)中实现同义词映射(如“美丽”和“漂亮”),核心是通过 同义词过滤器(Synonym Token Filter) 在分词阶段将同义词扩展或替换为统一词项,从而让搜索时输入任意一个同义词都能匹配到所有相关文档。以下是分步骤的实现方案,结合 ES8 的特性说明:
一、同义词处理的核心原理
ES 的同义词处理发生在 分词(Analysis)阶段,通过自定义分析器(Analyzer)中的 同义词过滤器 将输入的文本(无论是索引文档还是搜索词)中的同义词替换或扩展为统一词项。例如:
- 索引文档时,若文档包含“美丽”,会被扩展为“美丽 漂亮”;
- 搜索时输入“漂亮”,也会被扩展为“美丽 漂亮”,从而匹配到所有包含“美丽”或“漂亮”的文档。
二、同义词配置的关键步骤
1. 定义同义词规则
同义词规则需按 ES 支持的语法编写,常见格式为:
美丽, 漂亮 => 美丽 // 替换模式:将“美丽”和“漂亮”替换为“美丽”(保留一个词项)
# 或
美丽, 漂亮 // 扩展模式:将“美丽”或“漂亮”扩展为“美丽 漂亮”(保留所有词项)
=>符号表示替换(仅保留右侧词项);无符号表示扩展(保留所有词项)。#为注释行。
2. 创建包含同义词过滤器的自定义分析器
在 ES 中,需将同义词过滤器绑定到自定义分析器,并指定该分析器用于目标字段的索引和查询。
示例(通过 ES API 创建索引并配置分析器):
PUT /my_index
{
"settings": {
"analysis": {
"filter": {
"my_synonym_filter": {
"type": "synonym", // 同义词过滤器类型
"synonyms_path": "synonyms.txt", // 同义词文件路径(支持本地文件或远程 URL)
"expand": true, // 是否扩展同义词(默认 true)
"lenient": true // 忽略解析错误(如无效规则)
}
},
"analyzer": {
"my_synonym_analyzer": {
"tokenizer": "standard", // 基础分词器(如 standard、ik_max_word 等)
"filter": [
"lowercase", // 小写转换(可选,根据业务需求)
"my_synonym_filter" // 绑定同义词过滤器
]
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "my_synonym_analyzer", // 索引时使用的分析器
"search_analyzer": "my_synonym_analyzer" // 查询时使用的分析器(可与索引分析器不同)
}
}
}
}
3. 同义词文件的存储与加载
- 本地文件:将
synonyms.txt放在 ES 节点的config目录下(如config/synonyms.txt),需确保所有节点路径一致。 - 远程文件(ES 8+ 支持):通过
synonyms_path指定 HTTP/HTTPS URL(如https://example.com/synonyms.txt),ES 会定期拉取更新(需配置update_interval):"my_synonym_filter": { "type": "synonym", "synonyms_path": "https://example.com/synonyms.txt", "update_interval": "1h" // 每小时检查一次更新 }
三、索引阶段 vs 查询阶段应用同义词
同义词过滤器可在 索引时(分析文档内容)和 查询时(分析搜索词)应用,需根据业务需求选择:
1. 索引时应用(推荐场景:文档内容固定)
- 配置:在
analyzer中绑定同义词过滤器(索引和查询均使用该分析器)。 - 效果:文档中的同义词会被预先扩展或替换,搜索时输入任意同义词均可匹配。
- 优势:查询时无需处理同义词扩展,降低查询耗时。
- 缺点:新增同义词需重新索引文档(否则旧文档无法匹配新同义词)。
2. 查询时应用(推荐场景:同义词规则频繁更新)
- 配置:仅在
search_analyzer中绑定同义词过滤器,索引时使用基础分析器。 - 效果:文档内容保持原始词项,搜索时搜索词会被扩展为同义词。
- 优势:同义词规则更新无需重新索引文档。
- 缺点:查询时需处理扩展,可能增加查询耗时(尤其当同义词数量大时)。
3. 混合应用(平衡方案)
同时在索引和查询阶段应用同义词过滤器,但需确保两者的同义词规则一致,避免索引词项与查询词项不匹配。例如:
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "my_synonym_analyzer", // 索引时扩展同义词
"search_analyzer": "my_synonym_analyzer" // 查询时再次扩展同义词
}
}
}
四、验证同义词效果
通过 ES 的 _analyze API 验证分析器是否正确处理同义词:
示例(验证“美丽”的分词结果):
GET /my_index/_analyze
{
"analyzer": "my_synonym_analyzer",
"text": "美丽"
}
预期输出(扩展模式):
{
"tokens": [
{ "token": "美丽", "start_offset": 0, "end_offset": 2 },
{ "token": "漂亮", "start_offset": 0, "end_offset": 2 } // 同义词被扩展
]
}
预期输出(替换模式):
{
"tokens": [
{ "token": "美丽", "start_offset": 0, "end_offset": 2 } // 仅保留替换后的词项
]
}
五、动态更新同义词规则
若需动态更新同义词(如新增“好看”作为“美丽”的同义词),需执行以下步骤:
1. 更新同义词文件
修改 synonyms.txt 或远程文件,添加新规则:
美丽, 漂亮, 好看 // 扩展模式:三个词互为同义词
2. 刷新分析器(ES 8+ 支持)
通过 _indices/close 和 _indices/open 重新加载分析器(需短暂关闭索引):
// 关闭索引
POST /my_index/_close
// 打开索引(自动重新加载同义词文件)
POST /my_index/_open
注意:关闭索引会导致该索引不可用,生产环境建议使用 滚动升级(Rolling Upgrade) 或 双索引切换 避免停机。
六、注意事项与优化
1. 性能影响
- 扩展模式会增加词项数量(如一个词扩展为 5 个同义词),可能导致索引体积增大和查询耗时增加。
- 替换模式可减少词项数量,但需谨慎选择基准词(如统一为“美丽”),避免丢失语义。
2. 同义词规则维护
- 避免规则冲突(如“苹果”既指水果又指品牌),可通过 上下文感知同义词(需结合
context过滤器,ES 8.7+ 支持):"my_synonym_filter": { "type": "synonym", "synonyms": [ "美丽, 漂亮 => #general", // 通用上下文 "苹果, 水果 => #fruit", // 水果上下文 "苹果, 手机 => #electronics" // 电子设备上下文 ] }
3. 中文分词器适配
- 若使用中文分词器(如 IK、SmartCN),需确保同义词过滤器在分词器之后执行(避免分词结果与同义词规则不匹配)。例如:
"analyzer": { "my_synonym_analyzer": { "tokenizer": "ik_max_word", // 中文分词器 "filter": [ "my_synonym_filter" // 分词后应用同义词过滤器 ] } }
总结
ES 中实现同义词映射的核心是通过 同义词过滤器 在分词阶段扩展或替换词项。关键步骤包括:
- 定义同义词规则(扩展或替换模式);
- 创建包含同义词过滤器的自定义分析器;
- 将分析器绑定到目标字段(索引和/或查询阶段);
- 验证分词效果并动态更新规则。
通过合理配置,可实现“美丽”和“漂亮”等同义词在搜索时的智能映射,提升搜索结果的相关性。












![交叉引用、多个参考文献插入、跨文献插入word/wps中之【插入[1-3]、连续文献】](https://i-blog.csdnimg.cn/direct/ed4784c3d08b4c4580b50bbd2730668a.png)