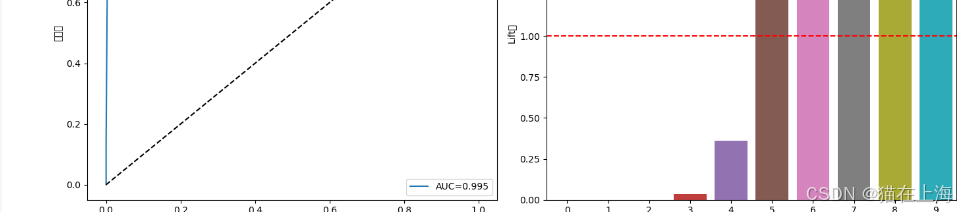
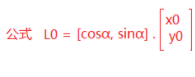引言部分
在深度学习领域,生成对抗网络(GAN)是一种强大的数据生成方法,它通过生成器(G)和判别器(D)之间的博弈来不断优化模型。然而,在实际训练过程中,GAN 往往会遇到 判别器收敛,而生成器发散 的问题,导致模型训练难以稳定进行。
这种现象的根本原因在于 GAN 的目标函数设计、训练过程中动态平衡的破坏、梯度消失与爆炸问题,以及数据分布的复杂性。判别器往往容易快速学会识别真假数据,而生成器在学习逼真数据分布时需要不断调整,容易陷入梯度问题或模式坍塌。
本文将深入分析 GAN 在训练过程中判别器收敛、生成器发散的原理,并探讨可能的解决方案,以帮助优化 GAN 的稳定性和生成质量。
1. GAN的基本原理
GAN(生成对抗网络)由两部分组成:生成器(G) 和 判别器(D)。它们就像两个对手在玩游戏:
- 生成器(G):它的任务是制造假数据,比如生成看起来像真实照片的图片。
- 判别器(D):它的任务是判断输入的数据是真实的还是假的,就像一个警察检查身份证是否是真的。
训练过程中,生成器和判别器互相竞争: - 生成器努力生成越来越逼真的假数据,试图骗过判别器。
- 判别器努力提高自己的判断能力,不被生成器骗到。
2. 为什么判别器容易收敛
判别器的任务相对简单,它只需要判断输入的数据是真实的还是假的。在训练初期,生成器生成的假数据质量很差,判别器很容易就能识别出来,比如生成器生成的图片可能只是一堆乱码,判别器很容易判断这是假的。
随着训练的进行,判别器不断学习,它的能力会越来越强,很快就能够很准确地判断出哪些是真实的,哪些是假的。这就像是一个警察,只要看到身份证上的照片和本人明显不符,就能轻易判断是假的。因此,判别器很容易就“收敛”了,也就是它的性能稳定下来,能够很好地完成任务。
3. 为什么生成器容易发散
生成器的任务要难得多,它需要从随机噪声中生成逼真的数据。在训练初期,生成器生成的假数据质量很差,判别器很容易就能识别出来。生成器会根据判别器的反馈进行调整,但它很难一下子找到生成逼真数据的方法。
随着训练的进行,如果判别器变得太强,生成器可能就会“绝望”了。比如,判别器已经能轻易判断出生成器生成的所有数据都是假的,生成器就会收到很强的负面反馈,它可能会朝着错误的方向调整,导致生成的数据越来越差,甚至完全失去方向。这就像是一个造假者,无论怎么努力,都造不出像样的假货,最后可能越造越离谱。
4. 为什么会发散
当判别器收敛后,生成器会收到很强的负面反馈,因为它生成的假数据总是被识破。这种情况下,生成器可能会朝着错误的方向调整,导致生成的数据质量越来越差,甚至完全失去方向。这就像是一个造假者,无论怎么努力,都造不出像样的假货,最后可能越造越离谱。
如何解决?
为了解决这个问题,研究人员想了很多办法:
- 调整训练节奏:让判别器和生成器交替训练,不要让判别器变得太强。
- 调整损失函数:让生成器的损失函数更加平滑,避免它朝着错误的方向调整。
- 增加正则化:限制生成器和判别器的复杂度,避免它们过于“聪明”,导致训练不稳定。
总之,GAN的训练就像一场复杂的博弈,需要精心设计和调整,才能让生成器和判别器都能稳定地进步。
请从原理上解释一下,为什么 GAN 生成对抗训练模型在实际训练中很容易判别器收敛,生成器发散。
好的!从原理上来说,GAN(生成对抗网络)在训练过程中容易出现判别器(D)收敛、生成器(G)发散的情况,主要是由于以下几个原因:
1. 目标函数的非对称性
GAN的训练目标是通过最小化生成器和判别器之间的博弈损失来实现的。具体来说:
- 判别器的目标:最大化对真实数据和假数据的区分能力,即最大化
E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \mathbb{E}_{x \sim p_{\text{data}}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log(1 - D(G(z)))] Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
这个公式是生成对抗网络(GAN)的损失函数,由两部分组成:
- 判别器对真实数据的期望对数似然
- 判别器对生成数据的期望对数似然
- 生成器的目标:
min D E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] 或 max D E z ∼ p z ( z ) [ log D ( G ( z ) ) ] \min_D \mathbb{E}_{z \sim p_z(z)}[\log(1 - D(G(z)))] \quad \text{或} \quad \max_D \mathbb{E}_{z \sim p_z(z)}[\log D(G(z))] DminEz∼pz(z)[log(1−D(G(z)))]或DmaxEz∼pz(z)[logD(G(z))]
这两个公式描述了生成对抗网络(GAN)训练过程中判别器的优化目标:
- 最小化对生成样本的判别概率的对数似然
- 最大化对生成样本的判别概率的对数似然
两者在数学上是等价的,但后者在训练初期具有更好的梯度性质。
这种目标函数的设计导致了两者的优化过程是非对称的:
- 判别器的优化目标:判别器的优化目标是清晰的,它只需要尽可能区分真实数据和生成数据。只要判别器能够准确地判断输入数据的真假,它的目标就达到了。
- 生成器的优化目标:生成器的目标相对复杂,它需要生成的数据不仅要在判别器看来是真实的,还要在分布上接近真实数据的分布。生成器需要不断调整自身参数,以生成越来越逼真的数据,但这个过程很容易出现偏差。
2. 训练过程中的动态平衡问题
GAN的训练过程是一个动态的博弈过程,生成器和判别器需要相互配合、相互制约。然而,这种动态平衡很容易被打破:
- 判别器过强:如果判别器的训练速度过快,或者其模型容量过大,它可能会变得过于强大,能够轻易地识别出生成器生成的所有假数据。此时,生成器会收到强烈的负面反馈,导致其梯度消失或梯度爆炸,从而无法有效更新参数,最终导致发散。
- 生成器滞后:如果生成器的训练速度跟不上判别器,生成器生成的数据质量始终无法达到判别器的要求,判别器会一直处于优势地位,进一步加剧生成器的优化困难。
3. 损失函数的性质
GAN的损失函数本质上是一个非凸优化问题,并且生成器和判别器的优化是交替进行的。这种交替优化方式导致了以下几个问题:
- 梯度消失:当判别器过于强大时,生成器生成的数据被判别器轻易识别为假数据,此时生成器的损失函数梯度可能变得非常小,导致生成器的参数更新缓慢甚至停滞。
- 梯度爆炸:在某些情况下,生成器的损失函数梯度可能变得非常大,导致生成器的参数更新幅度过大,从而破坏了生成器的稳定性和生成质量。
4. 模型容量和复杂度的不匹配
在实际训练中,生成器和判别器的模型容量(如层数、神经元数量等)往往不匹配:
- 判别器容量过大:如果判别器的模型容量远大于生成器,判别器会更容易学习到复杂的特征,从而更轻易地识别出生成器的假数据。这会导致生成器的优化更加困难。
- 生成器容量不足:如果生成器的模型容量不足,它可能无法生成足够复杂和逼真的数据,从而无法有效欺骗判别器。
5. 数据分布的复杂性
GAN的目标是让生成器生成的数据分布尽可能接近真实数据分布。然而,真实数据分布往往是复杂且难以建模的。生成器在训练过程中需要不断调整自身参数,以生成越来越接近真实分布的数据,但这个过程很容易出现偏差:
- 模式坍塌(Mode Collapse):生成器可能只学习到真实数据分布中的某些模式,而忽略了其他模式。例如,生成器可能只生成某几种类型的图像,而无法生成真实数据分布中的所有类型。这会导致生成器生成的数据多样性不足。
- 分布不匹配:即使生成器生成的数据在判别器看来是真实的,但其分布可能仍然与真实数据分布存在较大差异。这种分布不匹配会导致生成器的优化方向偏离目标。
解决方法
为了解决判别器收敛、生成器发散的问题,研究人员提出了许多改进方法:
- 调整训练策略:
- 交替训练:合理控制生成器和判别器的训练步数,避免判别器过于强大。
- 平滑目标:在训练判别器时,使用平滑的目标值(如将真实数据的目标值设为0.9,假数据的目标值设为0.1),避免判别器过于自信。
- 改进损失函数:
- Wasserstein GAN(WGAN):使用Wasserstein距离代替传统的JS散度,使损失函数更加平滑,减少梯度消失和梯度爆炸的问题。
- 最小二乘GAN(LSGAN):使用最小二乘损失函数,使生成器的优化过程更加稳定。
- 正则化技术:
- 梯度惩罚:对判别器的梯度进行惩罚,限制其梯度的大小,避免判别器过于强大。
- 谱归一化:对判别器的权重进行归一化,限制其谱范数,提高训练的稳定性。
- 模型架构设计:
- 合理设计生成器和判别器的模型容量:确保生成器和判别器的模型容量相匹配,避免一方过于强大。
- 引入残差连接:在生成器和判别器中引入残差连接,增强模型的训练稳定性。
总结
GAN在训练过程中容易出现判别器收敛、生成器发散的问题,主要是由于目标函数的非对称性、训练过程中的动态平衡问题、损失函数的性质、模型容量和复杂度的不匹配以及数据分布的复杂性等因素共同导致的。通过调整训练策略、改进损失函数、应用正则化技术以及合理设计模型架构,可以在一定程度上缓解这些问题,提高GAN的训练稳定性和生成质量。