Text2SQL技术
早期阶段:依赖于人工编写的规则模板来匹配自然语言和SQL语句之间的对应关系
机器学习阶段:采用序列到序列模型等机器学习方法来学习自然语言与SQL之间的关系
LLM阶段:借助LLM强大的语言理解和代码生成能力,利用提示工程,微调等方法将Text2SQL性能提升到新的高度
我们目前已处于LLM阶段,基于LLM 的 Text-to-saL系统会包含以下几个步骤
自然语言理解:分析用户输入的自然语言问题,理解其意图和语义。
模式链接: 将问题中的实体与数据库模式中的表和列进行链接。
SQL生成:根据理解的语义和模式链接结果,生成相应的 SQL查询语句。
SQL执行:在数据库上执行SQL查询,将结果返回给用户,(function call)
LLM模型选择
闭源模型,收费且数据上传服务器

开源模型:

Qwen72B开源天花板,但贵,会用7B比较多
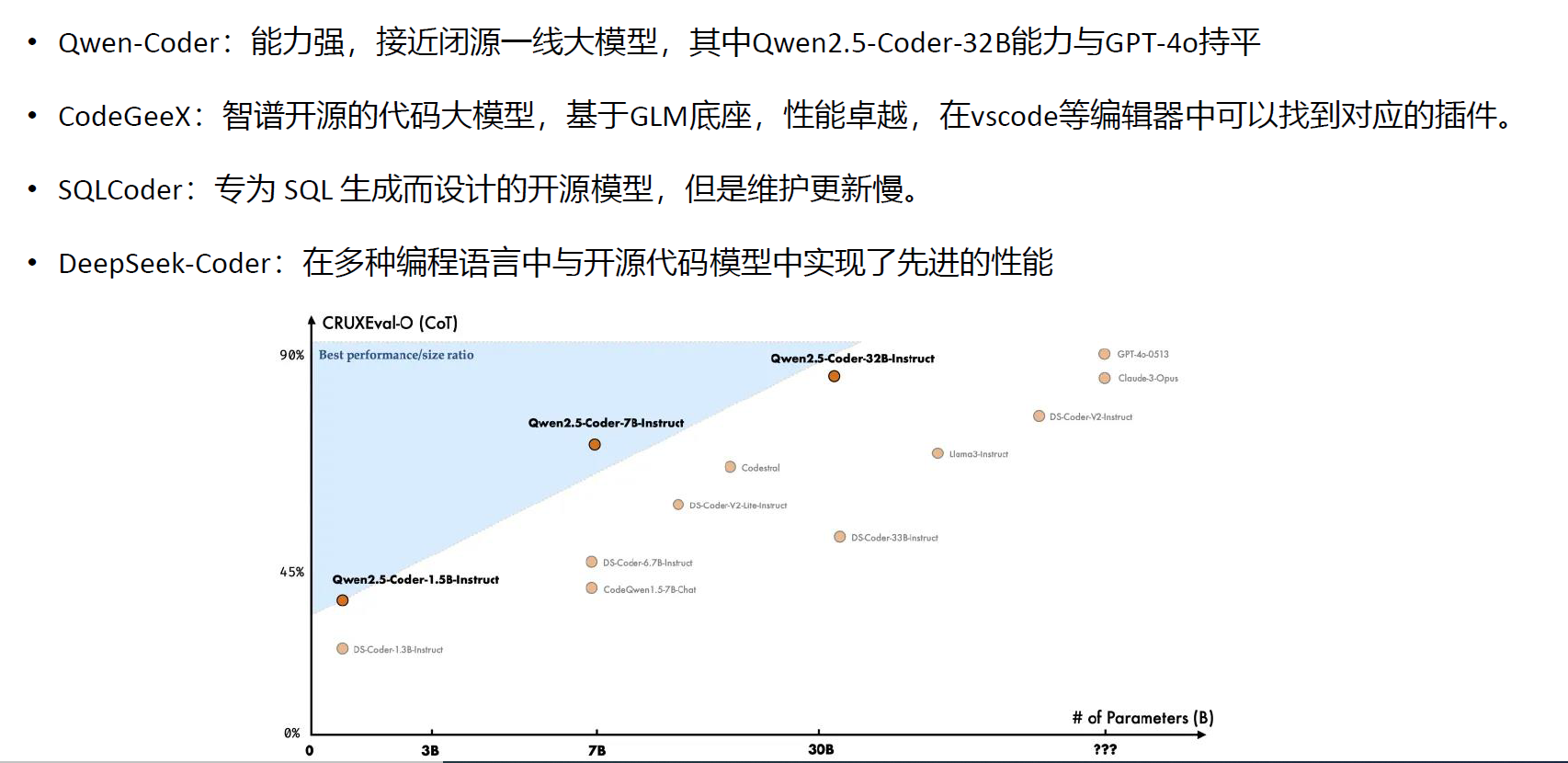
横向是参数,纵向是性能,性价比看斜率
写代码Qwen-coder,CodeGeex
Function Call-->SQL执行
搭建SQL Copilot

LangChain中的SQL Agent
SQL Agent如何通过自然语言,撰写SQL
1)通过 sql_db_list_tables,看到数据库中的表都有哪些
2)思考,我需要查哪张表(基于用户的Query)
3)Action: sql_db_schema
找到对应数据表的 表结构(CREATE TABLE)
4)基于表结构,和用户的Query =>撰写SQL语句
5)执行SQL =>得到SQL执行后的结果
6)再思考是否能回答用户的问题
Thinking:如果表特别多的情况下,不可能把所有表结构传入大模型吧
是的,如果有10万张表,光是10万张表名,大模型都看不过来;
助手是分业务场景的,每个业务场景的表的数量就不会太多,分而治之。
Thinking:可不可以用知识库来限定使用的表结构?
一般知识库适用于保存之前查询问题的SQL语句的
Query =>SQL之间的问答对;
RAG的作用是给LLM提供开卷考试;
LLM的考试:用户给你Query,你写SQL
Thinking:如何处理自然语言中隐含的多层逻辑(如嵌套子查询,多条件连接),以此生成复杂的SQL,有什么技巧?
LLM写复杂的SQL,一般处理3张表联查是没有问题;
我们可能会有一些规则,或者存在多个使用字段表达同一个意思***
1)COMMENTS,注释
2)向量数据库,存储着过去的Query => SQL(对的答案)
Thinking:拿到数据库数据后如何保证后续的生成不影响数字的准确?
SQL执行后,得到dataframe,LLM会基于dataframe进行后续的推理
Thinking:如果SQL一直不正确,可否人工写个准确的SQL给大模型,并与问题关联,这里就可以用向量数据库
自己编写(LLM+Prompt)
Thinking:直接使用SQL+LLM会有什么问题?
1)多个相似的数据表 =>导致Langchain会尝试多次生成SQL
2)用户Prompt太宽泛 =>生成的结果,不是用户想要的
所以得给Agent配备专有的知识库,在prompt中动态完善和query相关的context
SQL+向量数据库+LLM:
向量数据库可以提供领域知识,当用户检索某个问题的时候=>从向量数据库中找到相关的内容,放到prompt中=>提升SQL查询的相关性,保留以前的答案
RAG技术(Retrieval Augmented Generational)
在prompt中增加few-shot examples
专门定制搜索工具,从向量数据库中检索到与用户query相近的知识
SQL + 向量数据库+ LLM 使用:
如果想让LLM使用tool(可以按照某个顺序,执行完这个再执行下一个),比较有效的方式是写在prompt中,而不是在tool description中进行定义
向量数据库的作用:
给Prompt提供更多的context,用于LLM进行决策
CASE:保险场景SQL Copilot实战

Qwen2.5 7B或者72B CodeGeex

在这三种写法中,写法3可能是最好的,原因如下:
1. 结构清晰
写法3采用了一种正式的模板格式,将问题、输入和响应明确分开,使整个提示的逻辑非常清晰:
-
Question:明确指出了用户的问题。 -
Input:提供了数据表的建表语句(create_sql),这对于理解表结构和字段非常重要。 -
Response:清晰地指出了生成的 SQL 语句的位置。
这种结构化的方式可以帮助模型更好地理解任务需求,减少歧义。
2. 信息完整
写法3包含了以下关键信息:
-
问题描述:明确指出了用户需要解决的问题。
-
输入数据:提供了数据表的建表语句,帮助模型理解数据结构。
-
输出格式:指定了生成的 SQL 语句的位置和格式。
这种完整性使得模型能够更全面地理解任务,从而生成更准确的 SQL 查询。
3. 易于扩展
写法3的模板化设计使得它非常易于扩展。如果需要增加更多的信息或步骤,可以在模板中轻松添加新的部分。例如,如果需要增加对数据表的中文描述或其他约束条件,可以很方便地整合到模板中。
4. 可读性高
写法3的格式非常清晰,易于阅读和维护。无论对于开发人员还是模型来说,都能快速理解提示的内容和结构。
5. 减少歧义
由于写法3明确了每个部分的内容和格式,减少了模型对提示的误解。相比之下,写法1和写法2虽然也能传递必要的信息,但结构上不如写法3清晰,容易导致模型在理解上出现偏差。
对比其他写法
-
写法1:
-
优点:简洁,直接在提示中包含表描述。
-
缺点:缺乏结构化,模型可能难以快速定位关键信息。
-
-
写法2:
-
优点:使用了注释,提供了一定的结构。
-
缺点:信息组织不够清晰,模型可能需要更多时间来解析提示。
-
总结
写法3通过其清晰的结构、完整的信和高可读性,能够更有效地引导模型生成准确的 SQL 查询。这种模板化的方法不仅提高了生成结果的质量,还便于维护和扩展,因此在实际应用中可能表现最佳。

补全代码能力
Thinking:text2SQL,数据保护问题是不是解决不了,生产环境有落地吗?
在生产环境中,可以用开源模型,比如Qwen2.5-Coder
可以用云端数据库,也可以自己电脑本地搭建数据库
Thinking:如何想知道哪个大模型,用哪种格式会效果更好
开源大模型:
Qwen2.5-Coder ***,CodeGeex,SQLCoder =>代码补全大模型
prompt = f"""-- language: SQL
### Question: {query}
### Input: {create sql}
### Response:
Here is the SQL query l have generated to answer the question `{query}:
```sql
''''''
导出建表语句,创建SQL数据表的SQL语句
查询SQL数据,机器学习的建模=>Function Call,让LLM调用Function Call来执行特定的任务。
助手的结构设计:
1)为什么要划分很多助手?
因为用户的需求是多样的,数据表是多样的,Function Call也是多样的;
LLM直接来判断,选择哪个数据表,哪个FunctionCall =>比较困难,容易出错
所以划分不同的助手,每个助手有自己的业务场景(职责),也有自己匹配的数据
表,和Function cal。这样执行起来更清晰
2)能否打造一个 all in one 助手
Step1,先打造多个助手,比如100个
Step2,all in one 助手 =>先判断调用哪个助手
相当于是一个分诊台;
query input =>给到特定的助手;
Vanna使用
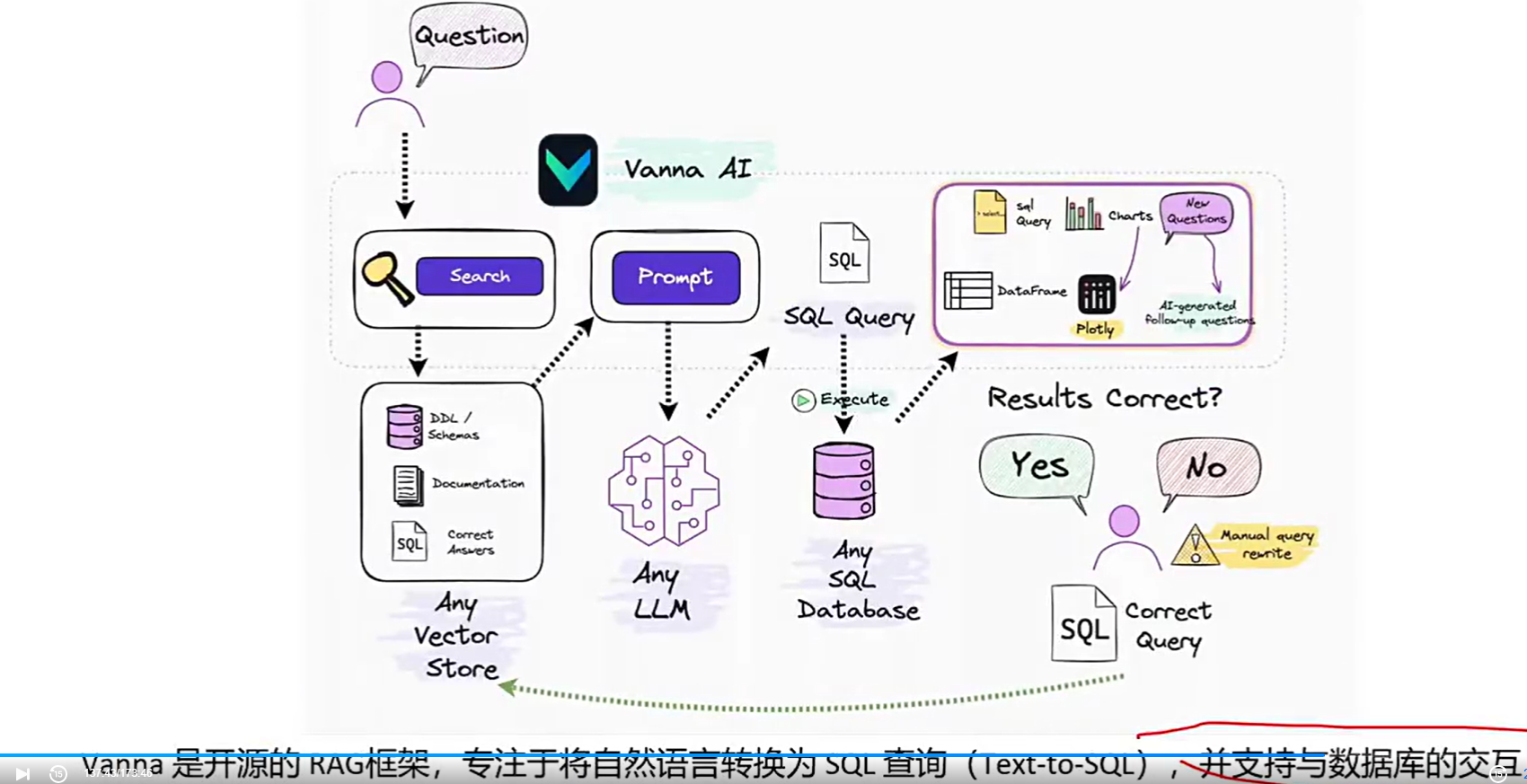

Vanna工作原理:
---训练RAG模型
输入数据库的元数据(如INFORMATION_SCHEMA),DDL语句,文档或示例SQL
模型将这些信息转换为向量并存储到向量库中,用于后续检索
---生成SQL
用户提问时,系统从向量库中检索相关上下文,组装成Prompt发送给LLM
LLM生成SQL后,自动执行并返回结果(表格或图标)
Vanna使用步骤:
vanna安装
pip install vanna,可选扩展如vanna[chromadb,mysql]支持本地化部署
连接数据库
自定义run_sql方法(如MySQL需要通过mysql.connector返回Pandas DataFrame)
训练模型
通过DDL,文档或SQL示例训练,例如:
vn.train(ddl="CREATE TABLE users(id INT PRIMARY KEY,name VARCHAR(100))")
提问与查询
调用vn.ask("查询销售额最高产品"),生成并执行SQL
ask函数
作用:用户通过自然语言提问时调用此函数,它是查询的核心入口,会依次调用generate_sql、run_sq1、generate_plotly_code、get_plotly_figure四个函数来完成整个查询及可视化的过程。
工作流程:
-->首先将用户的问题转换成向量表示,然后在向量数据库中检索与问题语义最相似的DDL语句、文档和SQL查询。
-->将检索到的信息和用户的问题一起提供给LLM,生成对应的SaL查询。
-->执行生成的SQL查询,并将查询结果以表格和Plotly图表的形式返回给用户,
比如:vn.ask("查询heros表中 英雄攻击力前5名的英雄")
generate sql函数
作用:根据用户输入的自然语言问题,生成对应的SQL语句。
工作流程:
调用get_similar_question_sql函数,在向量数据库中检索与问题相似的sql/question对。
在向量数据库中检索与问题相似的建表语句ddl。
调用get related ddl函数,
调用get related documentation函数,在向量数据库中检索与问题相似的文档
调用get_sql_prompt函数,结合上述检索到的信息生成prompt,然后将prompt提供给LLM,生成SQL语句。
比如:sql=vn.generate_sql("査询heros表中 英雄攻击力前5名的英雄")
run_sql函数
作用:执行generate_sql函数生成的SQL语句,并返回查询结果
工作流程:将生成的SQL语句发送到连接的数据库中执行,获取并返回查询结果。
比如:
sql=vn.generate_sql("査询heros表中 英雄攻击力前5名的英雄")
vn.run sql(sql)
=========================================================================
结构化数据库 SQL,非结构化数据库 NoSQL
SQL数据库 更有前景;oracle,mysql
AI大模型的项目,要处理数据,哪种数据更有价值,更容易看到结果?
RAG 处理很多非结构化的数据,难点在什么 =>数据清洗
结构化数据的 Text2SQL,更容易看到一些结果
3种搭建Text2SQL的能力:
1)LangChain
2)Vanna
3)开源的大模型 Code大模型的使用+prompt
Thinking:缺乏含义的话,在字段的备注里面加说明
1)字段的注释
2)有时候,还需要提供一些字段值,尤其是针对分类的字段
gender = male
gender ='男’
不光是建表语句需要给到 LLM,针对提问的分类字段,也需要给到大模型
Thinking:能介绍一些非结构化的数据清洗的比较好的方法吗?
工具:使用LLM来进行数据清洗
非结构化数据 常见的问题是什么?
1)文件过时
2)标注,文档的注释(摘要、关键词、提一些文档知识的问题)
提升RAG的能力
摘要 =>LLM写摘要
关键词 =>LLM写关键词抽取
给文档知识提一些问题=>LLM写知识问题
机器学习的建模:
1)写代码,可以用Cursor
2)需要了解都有哪些机器学习模型,能做什么
LR线性回归,对特征的重要性进行计算
w1x1+w2x2+w3x3 = y
x1,x2,x3=>年卡人数,促销人数,普通人数
Thinking:机器学习建模这种是不是只有获取不到底层的时候才适用?除此之外在text2SQL中还有什么应用场景?
时间序列=>预测未来一段时间的y
d1,d2,d3,d4...dn,dn+1
![[Mac] 开发环境部署工具ServBay 1.12.2](https://i-blog.csdnimg.cn/direct/9fe237104c584807b408678d28323340.png)