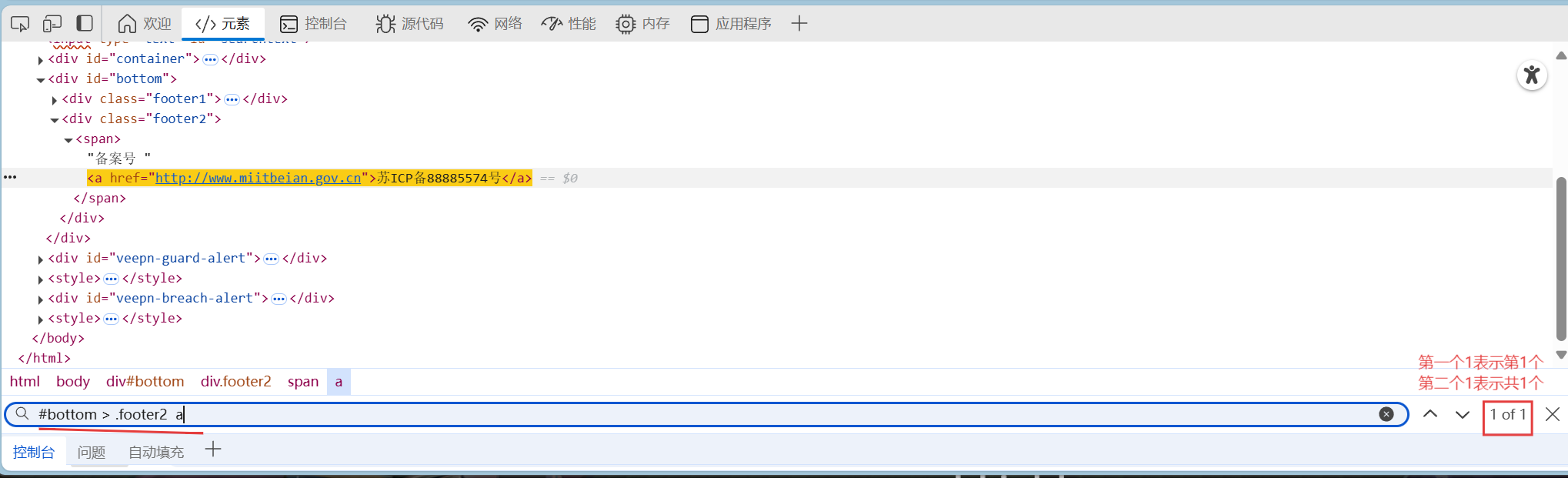
文章目录
- 智能体的4大要素
- 一些上手的例子与思考。
- 创建简单的AI agent.
- 从本地读取文件,然后让AI智能体总结。
- 也可以自己定义一些工具 来完成一些特定的任务。
- 我们可以使用智能体总结一个视频。用户可以随意问关于视频的问题。
智能体的4大要素
AI 智能体有以下几个重要的要素:
1 规划: AI agent 需要拥有规划和决策能力,规划能力通常包括 目标分解,思维链(连续的进行思考), 自我的反思,以及对过去的反思。
2. 记忆: 包含长期记忆和短期记忆
3. 能使用工具:使用外部的工具来辅助完成更加复杂的任务。可以理解成是扩大了智能体的知识范围,因为训练好的大模型的知识是固定的,相对难以直接扩展。
4. 执行:通过以上提到来执行任务。
一些上手的例子与思考。
创建简单的AI agent.
使用lang chain创建一个AI 智能体是相对简单的。只需要调用一些开放接口就可以了。一般是使用OpenAI 的接口相对方便一点,但是因为所有的OpenAI 接口都要收费,所以这里我是用的是google的gemini.
一个基础的智能体,应该有向外获取信息的能力。 所以出了将大模型作为智能体的大脑外,还需要定义一些基础的工具让他使用。我使用奴serpapi的作为智能体的搜索工具,这个工具可以免费使用100次/月。 首先是获取大模型gemini,和serpapi的接口的密钥,并将它写入本地的.env文件中。之后只用dotenv.load进行读取就好,这样做的好处是直接将密钥显式的写入代码中。 然后就可以直接构建一个llm
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain_google_genai import ChatGoogleGenerativeAI
#创建一个gemini-1.5模型
llm = ChatGoogleGenerativeAI(model='gemini-1.5-flash-001')
这就可以让我们直接使用gemini了,如果想要直接使用的话可以:
result = llm.invoke("从文化的角度评价一下印度")
以下是只用大模型的输出结果。从一些固定的角度去评价印度。
 但是我们要创建智能体,需要大脑(大模型)还有工具联系到一起,并且定义智能体的推理框架,
但是我们要创建智能体,需要大脑(大模型)还有工具联系到一起,并且定义智能体的推理框架,
#定义工具
tools = load_tools(['serpapi'])
#初始化智能体
agent = initialize_agent(tools,llm,agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
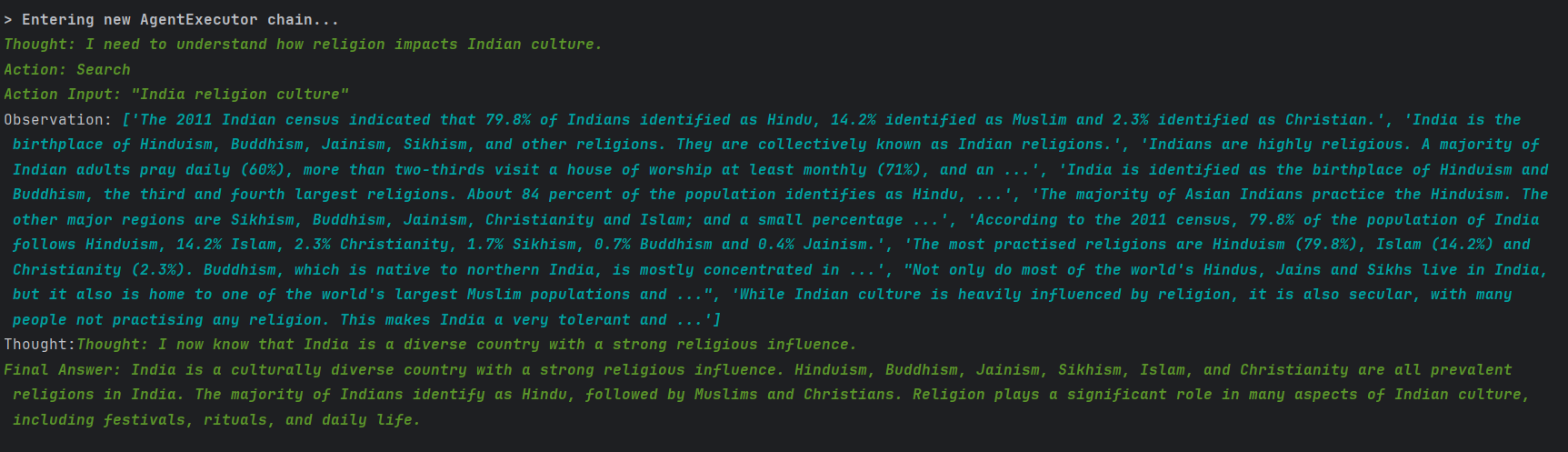
推理框架(AgentType)选择ReACT, 他是一种知道大模型推理和行动的认知框架。基本上就是有三个主要步骤,思考,行动,观察。比如我们用这个最简单的智能体去从文化角度评价一下印度,它的输出会比只用大模型更加的全面。
从本地读取文件,然后让AI智能体总结。
这个案例主要是讲解如何使用 智能体做一个总结工具。在langchain 框架中,有很多不同的现成的chain工具。 可以把每一个chain理解成是一个任务。我们可以直接使用summarize_chain来完成本地文档的总结。但是需要注意的点有两个。 首先如果文档过长可能会超过大模型的token_size限制。所以一般将很长的文档打散成多个chunk,然后根据不同的chain_type进行总结。
from langchain.document_loaders import UnstructuredFileLoader
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
from langchain_google_genai import ChatGoogleGenerativeAI
import os
class LoadFiles():
def __init__(self,path):
self.path = path
self.loader = UnstructuredFileLoader(self.path)
self.splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=2)
self.llm = ChatGoogleGenerativeAI(model='gemini-1.5-flash-001')
def get_documents(self):
return self.loader.load()
def spilit_files(self):
documents = self.get_documents()
print('split_text:{}'.format(len(self.splitter.split_documents(documents))))
return self.splitter.split_documents(documents)
def __call__(self, *args, **kwargs):
chain = load_summarize_chain(self.llm,chain_type='refine',verbose=True)
chain.run(self.spilit_files()[:5])
if __name__ == '__main__':
load_dotenv()
path = '3D-decoupling.pdf'
summerzier = LoadFiles(path)
summerzier()
需要记录的点是 RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=2)的overlap参数是指每个chunk的重叠程度。当chunk=0时说明每个chunk之间是没有重叠的。重叠chunk在一定程度上可以增加chunk之间的关联性。还有就是 在创建load_summarize_chain中的chain_type有多种种类,代码中的refine 就是深度学习中的残差概念,将第n个文本块总结出来的内容和第n+1个文本块同时输入到大模型中经行总结。
除此之外,stuff 就是将所有的文件一次性塞入模型,map_reduce是先将每一个chunk先做一个初步的总结,然后将所有的总结内容再总结一次。 map_rerank是将总结的文件做一个置信度排名。 比较适合从多个文档中找到最相关的答案。
也可以自己定义一些工具 来完成一些特定的任务。
这个相对比较的简单,只需要使用tool类,来定义工具,然后将它在初始化agent的时候当作参数传入就行了。我们只需要先定义好工具的示例然后当作Tool类的参数传入即可。
def tools(self):
tool = [Tool(
name = 'searcher',
func= self.searcher.run,
description= 'searcher',
),
Tool(
name= 'calculator',
func= self.calculator.run,
description= 'calculator',
)
]
return tool
然后初始化智能体即可。
def ini_agent(self):
self.agent = initialize_agent(tools=self.tools,llm=self.llm,agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,verbose=True)
def __call__(self, *args, **kwargs):
self.ini_agent()
self.agent.run(kwargs['message'])
我们可以使用智能体总结一个视频。用户可以随意问关于视频的问题。
首先因为我们需要连续的问智能体关于视频的问题。 我们希望智能体能以一种相对固定的格式返回答案,所以我们先需要设定一个回答的模板。
def meg_template(self):
system_template = """
Use the following context to answer the user's question.
If you don't know the answer, say you don't, don't try to make it up. And answer in Chinese.
-----------
{question}
-----------
{chat_history}
"""
messages = [
SystemMessagePromptTemplate.from_template(system_template),
HumanMessagePromptTemplate.from_template('{question}')
]
prompt = ChatPromptTemplate.from_messages(messages)
return prompt
接下来,我们需要获取视频的内容,并将它存到一个数据库中,来确保访问。 首先需要先读取一个视频,这里使用油管上的一个随便的视频,这里使用一个youtubeLoader.
self.loader = YoutubeLoader.from_youtube_url(video_url)
获取到视频内容之后,我们需要将这些内容进行向量化,然后存入 Chroma中。 这里有一点需要注意,因为我们需要用到OpenAI的Embedding,但是这个也是需要收费的。所以我用了sentence_transformer来输出embedding. 只需要做一个简单的包装重写 embed_query 和embed_documents两个类函数即可.
class My_embedding():
def __init__(self):
self.model = SentenceTransformer('all-MiniLM-L6-v2')
def embed_query(self,documents):
texts = [doc for doc in documents]
return self.model.encode(texts, show_progress_bar=False)[0]
def embed_documents(self,documents):
texts = [doc for doc in documents]
return self.model.encode(texts, show_progress_bar=False).tolist()
之后, 我们将数据存入数据库中:
self.vector_store = Chroma.from_documents(self.data_spilt(),self.embedding_model)
self.retriever = self.vector_store.as_retriever()
然后我们使用RetrievalChain去构建这个智能体.
def __call__(self, *args, **kwargs):
self.data_spilt()
self.store_and_retrive()
prompt = self.meg_template()
qa = ConversationalRetrievalChain.from_llm(self.llm, self.retriever,
condense_question_prompt=prompt)
chat_history = []
while True:
question = input('问题:')
# 开始发送问题 chat_history 为必须参数,用于存储对话历史
result = qa({'question': question, 'chat_history': chat_history})
chat_history.append((question, result['answer']))
print(result['answer'])