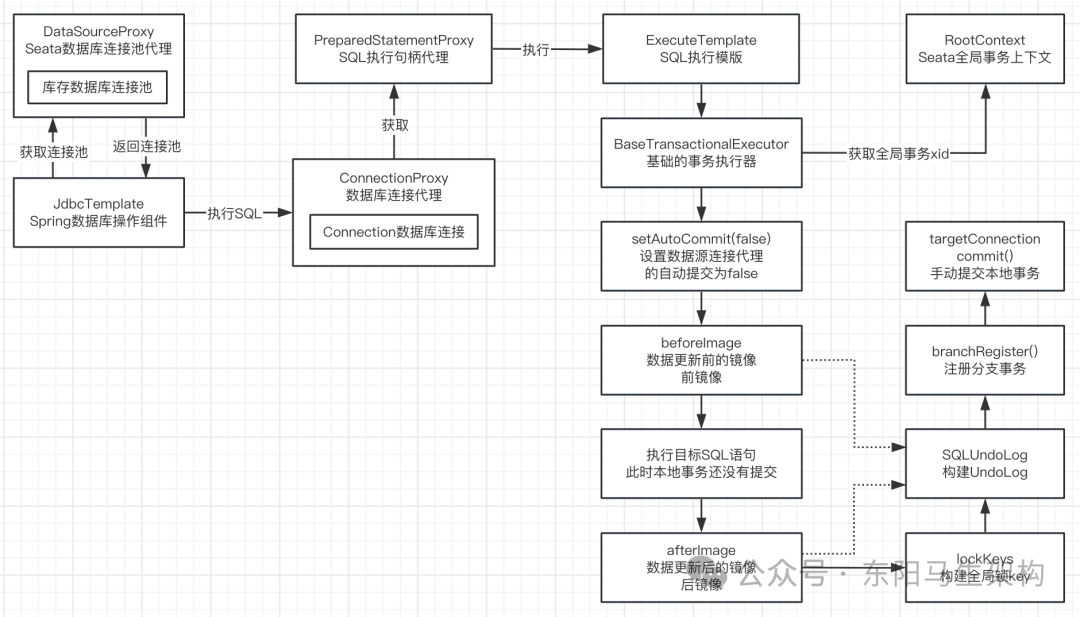
Apache Flink 的 作业提交流程(Job Submission Process) 是指从用户编写完 Flink 应用程序,到最终在 Flink 集群上运行并执行任务的整个过程。它涉及多个组件之间的交互,包括客户端、JobManager、TaskManager 和 ResourceManager。
[Client] → 提交 JobGraph
↓
[JobManager / Dispatcher] → 调度与资源申请
↓
[ResourceManager] → 分配 TaskManager Slot
↓
[TaskManager] → 启动 Task 并执行 Subtask
↓
[JobManager] → 协调任务状态、检查点等
步骤 描述 1. 用户编写代码 使用 DataStream API 或 SQL 编写 Flink 作业 2. 构建 StreamGraph 客户端将逻辑流转换为 StreamGraph(DAG) 3. 转换为 JobGraph 将 StreamGraph 转换为 JobGraph,包含算子链、并行度等信息 4. 提交 JobGraph 到集群 通过 CLI、REST API 或 Web UI 提交到 Flink 集群 5. JobManager 接收并初始化 创建 ExecutionGraph,管理任务调度 6. ResourceManager 分配资源 根据资源需求向 TaskManager 申请 Slot 7. TaskManager 启动任务 在分配的 Slot 上启动 Task,并开始执行 Subtask 8. 执行计算任务 持续处理数据流,进行状态更新和窗口计算 9. 状态管理与容错 Checkpoint/Savepoint 机制保障状态一致性 10. 结果输出或写入外部系统 输出到 Sink(如 Kafka、HDFS、MySQL 等)
组件 职责 Client 提交作业、打包 JAR、生成 JobGraph JobManager 负责任务调度、协调 Checkpoint、维护 ExecutionGraph Dispatcher 接收作业提交请求,负责创建 JobManager ResourceManager 管理 TaskManager 的 Slot 资源,分配资源给 JobManager TaskManager 执行具体的 Task,每个 Task 包含一个或多个 Subtask ExecutionGraph JobManager 内部的执行图,用于调度 Subtask Checkpoint Coordinator 协调 Checkpoint,确保状态一致性
方式 描述 命令示例 CLI 提交 最常用方式,适合本地测试和生产部署 flink run -c com.example.MyJob ./myjob.jarWeb UI 提交 图形化界面上传 JAR 文件并运行 http://localhost:8081 REST API 提交 适用于自动化部署、平台集成 POST /jars/{jarid}/runYARN Session 模式 多个作业共享一个 YARN ApplicationMaster yarn session -n 2 -tm 2048Application 模式 每个作业单独启动一个 ApplicationMaster flink run-application -t yarn-application ./myjob.jarKubernetes Native 模式 在 Kubernetes 上直接部署 Flink 作业 使用 Operator 或 Native 部署模式
编译并打包 Flink 作业为 JAR 文件 使用 flink run 命令提交作业 生成 JobGraph 并发送至 JobManager flink run -m yarn-cluster -p 4 -c com.example.WordCount ./wordcount.jar
接收 Client 提交的 JobGraph 创建 ExecutionGraph,描述任务执行计划 请求 ResourceManager 分配资源 根据 JobManager 请求,向 TaskManager 申请 Slot 协调资源分配,保证资源公平使用 收到 Slot 分配通知后,准备执行环境 加载 JAR 文件,启动 Subtask 向 JobManager 报告执行状态 JobManager 监控所有 Task 的执行情况 触发 Checkpoint,维护状态一致性 处理失败重试、反压监控等 名称 描述 特点 StreamGraph 用户编写的 DAG 流程 包含 operator chain 优化后的逻辑图 JobGraph 提交到集群的任务图 包含 operator chains、slot sharing group 等元数据 ExecutionGraph JobManager 内部运行图 包含实际执行的 Subtask 及其依赖关系
JobManager 定期触发 CheckpointTaskManager 将状态快照写入配置的 Checkpoint 存储路径(如 HDFS)JobManager 收集所有 Task 的 Checkpoint 成功信号如果发生故障,从最近成功的 Checkpoint 恢复状态
flink run-application -t yarn-application \
-Djobmanager.memory.process.size= 1024mb \
-Dtaskmanager.memory.process.size= 2048mb \
-Dparallelism.default= 4 \
./my-flink-job.jar
flink run -m yarn-cluster -p 4 -c com.example.MyJob ./myjob.jar
概念 描述 Operator Chaining 算子链合并,减少网络传输开销 Slot Sharing Group 同一组内的算子可共享同一个 Slot Parallelism 设置每个算子的并发数 Checkpoints 用于状态一致性和容错机制 Savepoints 手动触发的状态快照,用于升级、迁移等 Backpressure 当下游处理速度慢于上游时产生的压力反馈机制
阶段 描述 1. 客户端构建 将用户代码转换为 StreamGraph → JobGraph 2. 提交作业 Client 提交到 JobManager 3. 资源调度 ResourceManager 分配 TaskManager Slot 4. 任务执行 TaskManager 启动 Subtask 并执行逻辑 5. 状态管理 Checkpointing 保障状态一致性 6. 故障恢复 重启失败任务并从 Checkpoint 恢复
如果你希望我为你演示以下内容,请继续提问:
Flink on YARN 提交流程详解 Flink on Kubernetes 提交原理 自定义 Checkpoint 存储路径 Savepoint 的使用与恢复 ExecutionGraph 的结构与作用 如何查看 Web UI 中的 ExecutionGraph 作业失败时的恢复机制详解 📌 一句话总结:
Flink 作业提交流程是一个多组件协作的过程,核心是 JobGraph 的构建与 ExecutionGraph 的执行,结合 Checkpoint 实现高可用与状态一致性。