飞书文档![]() https://x509p6c8to.feishu.cn/wiki/FfpIwIPtviMMb4kAn3Sc40ABnUh
https://x509p6c8to.feishu.cn/wiki/FfpIwIPtviMMb4kAn3Sc40ABnUh
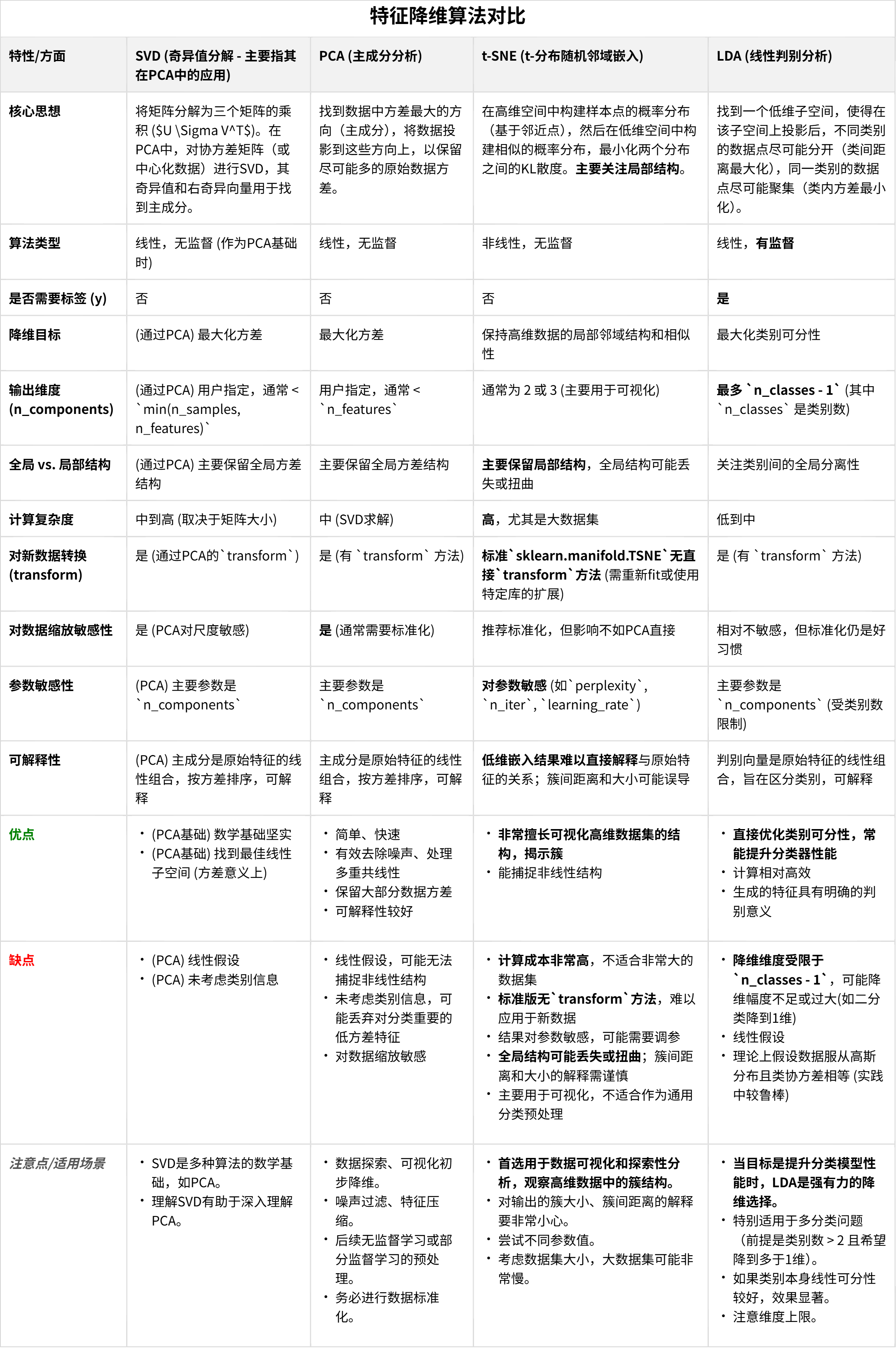
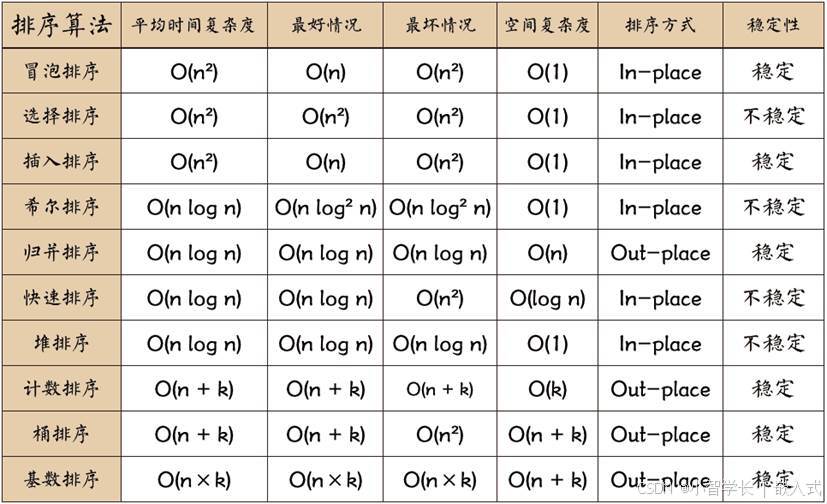
常用排序算法
这几种算法都是常见的排序算法,它们的优劣和适用场景如下:
冒泡排序(Bubble Sort):简单易懂,时间复杂度较高,适用于小规模数据排序。
选择排序(Selection Sort):简单易懂,时间复杂度较高,适用于小规模数据排序。
插入排序(Insertion Sort):对于部分有序的数据,插入排序的效率比较高,适合排序部分有序的小规模数据。
快速排序(Quick Sort):时间复杂度较低,适合排序大规模的数据,但对于有序数据排序,时间复杂度较高。
归并排序(Merge Sort):时间复杂度稳定,适用于大规模数据排序。
堆排序(Heap Sort):时间复杂度较低,但需要额外的空间存储堆。
计数排序(Counting Sort):时间复杂度较低,但需要额外的空间存储计数数组,适用于数据范围较小的排序。
桶排序(Bucket Sort):时间复杂度较低,但需要额外的空间存储桶,适用于数据范围较小的排序。
基数排序(Radix Sort):时间复杂度较低,但需要额外的空间存储桶,适用于数据范围较小的排序。
时间复杂度和空间复杂度
算法时间/空间复杂度是用来衡量算法执行时间和所需空间的一个指标。
它描述了算法在处理数据时所需的时间/空间量随着数据规模的增加而增加的速度。通常用大O符号(O)来表示。
| 时间复杂度是指算法执行所需的时间与问题规模之间的关系。 |
算法的稳定性什么意思?
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,A1=A2,且A1在A2之前,而在排序后的序列中,A1仍在A2之前,则称这种排序算法是稳定的;否则称为不稳定的。
| 1、6、3、a1、9、a2、5、0,假设a1=a2 ;排序后:0、1、3、a1、a2、5、6、9 |
稳定也可以理解为一切皆在掌握中,元素的位置处在你在控制中.而不稳定算法有时就有点碰运气,随机的成分.当两元素相等时它们的位置在排序后可能仍然相同.但也可能不同.是未可知的.
综上所述,不同的排序算法适用于不同的场景。在实际应用中,应根据数据规模、排序稳定性、时间复杂度、空间需求等因素选择合适的排序算法。
冒泡排序
比较相邻的元素,把大的交换到右边,从第一对到最后一对,这步做完后,最后的元素会是最大的数。
对剩余数据重复以上步骤,找第二大的数、第三大的数直至最后。
#include <stdio.h>
void exportArray(int arr[], int n){
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
//冒泡排序的基本思想是逐次判断相邻数值大小,把大的交换到右边。
//该函数中使用了两个嵌套的for循环来实现冒泡排序。
void bubbleSort(int arr[], int n) {
int i, j, temp, step;
//遍历整个数组
for (i = 0; i < n - 1; i++) {
//每一轮冒泡比较的次数,i越大比较次数越少
//因为每次i++前,都会确定一个最大的值,完成的不需要再比较,所以判断条件变为j < n-i-1
for (j = 0; j < n - i - 1; j++) {
step ++;//step表示排序的步数
//若左边值大于右边值,则交换两个值
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
//exportArray函数用于输出每一步排序后的结果
printf("Sorted step %d:",step);
exportArray(arr,n);
}
}
}
int main() {
int arr[] = {64, 34, 25, 12, 22};
int n = sizeof(arr) / sizeof(arr[0]);
bubbleSort(arr, n);
printf("Sorted end: \n");
exportArray(arr,n);
return 0;
}选择排序
- 首先在未排序序列中找到最小元素,存放到排序序列的起始位置。
- 再从剩余未排序元素中继续寻找最小元素,然后放到已排序序列的末尾。
- 重复第二步,直到所有元素均排序完毕。
#include <stdio.h>
void exportArray(int arr[], int n){
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
//遍历数组,每轮遍历时查找到最小的元素,放置左边
void selectionSort(int arr[], int n) {
int i, j, min_idx;
// 遍历整个数组
for (i = 0; i < n-1; i++) {
//设置当前数组第i个元素为假设最小值,其它元素会与其对比
min_idx = i;
// 遍历未排序的数组(未排序从i+1开始),找到数组中最小元素,记录它的索引
for (j = i+1; j < n; j++) {
printf("Find & Contrast %d\n",j);
//如果当前元素小于假设最小值,则认为当前值是最小的元素,记录当前元素位置位置
if (arr[j] < arr[min_idx])
min_idx = j;
}
// 将最小元素与未排序部分的第一个元素交换,每轮遍历都会记录一次当前轮最小值
int temp = arr[min_idx];
arr[min_idx] = arr[i];
arr[i] = temp;
//exportArray函数用于输出每一步排序后的结果
printf("Sorted step %d:",i);
exportArray(arr,n);
}
}
int main() {
int arr[] = {64, 25, 12, 22, 11};
int n = sizeof(arr)/sizeof(arr[0]);
selectionSort(arr, n);
printf("Sorted end: \n");
exportArray(arr,n);
return 0;
}插入排序
插入排序,只要打过扑克牌的人都应该能够秒懂,它的步骤如下:
- 将第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
- 依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。
#include <stdio.h>
void exportArray(int arr[],int n){
for(int i = 0; i < n; i++){
printf("%d ",arr[i]);
}
printf("\n");
}
void insertionSort(int arr[],int n){
for(int i = 1;i < n;i ++){
int key = arr[i];
for(int j = i - 1;j >= 0; j--){
int compara_value = arr[j];
if(compara_value > key){
arr[j + 1] = arr[j];
arr[j] = key;
}else{
//key为当前轮最大值,不需要往前插入
break;
}
}
printf("第%d轮插入\n",i);
exportArray(arr,n);
}
}
int main(){
int arr[] = {12,11,1,5,6};
int len = sizeof(arr)/sizeof(arr[0]);
printf("main init\n");
exportArray(arr,len);
insertionSort(arr,len);
}快速排序
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,而且效率高!它是处理大数据最快的排序算法之一了。
- 从数列中挑出一个元素,称为 "基准值";
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
#include <stdio.h>
void exportArray(int arr[], int n){
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
//交换两个值
void swap(int *a, int *b) {
int tmp = *a;
*a = *b;
*b = tmp;
}
//对比区间内,从第一个数开始与基准值的大小,如果比基准小,则把当前数与前面(比基准大的值)逐个交换
int partition(int arr[], int low, int high, int n) {
//选择基准元素为当前区间最后位置的元素
int pivot = arr[high];
//记录当前区间首个元素的位置
int i = low;
//统计交换次数
int times = 0;
printf("本轮区间 %d-%d 基准值:%d\n",low, high ,pivot);
//从第当前区间一个元素开始,到最后一个元素,与基准值比较
for (int j = low; j < high ; j++) {
if (arr[j] < pivot) {
//如果当前元素小于基准值,则把当前元素交换至当前区间的前面
swap(&arr[i], &arr[j]);
//从当前区间首个位置开始存放,每次存放完加1
i++;
//统计交换次数,打印交换后的数组
times++;
printf("Sorted step %d:",times);
exportArray(arr,n);
}
}
//结束一轮后,把基准值放到比它小的所有元素后方,也就是位置i后方
swap(&arr[i], &arr[high]);
//统计交换次数,打印交换后的数组
times++;
printf("Sorted step %d:",times);
exportArray(arr,n);
//返回当前基准值位置
return i;
}
void quicksort(int arr[], int low, int high, int n) {
//首次排序时,low等于数组首个元素位置(0),high等于数组最后一个元素的位置(数组长度)
//排序结束时,low>=high
if (low < high) {
//开始执行区间排序,选择最后一个元素作为基准元素
//排序后,数组分为两部分,左边比基准元素小,右边比基准元素大
int pi = partition(arr, low, high, n);
//根据上次排序划分的基准值位置,对左边区间排序
quicksort(arr, low, pi - 1, n);
//根据上次排序划分的基准值位置,对右边区间排序
quicksort(arr, pi + 1, high, n);
}
}
/**
快速排序(Quicksort)是一种高效的排序算法,
它的基本思想是通过一趟排序将待排序的数据分割成两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,
然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行。
具体实现过程如下:
选择一个基准元素,通常选择第一个元素或者最后一个元素,本程序选择最后一个为6;
通过一趟排序将待排序列分成两部分,一部分比基准元素小,一部分比基准元素大;
将基准元素和两个子序列分别递归地进行快速排序。
*/
int main() {
int arr[] = {10, 7, 8, 9, 1, 5, 6};
int n = sizeof(arr) / sizeof(arr[0]);
quicksort(arr, 0, n - 1,n);
printf("Sorted end: \n");
exportArray(arr,n);
return 0;
}



![【离散化 线段树】P3740 [HAOI2014] 贴海报|普及+](https://i-blog.csdnimg.cn/img_convert/6d5e5f1ce0c750699da2fc655a991b4c.png)