作者:IvanCodes
日期:2025年5月1日
专栏:Hive教程
在数据处理的广阔天地中,我们常常需要对数据进行转换、计算、清洗或提取特定信息。Hive 提供了强大的内置运算符和丰富的内置函数库,它们就像魔法师手中的魔法棒,能帮助我们灵活高效地操控数据,挖掘其深层价值。
思维导图
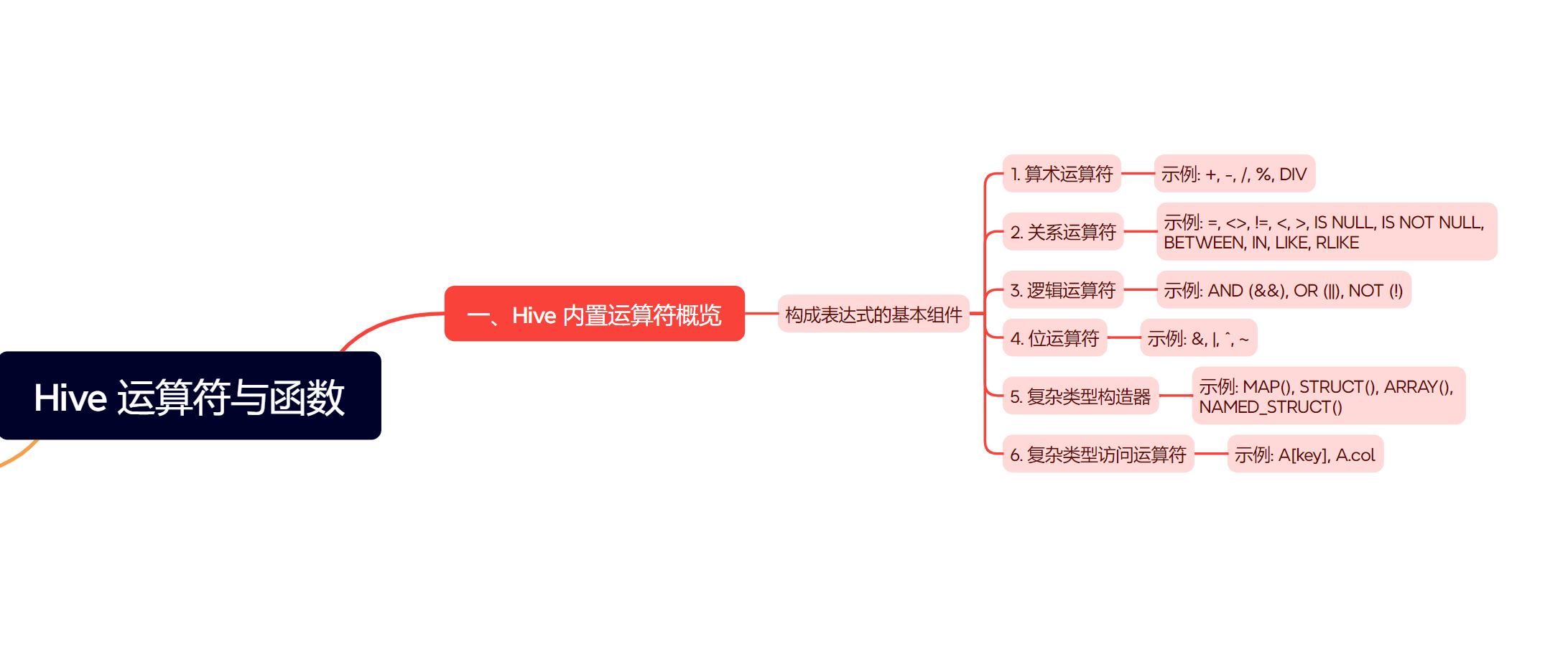

一、Hive 内置运算符概览
在深入函数之前,我们先快速回顾一下 Hive 支持的常见内置运算符,这些是构成表达式的基本组件:
- 算术运算符:
+,-,*,/,%,DIV - 关系运算符:
=,<>,!=,<,>,<=,>=,IS NULL,IS NOT NULL,BETWEEN,IN,NOT IN,LIKE,RLIKE,REGEXP - 逻辑运算符:
AND(&&),OR(||),NOT(!) - 位运算符:
&,|,^,~ - 复杂类型构造器:
MAP(),STRUCT(),ARRAY(),NAMED_STRUCT() - 复杂类型访问运算符:
A[key],A.col
二、Hive 内置函数详解
我们可以通过 SHOW FUNCTIONS; 查看所有可用函数,DESC FUNCTION [EXTENDED] <function_name>; 查看特定函数详情。
1. 数值函数 (Mathematical Functions)
round(DOUBLE a): 四舍五入为BIGINT。
SELECT round(3.14159); -- 输出: 3
round(DOUBLE a, INT d): 四舍五入到小数点后d位。
SELECT round(3.14159, 2); -- 输出: 3.14
floor(DOUBLE a): 不大于a的最大整数。
SELECT floor(3.7); -- 输出: 3
ceil(DOUBLE a)或ceiling(DOUBLE a): 不小于a的最小整数。
SELECT ceil(3.1); -- 输出: 4
abs(DOUBLE a): 绝对值。
SELECT abs(-5.5); -- 输出: 5.5
pow(DOUBLE a, DOUBLE p)或power(DOUBLE a, DOUBLE p): a的p次方。
SELECT pow(2, 3); -- 输出: 8.0
sqrt(DOUBLE a): 平方根。
SELECT sqrt(16); -- 输出: 4.0
rand()或rand(INT seed): 0到1之间的随机数。
SELECT rand(); -- 输出: (一个随机小数)
bin(BIGINT a): 二进制字符串。
SELECT bin(10); -- 输出: 1010
hex(BIGINT a)或hex(STRING a): 十六进制字符串。
SELECT hex(255); -- 输出: FF
conv(BIGINT num, INT from_base, INT to_base): 进制转换。
SELECT conv('A', 16, 10); -- 输出: 10
2. 字符串函数 (String Functions)
length(STRING a): 字符串长度。
SELECT length('hello'); -- 输出: 5
concat(STRING|BINARY a, STRING|BINARY b...): 连接字符串。
SELECT concat('Hi, ', 'Hive'); -- 输出: Hi, Hive
concat_ws(STRING separator, STRING a, STRING b...): 带分隔符连接。
SELECT concat_ws('-', 'A', 'B', 'C'); -- 输出: A-B-C
lower(STRING a)或lcase(STRING a): 转小写。
SELECT lower('HELLO'); -- 输出: hello
upper(STRING a)或ucase(STRING a): 转大写。
SELECT upper('world'); -- 输出: WORLD
trim(STRING a): 去两端空格。
SELECT trim(' Hive '); -- 输出: Hive
substring(STRING a, INT start[, INT len]): 取子串。
SELECT substring('HelloWorld', 1, 5); -- 输出: Hello
replace(STRING a, STRING old, STRING new): 替换子串。
SELECT replace('banana', 'na', 'PA'); -- 输出: baPAPA
instr(STRING str, STRING substr): 子串首次出现位置。
SELECT instr('apple-banana-orange', 'banana'); -- 输出: 7
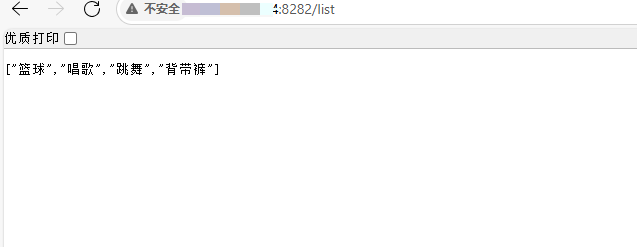
split(STRING str, STRING pat): 按正则分割,返回数组。
SELECT split('a,b,c', ','); -- 输出: ["a","b","c"]
lpad(STRING str, INT len, STRING pad): 左填充。
SELECT lpad('hi', 5, '*'); -- 输出: ***hi
rpad(STRING str, INT len, STRING pad): 右填充。
SELECT rpad('hi', 5, '*'); -- 输出: hi***
regexp_extract(STRING subject, STRING pattern, INT index): 正则提取。
SELECT regexp_extract('user_123_name', 'user_(\\d+)_name', 1); -- 输出: 123
regexp_replace(STRING initial_string, STRING pattern, STRING replacement): 正则替换。
SELECT regexp_replace('100-200', '-', ':'); -- 输出: 100:200
3. 日期函数 (Date Functions)
current_date(): 当前日期。
SELECT current_date(); -- 输出: (类似 2023-10-27)
current_timestamp(): 当前日期时间。
SELECT current_timestamp(); -- 输出: (类似 2023-10-27 10:30:00.123)
unix_timestamp(): 当前Unix时间戳。
SELECT unix_timestamp(); -- 输出: (当前秒级时间戳)
unix_timestamp(STRING date[, STRING pattern]): 日期转Unix时间戳。
SELECT unix_timestamp('2023-10-27', 'yyyy-MM-dd'); -- 输出: (对应时间戳)
from_unixtime(BIGINT unixtime[, STRING format]): Unix时间戳转日期字符串。
SELECT from_unixtime(1698381000, 'yyyy/MM/dd HH:mm'); -- 输出: 2023/10/27 10:30
to_date(STRING timestamp): 提取日期部分。
SELECT to_date('2023-10-27 10:30:00'); -- 输出: 2023-10-27
date_format(STRING/TIMESTAMP/DATE ts, STRING fmt): 格式化日期。
SELECT date_format(current_date(), 'yyyy年MM月dd日'); -- 输出: (类似 2023年10月27日)
year(STRING date),month(STRING date),day(STRING date): 提取年/月/日。
SELECT year('2023-10-27'), month('2023-10-27'); -- 输出: 2023, 10
date_add(STRING/TIMESTAMP/DATE startdate, INT days): 日期加天数。
SELECT date_add('2023-10-27', 3); -- 输出: 2023-10-30
date_sub(STRING/TIMESTAMP/DATE startdate, INT days): 日期减天数。
SELECT date_sub('2023-10-27', 3); -- 输出: 2023-10-24
datediff(STRING enddate, STRING startdate): 日期天数差。
SELECT datediff('2023-10-30', '2023-10-27'); -- 输出: 3
4. 条件函数 (Conditional Functions)
if(boolean testCondition, T valueTrue, T valueFalseOrNull): IF判断。
SELECT if(1 > 0, 'Yes', 'No'); -- 输出: Yes
CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END: 标准CASE WHEN。
SELECT
CASE
WHEN score >= 90 THEN 'A'
WHEN score >= 80 THEN 'B'
ELSE 'C'
END AS grade
FROM (SELECT 85 AS score) t; -- 输出: B
COALESCE(T v1, T v2, ...): 返回首个非NULL值。
SELECT COALESCE(NULL, 'Default1', 'Default2'); -- 输出: Default1
NVL(T value, T default_value): value非NULL则返回value,否则返回default_value。
SELECT NVL(NULL, 'Is Null'); -- 输出: Is Null
5. 类型转换函数 (Type Conversion Functions)
cast(expr AS type): 强制类型转换。
SELECT cast('123' AS INT) + cast('7' AS INT); -- 输出: 130
6. 聚合函数 (Aggregate Functions) (常与 GROUP BY 联用)
count(*)或count(expr)或count(DISTINCT expr): 计数。
SELECT count(*) FROM my_table;
SELECT count(DISTINCT user_id) FROM user_logs;
sum(col)或sum(DISTINCT col): 求和。
SELECT sum(sales_amount) FROM sales_data;
avg(col)或avg(DISTINCT col): 平均值。
SELECT avg(score) FROM student_scores;
min(col): 最小值。
SELECT min(price) FROM products;
max(col): 最大值。
SELECT max(temperature) FROM weather_records;
7. 集合函数 (Collection Functions) (处理ARRAY, MAP, STRUCT)
size(MAP<K,V> m)或size(ARRAY<T> a): 返回Map或Array的大小。
SELECT size(array(1, 2, 3)); -- 输出: 3
SELECT size(map('a', 1, 'b', 2)); -- 输出: 2
array_contains(ARRAY<T> a, value): 判断Array是否包含指定值。
SELECT array_contains(array('apple', 'banana'), 'apple'); -- 输出: true
map_keys(MAP<K,V> m): 返回Map的所有键组成的Array。
SELECT map_keys(map('name', 'Alice', 'age', 30)); -- 输出: ["name","age"] (顺序可能不同)
map_values(MAP<K,V> m): 返回Map的所有值组成的Array。
SELECT map_values(map('name', 'Alice', 'age', 30)); -- 输出: ["Alice","30"] (顺序可能不同)
sort_array(ARRAY<T> a): 对Array进行排序。
SELECT sort_array(array(3, 1, 2)); -- 输出: [1,2,3]
8. 表生成函数 (Table-Generating Functions - UDTF)
explode(ARRAY<T> a): 将数组每个元素转为一行。
SELECT explode(array('A', 'B')) AS item;
-- 输出:
-- A
-- B
explode(MAP<K,V> m): 将Map每个键值对转为一行两列。
SELECT explode(map('key1', 'val1')) AS (my_key, my_value);
-- 输出:
-- key1 val1
posexplode(ARRAY<T> a): 类似explode(array),额外输出元素在数组中的位置(从0开始)。
SELECT posexplode(array('X', 'Y')) AS (pos, val);
-- 输出:
-- 0 X
-- 1 Y
inline(ARRAY<STRUCT<f1:T1, f2:T2, ...>> a): 将结构体数组展开,每个结构体的字段成为独立的列。
-- 假设table t有列 arr_struct: ARRAY<STRUCT<name:STRING, age:INT>>
-- 且某行 arr_struct 值为 [named_struct('name','Tom','age',20), named_struct('name','Jerry','age',18)]
-- SELECT inline(arr_struct) FROM t;
-- 输出 (对于该行会产生两行结果):
-- Tom 20
-- Jerry 18
9. 数据脱敏函数 (Data Masking/Anonymization - 通过组合或UDF实现)
Hive 内置的直接、专用的脱敏函数较少。通常通过组合现有字符串函数来实现,或者编写用户自定义函数 (UDF) 来完成复杂的脱敏逻辑。
- 示例:部分屏蔽手机号 (组合字符串函数)
-- 假设 phone_number 是 '13812345678'
SELECT concat(substring(phone_number, 1, 3), '****', substring(phone_number, 8)) AS masked_phone
FROM (SELECT '13812345678' AS phone_number) t;
-- 输出: 138****5678
- 示例:屏蔽邮箱用户名 (组合字符串函数)
-- 假设 email 是 'user_example@domain.com'
SELECT concat(
substring(email, 1, 1), -- 第一个字符
'****', -- 屏蔽符
substring(email, locate('@', email) - 1, 1), -- @前一个字符
substring(email, locate('@', email)) -- @及之后的部分
) AS masked_email
FROM (SELECT 'user_example@domain.com' AS email) t;
-- 输出: u****e@domain.com (这是一个简化示例,更复杂的正则UDF效果更好)
对于更复杂或通用的脱敏需求(如身份证号、银行卡号按规则屏蔽,或基于角色的动态脱敏),通常推荐开发 UDF。
10. 用户自定义函数 (拓展)
当内置函数无法满足特定的业务逻辑时,Hive 允许用户使用 Java (或其他语言,但Java最常见) 编写自己的函数。
-
UDF (User-Defined Function): 一对一或多对一函数,输入一行中的一个或多个值,输出一个值。
- 例如,创建一个
to_uppercase(string_col)函数,将输入字符串转为大写(虽然已有内置upper)。 - 创建和使用步骤 (简要):
- 编写 Java 类继承
org.apache.hadoop.hive.ql.exec.UDF。 - 实现
evaluate()方法。 - 将 Java 项目打成 JAR 包。
- 在 Hive 中注册 JAR 包:
ADD JAR /path/to/your.jar; - 创建临时或永久函数:
CREATE TEMPORARY FUNCTION my_upper AS 'com.example.MyUpperUDF'; - 使用函数:
SELECT my_upper(name) FROM my_table;
- 编写 Java 类继承
- 例如,创建一个
-
UDAF (User-Defined Aggregate Function): 多对一函数,类似
SUM(),COUNT(),对分组数据进行聚合。编写 UDAF 相对复杂。 -
UDTF (User-Defined Table-Generating Function): 一对多函数,类似
explode(),输入一行,输出多行。
练习题
- 将字符串 “hive is great” 中的所有空格替换为下划线
_。 - 计算日期 “2023-01-15” 之后45天的日期。
- 有一个用户评分表
ratings (user_id INT, score INT),如果用户评分低于60则标记为 “不及格”,否则标记为 “及格”。写出查询。 - 将字符串 “ID:123,Name:Alice,Age:30” 按逗号分割,然后对每个部分按冒号分割,提取出 Name 的值 “Alice”。
- 有一个字段
tags其值为 ARRAY 类型,如['TagA', 'TagB', 'TagC']。检查该数组是否包含 ‘TagB’。 - 将一个包含用户月消费金额的数组
monthly_spend ARRAY<INT>(例如[100, 150, 120]) 展开成多行,每行显示一个月的消费金额。 - 假设有一个字段
ip_address存储IP地址字符串,请使用内置函数(如果可能)将其最后一个点之后的部分替换为 ‘XXX’ (例如 ‘192.168.1.100’ -> ‘192.168.1.XXX’)。如果内置函数难以实现,请描述UDF的思路。 - 将 Unix 时间戳
1672531200(代表 2023-01-01 00:00:00 UTC) 格式化为 “YYYY年MM月DD日 HH时mm分ss秒” 的形式。 - 从字符串 “apple,banana,orange,apple” 中提取出所有不重复的水果名称,并计算不重复水果的数量。
- 如何使用
COALESCE函数处理一个可能为NULL的middle_name字段,如果它为NULL,则在拼接全名时用空字符串代替?例如,first_name,middle_name,last_name。
练习题答案
- 将字符串 “hive is great” 中的所有空格替换为下划线
_。
SELECT replace('hive is great', ' ', '_');
- 计算日期 “2023-01-15” 之后45天的日期。
SELECT date_add('2023-01-15', 45);
- 有一个用户评分表
ratings (user_id INT, score INT),如果用户评分低于60则标记为 “不及格”,否则标记为 “及格”。写出查询。
SELECT user_id, score, if(score < 60, '不及格', '及格') AS status FROM ratings;
-- 或者使用 CASE WHEN
-- SELECT user_id, score, CASE WHEN score < 60 THEN '不及格' ELSE '及格' END AS status FROM ratings;
- 将字符串 “ID:123,Name:Alice,Age:30” 按逗号分割,然后对每个部分按冒号分割,提取出 Name 的值 “Alice”。
SELECT split(kv[1], ':')[1] AS name_value
FROM (
SELECT split('ID:123,Name:Alice,Age:30', ',') AS kv_array
) t
LATERAL VIEW explode(kv_array) exploded_table AS kv_pair_str
WHERE split(kv_pair_str, ':')[0] = 'Name';
-- 更简洁的方式如果知道Name总在第二个位置:
SELECT split(split('ID:123,Name:Alice,Age:30', ',')[1], ':')[1];
- 有一个字段
tags其值为 ARRAY 类型,如['TagA', 'TagB', 'TagC']。检查该数组是否包含 ‘TagB’。
SELECT array_contains(tags, 'TagB') FROM (SELECT array('TagA', 'TagB', 'TagC') AS tags) t;
- 将一个包含用户月消费金额的数组
monthly_spend ARRAY<INT>(例如[100, 150, 120]) 展开成多行,每行显示一个月的消费金额。
SELECT spend
FROM (SELECT array(100, 150, 120) AS monthly_spend) t
LATERAL VIEW explode(monthly_spend) exploded_table AS spend;
- 假设有一个字段
ip_address存储IP地址字符串,请使用内置函数(如果可能)将其最后一个点之后的部分替换为 ‘XXX’ (例如 ‘192.168.1.100’ -> ‘192.168.1.XXX’)。如果内置函数难以实现,请描述UDF的思路。
使用内置函数比较复杂,需要多次使用instr和substring或regexp_replace:
SELECT regexp_replace(ip_address, '\\.[^.]+$', '.XXX') AS masked_ip
FROM (SELECT '192.168.1.100' AS ip_address) t;
-- 或者更精确控制,找到最后一个点的位置
-- SELECT concat(substring(ip_address, 1, instr(reverse(ip_address), '.') * -1 + length(ip_address) -1), '.XXX') ... (这种方式更复杂且易错)
UDF思路:编写一个Java UDF,输入IP字符串。在Java中使用 lastIndexOf('.') 找到最后一个点的位置,然后使用 substring() 截取前面的部分,并拼接上 “.XXX”。
- 将 Unix 时间戳
1672531200(代表 2023-01-01 00:00:00 UTC) 格式化为 “YYYY年MM月DD日 HH时mm分ss秒” 的形式。
SELECT from_unixtime(1672531200, 'yyyy年MM月dd日 HH时mm分ss秒');
- 从字符串 “apple,banana,orange,apple” 中提取出所有不重复的水果名称,并计算不重复水果的数量。
SELECT collect_set(fruit) AS unique_fruits, size(collect_set(fruit)) AS unique_fruit_count
FROM (
SELECT explode(split('apple,banana,orange,apple', ',')) AS fruit
) t_fruits;
- 如何使用
COALESCE函数处理一个可能为NULL的middle_name字段,如果它为NULL,则在拼接全名时用空字符串代替?例如,first_name,middle_name,last_name。
SELECT concat_ws(' ', first_name, COALESCE(middle_name, ''), last_name) AS full_name
FROM (
SELECT 'John' AS first_name, NULL AS middle_name, 'Doe' AS last_name
UNION ALL
SELECT 'Jane' AS first_name, 'M' AS middle_name, 'Smith' AS last_name
) t_names;
-- 对于 'John', NULL, 'Doe' 会输出 "John Doe" (注意concat_ws对空字符串的处理)
-- 如果希望中间没有多余空格,可以这样:
-- SELECT trim(concat(first_name, ' ', COALESCE(concat(middle_name, ' '), ''), last_name)) AS full_name ...
更优雅的方式是针对 concat_ws 的特性,如果 COALESCE(middle_name, NULL) 结果是 NULL,concat_ws 会跳过它。但如果希望它是空字符串而不是被跳过(比如为了保持名字间的空格),上面的 COALESCE(middle_name, '') 是对的。