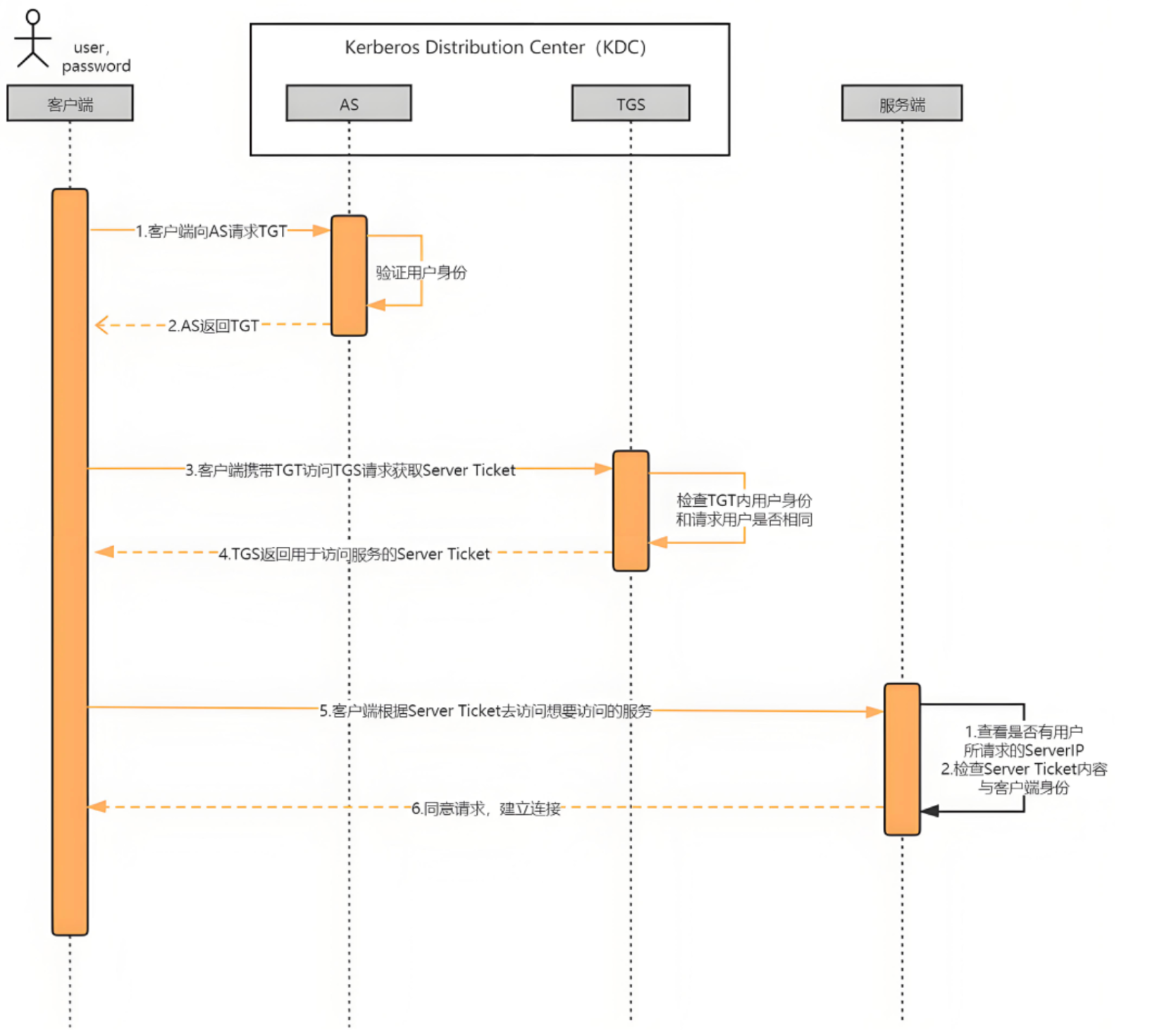
3. 编译器gcc/g++
3.1 背景知识
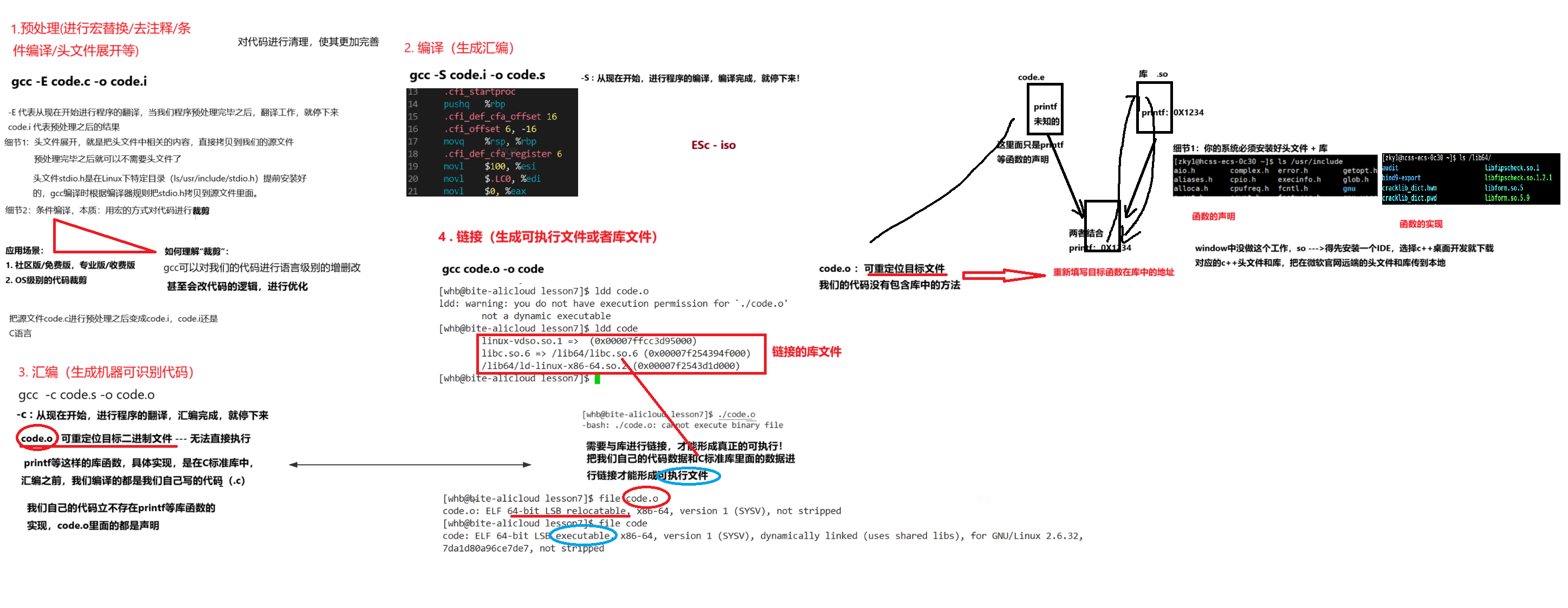
1. 预处理(进行宏替换/去注释/条件编译/头文件展开等)
2. 编译(生成汇编)
3. 汇编(生成机器可识别代码)
4. 连接(生成可执行文件或库文件)
3.2 gcc编译选项
格式 : gcc 【选项】 要编译的文件 【选项】【目标文件】
1.预处理(进行宏替换)
预处理功能主要包括宏定义,⽂件包含,条件编译,去注释等。
预处理指令是以#号开头的代码行。
实例: gcc –E hello.c –o hello.i
选项“-E”,该选项的作⽤是让 gcc 在预处理结束后停⽌编译过程。
选项“-o”是指⽬标⽂件,“.i”⽂件为已经过预处理的C原始程序。

2. 编译(生成汇编)
在这个阶段中,gcc ⾸先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的⼯作,在检查⽆误后,gcc 把代码翻译成汇编语⾔。
用户可以使⽤“-S”选项来进⾏查看,该选项只进⾏编译⽽不进⾏汇编,⽣成汇编代码。实例: gcc –S hello.i –o hello.s

3. 汇编(生成机器可识别代码)
汇编阶段是把编译阶段⽣成的“.s”⽂件转成⽬标⽂件
读者在此可使⽤选项“-c”就可看到汇编代码已转化为“.o”的⼆进制⽬标代码了
实例: gcc –c hello.s –o hello.o

4. 连接(生成可执行文件或库文件)
3.3 动态链接和静态链接
在我们的实际开发中,不可能将所有代码放在⼀个源⽂件中,所以会出现多个源⽂件,⽽且多个源⽂件之间不是独⽴的,⽽会存在多种依赖关系,如⼀个源⽂件可能要调⽤另⼀个源⽂件中定义的函数,但是每个源⽂件都是独⽴编译的,即每个*.c⽂件会形成⼀个*.o⽂件,为了满⾜前⾯说的依赖关系,则需要将这些源⽂件产⽣的⽬标⽂件进⾏链接,从⽽形成⼀个可以执⾏的程序。这个链接的过程就是静态链接。静态链接的缺点很明显:
- 浪费空间:因为每个可执⾏程序中对所有需要的⽬标⽂件都要有⼀份副本,所以如果多个程序对同⼀个⽬标⽂件都有依赖,如多个程序中都调⽤了printf()函数,则这多个程序中都含有
printf.o,所以同⼀个⽬标⽂件都在内存存在多个副本;
-
更新⽐较困难:因为每当库函数的代码修改了,这个时候就需要重新进⾏编译链接形成可执⾏程序。但是静态链接的优点就是,在可执⾏程序中已经具备了所有执⾏程序所需要的任何东西,在执⾏的时候运⾏速度快
动态链接的出现解决了静态链接中提到问题。动态链接的基本思想是把程序按照模块拆分成各个相对独⽴部分,在程序运⾏时才将它们链接在⼀起形成⼀个完整的程序,⽽不是像静态链接⼀样把所有程序模块都链接成⼀个单独的可执⾏⽂件。
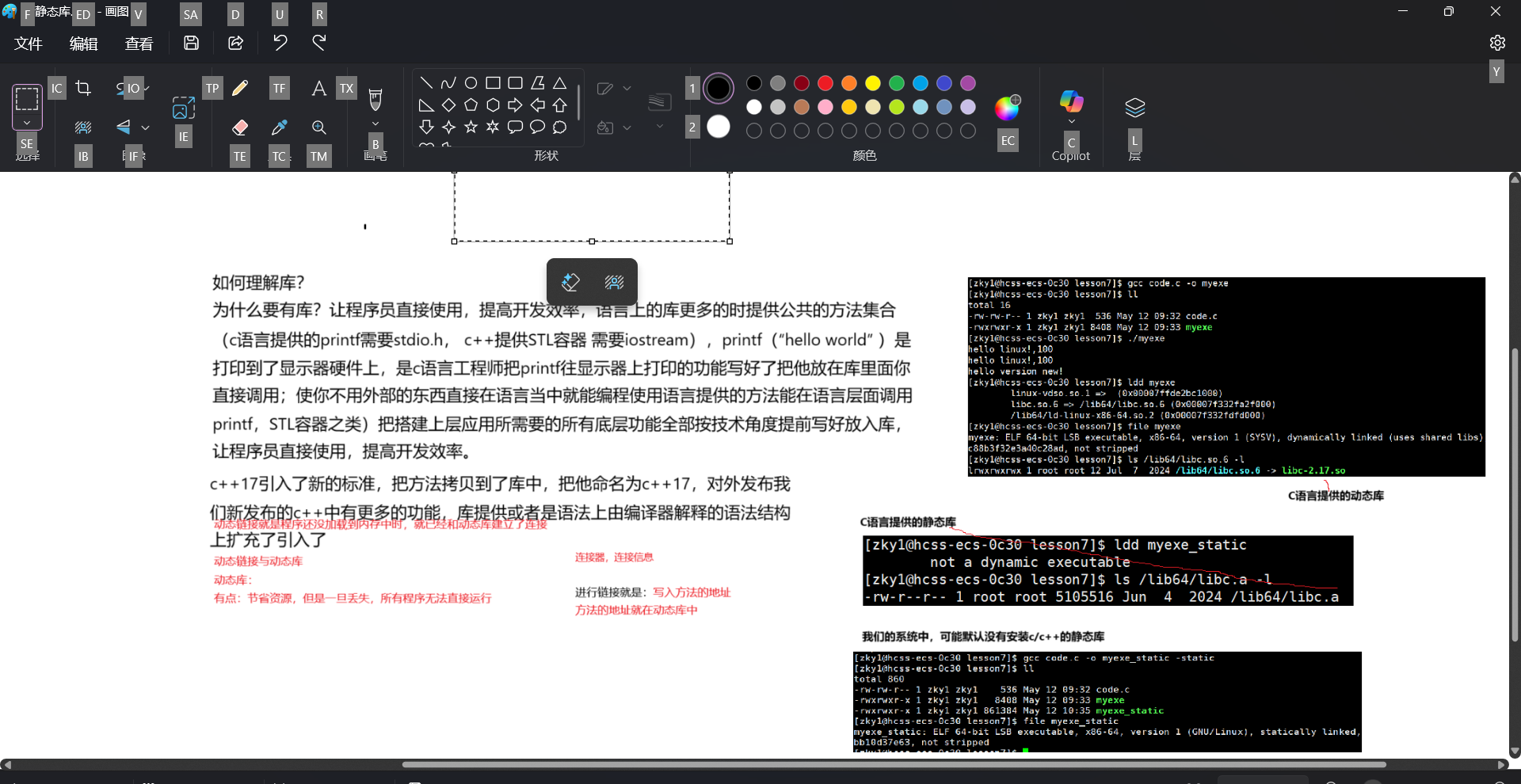
动态链接其实远⽐静态链接要常⽤得多。⽐如我们查看下 hello 这个可执⾏程序依赖的动态库,会发现它就⽤到了⼀个c动态链接库:
$ ldd hello
linux-vdso.so.1 => (0x00007fffeb1ab000)
libc.so.6 => /lib64/libc.so.6 (0x00007ff776af5000)
/lib64/ld-linux-x86-64.so.2 (0x00007ff776ec3000)
# ldd命令⽤于打印程序或者库⽂件所依赖的共享库列表。在这里涉及到⼀个重要的概念: 库!!!
我们的C程序中,并没有定义“printf”的函数实现,且在预编译中包含的“stdio.h”中也只有该函数的声明,⽽没有定义函数的实现,那么,是在哪⾥实“printf”函数的呢?
答案是:系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径“/usr/lib”下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数“printf”了,而这也就是链接的作用。
如何理解库?
为什么要有库?让程序员直接使用,提高开发效率,语言上的库更多的时提供公共的方法集合(c语言提供的printf需要stdio.h, c++提供STL容器 需要iostream),printf(“hello world” )是打印到了显示器硬件上,是c语言工程师把printf往显示器上打印的功能写好了把他放在库里面你直接调用;使你不用外部的东西直接在语言当中就能编程使用语言提供的方法能在语言层面调用printf,STL容器之类)把搭建上层应用所需要的所有底层功能全部按技术角度提前写好放入库,让程序员直接使用,提高开发效率。
动态库/共享库最终也是会加载到内存中的,只有一份,把公共的方法抽取出来,在系统中只有一份节省内存资源,磁盘里面不存速度慢一点。
动态链接就是程序还没加载到内存中时,就已经和动态库建立了连接;
动态链接:
程序通过连接器获取了连接信息,要进行链接!!
进行链接就是去动态库获取写入方法的地址;
优点:节省资源;
缺点:动态库一旦丢失所有程序无法直接运行、速度慢;
静态链接: 把你要的方法直接拷贝到可执行程序中
动态库把方法直接给了连接器,连接器进行链接时,直接给程序,和动态库取消联系,不依赖任何库
优点:不依赖任何库,自己独立就能运行;
缺点:体积大,占据资源多(占据磁盘空间,内存空间)无法充分利用资源,加载速度受影响
我们的系统中一般默认没有安装c/c++的静态库,我们可以用命令行安装c/c++的静态库:
使用yum(适用于CentOS,RHEL,Fedora)centos:
sudo yum install glibc-static
sudo yum install libstdc++-static
如果需要完整的的开发工具链(如gcc、g++等),可以安装一下包:
sudo yum install gcc gcc-c++ make
使用apt(适用于Ubuntu,Debian等):
sudo apt install libc6-dev
sudo apt install libstdc++-static-dev
如果需要完整的的开发工具链(如gcc、g++等),可以安装一下包:
sudo apt install build-essential
3.4 静态库和动态库
静态库是指编译链接时,把库⽂件的代码全部加⼊到可执⾏⽂件中,因此⽣成的⽂件⽐较⼤,但在运⾏时也就不再需要库⽂件了。其后缀名⼀般为".a"
动态库与之相反,在编译链接时并没有把库⽂件的代码加⼊到可执⾏⽂件中,⽽是在程序执⾏时由运⾏时链接⽂件加载库,这样可以节省系统的开销。动态库⼀般后缀名为“.so”,如前⾯所述的libc.so.6 就是动态库。gcc 在编译时默认使⽤动态库。完成了链接之后,gcc 就可以⽣成可执⾏⽂件,如下所⽰。 gcc hello.o –o hello
gcc默认生成的⼆进制程序,是动态链接的,这点可以通过 file 命令验证。
Linux下,动态库XXX.so, 静态库XXX.a
Windows下,动态库XXX.dll, 静态库XXX.lib
如何查看是否已经安装epel-release源:
EPEL 仓库的配置文件通常位于 /etc/yum.repos.d/ 目录下。你可以列出该目录下的文件,看看是否有与 EPEL 相关的 repo 文件:
ls -l /etc/yum.repos.d/ | grep epel也可以安装一个广泛使用的C++库集合,提供了大量的功能,从智能指针到正则表达式支持等
# 安装 Boost 静态库
sudo yum install boost-devel二. 自动化构建 -make/Makefile
2.1 背景
会不会写makefile,从⼀个侧⾯说明了⼀个人是否具备完成⼤型工程的能力。
⼀个⼯程中的源⽂件不计数,其按类型、功能、模块分别放在若⼲个⽬录中,makefile定义了⼀系列的规则来指定,哪些⽂件需要先编译,哪些⽂件需要后编译,哪些⽂件需要重新编译,甚⾄于进⾏更复杂的功能操作
makefile带来的好处就是⸺“⾃动化编译”,⼀旦写好,只需要⼀个make命令,整个⼯程完全⾃动编译,极⼤的提⾼了软件开发的效率。
make是⼀个命令⼯具,是⼀个解释makefile中指令的命令⼯具,⼀般来说,⼤多数的IDE都有这个命令,⽐如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可⻅,makefile都成为了⼀种在⼯程⽅⾯的编译⽅法。
make是⼀条命令,makefile是⼀个文件,两个搭配使⽤,完成项目自动化构建
2.2 基本使用
实例代码
#include <stdio.h>
int main()
{
printf("hello Makefile!\n");
return 0;
}Makefile文件
myproc:myproc.c
gcc -o myproc myproc.c
.PHONY:clean
clean:
rm -f myproc依赖关系
上⾯的⽂件myproc,它依赖myproc.c
依赖方法
gcc -o myproc myproc.c ,就是与之对应的依赖关系
项⽬清理
⼯程是需要被清理的
像clean这种,没有被第⼀个⽬标⽂件直接或间接关联,那么它后⾯所定义的命令将不会被⾃动执⾏,不过,我们可以显⽰要make执⾏。即命令⸺“make clean”,以此来清除所有的⽬标⽂件,以便重编译。
但是⼀般我们这种clean的⽬标⽂件,我们将它设置为伪⽬标,⽤ .PHONY 修饰,伪⽬标的特性是,总是被执⾏的。
这里就涉及到了总是被执行和不被执行两个概念。
这里直接看图详解:

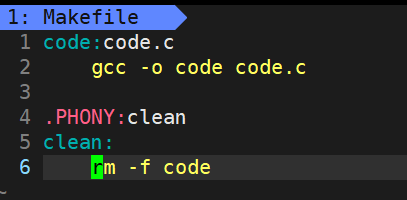
输入make命令,make命令会自动在当前目录下 找Makefile,然后用make去解释Makefile里面的内容, 从上往下执行Makefile中的编译方法,帮我们形成可执行程序。
有了.PHONY,make clean 就可以重复执行 rm -f code。
.PHONY:让make忽略源文件和可执行标文件的M时间对比
2.3 推导过程
myproc:myproc.o
gcc myproc.o -o myproc
myproc.o:myproc.s
gcc -c myproc.s -o myproc.o
myproc.s:myproc.i
gcc -S myproc.i -o myproc.s
myproc.i:myproc.c
gcc -E myproc.c -o myproc.i
.PHONY:clean
clean:
rm -f *.i *.s *.o myproc
编译过程
$ make
gcc -E myproc.c -o myproc.i
gcc -S myproc.i -o myproc.s
gcc -c myproc.s -o myproc.o
gcc myproc.o -o myproc
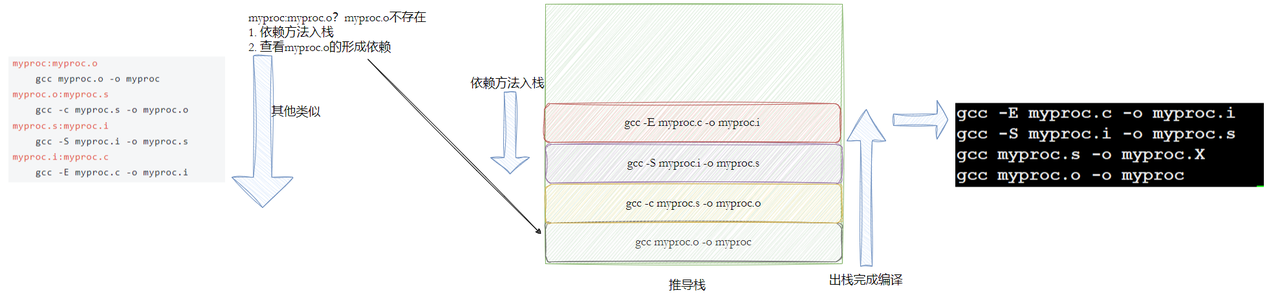
make是如何工作的,在默认的方式下,也就是我们只输入make命令。那么:
- make会在当前⽬录下找名字叫“Makefile”或“makefile”的⽂件。
- 如果找到,它会找⽂件中的第⼀个⽬标⽂件(target),在上⾯的例⼦中,他会找到 myproc 这个⽂件,并把这个⽂件作为最终的⽬标⽂件。
- 如果 myproc ⽂件不存在,或是 myproc 所依赖的后⾯的 myproc.o ⽂件的⽂件修改时间要⽐ myproc 这个⽂件新(可以⽤ touch 测试),那么,他就会执⾏后⾯所定义的命令来⽣成myproc 这个⽂件。
- 如果 myproc 所依赖的 myproc.o ⽂件不存在,那么 make 会在当前⽂件中找⽬标为myproc.o ⽂件的依赖性,如果找到则再根据那⼀个规则⽣成 myproc.o ⽂件。(这有点像⼀个堆栈的过程)
- 当然,你的C⽂件和H⽂件是存在的啦,于是 make 会⽣成 myproc.o ⽂件,然后再⽤ myproc.o ⽂件声明 make 的终极任务,也就是执⾏⽂件 hello 了。
- 这就是整个make的依赖性,make会⼀层⼜⼀层地去找⽂件的依赖关系,直到最终编译出第⼀个⽬标⽂件。
- 在找寻的过程中,如果出现错误,⽐如最后被依赖的⽂件找不到,那么make就会直接退出,并报错,⽽对于所定义的命令的错误,或是编译不成功,make根本不理。
- make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后⾯的⽂件还是不存在,那么就停止工作
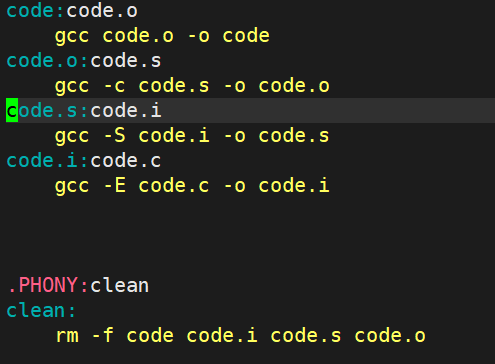
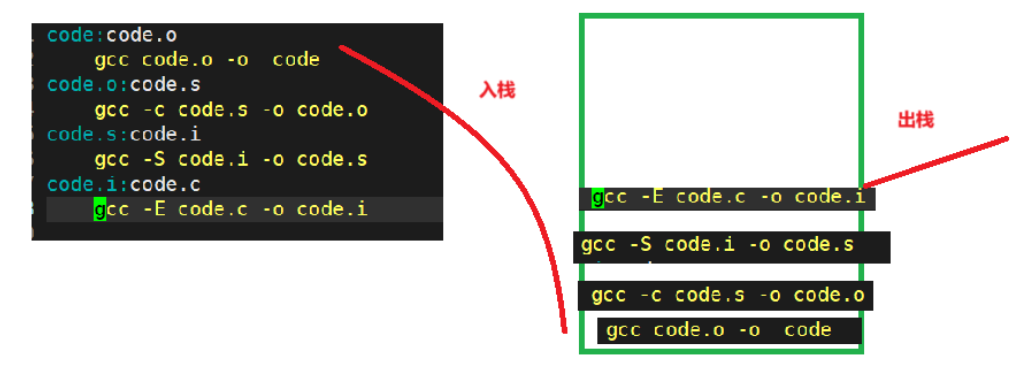
输入make命令时,会读取当前目录下的Makefile文件,自顶向下对文件进行扫描,首先会发现code依赖的code.o不存在,因为code.o也有依赖关系,所以make进而找code.o的依赖关系,依次往下。到最后找到code.i依赖的code.c,依赖文件列表code.c本身在当前目录下是已经存在的,所以code.c已经具备了能够进行形成code.i的条件了,所以make就会执行code.i的依赖方法gcc -E code.c -o code.c这条命令,一旦code.i形成那么code.s,code.s所对应的依赖关系也有了,就会执行他的依赖方法。依次往上。---这就是make自动推导的过程。
当识别到code.o不存在会向下找,因为code.o也有依赖关系,所以make除了找code.o的依赖关系,还会把上一组code.o形成code的这组依赖方法入栈,然后依次往下,等到识别到code.c已经具备了能够进行形成code.i的条件时,然后依次出栈执行依赖方法。
不想看这个命令执行的过程,只看结果,前面加@,关闭回显
2.4 扩展语法
有了变量的定义,我们要定义的目标文件叫Bin,
源文件SRC

BIN=proc.exe # 定义变量
CC=gcc
#SRC=$(shell ls *.c) # 采⽤shell命令⾏⽅式,获取当前所有.c⽂件名
SRC=$(wildcard *.c) # 或者使⽤ wildcard 函数,获取当前所有.c⽂件名
OBJ=$(SRC:.c=.o) # 将SRC的所有同名.c 替换 成为.o 形成⽬标⽂件列表
LFLAGS=-o # 链接选项
FLAGS=-c # 编译选项
RM=rm -f # 引⼊命令