归并排序(Merge Sort)以简洁而高效的分治思想,在众多排序算法中占据着重要的地位。今天,就让我们一同深入探索归并排序的奥秘。
一、归并排序简介
归并排序是一种基于分治策略的排序算法。它的核心思想是将一个大的问题分解成若干个小的子问题,分别解决这些子问题,最后将子问题的解合并起来,从而得到原问题的解。具体到排序问题,归并排序将待排序的数组不断地二分,直到每个子数组只包含一个元素(因为单个元素本身就是有序的),然后再将这些有序的子数组合并成一个大的有序数组。
二、算法步骤详解
1. 分解(Divide)
将待排序的数组从中间位置分成两个子数组。如果数组的长度为 n,那么中间位置通常取 mid = left + (right - left) / 2(这里 left 和 right 分别表示当前子数组的左右边界),这样可以避免直接相加可能导致的整数溢出问题。然后,对这两个子数组分别递归地进行归并排序。
2. 合并(Merge)
当子数组的长度为 1 时,递归过程开始回溯。此时,需要将两个已经有序的子数组合并成一个大的有序数组。合并的过程如下:
- 创建一个临时数组
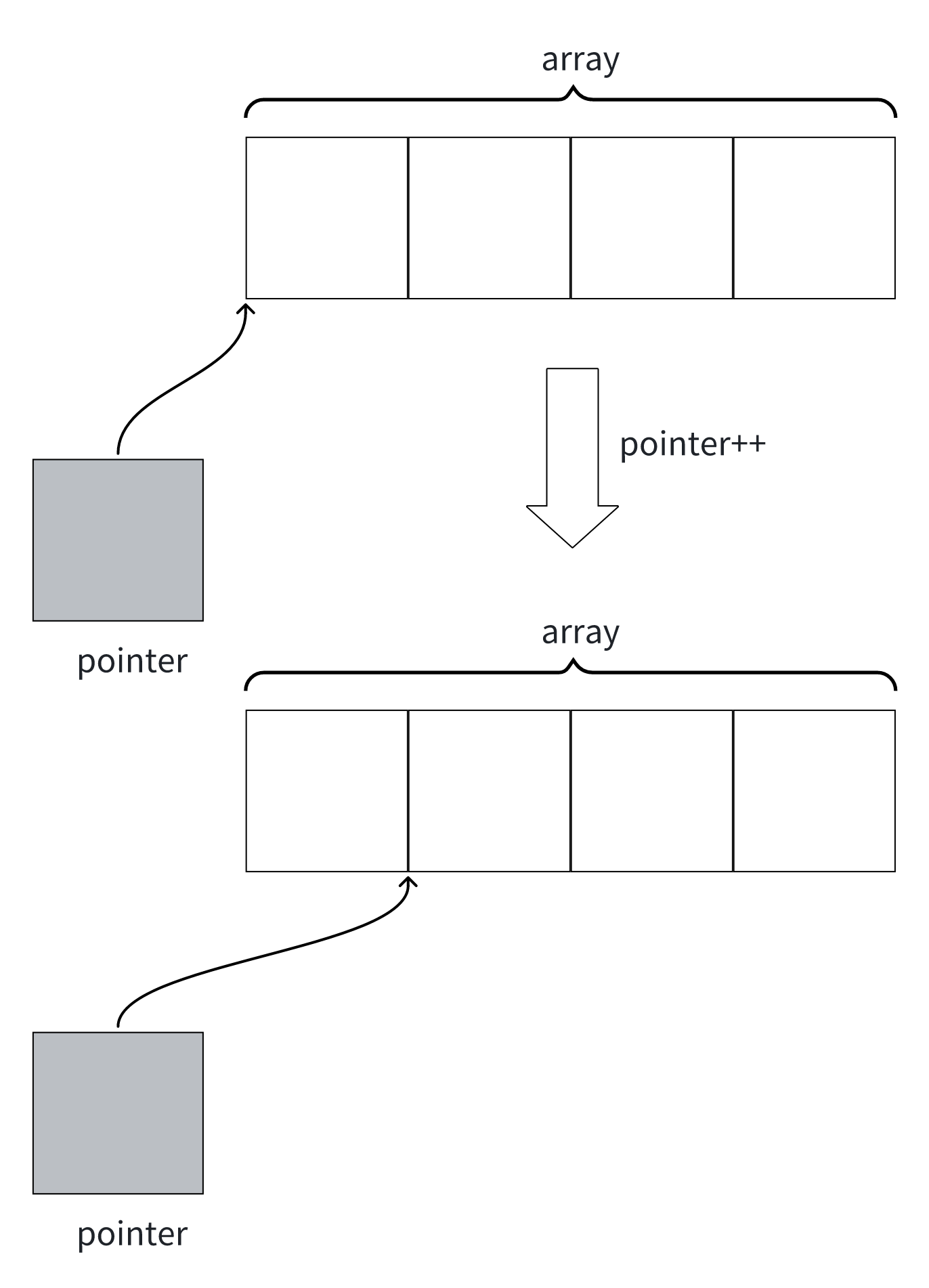
temp,用于存储合并后的结果。 - 使用两个指针
i和j分别指向两个子数组的起始位置。 - 比较两个子数组当前指针所指向的元素,将较小的元素放入临时数组
temp中,并移动相应的指针。 - 重复上述比较和移动指针的操作,直到其中一个子数组的所有元素都被放入临时数组。
- 将另一个子数组中剩余的元素依次放入临时数组。
- 最后,将临时数组中的元素复制回原数组的相应位置。
三、代码实现(C)
ElemType *B = (ElemType *) malloc((n + 1) * sizeof(ElemType)); //辅助数组
//将A中left到right的元素按升序
merge(ElemType A[], int left, int mid, int right) {
for (int k = left; k <= right; k++) B[k] = A[k];
int i = left, j= mid + 1;
int k = i;
while (i <= left && j <= right) {
if (B[i] <= B[j]) {
A[k++] = B[i];
} else {
A[k++] = B[j];
}
}
while (j <= right) {
A[k++] = B[j++]
}
while (i <= mid) {
A[k++] = B[i++];
}
}
void mergeSort(ElemType A[], int left, int right){
if (left == right) return;
int mid = (left + right) / 2; //将数组划分为两个子数组
mergeSort(A, left, mid);
mergeSort(A, mid + 1, right);
merge(A, left, mid, right); //合并两个子数组
}
四、算法分析
1. 时间复杂度
归并排序的时间复杂度为 O ( n l o g n ) O(n log n) O(nlogn)。在分解阶段,每次都将数组分成两半,需要进行 l o g n log n logn 次分解;在合并阶段,每次合并两个子数组的时间复杂度为 O ( n ) O(n) O(n),因为需要遍历所有的元素。因此,总的时间复杂度为 O ( n l o g n ) O(n log n) O(nlogn)。无论待排序数组的初始状态如何,归并排序的时间复杂度都是稳定的 O ( n l o g n ) O(n log n) O(nlogn),这使得它在处理大规模数据时具有很高的效率。
2. 空间复杂度
归并排序的空间复杂度为 O ( n ) O(n) O(n)。因为在合并过程中需要创建一个临时数组来存储合并后的结果,这个临时数组的大小与原数组相同,所以空间复杂度为 O ( n ) O(n) O(n)。
3. 稳定性
归并排序是一种稳定的排序算法。在合并过程中,当遇到两个相等的元素时,会优先将左子数组中的元素放入结果数组,这样可以保证相等元素的相对顺序不变。
五、归并排序的优缺点
优点
- 效率高:时间复杂度稳定为 O ( n l o g n ) O(n log n) O(nlogn),适合处理大规模数据。
- 稳定性:是一种稳定的排序算法,适用于对稳定性有要求的场景。
- 可并行化:由于归并排序采用了分治策略,其分解和合并过程可以并行进行,适合在多核处理器上实现并行计算,进一步提高排序效率。
缺点
- 空间复杂度高:需要额外的 O ( n ) O(n) O(n)空间来存储临时数组,这在处理大规模数据时可能会成为瓶颈。
- 递归开销:归并排序采用了递归的方式实现,递归调用会带来一定的函数调用开销,不过在大多数编程语言中,这种开销通常可以忽略不计。
六、应用场景
归并排序在实际应用中有着广泛的应用,例如:
- 外部排序:当数据量非常大,无法全部装入内存时,可以使用归并排序的思想进行外部排序。将数据分成多个块,分别在内存中进行排序,然后再将这些有序的块合并起来。
- 数据库排序:在数据库系统中,经常需要对大量的数据进行排序操作,归并排序的高效性和稳定性使其成为一种常用的排序算法。
- 并行计算:在并行计算环境中,归并排序可以很容易地实现并行化,充分利用多核处理器的计算能力,提高排序速度。
七、总结
归并排序以其简洁的分治思想和高效稳定的排序性能,在算法领域中占据着重要的地位。虽然它存在一定的空间复杂度问题,但在处理大规模数据和对稳定性有要求的场景下,归并排序无疑是一种非常优秀的选择。通过深入理解归并排序的原理和实现,我们不仅可以掌握一种实用的排序算法,还能从中体会到分治策略的强大魅力。希望这篇文章能帮助你更好地理解和应用归并排序算法。
以上就是关于归并排序的详细介绍,如果你对算法感兴趣,不妨自己动手实现一下归并排序,并尝试对它进行优化和改进,相信你会有更多的收获!

![[模型部署] 3. 性能优化](https://i-blog.csdnimg.cn/blog_migrate/tags/671f42ab07fd990f949a1c903140dd83.png#pic_center)