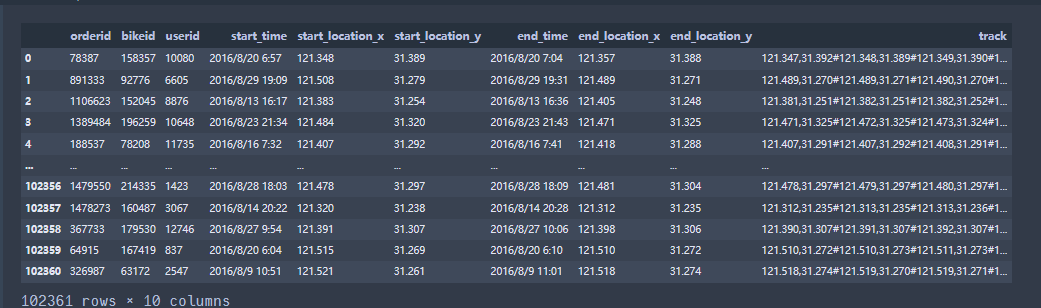
数据初始样貌

一、数据预处理
1. 数据每5分钟栅格统计
- 时间数据的处理
path="mobike_shanghai.csv"
df=pd.read_csv(path)
# 获取时间信息,对于分钟信息,5分钟取整
def time_info(df,col):
df['datetime'] = pd.to_datetime(df[col])
df['week'] = df.datetime.dt.dayofweek
df['date'] = df.datetime.dt.date
df['hour'] = df.datetime.dt.hour
df["minute"]=df.datetime.dt.minute
df["minute"]=df["minute"].apply(lambda x :ceil_5(x) ) #对时间5分钟取整
return df[["week","date","hour","minute"]]
- 筛选数据:位置,时间,类型。
每一条信息,根据起点的(位置,时间)和终点(位置,时间)划分为2条信息了。
#筛选起点信息
df1=time_info(df,"start_time")
dfs=df[["start_location_x","start_location_y"]]
dfs.columns=["x","y"]
dfs=pd.concat([dfs,df1],axis=1)
dfs["type"]=1
# 筛选终点信息
df1=time_info(df,"end_time")
dfe=df[["end_location_x","end_location_y"]]
dfe.columns=["x","y"]
dfe=pd.concat([dfe,df1],axis=1)
dfe["type"]=0
# 两组信息合并
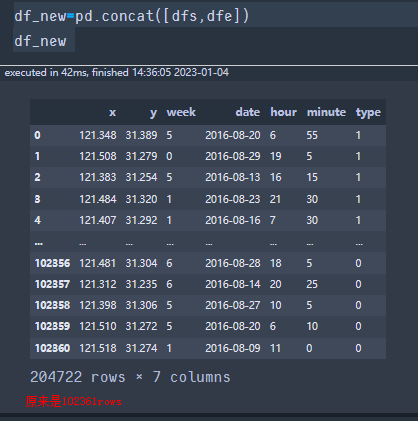
df_new=pd.concat([dfs,dfe])
df_new
2. 经纬度匹配
- 定义网格。确定经纬度的最大范围。确定网格的形状。
12,13,14,15,16,17
06,07,08,09,10,11
00,01,02,03,04,05, - 查看相关信息
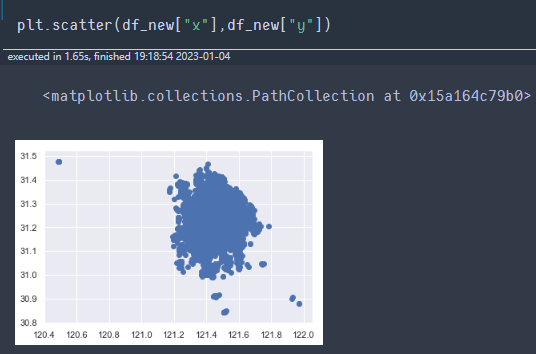
删除距离过远的点。
df_new.reset_index(drop=True,inplace=True) # 重置索引
in1=df_new[df_new["x"]<121.0].index.tolist()
in2=df_new[df_new["y"]<30.95].index.tolist()
indexes=in1+in2 #删除外部的数据
for idx in indexes:
df_new.drop(idx,inplace=True) #删除外部的数据
df_new.reset_index(drop=True,inplace=True) #再次重置索引
删除异常点。
# 获取 区域的极限经纬度
East=df_new["x"].max()
West=df_new["x"].min()
North=df_new["y"].max()
South=df_new["y"].min()
print(East,West,North,South)
# 因为地理位置已经脱敏,所以不是连续型数据。查看多少个地理点。
print(len(set(df_new["x"])) ,len(set(df_new["y"])) )
# 计算区域内的最长距离,平均每个网格的距离为500米。并预估网格个数。
from geopy.distance import geodesic
distance = geodesic((South,West), (North,East)).m #geodesic #计算对角线距离
print(distance/500)
distance = geodesic((South,West), (North,West)).m #geodesic #计算南北距离
print(distance/500)
distance = geodesic((South,West), (South,East)).m #geodesic #计算东西距离
print(distance/500)
out:
121.785 121.172 31.468 30.989
495 441
157.87945410409293
106.21671999130861
117.1015158394339
确定,南北划分100,东西划分120.
- 获取每个loc的id号。
########定义获取id号的函数
d_x=(East-West)/100 #东西的经度间隔
d_y=(North-South)/100 #南北的维度间隔
def get_label(x,y):
i=min(int((x-West)/d_x),99)
j=min(int((y-South)/d_y),99)
ID=j*100+i
return ID
########
df_new["id"] =df_new[["x","y"]].apply(lambda x :get_label(x["x"],x["y"]),axis=1)
print(df_new.id.min(),df_new.id.max())
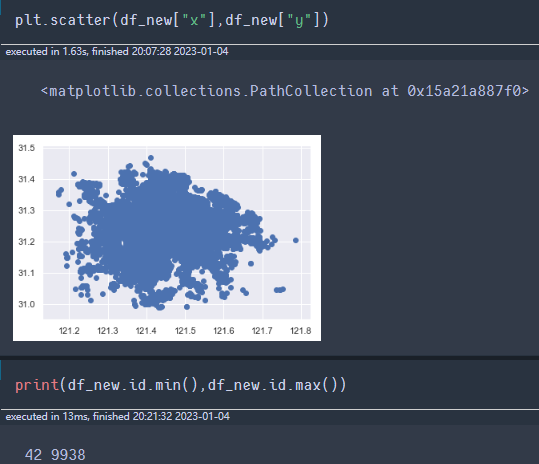
idxes=sorted(set(df_new.id.tolist()) ) #id号取独(),再从小到大排序
id_dict={idxes[k]:k for k in range(len(idxes))} #将索引和网格号对应起来。
#因为网格号的最小值为42,最大值为9938.且共3289个网格。因此可以将索引代表node的id
df_new["id"] =df_new["id"].apply(lambda x :id_dict[x])
3. 根据id号,type, hour合并数据。
- 筛选一周的数据。
df_new['Date']=df_new['date'].apply(lambda x: str(x))
df2= df_new.query("Date<='2016-08-19'& Date>='2016-08-13' ")
df2.reset_index(drop=True,inplace=True) # 重置索引
- 按照
"Date","hour","type","id"统计数据。虽然按照dict的方式比较慢。但是比较准确。主要是分组的方式,我不太会。
### 按关键词统计数据
a =defaultdict(lambda:0)
for i in range(df2.shape[0]):
D =df2.loc[i]["Date"]
H =df2.loc[i]["hour"]
T =df2.loc[i]["type"]
ID =df_new.loc[i]["id"]
a[D,H,T,ID] +=1
### 生成新的数据
DF =pd.DataFrame(columns=["Date","hour","type","id","flow"])
i =0
for key in a.keys():
D,H,T,ID =key
DF.loc[i]=[D,H,T,ID,a[key]]
i +=1
#### id号的loc位置的获取
Loc=df_new.groupby(["id"])[["x","y"]].mean()
####拼接数据
DF1 = pd.merge(DF, Loc, how = 'left',left_on="id",right_on="id")
## DF1.isnull().sum() #验证拼接结果没有空值null
- 数据的排序
## flow分为正负性
DF1["Flow"]=DF1[["type","flow"]].apply(lambda x :get_flow(x["type"],x["flow"]),axis=1)
## 数据排序和删除无用序列
DF1.sort_values(by=["Date","hour","id"],ascending=False,inplace=True)
DF1.reset_index(drop=True,inplace=True) # 重置索引
del DF1["type"]
附录:case数据改为取送问题。
- 原数据形状
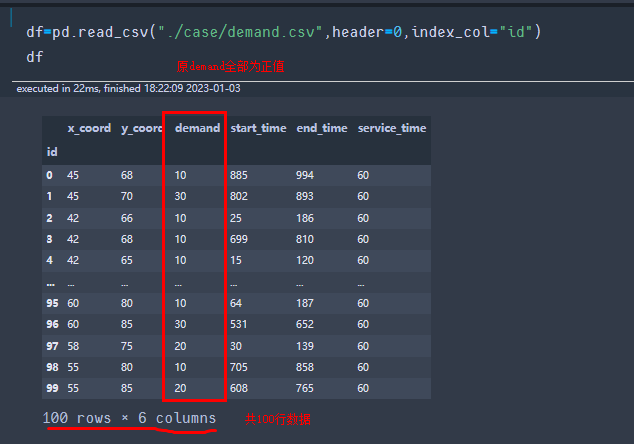
- 对100行数据,重新赋值。使得 ∑ i = 0 99 d i = 0 \sum_{i=0}^{99} d_i=0 ∑i=099di=0, ∑ i ∈ S d i = 900 = − ∑ j ∈ E d j \sum_{i\in S}d_i=900=-\sum_{j\in E}d_j ∑i∈Sdi=900=−∑j∈Edj. S是pick-up集合。E是drop-out集合。
2.1)在(40-60)之间随机选择一个数字c。划分两个集合S和E.
∣
S
∣
=
c
|S|=c
∣S∣=c,
∣
E
∣
=
100
−
c
|E|=100-c
∣E∣=100−c
2.2) 分别构造集合S和E的id索引a和b。
a=random.sample(range(100),random.randint(40,60))
b=set(range(100))-set(a)
b =list(b)
2.3) 将900随机分配为 ∣ S ∣ = c |S|=c ∣S∣=c个数。将-900随机分配到 ∣ E ∣ = 100 − c |E|=100-c ∣E∣=100−c个数。并保证0不会出现,且不会出现超过45的值(值太大的话,会导致局部出现小数字的情况)。
def choise(s,n):
men=min(45,s-10*n)
p =random.choice(range(1,men))
return s-p,p
A=[]
n=56
s=900
for i in range(n,1,-1):
s,p=choise(s,i)
A.append(p)
A.append(900-np.sum(A))
B=[]
n=44
s=900
for i in range(n,1,-1):
s,p=choise(s,i)
B.append(p)
B.append(900-np.sum(B))
2.4) 检查A,B中没有特别大的数字。否则再一次随机。
2.5)构造索引和数值之间的对应的关系,用dict表示。
demand={}
for i in range(56):
demand[a[i]]=A[i]
for j in range(44):
demand[b[j]]=-B[j]
2.6)按照索引排序,然后获得整体的demand.并赋值给原DataFrame.然后保存。
de=[demand[k] for k in sorted(demand.keys())]
df["demand"]=de
df.to_csv("./case/demand1.csv")
2.7)查看修改后的结果。demand的正负值交错,非常不错。
3. 因为对需求值重新赋值过了。我们的车辆的一条最短的轨迹必为:depot-start
t
o
to
to 起点
→
\to
→ 终点
→
\to
→ depot-end.所以,我们要求服务的时间窗口不能太小。因次我们对小的窗口进行松弛。
for i in range(100):
if df.loc[i]["end_time"]-df.loc[i]["start_time"] < 150:
a=random.choice(range(40,60))
df.loc[i]["end_time"] =min(1000,df.loc[i]["end_time"]+a)
df.loc[i]["start_time"] = max(0,df.loc[i]["start_time"]-a)