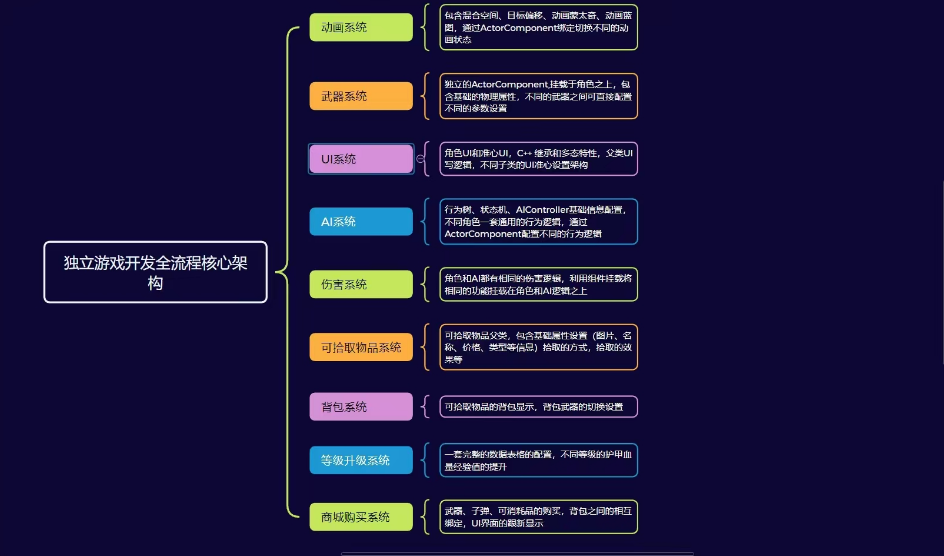
好的!为了更清楚地说明`flattened`类型在查询嵌套数组时可能返回不准确结果的情况,我们可以通过一个具体的例子来展示。这个例子将展示如何在文档中没有完全匹配的嵌套对象时,`flattened`类型仍然可能返回该文档。
示例文档结构
假设你有以下文档结构,其中`addresses`是一个嵌套数组:
```json
PUT /my_index/_doc/1
{
"user": {
"id": 1,
"name": "John Doe",
"addresses": [
{
"street": "123 Main St",
"city": "Anytown",
"state": "NY" // 注意这里 state 是 NY,而不是 CA
},
{
"street": "456 Elm St",
"city": "Othertown",
"state": "CA" // 注意这里 city 是 Othertown,而不是 Anytown
}
]
}
}
```
在这个文档中,`addresses`数组包含两个地址对象:
1. 第一个地址对象的`city`是`"Anytown"`,但`state`是`"NY"`。
2. 第二个地址对象的`state`是`"CA"`,但`city`是`"Othertown"`。
查询示例
假设你希望查询所有`city`为`"Anytown"`且`state`为`"CA"`的地址。如果`addresses`字段被定义为`flattened`类型,你可能会写出以下查询:
```json
GET /my_index/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"user.addresses.city": {
"value": "Anytown"
}
}
},
{
"term": {
"user.addresses.state": {
"value": "CA"
}
}
}
]
}
}
}
```
查询结果
由于`flattened`类型会将嵌套结构展开为多个字段路径,Elasticsearch 无法保证`city`和`state`属于同一个嵌套对象。因此,查询可能会返回不准确的结果。
在上面的例子中,`flattened`类型会将`addresses`展开为以下字段路径:
```json
{
"user.addresses.street.0": "123 Main St",
"user.addresses.city.0": "Anytown",
"user.addresses.state.0": "NY",
"user.addresses.street.1": "456 Elm St",
"user.addresses.city.1": "Othertown",
"user.addresses.state.1": "CA"
}
```
当你执行查询时,Elasticsearch 会分别匹配`city`和`state`,但无法保证它们属于同一个嵌套对象。因此,查询可能会返回包含以下内容的文档:
```json
{
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"user": {
"id": 1,
"name": "John Doe",
"addresses": [
{
"street": "123 Main St",
"city": "Anytown",
"state": "NY"
},
{
"street": "456 Elm St",
"city": "Othertown",
"state": "CA"
}
]
}
}
}
]
}
}
```
问题解释
尽管文档中没有完全匹配`city`为`"Anytown"`且`state`为`"CA"`的地址对象,但查询仍然返回了该文档。这是因为`flattened`类型无法保证`city`和`state`属于同一个嵌套对象。具体来说:
• 第一个地址对象的`city`是`"Anytown"`,但`state`是`"NY"`。
• 第二个地址对象的`state`是`"CA"`,但`city`是`"Othertown"`。
由于`flattened`类型将这些字段路径展开后,Elasticsearch 会分别匹配`city`和`state`,而不会检查它们是否属于同一个嵌套对象。因此,只要文档中存在满足条件的字段路径,即使这些字段路径不属于同一个嵌套对象,查询也会返回该文档。
使用`nested`类型的正确结果
如果`addresses`字段被定义为`nested`类型,查询会正确地返回没有匹配结果的情况:
```json
PUT /my_index
{
"mappings": {
"properties": {
"user": {
"properties": {
"id": { "type": "integer" },
"name": { "type": "text" },
"addresses": { "type": "nested" }
}
}
}
}
}
```
查询:
```json
GET /my_index/_search
{
"query": {
"nested": {
"path": "user.addresses",
"query": {
"bool": {
"must": [
{
"term": {
"user.addresses.city": {
"value": "Anytown"
}
}
},
{
"term": {
"user.addresses.state": {
"value": "CA"
}
}
}
]
}
}
}
}
}
```
返回结果:
```json
{
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
```
`nested`类型会正确地检查每个嵌套对象的完整性,因此不会返回不匹配的文档。
总结
• `flattened`类型的限制:`flattened`类型会将嵌套结构展开为多个字段路径,无法保证这些字段属于同一个嵌套对象。因此,在查询时可能会返回不准确的结果。
• `nested`类型的优势:`nested`类型可以保持嵌套对象的完整性,支持复杂的嵌套查询,能够精确匹配嵌套结构。
希望这个例子清楚地展示了`flattened`类型在查询嵌套数组时可能返回不准确结果的情况。
这里`flattened`类型在处理嵌套对象时出现不准确结果的问题,主要是因为嵌套对象是列表(数组)结构。当嵌套对象是数组时,`flattened`类型会将数组中的每个对象展开为多个字段路径,而这些字段路径之间没有关联关系,因此无法保证它们属于同一个嵌套对象。
为什么`flattened`类型在数组结构中会出现问题?
当嵌套对象是数组时,`flattened`类型会将数组中的每个对象的字段路径展开为独立的字段。例如,假设你有以下文档结构:
```json
{
"user": {
"id": 1,
"name": "John Doe",
"addresses": [
{
"street": "123 Main St",
"city": "Anytown",
"state": "NY"
},
{
"street": "456 Elm St",
"city": "Othertown",
"state": "CA"
}
]
}
}
```
如果`addresses`字段被定义为`flattened`类型,Elasticsearch 会将`addresses`展开为以下字段路径:
```json
{
"user.addresses.street.0": "123 Main St",
"user.addresses.city.0": "Anytown",
"user.addresses.state.0": "NY",
"user.addresses.street.1": "456 Elm St",
"user.addresses.city.1": "Othertown",
"user.addresses.state.1": "CA"
}
```
当你执行查询时,Elasticsearch 会分别匹配这些字段路径,但无法保证它们属于同一个嵌套对象。因此,查询可能会返回不准确的结果。
示例:`flattened`类型在数组结构中的问题
假设你希望查询所有`city`为`"Anytown"`且`state`为`"CA"`的地址。如果`addresses`字段被定义为`flattened`类型,你可能会写出以下查询:
```json
GET /my_index/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"user.addresses.city": {
"value": "Anytown"
}
}
},
{
"term": {
"user.addresses.state": {
"value": "CA"
}
}
}
]
}
}
}
```
由于`flattened`类型将数组中的每个对象的字段路径展开为独立的字段,Elasticsearch 会分别匹配`city`和`state`,但无法保证它们属于同一个嵌套对象。因此,查询可能会返回包含以下内容的文档:
```json
{
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"user": {
"id": 1,
"name": "John Doe",
"addresses": [
{
"street": "123 Main St",
"city": "Anytown",
"state": "NY"
},
{
"street": "456 Elm St",
"city": "Othertown",
"state": "CA"
}
]
}
}
}
]
}
}
```
尽管文档中没有完全匹配`city`为`"Anytown"`且`state`为`"CA"`的地址对象,但查询仍然返回了该文档。这是因为`flattened`类型无法保证`city`和`state`属于同一个嵌套对象。
如果嵌套对象不是数组结构呢?
如果嵌套对象不是数组结构,`flattened`类型通常不会出现这种问题。例如,假设你有以下文档结构:
```json
{
"user": {
"id": 1,
"name": "John Doe",
"address": {
"street": "123 Main St",
"city": "Anytown",
"state": "CA"
}
}
}
```
在这种情况下,`address`是一个嵌套对象,而不是数组。如果`address`字段被定义为`flattened`类型,Elasticsearch 会将`address`展开为以下字段路径:
```json
{
"user.address.street": "123 Main St",
"user.address.city": "Anytown",
"user.address.state": "CA"
}
```
当你执行查询时,Elasticsearch 会匹配这些字段路径,而这些字段路径属于同一个嵌套对象,因此不会出现不准确的结果。
示例:`flattened`类型在非数组结构中的表现
假设你希望查询所有`city`为`"Anytown"`且`state`为`"CA"`的地址。如果`address`字段被定义为`flattened`类型,你可能会写出以下查询:
```json
GET /my_index/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"user.address.city": {
"value": "Anytown"
}
}
},
{
"term": {
"user.address.state": {
"value": "CA"
}
}
}
]
}
}
}
```
返回结果:
```json
{
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"user": {
"id": 1,
"name": "John Doe",
"address": {
"street": "123 Main St",
"city": "Anytown",
"state": "CA"
}
}
}
}
]
}
}
```
在这种情况下,`flattened`类型可以正确匹配`city`和`state`,因为它们属于同一个嵌套对象。
总结
• `flattened`类型在数组结构中的问题:
• 当嵌套对象是数组时,`flattened`类型会将数组中的每个对象的字段路径展开为独立的字段。
• Elasticsearch 无法保证这些字段路径属于同一个嵌套对象,因此查询可能会返回不准确的结果。
• `flattened`类型在非数组结构中的表现:
• 当嵌套对象不是数组时,`flattened`类型可以正确匹配字段路径,因为这些字段路径属于同一个嵌套对象。
• 查询结果通常是准确的。
因此,`flattened`类型在处理嵌套数组时需要特别小心,而`nested`类型在这种场景下通常是更好的选择,因为它可以保持嵌套对象的完整性并支持复杂的嵌套查询。