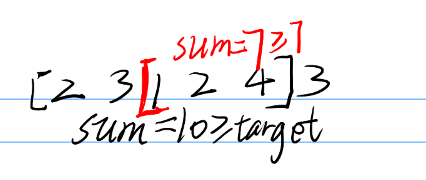目录
Spark DAG 和宽窄依赖的核心
一、什么是 DAG?
示例:WordCount 程序的 DAG
二、宽依赖与窄依赖
1. 窄依赖
2. 宽依赖
三、DAG 与宽窄依赖的性能优化
1. 减少 Shuffle 操作
2. 合理划分 Stage
3. 使用缓存机制
四、实际案例分析:同行车判断
五、总结
Spark DAG 和宽窄依赖的核心
Apache Spark 是当前主流的大数据处理框架之一,其高效的内存计算和灵活的编程模型使其在大数据处理领域占据重要地位。在 Spark 的核心架构中,DAG(有向无环图)和宽窄依赖是关键概念,直接影响任务的执行效率和性能优化策略。本文将深入解析这两个概念,并结合实际案例和图示,帮助读者更好地理解和应用。
一、什么是 DAG?
DAG,全称 Directed Acyclic Graph(有向无环图),在 Spark 中用于表示 RDD(弹性分布式数据集)之间的依赖关系。每个节点代表一个 RDD,边表示 RDD 之间的转换操作。Spark 通过构建 DAG 来规划任务的执行路径,从而实现高效的任务调度和容错机制。