向量数据库是一种特殊类型的数据库,在 AI 应用中发挥着至关重要的作用。
在向量数据库中,查询与传统关系型数据库不同。它们执行的是相似性搜索,而非精确匹配。当给定一个向量作为查询时,向量数据库会返回与该查询向量“相似”的向量。
Spring AI 通过 VectorStore 接口提供了一个抽象的 API,用于与向量数据库交互。
VectorStore接口中主要方法:
public interface VectorStore extends DocumentWriter {
default String getName() {
return this.getClass().getSimpleName();
}
// 向向量数据库写入数据
void add(List<Document> documents);
// 根据id删除数据
void delete(List<String> idList);
// 根据过滤表达式删除数据
void delete(Filter.Expression filterExpression);
default void delete(String filterExpression) { ... };
// 进行相似度搜索
List<Document> similaritySearch(String query);
List<Document> similaritySearch(SearchRequest request);
default <T> Optional<T> getNativeClient() {
return Optional.empty();
}
}支持的向量数据库:
- Azure Vector Search
- Apache Cassandra
- Chroma Vector Store
- Elasticsearch Vector Store
- GemFire Vector Store
- MariaDB Vector Store
- Milvus Vector Store
- MongoDB Atlas Vector Store
- Neo4j Vector Store
- OpenSearch Vector Store
- Oracle Vector Store
- PgVector Store
- Pinecone Vector Store
- Qdrant Vector Store
- Redis Vector Store
- SAP Hana Vector Store
- Typesense Vector Store
- Weaviate Vector Store
- SimpleVectorStore - 一个简单的持久化向量存储实现,适合教学目的。
SimpleVectorStore使用
注意:需要提前启动上篇博客中通过Ollama安装的嵌入模型
SimpleVectorStore将向量数据存储在内存中。
导入jar
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-vector-store</artifactId>
</dependency>创建SimpleVectorStore对象
@Bean
public SimpleVectorStore vectorStore() {
return SimpleVectorStore.builder(embeddingModel).build();
}创建对象时,将存储对象和嵌入模型进行关联。关于嵌入模型的使用,参考:
Spring AI(5)——通过嵌入模型进行数据的向量化处理-CSDN博客
向SimpleVectorStore对象中写入测试数据
本例中,创建Document对象时,三个参数分别为:文档id,文档内容,文档的元数据。
@PostConstruct
public void init() {
List<Document> documents = List.of(
new Document("1", "今天天气不错", Map.of("country", "郑州", "date", "2025-05-13")),
new Document("2", "天气不错,适合旅游", Map.of("country", "开封", "date", "2025-05-15")),
new Document("3", "去哪里旅游好呢", Map.of("country", "洛阳", "date", "2025-05-15")));
// 存储数据
simpleVectorStore.add(documents);
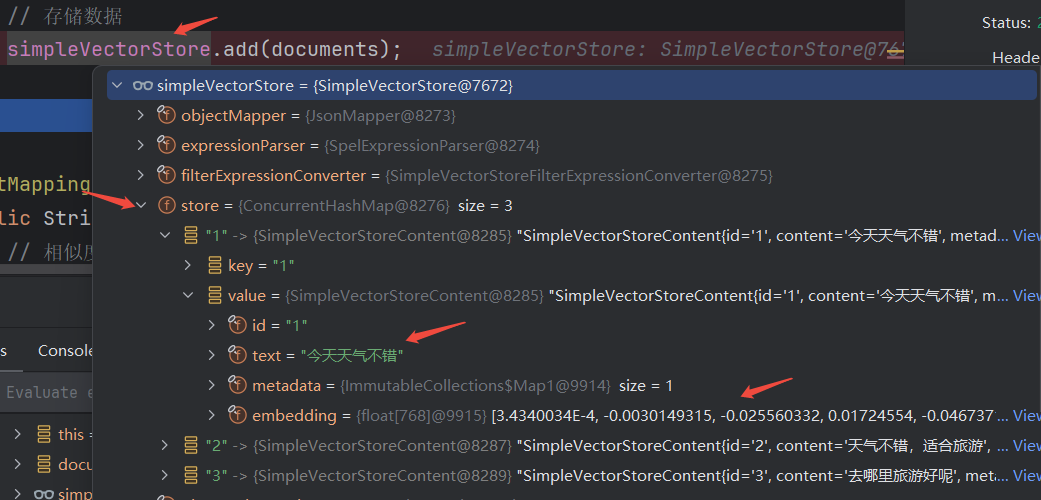
}通过调试可以看出, SimpleVectorStore对象中存储的原始文档信息和向量化后的数据。
进行相似度搜索
根据字符串内容进行搜索
@GetMapping("/store")
public String store(String message) {
// 相似度检索
List<Document> list= simpleVectorStore.similaritySearch("旅游");
System.out.println(list.size());
System.out.println(list.get(0).getText());
return "success";
}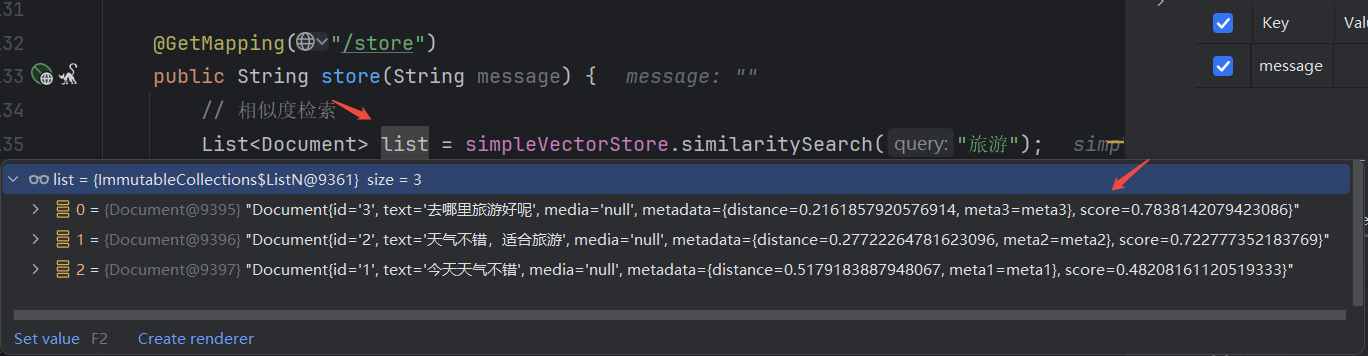
通过调试可以看到,对所有的数据进行向量的相似度计算,并进行打分,计算结果按照score的降序排列 。
根据元数据过滤器进行搜索
使用字符串设置搜索条件
例如:
-
"country == 'BG'" -
"genre == 'drama' && year >= 2020" -
"genre in ['comedy', 'documentary', 'drama']"
SearchRequest request = SearchRequest.builder()
.query("World")
.filterExpression("country == 'Bulgaria'")
.build();使用Filter.Expression设置搜索条件
可以使用 FilterExpressionBuilder 创建 Filter.Expression 的实例。一个简单的示例如下:
FilterExpressionBuilder b = new FilterExpressionBuilder();
Expression expression = this.b.eq("country", "BG").build();可以使用以下运算符构建复杂的表达式:
EQUALS: '=='
MINUS : '-'
PLUS: '+'
GT: '>'
GE: '>='
LT: '<'
LE: '<='
NE: '!='可以使用以下运算符组合表达式:
AND: 'AND' | 'and' | '&&';
OR: 'OR' | 'or' | '||';参考示例:
Expression exp = b.and(b.eq("genre", "drama"), b.gte("year", 2020)).build();还可以使用以下运算符:
IN: 'IN' | 'in';
NIN: 'NIN' | 'nin';
NOT: 'NOT' | 'not';参考示例:
Expression exp = b.and(b.in("genre", "drama", "documentary"), b.not(b.lt("year", 2020))).build();测试案例:
@GetMapping("/store")
public String store(String message) {
// 相似度检索
// List<Document> list = simpleVectorStore.similaritySearch("旅游");
// 创建过滤器对象
FilterExpressionBuilder b = new FilterExpressionBuilder();
Filter.Expression filter = b.eq("country", "郑州").build();
// Filter.Expression filter = b.and(b.eq("country", "郑州"), b.gte("date", "2025-05-15")).build();;
// 创建搜索对象
SearchRequest request = SearchRequest.builder()
.query("旅游") // 搜索内容
.filterExpression(filter) // 指定过滤器对象
.build();
List<Document> list = simpleVectorStore.similaritySearch(request);
System.out.println(list.size());
System.out.println(list.get(0).getText());
return "success";
}删除数据
@GetMapping("/store2")
public String store2(String message) {
// 删除数据
simpleVectorStore.delete(List.of("3"));
return "success";
}注意:也可以根据元数据过滤器进行删除,本文不再演示
Milvus进行向量存储
关于milvus的介绍和环境安装,参考:
LangChain4j(16)——使用milvus进行向量存储-CSDN博客
注意:需要提前启动上篇博客中通过Ollama安装的嵌入模型
导入jar
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-milvus</artifactId>
</dependency>yml配置
在原来的基础上,增加如下配置:
spring:
ai:
vectorstore:
milvus:
client:
host: "localhost"
port: 19530
databaseName: "myai"
collectionName: "vector_store"
embeddingDimension: 768
indexType: IVF_FLAT
metricType: COSINE
该配置中指定了milvus的数据库名,collection名称,向量纬度,索引的类型,向量搜索的算法等,更多的属性设置可以参考官网:
| 属性 | 描述 | 默认值 |
|---|---|---|
| spring.ai.vectorstore.milvus.database-name | 要使用的 Milvus 数据库名称。 | default |
| spring.ai.vectorstore.milvus.collection-name | 用于存储向量的 Milvus Collection 名称 | vector_store |
| spring.ai.vectorstore.milvus.initialize-schema | 是否初始化 Milvus 后端 | false |
| spring.ai.vectorstore.milvus.embedding-dimension | 存储在 Milvus Collection 中的向量维度。 | 1536 |
| spring.ai.vectorstore.milvus.index-type | 为 Milvus Collection 创建的索引类型。 | IVF_FLAT |
| spring.ai.vectorstore.milvus.metric-type | 用于 Milvus Collection 的度量类型(Metric Type)。 | COSINE |
| spring.ai.vectorstore.milvus.index-parameters | 用于 Milvus Collection 的索引参数。 | {"nlist":1024} |
| spring.ai.vectorstore.milvus.id-field-name | Collection 的 ID 字段名称 | doc_id |
| spring.ai.vectorstore.milvus.is-auto-id | 布尔标志,指示 ID 字段是否使用 auto-id | false |
| spring.ai.vectorstore.milvus.content-field-name | Collection 的内容字段名称 | content |
| spring.ai.vectorstore.milvus.metadata-field-name | Collection 的元数据字段名称 | metadata |
| spring.ai.vectorstore.milvus.embedding-field-name | Collection 的嵌入字段名称 | embedding |
| spring.ai.vectorstore.milvus.client.host | 主机名称或地址。 | localhost |
| spring.ai.vectorstore.milvus.client.port | 连接端口。 | 19530 |
| spring.ai.vectorstore.milvus.client.uri | Milvus 实例的 URI | - |
| spring.ai.vectorstore.milvus.client.token | 用作身份识别和认证目的的 Token。 | - |
| spring.ai.vectorstore.milvus.client.connect-timeout-ms | 客户端通道的连接超时值。超时值必须大于零。 | 10000 |
| spring.ai.vectorstore.milvus.client.keep-alive-time-ms | 客户端通道的 Keep-alive 时间值。Keep-alive 值必须大于零。 | 55000 |
| spring.ai.vectorstore.milvus.client.keep-alive-timeout-ms | 客户端通道的 Keep-alive 超时值。超时值必须大于零。 | 20000 |
| spring.ai.vectorstore.milvus.client.rpc-deadline-ms | 愿意等待服务器回复的截止时间。设置截止时间后,客户端在遇到由网络波动引起的快速 RPC 失败时将等待。截止时间值必须大于或等于零。 | 0 |
| spring.ai.vectorstore.milvus.client.client-key-path | 用于 TLS 双向认证的 client.key 路径,仅当 "secure" 为 true 时生效 | - |
| spring.ai.vectorstore.milvus.client.client-pem-path | 用于 TLS 双向认证的 client.pem 路径,仅当 "secure" 为 true 时生效 | - |
| spring.ai.vectorstore.milvus.client.ca-pem-path | 用于 TLS 双向认证的 ca.pem 路径,仅当 "secure" 为 true 时生效 | - |
| spring.ai.vectorstore.milvus.client.server-pem-path | 用于 TLS 单向认证的 server.pem 路径,仅当 "secure" 为 true 时生效。 | - |
| spring.ai.vectorstore.milvus.client.server-name | 设置 SSL 主机名检查的目标名称覆盖,仅当 "secure" 为 True 时生效。注意:此值会传递给 grpc.ssl_target_name_override | - |
| spring.ai.vectorstore.milvus.client.secure | 保护此连接的授权,设置为 True 以启用 TLS。 | false |
| spring.ai.vectorstore.milvus.client.idle-timeout-ms | 客户端通道的空闲超时值。超时值必须大于零。 | 24h |
| spring.ai.vectorstore.milvus.client.username | 此连接的用户名和密码。 | root |
| spring.ai.vectorstore.milvus.client.password | 此连接的密码。 | milvus |
通过attu创建collection
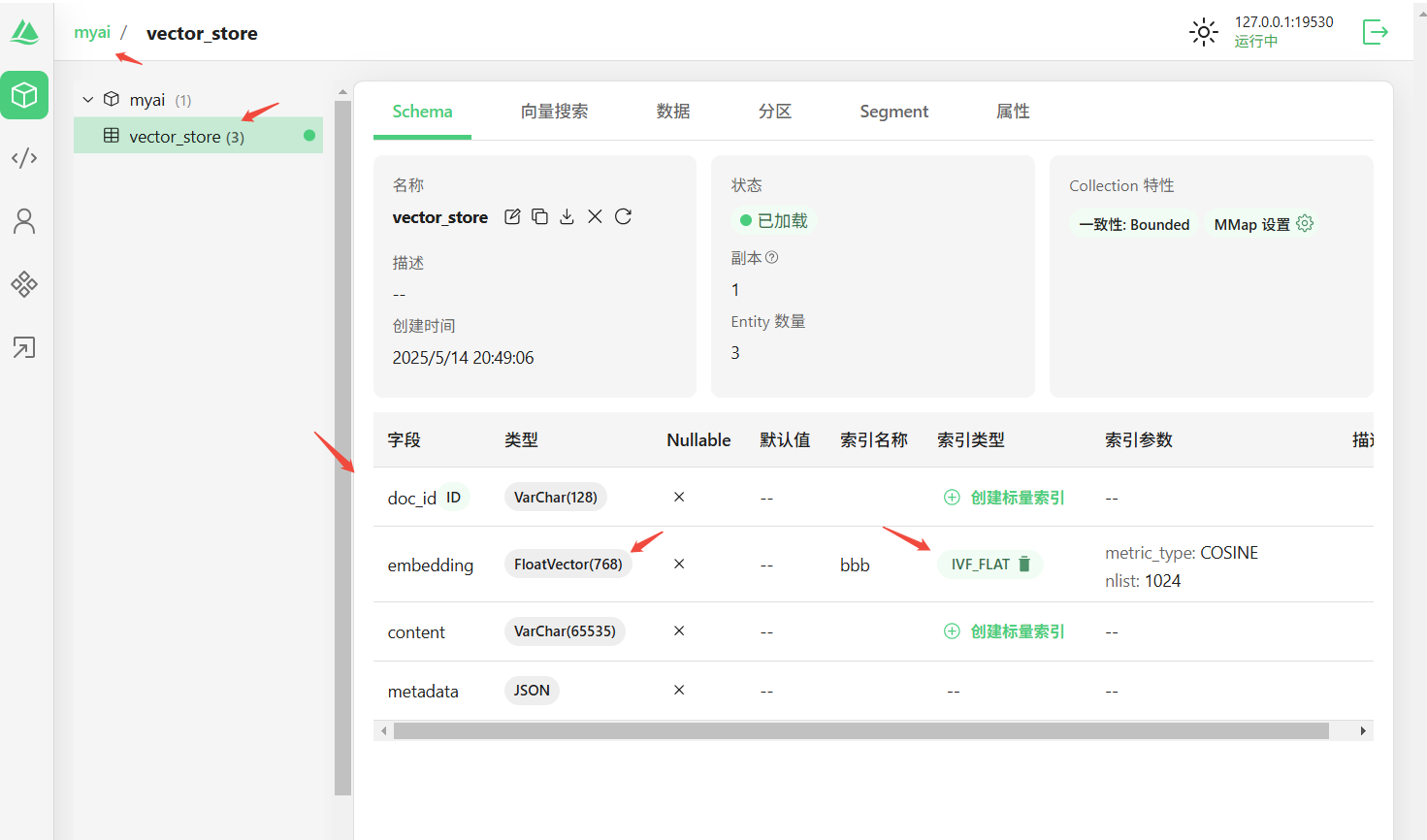
注意:collection中的字段名称使用的是上面属性中的默认名称:
spring.ai.vectorstore.milvus.id-field-name=doc_id
spring.ai.vectorstore.milvus.content-field-name=content
spring.ai.vectorstore.milvus.metadata-field-name=metadata
spring.ai.vectorstore.milvus.embedding-field-name=embedding
注入MilvusVectorStore对象
@Resource
private MilvusVectorStore milvusVectorStore;添加测试数据
@PostConstruct
public void init() {
List<Document> documents = List.of(
new Document("今天天气不错", Map.of("country", "郑州", "date", "2025-05-13")),
new Document("天气不错,适合旅游", Map.of("country", "开封", "date", "2025-05-15")),
new Document("去哪里旅游好呢", Map.of("country", "洛阳", "date", "2025-05-15")));
// 存储数据
milvusVectorStore.add(documents);
}本例没有指定Document的id,id会随机生成
相似度搜索
@GetMapping("/search")
public String search(String message) {
// 相似度检索
List<Document> list = milvusVectorStore.similaritySearch("旅游");
System.out.println(list.size());
System.out.println(list.get(0).getText());
return "success";
}
@GetMapping("/search5")
public String search5(String message) {
MilvusSearchRequest request = MilvusSearchRequest.milvusBuilder()
.query("旅游")
.topK(5)
.similarityThreshold(0.7)
.filterExpression("date == '2025-05-15'") // Ignored if nativeExpression is set
//.searchParamsJson("{\"nprobe\":128}")
.build();
// 相似度检索
List<Document> list = milvusVectorStore.similaritySearch(request);
System.out.println(list.size());
System.out.println(list.get(0).getText());
return "success";
}top_k: 表示根据token排名,只考虑前k个token
similarity threshold:相似度的阈值