本文是实验设计与分析(第6版,Montgomery著傅珏生译)第4章随机化区组,拉丁方,以及有关的设计第4.2节的python解决方案。本文尽量避免重复书中的理论,着于提供python解决方案,并与原书的运算结果进行对比。您可以从Detail 下载实验设计与分析(第6版,Montgomery著傅珏生译)电子版。本文假定您已具备python基础,如果您还没有python的基础,可以从Detail 下载相关资料进行学习。
4.1节介绍了随机化完全区组设计,这一设计可以减少由一个已知的可控制的讨厌变量的变异性所引起的实验残差。还有很多其他类型的利用区组化原理的设计。例如,实验者研究用在机组人员数生系统中的火箭推进剂的5种不同配方关于燃烧率的效应。每种配方都取自一批仅仅够配成5份供试验用的配方的原料。而且,这些配方是由几个操作人员准备的,这些操作人员在实验技能和经验上可能有实质性的差别。这样一来,在设计中看来会有两个讨厌因子需要被“平均出来”:原料的批次和操作人员。这一问题的合适设计应是对每批原料的每种配方恰好试验次,而且对于每种配方,5名操作人员每人恰好试验一次。设计的结果如表4.8所示,称为拉丁方设计(Latin square design)。这一设计是按正方形排列的,5种配方(或处理)用拉丁字母A,B,C,D,E表示,因而叫做拉丁方。原料的批次(行)与操作人员(列)对于处理是正交的。

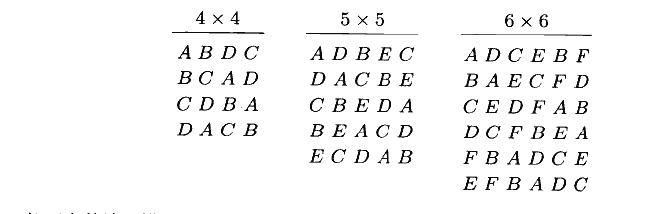
拉丁方设计用来消除两个讨厌的变异性来源,也就是说,它允许从两个方向来系统地区组化。这样一来,行和列实际上就表示了两种随机化约束。一般说来,一个p因子的拉丁方或P×P拉丁方,是一个含有p行和P列的方形。p2个单元中的每一个单元含有与处理对应的n个字母之一,每一字母在每行每列中恰好出现一次,一些拉丁方的例子如
方差分析计算方法中的处理、行以及列之和如表4.9所示。从平方和的计算公式可以有出,这一分析只是随机化完全区组设计的简单延伸,其中源于行因子的平方和是用那些行和得到的。

例4.3考虑前面的火箭推进剂问题,其中原料的批次与操作人员都代表随机化约束。这一实验设计如表4.8所示,是一个5×5拉丁方。

现将每个观测值减25得如表4.10所示的规范值。总平方和、批次(行)平方和,操作人员(列)平方和算得如下:
![]()
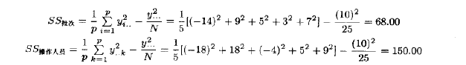
处理(拉丁字母)的总和是
![]()
由这些总和算得配方的平方和为
![]()
相减得误差的平方和:
![]()
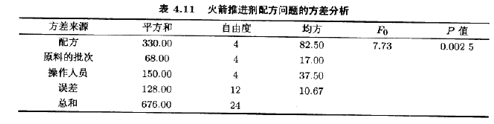
方差分析见表4.11。结论是,不同的火箭推进剂配方所产生的燃烧率有显著性差异,方差分析还表明操作人员之间亦有差异,因此,关于该因子的区组化的确是一个好的预防措施。没有强有力的证据证明原料的批次间存在差异,所以,在这一实验中,看来不的关心这一变异性来源。不过,对原料的批次区组化通常是一个好的主意。
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.formula.api as smf
import pandas as pd
import statsmodels.api as sm
from sklearn import linear_model
import seaborn as sns
import matplotlib.pyplot as plt
import mistat
y = [-1,-8,-7,1,-3,-5,-1,13,6,5,-6,5,1,1,-5,-1,2,2,-2,4,-1,11,-4,-3,6]
x1 = [1,2,3,4,5, 1,2,3,4,5, 1,2,3,4,5, 1,2,3,4,5, 1,2,3,4,5]
x2 =[1,1,1,1,1,2,2,2,2,2,3,3,3,3,3,4,4,4,4,4,5,5,5,5,5]
x3 =[1,2,3,4,5,2,3,4,5,1,3,4,5,1,2,4,5,1,2,3,5,1,2,3,4]
data = {"y":y,"x1":x1,"x2":x2,"x3":x3}
data=pd.DataFrame(data)
model =smf. ols('data.y ~ C(data.x1)+C(data.x2)+C(data.x3) ', data=data).fit()
anova_table = sm.stats.anova_lm(model, typ=2)
anova_table
>>> anova_table
sum_sq df F PR(>F)
C(data.x1) 68.0 4.0 1.593750 0.239059
C(data.x2) 150.0 4.0 3.515625 0.040373
C(data.x3) 330.0 4.0 7.734375 0.002537
Residual 128.0 12.0 NaN NaN
#以下内容保存为4-10.txt
value operator batch PSI
-1 1 1 1
-8 1 2 2
-7 1 3 3
1 1 4 4
-3 1 5 5
-5 2 1 2
-1 2 2 3
13 2 3 4
6 2 4 5
5 2 5 1
-6 3 1 3
5 3 2 4
1 3 3 5
1 3 4 1
-5 3 5 2
-1 4 1 4
2 4 2 5
2 4 3 1
-2 4 4 2
4 4 5 3
-1 5 1 5
11 5 2 1
-4 5 3 2
-3 5 4 3
6 5 5 4
import pandas as pd
import seaborn as sns
import statsmodels.api as sm
import matplotlib as plt
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
# load data file
d = pd.read_csv("4-10.txt", sep="\t")
model = ols('value ~ C(operator)+C(batch)+ C(PSI)', data=d).fit()
anova_table = sm.stats.anova_lm(model, typ=2)
anova_table
>>> anova_table
sum_sq df F PR(>F)
C(operator) 150.0 4.0 3.515625 0.040373
C(batch) 68.0 4.0 1.593750 0.239059
C(PSI) 330.0 4.0 7.734375 0.002537
Residual 128.0 12.0 NaN NaN