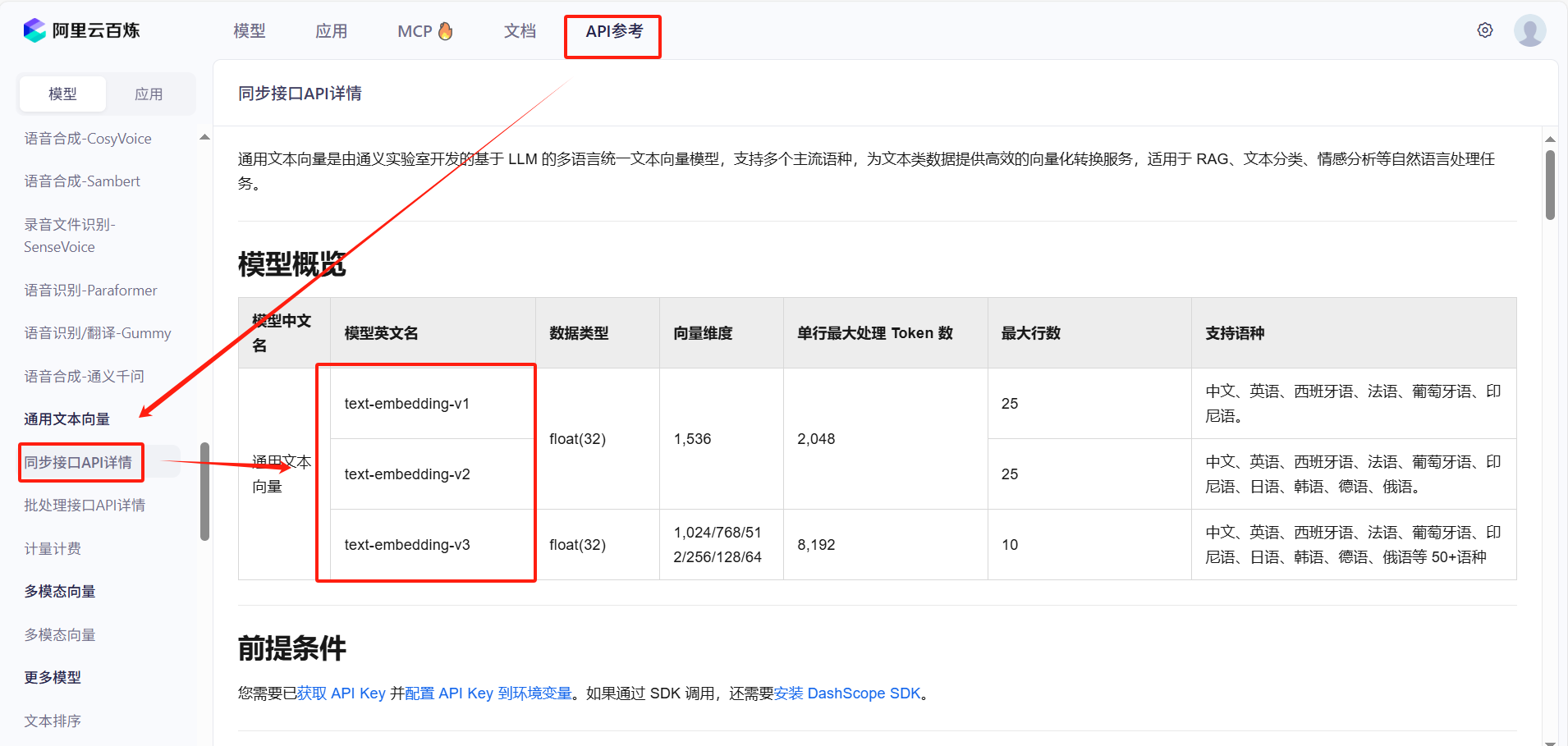
PDF 文档在商业、学术和政府领域无处不在,蕴含着大量宝贵信息。然而,从 PDF 中提取结构化数据却面临着独特的挑战,尤其是在处理数千甚至数百万个文档时。本指南探讨了大规模解析 PDF 的策略和工具。
PDF解析挑战
PDF 的设计初衷是为了提供一致的视觉呈现,而非数据提取。这带来了一些挑战:
- 结构复杂:PDF 结合了文本、图像、表格和表单
PDF 文档在商业、学术和政府领域无处不在,蕴含着大量宝贵信息。然而,从 PDF 中提取结构化数据却面临着独特的挑战,尤其是在处理数千甚至数百万个文档时。本指南探讨了大规模解析 PDF 的策略和工具。
PDF 的设计初衷是为了提供一致的视觉呈现,而非数据提取。这带来了一些挑战:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2376301.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!