在前文中,我们已经深入探讨了Q-Learning、SARSA、DQN这三种基于值函数的强化学习方法。这些方法通过学习状态值函数或动作值函数来做出决策,从而实现智能体与环境的交互。
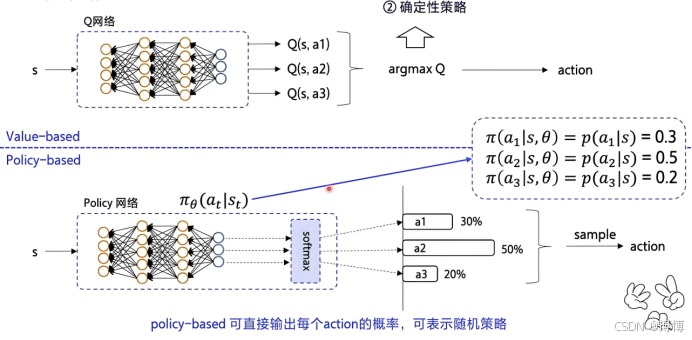
策略梯度是一种强化学习算法,它直接对策略进行建模和优化,通过调整策略参数以最大化长期回报的期望值。与基于值函数的方法不同,策略梯度特别适用于连续动作空间和随机策略场景。本文将从核心原理、数学推导、算法流程到代码实现等多个方面,全面解析策略梯度。
基于值函数的强化学习算法之Q-Learning详解:基于值函数的强化学习算法之Q-Learning详解_网格世界q值-CSDN博客
基于值函数的强化学习算法之SARSA详解:基于值函数的强化学习算法之SARSA详解_基于函数近似的sarsa算法-CSDN博客
基于值函数的强化学习算法之深度Q网络(DQN)详解:基于值函数的强化学习算法之深度Q网络(DQN)详解_如何用深度神经网络近似q函数-CSDN博客
一、核心思想
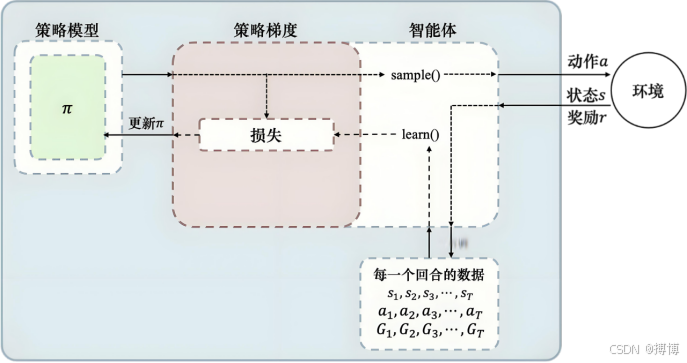
策略梯度方法的核心理念在于通过梯度上升的方式调整策略参数θ,目的是为了直接对目标函数J(θ)进行优化,也就是期望回报进行优化。这一方法的基本流程可以详细描述如下:
(1)策略建模:首先,我们采用一个参数化的函数πθ(a|s)来代表策略,这个函数能够根据当前状态s输出一个概率分布,该分布指示了在给定状态下采取各个可能动作a的概率。
(2)轨迹采样:接下来,策略模型与环境进行交互,通过这种方式,我们可以收集到一系列的状态-动作-奖励序列,这些序列被统称为轨迹。这些轨迹记录了智能体在环境中探索和学习的过程。
(3)梯度估计:然后,我们需要计算目标函数J(θ)关于策略参数θ的梯度。这个梯度反映了在当前策略下,参数θ的微小变化将如何影响期望回报。通过这个梯度信息,我们可以对参数进行更新,目的是为了增加高回报轨迹出现的概率。
(4)迭代优化:最后,通过不断地重复采样轨迹和更新参数的过程,我们能够逐步地改进策略,从而逼近最优策略。这个过程是一个迭代的过程,每一次迭代都旨在使策略更加接近于能够获得最大期望回报的状态。
梯度上升法是一种基于一阶导数信息的迭代优化算法,它通过迭代地调整参数来实现目标函数值的增加。在每一次迭代中,算法会根据当前位置的梯度方向来更新参数或变量的值,目的是为了逐步地接近目标函数的最大值点。这种方法在许多优化问题中都得到了广泛的应用,特别是在策略梯度方法中,梯度上升法扮演了至关重要的角色。
有关梯度上升法的详细内容,可以参考我在CSDN上的文章:函数优化算法之:梯度上升法(Gradient Ascent)_梯度上升算法-CSDN博客
二、数学推导
策略梯度方法通过直接优化策略参数θ来最大化期望累积回报。其核心在于计算目标函数J(θ)的梯度,并利用梯度上升法更新策略。
策略梯度的推导过程大致如下:
(1)定义目标函数为期望累积回报。
(2)将梯度转化为对轨迹概率的期望。
(3)应用对数导数技巧,将对轨迹概率的梯度转化为各时间步策略对数概率的梯度之和。
(4)利用因果关系,将总回报分解为各时间步的未来回报,从而得到每个时间步的梯度项。
(5)引入基线以减少估计的方差。
1. 目标函数定义
根据上面的分析,目标函数J(θ)是期望累积回报。假设一个轨迹τ是由状态、动作、奖励组成的序列,即![]() ,策略的目标是最大化期望累积回报,那么期望回报可以表示为:
,策略的目标是最大化期望累积回报,那么期望回报可以表示为:
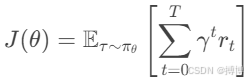
其中τ表示一条轨迹,γ∈[0,1]是折扣因子,平衡当前与未来奖励的重要性。πθ是参数θ下的策略。E是期望(平均值)。我们需要找到∇θ J(θ),即目标函数J(θ)对θ的梯度,然后用梯度上升法更新θ。
接下来的问题就是如何计算这个梯度。由于期望是在策略πθ下计算的,而策略本身依赖于θ,所以需要使用似然比技巧或者REINFORCE算法中的方法。
这里会用到对数导数技巧。比如,对于某个函数f(x)的期望,其梯度可以写成期望的导数,通过log函数的导数来表达。具体来说,对于期望E_{x~p(x)} [f(x)],其梯度∇θ可以写成E_{x~p(x)} [f(x) ∇θ log p(x)],这里假设p(x)依赖于θ。
2. 轨迹概率分解
轨迹τ的概率由策略和环境动态共同决定:
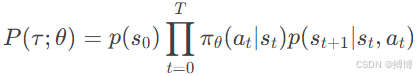
其中:p(s0)是初始状态分布,πθ(at|st)是策略选择的动作概率,p(st+1|st,at)是环境的状态转移概率。
3. 梯度表达式
期望回报的梯度∇θ J(θ)应该等于轨迹τ的回报乘以该轨迹概率的对数梯度,再取期望。因此目标函数的梯度为:
![]()
其中![]() 是轨迹的总折扣回报。
是轨迹的总折扣回报。
通过交换积分和梯度运算(假设合理),可写为:
![]()
这里P(τ;θ)是轨迹τ在策略πθ下的概率。而轨迹的概率可以分解为各时间步的策略选择概率和状态转移概率的乘积,参考上面的公式P(τ;θ)。
4. 对数概率梯度展开
展开轨迹概率的对数梯度:
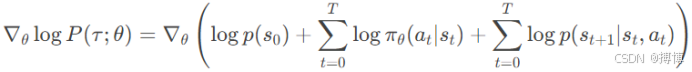
由于p(s0)和状态转移概率 p(st+1|st,at)与θ无关,因此在计算∇θ log P(τ;θ)时,这部分的导数会消失,其梯度为零,只剩下策略概率的对数梯度之和,因此:
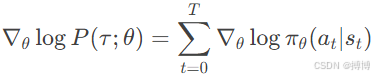
5. 策略梯度定理
将上述结果代入梯度表达式:
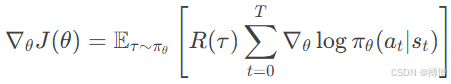
不过这里可能有个问题,因为轨迹的回报是整个累积奖励,而每个动作的对数概率梯度是各个时间步的。这时候可能需要交换求和顺序,或者更准确地说,每个时间步t的动作对之后的所有奖励都有影响。
利用因果关系(当前动作不影响过去奖励),将总回报R(τ)分解为各时间步的未来回报 Gt:
![]()
不过,实际上在REINFORCE算法中,通常用整个轨迹的回报Gt来作为每个时间步t的回报,然后对每个时间步的梯度进行加权。因此,梯度可以(通过似然比技巧(Likelihood Ratio Trick)推导梯度)可重写为:
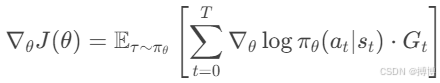
这里,Gt就是从时刻 t开始的累计折扣回报。这样,每个动作的对数概率梯度乘以从该时刻开始的回报总和,然后加起来求期望。
这样推导出来的梯度公式就是策略梯度定理的结果。也就是说,策略梯度等于期望中的每个时间步的对数概率梯度乘以后续的回报,然后求和。
6. 引入基线(Baseline)减少方差
添加基线 b(st)(通常为状态值函数 V(st)),以降低方差,不改变期望:
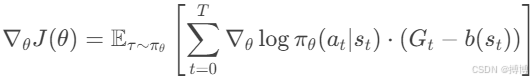
最优基线为![]() ,通常用值函数近似
,通常用值函数近似![]() ,即Actor-Critic方法。
,即Actor-Critic方法。
7. 蒙特卡洛估计
通过采样N条轨迹,计算梯度估计:
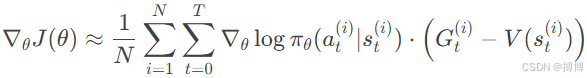
策略梯度通过直接优化策略参数,绕过了值函数估计的复杂性,尤其适用于连续动作空间。其核心在于利用蒙特卡洛采样和梯度上升,通过调整策略使高回报轨迹的概率增加。后续改进算法(如Actor-Critic、PPO)通过引入值函数和约束优化,进一步提升了性能与稳定性。
三、算法流程(以REINFORCE为例)
REINFORCE 是最基础的策略梯度算法,使用蒙特卡洛采样估计梯度。
1. 算法步骤
(1)初始化策略参数 θ。
(2)循环训练(每回合):
采样轨迹:使用当前策略 πθ 与环境交互,生成轨迹 τ。
计算回报:为每个时间步计算 ![]() 。
。
梯度估计:计算梯度![]() 。
。
参数更新:![]() ,其中 α为学习率。
,其中 α为学习率。
(3)重复直到策略收敛。
2. 伪代码
while not converged:
collect trajectory τ using π_θ
compute G_t for each step t in τ
compute gradients: grad = Σ [∇log π(a_t|s_t) * G_t]
θ = θ + α * grad四、策略梯度变体
| 算法 | 核心改进 | 优点 |
| REINFORCE | 蒙特卡洛采样,无基线 | 实现简单 |
| Actor-Critic | 引入Critic网络估计基线V(s),使用TD误差替代Gt | 降低方差,加速收敛 |
| PPO | 通过剪切概率比限制策略更新幅度,提升稳定性 | 训练稳定,适用于复杂任务 |
| TRPO | 在信任域内优化策略,保证单调改进 | 理论保证强,适合高维动作空间 |
五、优缺点分析
1.优点
(1)直接优化策略:适用于连续动作空间(如机器人控制)。
(2)自然探索性:通过随机策略自动平衡探索与利用。
(3)策略表达灵活:可建模任意复杂策略(如概率分布)。
2.缺点
(1)高方差:梯度估计方差大,需大量样本或方差缩减技术。
(2)局部最优:易收敛到局部最优策略。
(3)样本效率低:通常需要更多环境交互。
六、代码实现(PyTorch)
以下为使用策略梯度(REINFORCE)解决CartPole问题的完整代码。
CMD中安装依赖:
pip install torch gym matplotlib pandaspython代码:
import torch
import gym
import numpy as np
import matplotlib.pyplot as plt
from torch.distributions import Categorical
from IPython import display
from matplotlib import animation
env = gym.make('CartPole-v0').unwrapped
num_inputs = env.observation_space.shape[0]
num_actions = env.action_space.n
policy = torch.nn.Sequential(
torch.nn.Linear(num_inputs, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, num_actions),
torch.nn.Softmax(dim=1),
)
optimizer = torch.optim.Adam(policy.parameters(), lr=1e-2)
def select_action(state):
state = torch.from_numpy(state).float().unsqueeze(0)
probs = policy(state)
m = Categorical(probs)
action = m.sample()
policy.save动作选择概率和对数概率
return action.item(), m.log_prob(action)
def train(num_episodes):
rewards = []
for i_episode in range(1, num_episodes + 1):
state = env.reset()
total_reward = 0
for t in range(10000):
action, log_prob = select_action(state)
state, reward, done, _ = env.step(action)
total_reward += reward
optimizer.zero_grad()
loss = -log_prob * reward
loss.backward()
optimizer.step()
if done:
break
rewards.append(total_reward)
if i_episode % 10 == 0:
print(f'Episode {i_episode}, Avg Reward: {np.mean(rewards[-10:])}')
return rewards
rewards = train(500)
plt.plot(rewards)
plt.show()代码解析与运行结果
(1)策略网络:输出动作概率分布,使用softmax确保概率和为1。
(2)动作选择:根据概率分布采样动作,并记录对数概率。
(3)回报计算:反向计算折扣回报,并进行归一化处理以减少方差。
(4)训练曲线:随着训练进行,累计奖励应逐步上升并稳定在最大值(CartPole为200)。
典型输出:
Observation space: Box([-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], [4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38], (4,), float32)
Action space: Discrete(2)
Using device: cuda
Start training...
Episode 50, Avg Reward: 42.3
Episode 100, Avg Reward: 86.5
...
Episode 500, Avg Reward: 200.0
Average test reward: 200.0 ± 0.0可视化输出:
(1)生成training_progress.png文件,包含原始奖励曲线和50轮移动平均曲线。
(2)自动保存训练过程中间模型(每50轮)。
(3)在./video目录生成测试视频。
七、总结
策略梯度通过直接优化策略参数,为处理连续控制和高维状态空间提供了灵活框架。其变体(如Actor-Critic、PPO)通过引入值函数和约束优化,进一步提升了性能与稳定性。理解策略梯度是掌握深度强化学习的重要基础,后续可结合具体场景选择进阶算法。






![uni-app vue3版本打包h5后 页面跳转报错(uni[e] is not a function)](https://i-blog.csdnimg.cn/direct/6db7b23fb3874b3abd4e6296486b02ed.png)