分享CCF 第七届AIOps国际挑战赛的季军方案,从我们的比赛经历来看,并不会,相反,私域领域问答的优秀效果说明RAG真的很重要
历经4个月的时间,从初赛赛道第1,复赛赛道第2,到最后决赛获得季军,这一路我们团队收获了很多实践经验,也结识了不少业界的RAG研究者,受益匪浅。应组委会邀请,本文介绍一下我们EasyRAG方案的亮点和实验结果,欢迎感兴趣的朋友批评指正!
开源地址:https://github.com/BUAADreamer/EasyRAG
技术报告:https://github.com/BUAADreamer/EasyRAG/blob/master/assets/技术报告.pdf
PPT:https://github.com/BUAADreamer/EasyRAG/blob/master/assets/PPT.pdf
论文链接:EasyRAG: Efficient Retrieval-Augmented Generation Framework for Automated Network Operations
挑战赛官网:https://competition.aiops-challenge.com/home/competition/1780211530478944282
0.概览
先简要介绍背景,本次比赛题目是面向网络运维领域的私域知识问答,根据LLM的类型分为两个赛道,赛道一使用可以微调的Qwen2-7B,赛道二调用 GLM-4 API。我们选择了赛道二,模拟无法微调LLM的场景。
因此,我们的目标是如何在不微调任何模型的前提下,实现较为简洁的RAG,尽可能达到准确、高效和实用

为了达成这一目标,我们基于llama-index[1],实现了一套包含查询改写、图像数据处理、分块策略、元数据利用、密集检索、稀疏检索、重排、排序融合、提示词优化、上下文压缩、部署的RAG框架,可以灵活地配置自己的RAG流程,方便地应用在自己的私域数据问答中。

初赛RAG流程:块调优-两路稀疏/密集检索粗排-重排-rrf排序融合

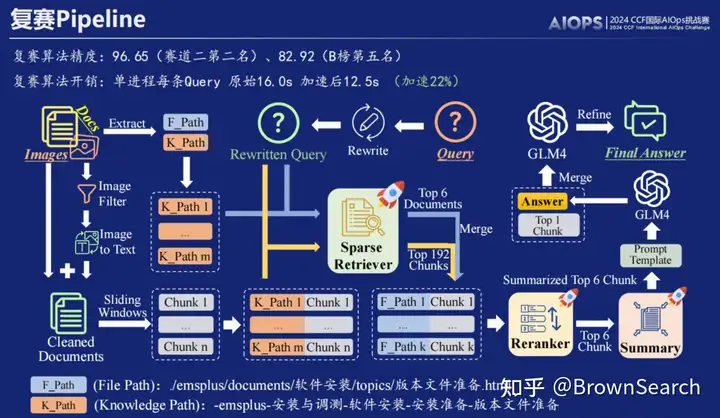
复赛RAG流程:块优化(图像信息和路径知识利用)-两路稀疏检索粗排-重排-答案迭代优化
接下来我们将分别介绍我们在准确性,高效性和实用性方面的实践和实验结果,以飨读者
1.准确性
数据处理流程
-
zedx文件处理:zedx文件解压-路径解析-文档抽取-保存。
- 关键点1:路径解析中,我们提取了xml文件中的知识路径(emsplus-安装与调测-软件安装-安装准备-版本文件准备)和文件路径(./emsplus/documents/软件安装/topics/版本文件准备.html),从而为后续的结合路径的检索提供数据支撑
- 关键点2:文档抽取中,我们用bs4提取了html中的文本,同时提取了图像标题和图像路径的一一对应关系,从而方便多模态知识的利用
-
文本分块:使用llama-index的Sentence Splitter进行分块,先利用中文分隔符分割句子,再按照设置的文本块大小合并多个小块。
- 关键点1:chunk_size和chunk_overlap比较重要,需要精心挑选
- 关键点2:节点的node.metadata中的file_path默认为绝对路径,而句子分割类会利用元数据长度,原始数据放在在不同绝对路径导致结果差异大,从而使得结果不稳定。因此我们重新实现了分块类。同时我们也在元数据存储时,将file_path改为相对路径,彻底消除绝对路径带来的不稳定性。代码如下
# 原代码:https://github.com/run-llama/llama_index/blob/8f7cd3e1043da26514ac82fc732cd21bbb4bbe9c/llama-index-core/llama_index/core/node_parser/text/sentence.py#L155C5-L157C62
def split_text_metadata_aware(self, text: str, metadata_str: str) -> List[str]:
metadata_len = len(self._tokenizer(metadata_str))
effective_chunk_size = self.chunk_size - metadata_len
# 我们的实现:https://github.com/BUAADreamer/EasyRAG/blob/893b3c272b2ce0d8c6cee80f02a171cccded9f96/src/easyrag/custom/splitter.py#L149
def split_text_metadata_aware(self, text: str, metadata_str: str) -> List[str]:
metadata_len = len(self._tokenizer(metadata_str))
effective_chunk_size = self.chunk_size
# 分块实现:https://github.com/BUAADreamer/EasyRAG/blob/893b3c272b2ce0d8c6cee80f02a171cccded9f96/src/easyrag/custom/transformation.py#L67C1-L71C51
for node in nodes:
node.metadata["file_abs_path"] = node.metadata['file_path']
file_path = node.metadata["file_path"].replace(self.data_path + "/", "")
node.metadata["dir"] = file_path.split("/")[0]
node.metadata["file_path"] = file_path
-
图像信息抽取:图像内容提取-图像过滤
-
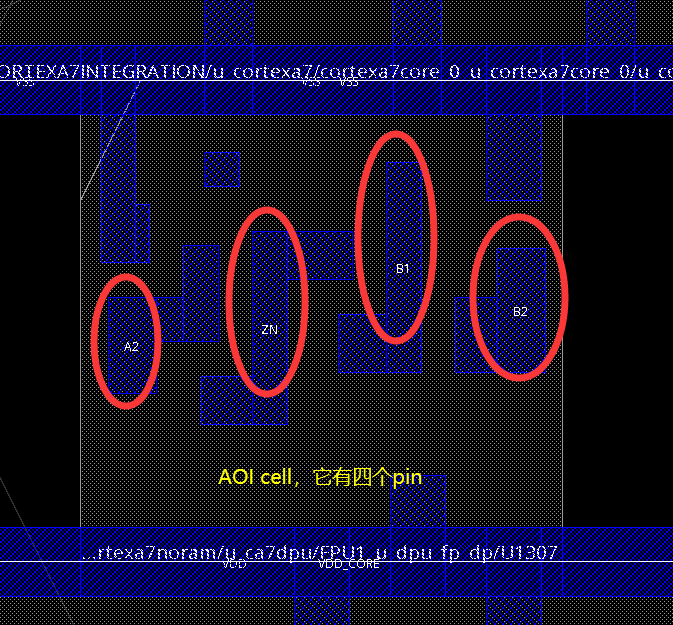
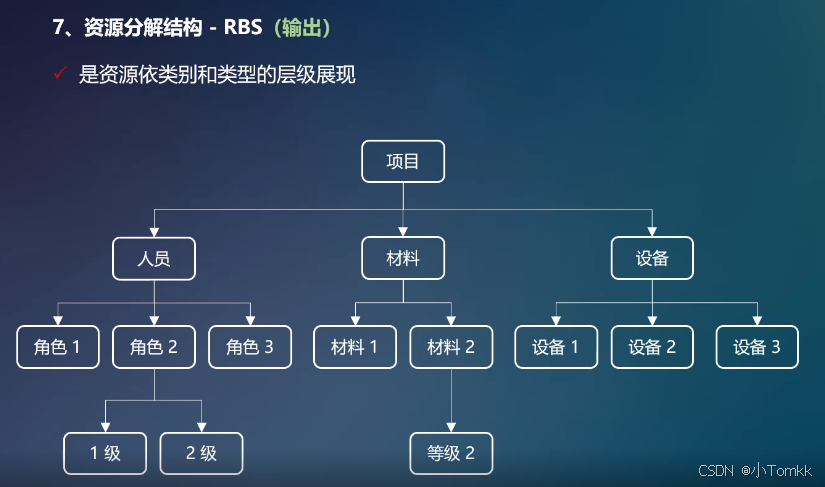
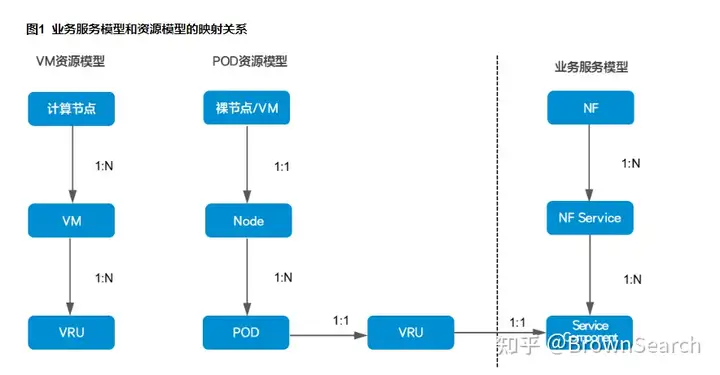
例子:有1道题目问的是流程图(下图)中POD和VRU的比例,必须解析图像内容才能予以回答
-
多模态大模型提取内容:
- glm4v-9b对图像做caption;提示词:
简要描述图像 - 我们还尝试了internvl2、gpt4o、claude等多个模型,发现glm4v的效果较好
- glm4v-9b对图像做caption;提示词:
-
多种规则图像过滤:
- 纯英文过滤:使用paddleocr提取文字,过滤不含有中文的图像(纯英文图像的信息可能和文中内容重复或过于复杂)
- 关键词过滤:标题含有组网图、架构的复杂图对问题帮助不大
- 引用过滤:过滤在文中以特定方式被引用的图像 (配置如图 x 所示,文件如图 x 所示等),这些图一般文字已经含有了全部信息
-
RAG流程
-
查询改写:我们尝试了关键词扩展和HyDE两种思路,但我们发现直接使用GLM4进行查询扩展会使得新查询词和私域文档偏差较大,因此在提交方案中没有采用,详情参见技术报告
-
两路稀疏检索粗排:基于BM25实现两路检索,除了常规的文档检索,我们还进行了知识路径检索。
- 例子:问题“VNF弹性分几类?“,VNF 和弹性都可以直接在相关的知识路径中找到,但在文档中找不到,此时路径检索优势就很明显
- BM25分词:我们发现llama-index对于中文BM25支持较糟糕,因此我们自己实现了基于jieba的中文分词,相比原实现提点明显。同时,我们也尝试了清华的IT词库[2],效果没有提升
- 停用词表:使用经典的哈工大停用词表[3]
-
密集检索粗排:基于LLM的embedding模型效果更佳
- 选用阿里的GTE-Qwen2-7B-instruct[4],在不微调的情况下,此模型在我们的实验中效果优于bge-v1.5和bce
- 使用qdrant向量数据库,其官网的docker例子就可以快速部署,简单高效
- 粗排topk为288
- 索引时将文本块和文件路径拼接,再输入模型得到表征
-
LLM Reranker 重排:基于LLM的Reranker效果更佳
- 选用智源的bge-reranker-v2-minicpm-layerwise[5],不微调情况下,此模型效果领先其他bge系列reranker
- 精排topk为6
- reranker推理时将文本块和知识路径拼接
-
多路排序融合:排序融合主要尝试了naive(去重合并)以及rrf(倒数排序融合)。我们发现重排融合相比粗排融合更有用
-
粗排融合:复赛中我们直接将两路进行naive融合
-
重排融合:多路分别进行粗排-重排,得到多组文档集合
- 生成前融合:多组文档集合排序融合得到一组文档集合,输入LLM
- 生成后融合:每组文档集合分别输入LLM,将多个答案融合。我们尝试了直接拼接和取最长两种方式
-
-
LLM 回答:简单问答提示词最佳
- 我们尝试了包括CoT提示,以及结构化的markdown提示词和CoSTAR[6]提示词,但都没有超过最原始的官方提供提示词,然而,考虑到API的波动,此处仍有探索空间,详情参见技术报告
-
LLM 答案迭代优化:让模型逐步关注重要信息
- 我们发现 LLM 对于每个文本块都会给予一定的注意力,可能会导致 top1 文本块的有效信息没有得到充分利用,因此我们设计了两轮迭代优化,第一轮先基于6个文本块得到answer1,第二轮将answer1和top1文本块输入LLM得到answer2作为最终答案
缩写描述
这里先对之后实验表中的一些缩写做出解释


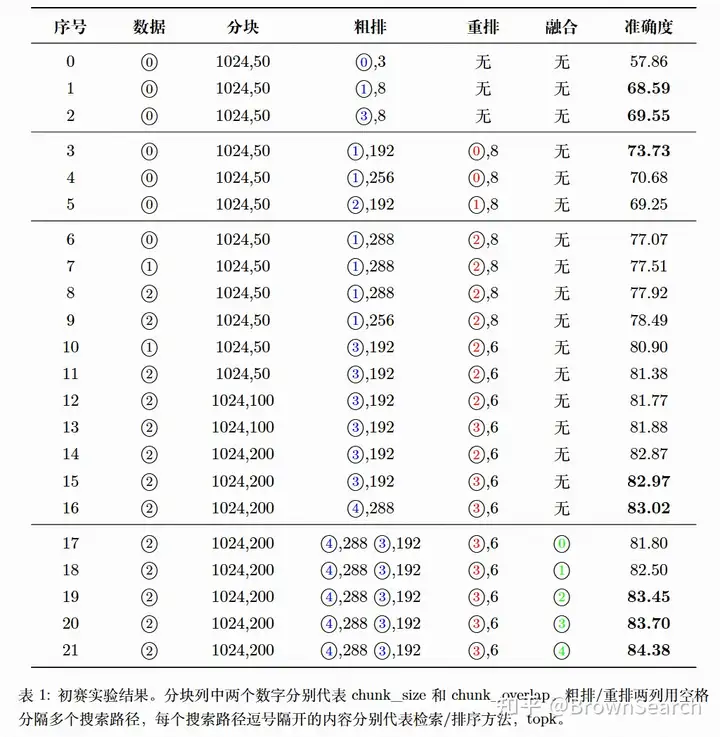
初赛实验结果
这里列出我们初赛的提分路径,主要经历了3个阶段
-
单路粗排(0-2)
- 官方Baseline跑通(0==>57)
- bge-v1.5实验(57==>68)
- bm25实验(68==>69)
-
单路粗排-精排(3-16)
- 增加基于BERT的重排(69==>73)
- 改为基于LLM的重排模型(73==>77)
- 优化数据处理流程(77==>78)
- 粗排换用bm25或gte-qwen2-7B(78==>81)
- 修改分块参数(81==>83)
-
多路融合(17-21)
- 重排后融合(83==>83.5+)
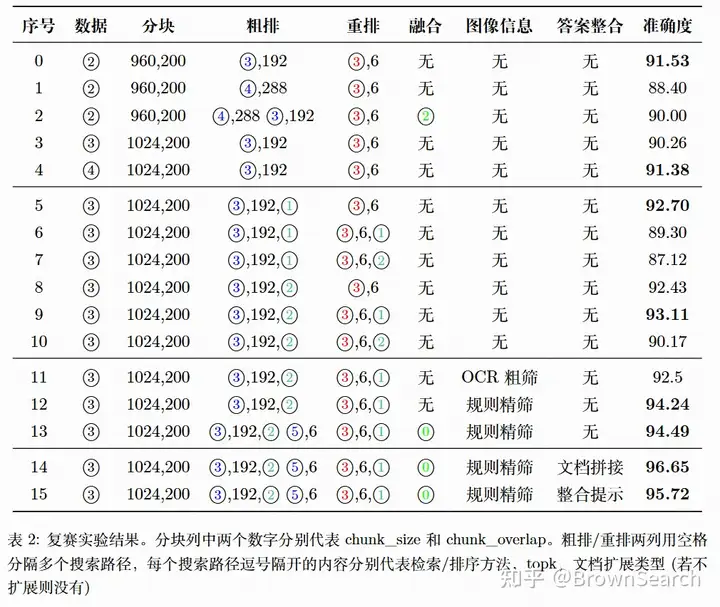
复赛实验结果
由于复赛和初赛评价指标发生了变化,更看重事实正确性,因此稀疏检索粗排总体更加有效
这里列出我们复赛的提分路径,主要经历了5个阶段
-
流程探索(0-4)
- 改为单路稀疏检索粗排-重排(90==>91.5)
-
路径知识利用(5-10)
- 粗排利用文件路径(91.5==>92.7)
- 重排利用知识路径(92.7==>93.1)
-
图像信息利用(11-12)
- 图像信息抽取+筛选(93.1==>94.2)
-
知识路径检索(13)
- 加上知识路径稀疏检索(94.2==>94.5)
-
答案迭代优化(14-15)
- 答案整合(94.5==>96+)
2.高效性
考虑到实际使用时对速度的要求,我们也实现了一些策略提升推理时延,以下为总的时间开销比较:
- 时间开销:无加速情况下总推理时延为粗排0.2s,重排6s,LLM推理10s
- 加速时间开销:加速情况下总推理时延为粗排~0s,重排<4s,LLM推理<8.5s
接下来分别讲解三个加速方案
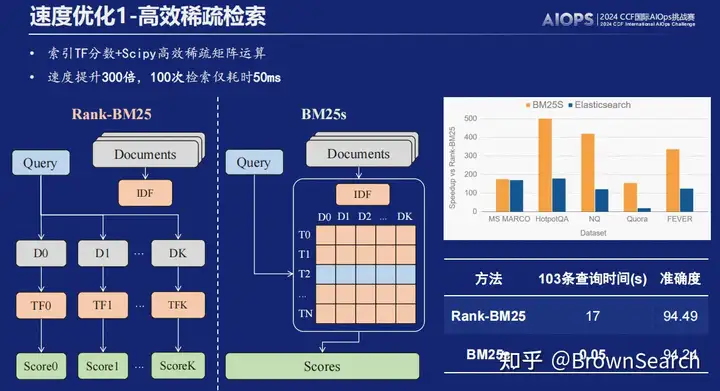
高效稀疏检索
- 此部分我们引入了bm25s库[7],将稀疏检索时延降低到可忽略不计,问答效果几乎无区别
- bm25s原理:1.主动索引技术,以空间换时间,在索引时存储每个token相对于每个文档的TF并用矩阵存储,推理时直接将每个词所在的行取出来;2.高效的scipy矩阵运算
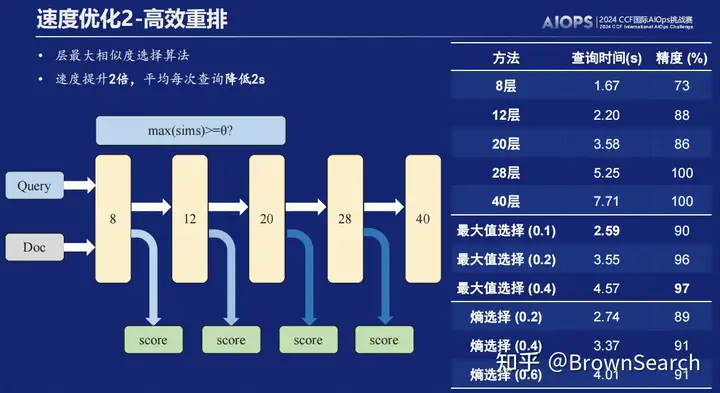
高效重排
我们设计了层早退算法,将重排时间降低2s+
-
动机:我们使用的重排模型bge-reranker-v2-minicpm-layerwise基于LLM设计为可选层模式,即可以选择较小的层进行推理提高速度。28层效果最佳,一般优于其他层
-
思路:我们基于简单query早退,复杂query晚退的思想,设计了类似DeeBERT[8]和FastBERT[9]的动态层早退方法,尽可能逼近原排序效果同时,降低了推理时延
-
结论:
- 最大相似度阈值选择算法优于熵阈值选择算法
- 阈值越大越慢但越准,可根据实际场景选择相应阈值
- 此处,我们还发现了有意思的一个现象,即选择算法的比较步骤会带来无法忽略的开销,因此我们只在28层之前选择了三个“断点”进行阈值判断,从而尽量做好tradeoff,避免“虚假”优化
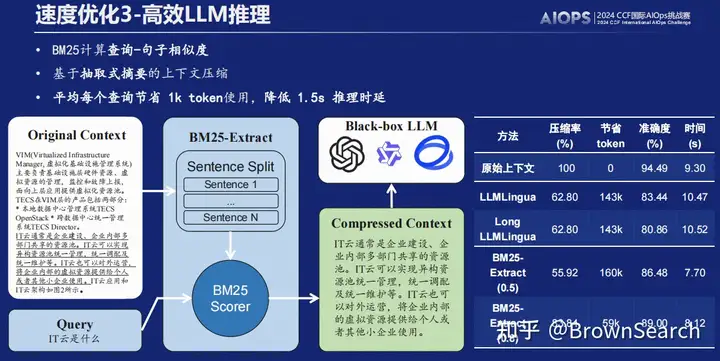
高效LLM推理
我们设计了上下文压缩方法,将LLM推理时间降低1.5s+
-
动机:我们首先尝试了llmlingua,但发现使用LLM来做压缩会带来额外开销,导致推理时延不升反降,节省了token,但增加了时间开销。
-
思路:因此我们设计了基于BM25相似度的抽取式压缩方法,先分句,再取出相似度最高的若干句子按原顺序拼接为压缩后上下文
-
结论:
- 在效果超越llmlingua的基础上,我们的模型可以节省更多token和时间
- 阈值越大越慢但越准,可根据实际场景选择相应阈值
3.实用性
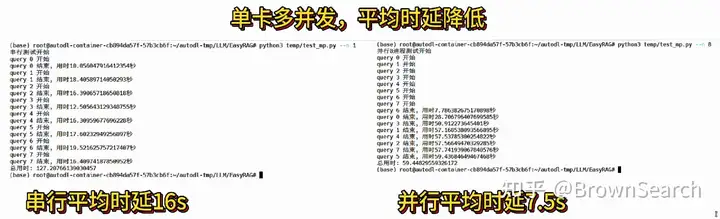
- 扩展性:我们测试了单张A800的8并发,发现平均推理时延从串行16s降低到了7.5s,因此初步验证具有一定的可扩展性
- 部署难度:我们支持了简单的命令行部署和docker批量运行,几行命令就可以方便地启动一个Web应用
网络运维问答案例
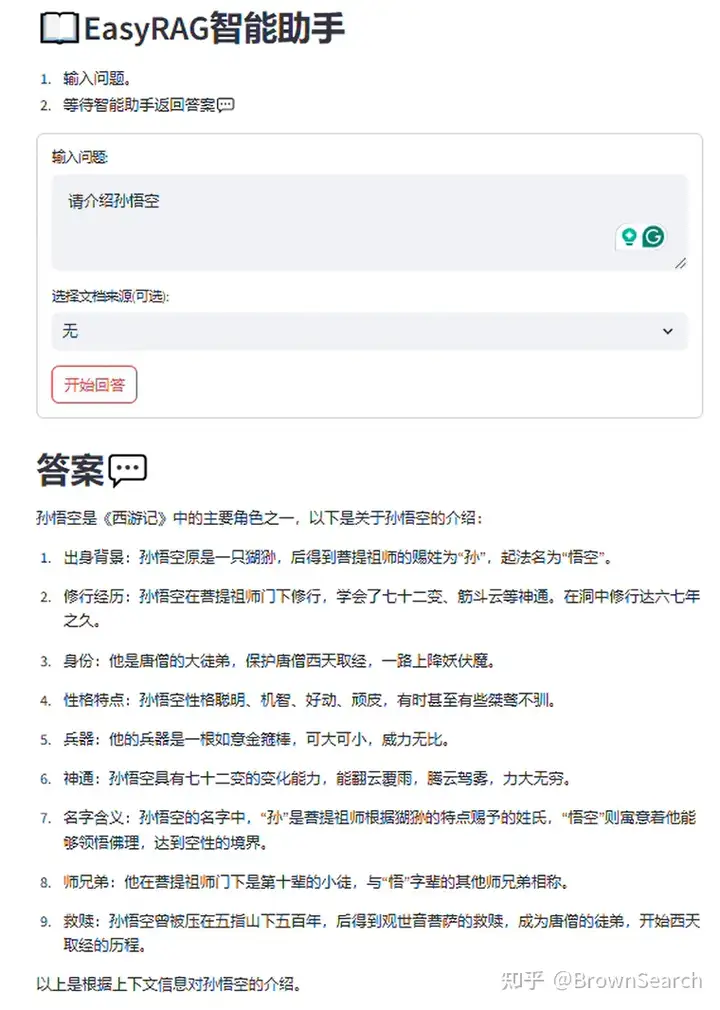
四大名著问答案例
我们还使用四大名著语料[10]测试了框架能否支持通用的语料问答
4.总结
本次比赛我们以不微调任何模型作为自己的目标,并在此前提下,利用了各种先进模型搭建我们的pipeline,做了充分的消融实验,达到了比赛中先进的准确度,同时也做了一些高效性和实用性方面的尝试
这初步说明一个结论:对于垂直领域RAG,精心设计流程+挑选sota模型+流程调优在初期带来的收益可能要大于微调模型。不过我们相信,经过微调后的模型可以让我们的pipeline获得更高的效果。希望这个工作能对RAG社区做出一些贡献,欢迎各位大佬批评指正!
参考
- https://github.com/run-llama/llama_index
- http://thuocl.thunlp.org
- https://github.com/goto456/stopwords
- https://huggingface.co/Alibaba-NLP/gte-Qwen2-7B-instruct
- https://huggingface.co/BAAI/bge-reranker-v2-minicpm-layerwise
- https://towardsdatascience.com/how-i-won-singapores-gpt-4-prompt-engineering-competition-34c195a93d41
- https://github.com/xhluca/bm25s
- https://aclanthology.org/2020.acl-main.204/
- https://aclanthology.org/2020.acl-main.537/
- https://github.com/weiyinfu/SiDaMingZhu
文章来源:https://www.zhihu.com/question/637421964/answer/61089640105