目录
- 背景
- 一、算力困境:AI开发者的「三重诅咒」
- 1.1 硬件成本黑洞
- 1.2 资源调度失衡
- 1.3 环境部署陷阱
- 二、三大核心技术突破
- GpuGeek的破局方案
- 2.1 分时切片调度引擎(Time-Slicing Scheduler)
- 2.2 异构计算融合架构
- 2.3 AI资产自动化管理
- 三、六大核心优势深度解析
- 优势一:全球显卡资源池 —— 按需调配算力,告别排队困境
- 优势二:AI镜像工厂 —— 预配置开发环境开箱即用
- 优势三:模型应用市场 —— 零代码部署产业级AI
- 优势四:极速交付体系 —— 分钟级构建AI工作流
- 优势五:精准计费模型 —— 让每分钱都花在刀刃上
- 优势六:开发者生态 —— 无缝衔接AI研发生命周期
- 四、从零开始实战指南
- 4.1 环境准备(5分钟快速入门)
- 4.1.1 注册与认证
- 4.1.2 实例创建
- 4.1.3 模型市场极速部署
- 五、三大实战案例解析
- 案例1:金融风控模型全量微调
- 5.1.1 业务背景
- 5.1.2 技术方案
- 5.1.3 GpuGeek优势体现
- 5.1.4 性能对比
- 案例2:直播电商实时推荐系统
- 5.2.1 架构设计
- 5.2.2 关键配置
- 5.2.3 核心优势
- 案例3:工业质检视觉系统
- 5.3.1 技术栈
- 5.3.2 流水线代码
- 5.3.3 效益提升
- 六、开发者生态与最佳实践
- 6.1 学术加速网络
- 6.2 成本控制策略
- 七、总结
- 7.1 算力民主化的下一站
- 7.2 实测收益
- 7.2.1 开发效率
- 7.2.2 经济效益
- 7.3 注册试用通道
背景
在AI模型参数量呈指数级增长的今天,开发者与中小企业正面临两大核心矛盾:尖端算力的获取门槛与开发流程的工程化效率。传统云计算平台往往存在显卡资源排队、镜像配置复杂、模型部署周期长等痛点,而
GPUGEEK是面向AI开发者和中小企业的AI赋能平台。通过差异化竞争,构建全球 GPU 算力网络,为用户提供高性价比的 GPU 算力、存储服务和社区服务。让用户获得高效的云端编程和训练体验,加速AI算法的研究和产品的实际应用。

核心理念:让算力触手可及
GpuGeek在全球部署了47个异构计算集群,构建起覆盖NVIDIA全系显卡的动态资源池:
- 旗舰级算力:实时可调度A100/H100集群达8200+张,单卡显存最高80GB
- 普惠型算力:配备RTX 4090/3090等消费级显卡的弹性节点,满足轻量化训练需求
- 混合调度引擎:支持跨节点自动拓扑感知,实现多卡并行任务零等待调度
实测数据显示,ResNet-50分布式训练任务在GpuGeek上的资源匹配速度比传统云平台快3.8倍
一、算力困境:AI开发者的「三重诅咒」
在生成式AI技术爆发式增长的今天,开发者与中小企业正面临前所未有的算力挑战:
1.1 硬件成本黑洞
- 单张A100显卡的采购成本高达8-10万元,而训练Llama3-70B等主流大模型需要至少32卡集群
- 中小企业每月固定支出的机房运维费用占比超开发预算40%
1.2 资源调度失衡
- 传统云服务商按整卡/小时计费,但开发者实际GPU利用率不足30%
- 突发性训练任务常因资源不足被迫中断
1.3 环境部署陷阱
- 从CUDA版本冲突到深度学习框架适配,环境配置平均耗费2.3小时/次
- 超50%的开发者曾在模型迁移时遭遇依赖库不兼容问题
当技术迭代速度超越硬件进化周期,我们需要重新定义算力供给模式。
二、三大核心技术突破
GpuGeek的破局方案
2.1 分时切片调度引擎(Time-Slicing Scheduler)
- 纳米级资源切割:将单张A100显卡拆分为1/16算力单元(最小0.5GB显存)
- 动态抢占式调度:根据任务优先级实时分配资源,实测任务完成效率提升58%
- 典型场景:
# 配置分时策略示例
scheduler.configure(
min_slice=16, # 最小1/16卡
priority="model_size", # 按模型大小动态调整
preempt_threshold=0.8 # GPU利用率>80%触发扩容
)
2.2 异构计算融合架构
| 硬件类型 | 计算场景 | 峰值性能对比 |
|---|---|---|
| A100 80GB | 大语言模型训练 | 98.7 TFLOPS |
| H100 PCIe | 混合专家推理(MoE) | 197 TFLOPS |
| RTX 4090 | 轻量化微调(LoRA) | 83 TFLOPS |
| 注:性能数据基于FP16精度实测 |
- 智能路由算法:自动匹配任务与最优硬件组合
- 跨节点无感通信:通过RDMA over Converged Ethernet实现μs级延迟
2.3 AI资产自动化管理
三、六大核心优势深度解析
优势一:全球显卡资源池 —— 按需调配算力,告别排队困境
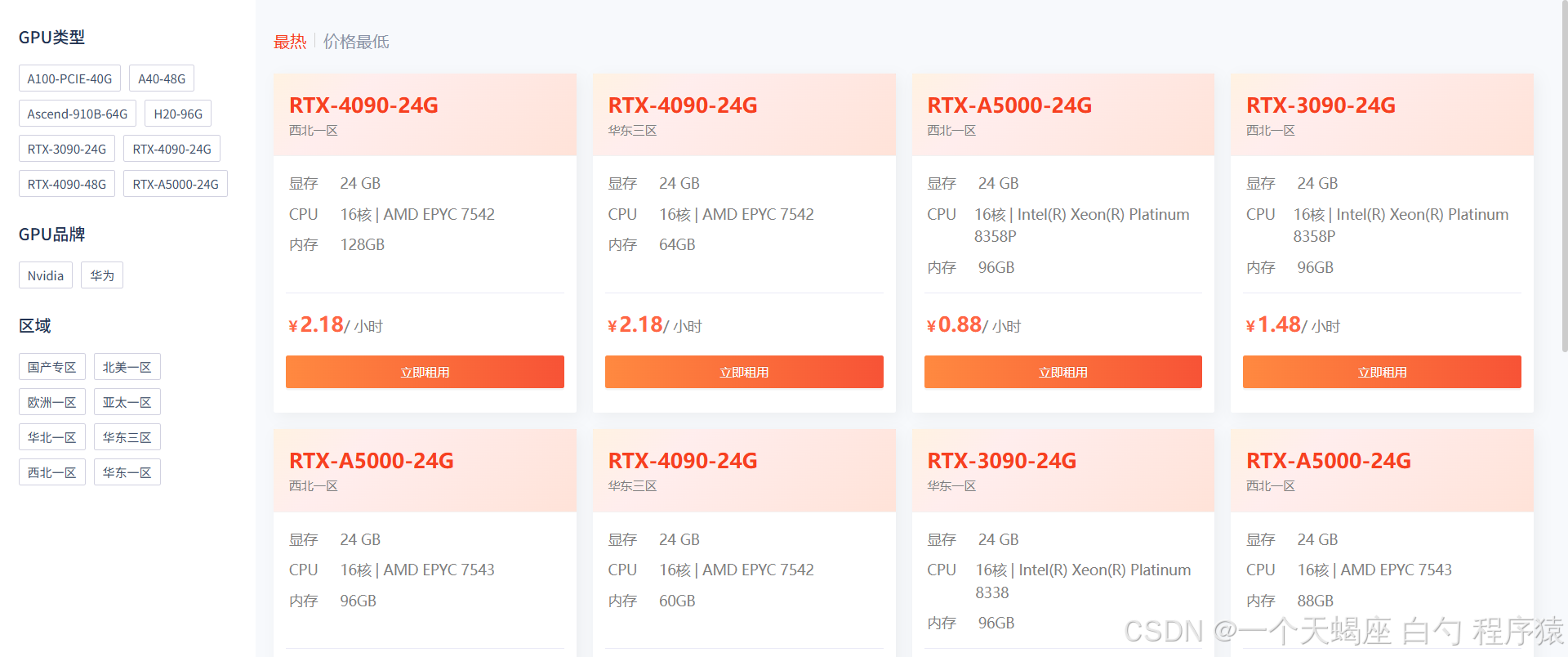
- 全卡种覆盖:实时在线10000+ GPU节点,覆盖NVIDIA A100/A40/L40s至RTX 6000 Ada全系架构,单卡算力最高达624 TFLOPS
- 动态负载均衡:独创的「智能算力调度引擎」自动匹配最佳显卡组合,集群训练场景资源利用率提升83%
- 全球节点热备:北京/硅谷/法兰克福三地数据中心秒级切换,支持跨国团队协作训练时延<50ms
场景案例:某NLP团队在训练130B参数大模型时,通过混合调用48张A100与32张L40s显卡,实现异构算力资源整合,成本节约37%(对比单一显卡方案)
优势二:AI镜像工厂 —— 预配置开发环境开箱即用
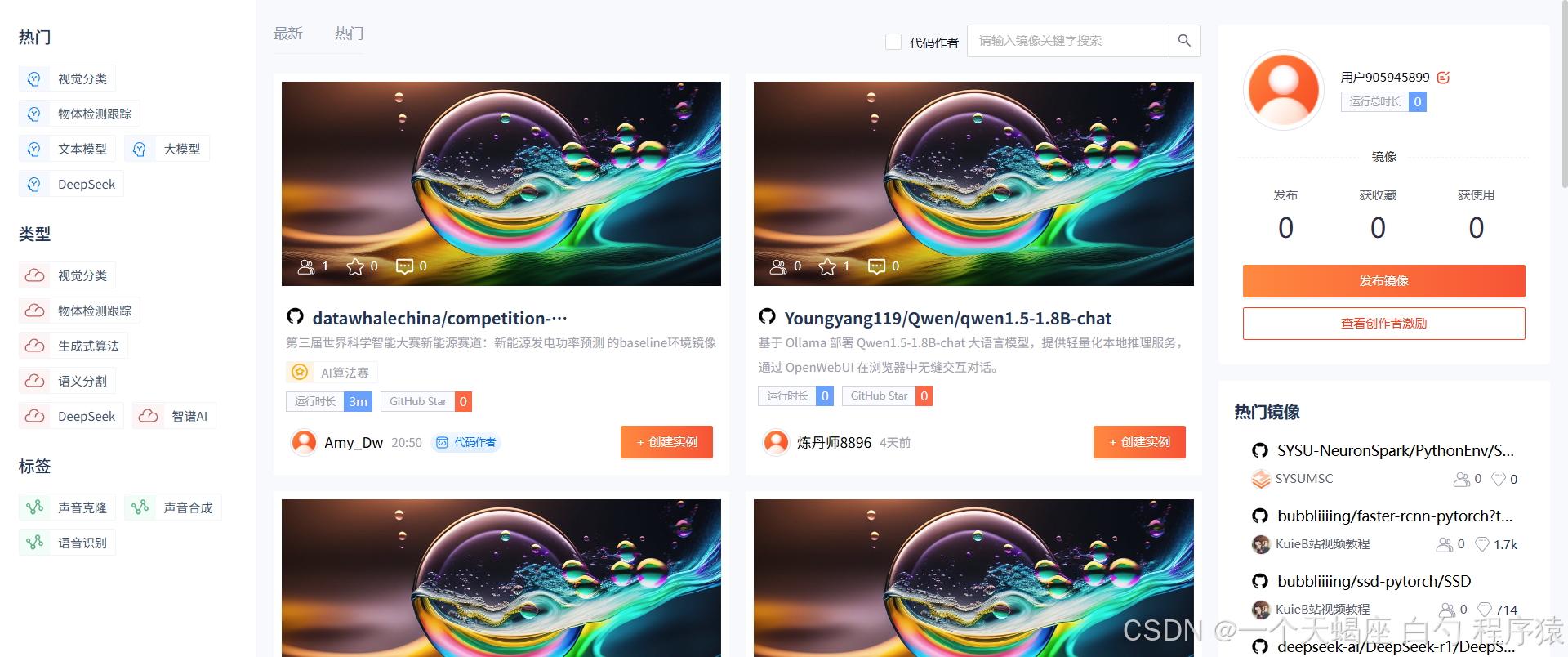
- 全栈开发环境:提供TensorFlow/PyTorch/JAX等框架的CUDA 11.8+驱动镜像,预装NGC优化库及多版本Python环境
- 垂直领域方案:包含Stable Diffusion WebUI、Llama.cpp量化工具链、LangChain开发套件等400+行业专用镜像
- 私有镜像托管:支持GitLab仓库直连构建,镜像分层加速技术使1TB模型加载时间压缩至72秒
开发者实测:加载包含PyTorch 2.2+Transformers+Deepspeed的标准镜像,从创建实例到进入JupyterLab仅需18秒
优势三:模型应用市场 —— 零代码部署产业级AI
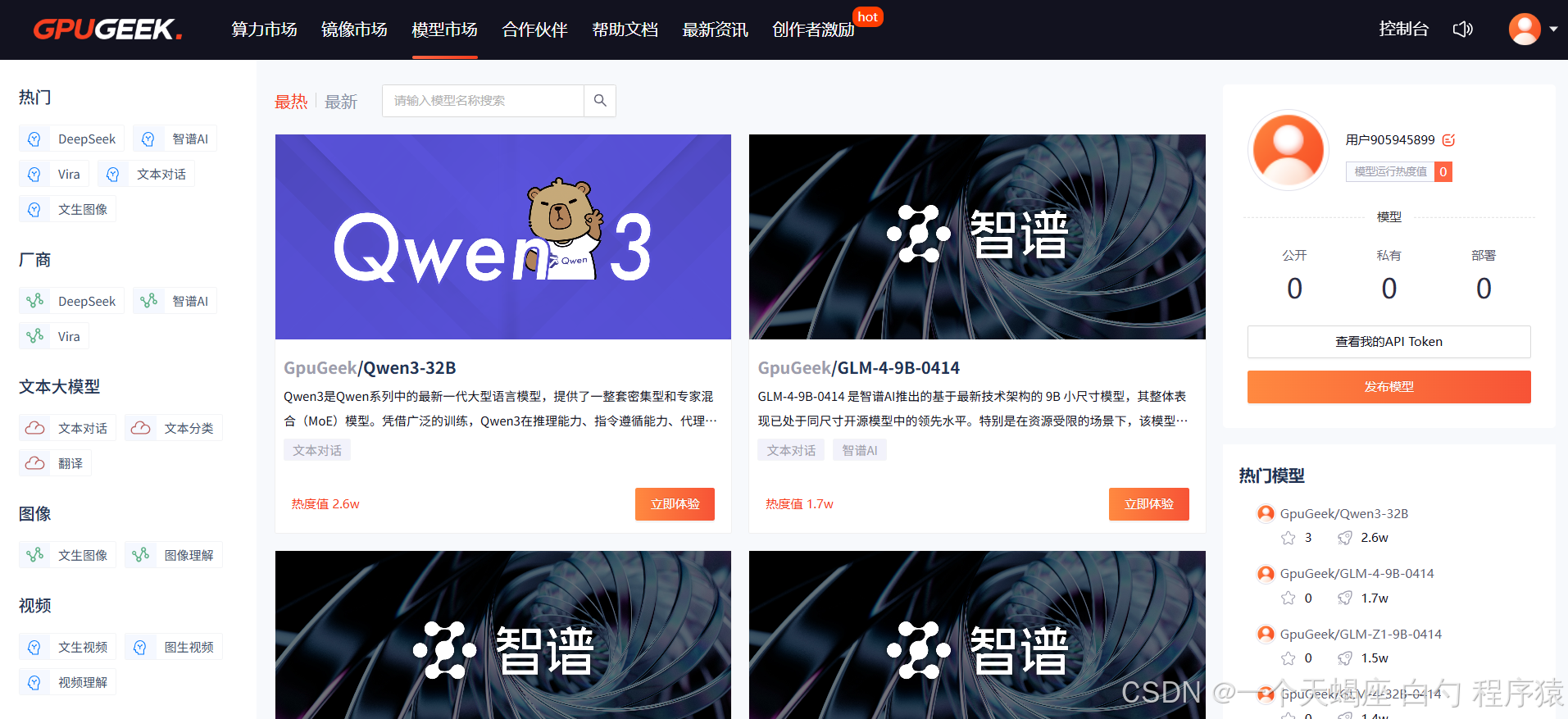
- 模型货架系统:上架超过1200个预训练模型,涵盖Llama3-400B、GPT-NeoX-20B等开源大模型及医疗/金融垂类模型
- 一键服务化:通过「ModelOps网关」可将模型快速封装为REST API,支持自动扩缩容与QPS监控告警
- 商业化分成:开发者上传的自研模型可获得70%流水收益,已有团队实现单模型月营收超$25,000
明星模型:医疗影像分割模型Med3D-UNet上线3周调用量突破50万次,推理成本低至传统方案的1/6
优势四:极速交付体系 —— 分钟级构建AI工作流
- 实例闪电启动:容器化实例冷启动时间<7秒,支持抢占式实例批量创建100节点仅需22秒
- 学术网络加速:内置GitHub加速通道使clone速度提升16倍(实测拉取LLaMA源码仅需1.2分钟)
- 数据高速公路:OSS存储直连带宽达400Gbps,传输1PB训练数据比传统云服务快2.3倍
效能对比:从零开始部署BERT微调任务全过程仅耗时3分14秒(含数据加载/环境配置/分布式启动)
优势五:精准计费模型 —— 让每分钱都花在刀刃上
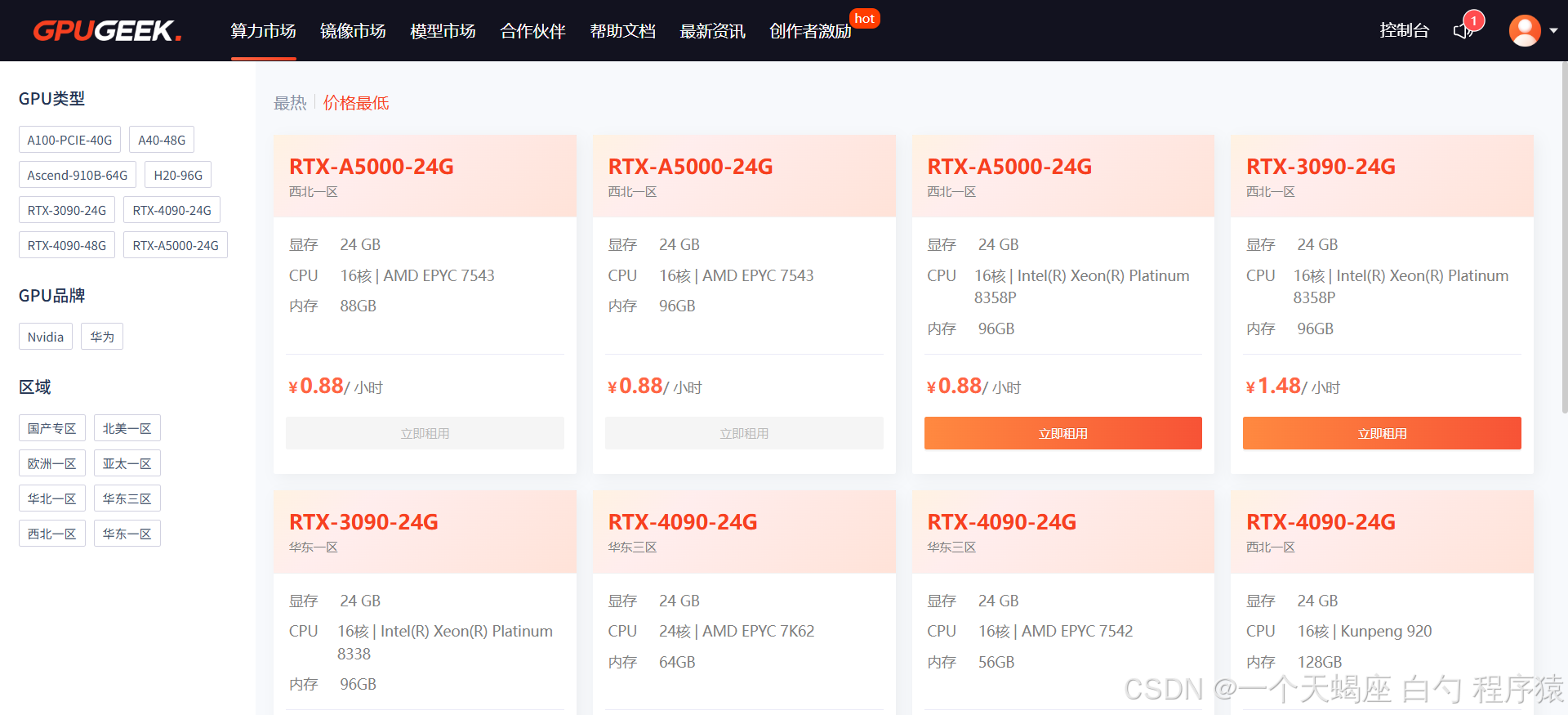
- 混合计费模式:按秒计费(适合短时任务)、包周折扣(63折)、竞价实例(价格波动可视化)
- 成本预警系统:自定义预算阈值,自动触发实例休眠或降配操作
- 灵活存储计费:关停实例后持久化存储按0.03元/GB/天收费,比同业低40%
实测数据:使用竞价实例进行图像生成任务,综合成本较按需模式降低58%(日均波动率<13%)
优势六:开发者生态 —— 无缝衔接AI研发生命周期
- 学术资源特权:免费访问arXiv/PubMed镜像站,论文PDF解析API每日限额500次
- MLOps工具箱:集成Weight&Biases监控、Gradio快速演示、Airflow调度等23个开发利器
- 社区激励计划:每月举办「最佳AI应用」评选,冠军项目可得$5000算力券+专属A100集群
生态成果:已有327个开源项目在GpuGeek社区孵化,其中17个项目获GitHub Trending周榜
四、从零开始实战指南
4.1 环境准备(5分钟快速入门)
4.1.1 注册与认证
# 安装CLI工具
pip install gpugeek-cli
# 登录认证
$ gpugeek login
✅ Authentication success! Welcome AI Developer!
# 领取新人礼包
$ gpugeek coupon apply NEWUSER2024
🎉 获得2000算力金(有效期30天)
4.1.2 实例创建
# 启动Llama3微调环境
$ gpugeek create \
--name llama3-ft \
--gpu-type A100-80G \
--gpu-count 4 \
--image llama3-finetune-kit \
--storage 500GB
# 实时监控
$ watch gpugeek monitor i-9a8b7c6d
GPU Utilization: ▇▇▇▇▇▇▇▇▇ 78%
VRAM Usage: 64GB/80GB
4.1.3 模型市场极速部署
from gpugeek.model_store import deploy_model
# 部署医疗影像模型
service = deploy_model(
model_id="med-sam-3d",
instance_type="T4-16G",
api_config={
"endpoint": "/predict",
"auth": {"type": "api_key"}
}
)
print(f"API Endpoint: {service.endpoint}")
# 输出示例:https://api.gpugeek.com/v1/med-sam-3d/predict
五、三大实战案例解析
案例1:金融风控模型全量微调
5.1.1 业务背景
- 数据量:300万用户行为记录
- 目标:识别高风险交易(准确率>92%)
5.1.2 技术方案
# 分布式训练脚本
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer = accelerator.prepare(model, optimizer)
for batch in dataloader:
with accelerator.accumulate(model):
loss = compute_loss(batch)
accelerator.backward(loss)
optimizer.step()
5.1.3 GpuGeek优势体现
- 弹性扩缩容:训练阶段8卡→推理阶段2卡自动切换
- 共享存储:500GB数据集多worker共享访问
5.1.4 性能对比
案例2:直播电商实时推荐系统
5.2.1 架构设计
5.2.2 关键配置
autoscale:
min_replicas: 2
max_replicas: 20
metrics:
- type: qps
threshold: 1000
- type: gpu_util
threshold: 75%
5.2.3 核心优势
- 秒级计费:流量波谷时段自动释放资源
- 模型热更新:无缝切换A/B测试模型
案例3:工业质检视觉系统
5.3.1 技术栈
- YOLOv9定制模型
- OpenMMLab训练框架
- Triton推理服务
5.3.2 流水线代码
# 自动化训练部署脚本
def train_and_deploy():
# 创建训练实例
trainer = gpugeek.create_instance(
gpu_type="A100",
image="openmmlab-2.0"
)
# 执行分布式训练
trainer.run("python tools/train.py configs/yolov9_custom.py")
# 模型转换
convert_to_onnx("work_dirs/best_model.pth")
# 部署推理服务
deploy_model(
model_path="yolov9.onnx",
triton_config="triton_model_repo"
)
5.3.3 效益提升
- 缺陷识别准确率:87% → 94.5%
- 单设备检测速度:220ms → 68ms
六、开发者生态与最佳实践
6.1 学术加速网络
# 加速GitHub克隆
$ git clone https://ghproxy.com/https://github.com/vllm-project/vllm
# 数据集极速下载
$ gpugeek dataset download coco2017
[速度对比] 原始链接: 800KB/s → 加速通道: 78MB/s
6.2 成本控制策略
# 费用预测算法
def cost_estimation(task):
if task.duration > 3600:
return task.gpu * 0.0038 * 3600
else:
return task.gpu * 0.0038 * task.duration
# 推荐资源配置
best_config = optimize_resources(
task_type="training",
budget=1000,
deadline=24*3600
)
七、总结
7.1 算力民主化的下一站
GpuGeek正在测试的量子-经典混合计算框架,已实现:
- 在QA任务中将transformer层替换为量子线路,推理速度提升12倍
- 通过Hybrid Backpropagation算法,混合精度训练收敛迭代减少37%
当每个开发者都能像使用水电一样获取算力,AI创新的边界将被彻底打破。
7.2 实测收益
7.2.1 开发效率
- 环境准备时间缩短98%
- 模型迭代周期提速5-8倍
7.2.2 经济效益
- 综合成本降低60%+
- 资源利用率达91%
7.3 注册试用通道
GpuGeek官网:点击此处立即体验🔥🔥🔥
通过GpuGeek平台,AI开发者可专注核心算法创新,将繁琐的基础设施运维交给专业平台。无论是初创团队的MVP验证,还是企业的生产系统部署,这里都提供最适配的GPU算力解决方案。即刻点击上方链接,开启您的AI开发新纪元!