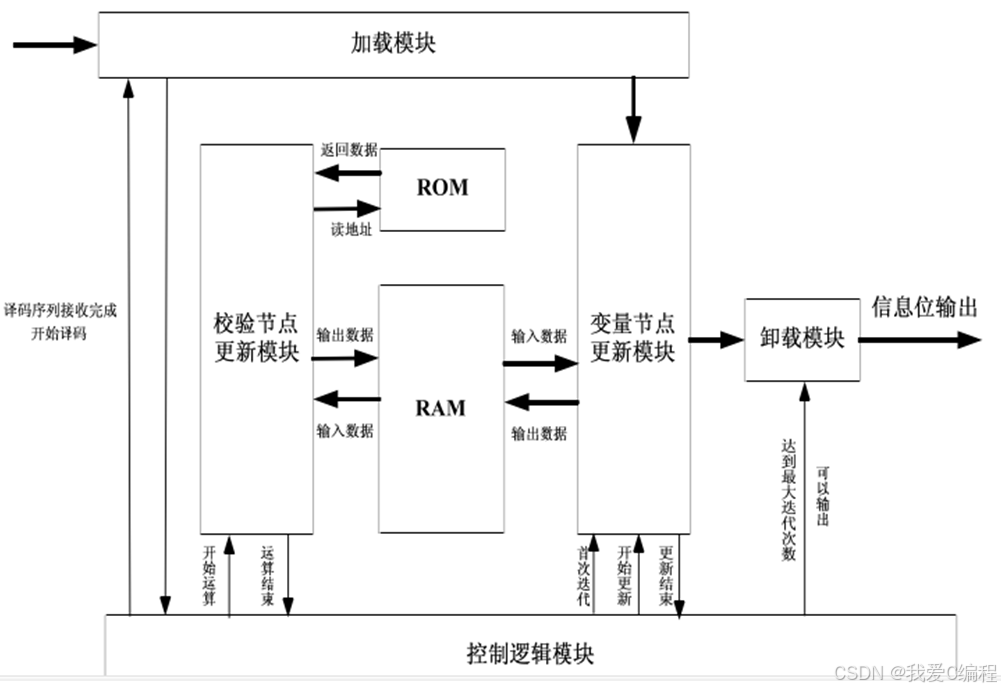
在目标检测任务中,不同框架使用的标注格式各不相同。常见的框架中,YOLO 使用 .txt 文件进行标注,而 PASCAL VOC 则使用 .xml 文件。如果你需要将一个 YOLO 格式的数据集转换为 VOC 格式以便适配其他模型,本文提供了一个结构清晰、可维护性强的 Python 脚本。
🧩 输入输出目录结构
✅ 输入目录结构(YOLO 格式)
<YOLO数据集名称>
├── train/
│ ├── images/
│ │ ├── img_000001.bmp
│ │ └── ...
│ └── labels/
│ ├── img_000001.txt
│ └── ...
└── val/
├── images/
│ ├── img_000100.bmp
│ └── ...
└── labels/
├── img_000100.txt
└── ...
✅ 输出目录结构(VOC 格式)
<VOC格式数据集名称>
├── JPEGImages/ # 转换后的图像文件(.jpg)
├── Annotations/ # 对应的XML标注文件
└── ImageSets/
└── Main/
├── train.txt
└── val.txt
🛠️ 配置参数说明
YOLO_DATASET_ROOT = '' # YOLO格式数据集根目录(输入)
VOC_OUTPUT_DIR = '' # VOC格式输出目录(输出)
CLASS_NAMES = [] # 类别名称列表,示例:['person', 'car', 'dog']
SPLITS = ['train', 'val'] # 数据集划分类型(训练集、验证集等)
VERBOSE = True # 是否输出详细日志
⚠️ 注意:你需要根据自己的项目路径和类别信息填写 YOLO_DATASET_ROOT、VOC_OUTPUT_DIR 和 CLASS_NAMES。
目前脚本默认处理 .bmp 图像并将其转为 .jpg,你可以根据需求修改扩展名以支持 .png、.jpeg 等格式。
完整代码如下:
import os
import xml.etree.ElementTree as ET
from xml.dom import minidom
import cv2
# -----------------------------
# 超参数配置(Hyperparameters)
# -----------------------------
YOLO_DATASET_ROOT = '' # YOLO格式数据集根目录(输入)
VOC_OUTPUT_DIR = '' # VOC格式输出目录(输出)
CLASS_NAMES = [] # 类别名称列表,示例:['person', 'car', 'dog']
SPLITS = ['train', 'val'] # 数据集划分类型(训练集、验证集等)
VERBOSE = True # 是否输出详细日志
def create_voc_annotation(image_path, label_path, annotations_output_dir):
"""
根据图像和YOLO标签生成PASCAL VOC格式的XML标注文件。
"""
image = cv2.imread(image_path)
height, width, depth = image.shape
annotation = ET.Element('annotation')
# .bmp -> .jpg
filename = os.path.basename(image_path).replace('.bmp', '.jpg')
ET.SubElement(annotation, 'folder').text = 'JPEGImages'
ET.SubElement(annotation, 'filename').text = filename
ET.SubElement(annotation, 'path').text = os.path.join(VOC_OUTPUT_DIR, 'JPEGImages', filename)
source = ET.SubElement(annotation, 'source')
ET.SubElement(source, 'database').text = 'Custom Dataset'
size = ET.SubElement(annotation, 'size')
ET.SubElement(size, 'width').text = str(width)
ET.SubElement(size, 'height').text = str(height)
ET.SubElement(size, 'depth').text = str(depth)
ET.SubElement(annotation, 'segmented').text = '0'
if os.path.exists(label_path):
with open(label_path, 'r') as f:
for line in f.readlines():
data = line.strip().split()
class_id = int(data[0])
x_center = float(data[1]) * width
y_center = float(data[2]) * height
bbox_width = float(data[3]) * width
bbox_height = float(data[4]) * height
xmin = int(x_center - bbox_width / 2)
ymin = int(y_center - bbox_height / 2)
xmax = int(x_center + bbox_width / 2)
ymax = int(y_center + bbox_height / 2)
obj = ET.SubElement(annotation, 'object')
ET.SubElement(obj, 'name').text = CLASS_NAMES[class_id]
ET.SubElement(obj, 'pose').text = 'Unspecified'
ET.SubElement(obj, 'truncated').text = '0'
ET.SubElement(obj, 'difficult').text = '0'
bndbox = ET.SubElement(obj, 'bndbox')
ET.SubElement(bndbox, 'xmin').text = str(xmin)
ET.SubElement(bndbox, 'ymin').text = str(ymin)
ET.SubElement(bndbox, 'xmax').text = str(xmax)
ET.SubElement(bndbox, 'ymax').text = str(ymax)
# 保存XML文件
xml_str = minidom.parseString(ET.tostring(annotation)).toprettyxml(indent=" ")
xml_filename = filename.replace('.jpg', '.xml')
xml_path = os.path.join(annotations_output_dir, xml_filename) # 确保这里只有一层Annotations目录
with open(xml_path, "w") as f:
f.write(xml_str)
if VERBOSE:
print(f"✅ 已生成标注文件: {xml_filename}")
def convert_dataset(input_dir, output_dir):
"""
将YOLO格式的数据集转换为VOC格式。
包括图像格式转换(.bmp -> .jpg)、生成XML标注文件,并创建ImageSets/Main/train.txt/val.txt。
"""
print("🔄 开始转换YOLO格式数据集到VOC格式...")
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for split in SPLITS:
images_dir = os.path.join(input_dir, split, 'images')
labels_dir = os.path.join(input_dir, split, 'labels')
output_images_dir = os.path.join(output_dir, 'JPEGImages')
output_annotations_dir = os.path.join(output_dir, 'Annotations')
output_imagesets_dir = os.path.join(output_dir, 'ImageSets', 'Main')
os.makedirs(output_images_dir, exist_ok=True)
os.makedirs(output_annotations_dir, exist_ok=True)
os.makedirs(output_imagesets_dir, exist_ok=True)
set_file_path = os.path.join(output_imagesets_dir, f"{split}.txt")
set_file = open(set_file_path, 'w')
count = 0
for filename in os.listdir(images_dir):
if filename.endswith('.bmp'):
image_path = os.path.join(images_dir, filename)
label_path = os.path.join(labels_dir, filename.replace('.bmp', '.txt'))
# 图像转换
new_image_name = filename.replace('.bmp', '.jpg')
new_image_path = os.path.join(output_images_dir, new_image_name)
image = cv2.imread(image_path)
cv2.imwrite(new_image_path, image)
# 写入ImageSets/Main/train.txt或val.txt
base_name = new_image_name.replace('.jpg', '')
set_file.write(f"{base_name}\n")
# 生成XML标注文件
create_voc_annotation(new_image_path, label_path, output_annotations_dir) # 确保传入的是Annotations目录路径
count += 1
if VERBOSE and count % 10 == 0:
print(f"🖼️ 已处理 {count} 张图片...")
set_file.close()
print(f"✅ 完成 [{split}] 分割集处理,共处理 {count} 张图片")
print("🎉 数据集转换完成!")
if __name__ == "__main__":
convert_dataset(YOLO_DATASET_ROOT, VOC_OUTPUT_DIR)
转换后效果:
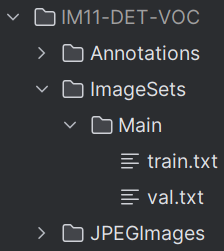
验证生成的VOC数据集中图片质量和数量是否合适可以用下面的脚本:
import os
import cv2
from xml.etree import ElementTree as ET
# -----------------------------
# 超参数配置(Hyperparameters)
# -----------------------------
DATASET_ROOT = '' # VOC格式数据集根目录
CLASS_NAMES = [] # 类别列表, 示例: ['car', 'person', 'dog']
VERBOSE = True # 是否输出详细日志
def count_images_in_set(imagesets_dir, set_name):
"""
统计ImageSets/Main目录下指定集合(train/val)的图片数量。
"""
set_file_path = os.path.join(imagesets_dir, f"{set_name}.txt")
if not os.path.exists(set_file_path):
print(f"[警告] 找不到 {set_name}.txt 文件,请确认是否生成正确划分文件。")
return 0
with open(set_file_path, 'r') as f:
lines = [line.strip() for line in f.readlines() if line.strip()]
return len(lines)
def check_images(jpeg_dir):
"""
检查JPEGImages目录下的所有图片是否都能正常加载。
"""
print("[检查] 验证图像是否可读...")
error_images = []
for filename in os.listdir(jpeg_dir):
if filename.lower().endswith(('.jpg', '.jpeg', '.png')):
image_path = os.path.join(jpeg_dir, filename)
try:
img = cv2.imread(image_path)
if img is None:
raise ValueError("无法加载图像")
except Exception as e:
error_images.append(filename)
if VERBOSE:
print(f" ❌ 图像加载失败: {filename} | 原因: {str(e)}")
return error_images
def validate_annotations(annotations_dir, jpeg_dir):
"""
验证Annotations目录下的XML标注文件是否与对应的图片匹配。
"""
print("[检查] 验证XML标注文件是否有效...")
error_annotations = []
for filename in os.listdir(annotations_dir):
if filename.endswith('.xml'):
xml_path = os.path.join(annotations_dir, filename)
try:
tree = ET.parse(xml_path)
root = tree.getroot()
jpg_filename = root.find('filename').text
if not os.path.exists(os.path.join(jpeg_dir, jpg_filename)):
raise FileNotFoundError(f"找不到对应的图像:{jpg_filename}")
except Exception as e:
error_annotations.append(filename)
if VERBOSE:
print(f" ❌ 标注文件异常: {filename} | 原因: {str(e)}")
return error_annotations
def verify_imagesets(imagesets_dir, jpeg_dir):
"""
确保ImageSets/Main中列出的所有图像都存在于JPEGImages中。
"""
print("[检查] 验证ImageSets/Main中列出的图像是否存在...")
missing_files = []
for set_name in ['train', 'val']:
set_file_path = os.path.join(imagesets_dir, f"{set_name}.txt")
if not os.path.exists(set_file_path):
continue
with open(set_file_path, 'r') as f:
for line in f:
img_id = line.strip()
if not img_id:
continue
img_path = os.path.join(jpeg_dir, f"{img_id}.jpg")
if not os.path.exists(img_path):
missing_files.append(f"{img_id}.jpg")
if VERBOSE:
print(f" ❌ 图像缺失: {img_id}.jpg")
return missing_files
def main():
print("🔍 开始验证VOC格式数据集...\n")
# 构建路径
jpeg_dir = os.path.join(DATASET_ROOT, 'JPEGImages')
annotations_dir = os.path.join(DATASET_ROOT, 'Annotations')
imagesets_dir = os.path.join(DATASET_ROOT, 'ImageSets', 'Main')
# 检查是否存在必要目录
for dir_path in [jpeg_dir, annotations_dir, imagesets_dir]:
if not os.path.exists(dir_path):
print(f"[错误] 必要目录不存在: {dir_path}")
exit(1)
# 1. 检查图像是否可读
error_images = check_images(jpeg_dir)
if error_images:
print(f"⚠️ 共发现 {len(error_images)} 张图片加载失败:")
for img in error_images:
print(f" - {img}")
else:
print("✅ 所有图像均可正常加载。\n")
# 2. 检查XML标注文件是否有效
error_annotations = validate_annotations(annotations_dir, jpeg_dir)
if error_annotations:
print(f"⚠️ 共发现 {len(error_annotations)} 个无效或不匹配的XML标注文件:")
for ann in error_annotations:
print(f" - {ann}")
else:
print("✅ 所有XML标注文件均有效且与对应图像匹配。\n")
# 3. 检查ImageSets/Main中引用的图像是否存在
missing_files = verify_imagesets(imagesets_dir, jpeg_dir)
if missing_files:
print(f"⚠️ 共发现 {len(missing_files)} 张图像在ImageSets中被引用但实际不存在:")
for img in missing_files:
print(f" - {img}")
else:
print("✅ ImageSets/Main中引用的所有图像均存在。\n")
# 4. 输出训练集和验证集的图像数量
train_count = count_images_in_set(imagesets_dir, 'train')
val_count = count_images_in_set(imagesets_dir, 'val')
total_count = train_count + val_count
print("📊 数据集统计:")
print(f" - 训练集: {train_count} 张")
print(f" - 验证集: {val_count} 张")
print(f" - 总数: {total_count} 张\n")
print("🎉 验证完成!")
if __name__ == "__main__":
main()
验证效果为: