一、什么是神经网络
人工神经网络(Articial Neural Network,简写为ANN)也称为神经网络(NN),是一种模仿生物神经网络和功能的计算模型,人脑可以看做是一个生物神经网络,由众多的神经元连接而成,各个神经元传递复杂的电信号,树突接收到输入信号,然后对信号进行处理,通过轴突输出信号。人工神经网络也是类似,通过模仿人脑的“学习机器”,通过不断“看”数据(比如图片,数字),自己总结规律,最终学会预测(比如分类图片)
1.1、如何构建人工神经网络中的神经元
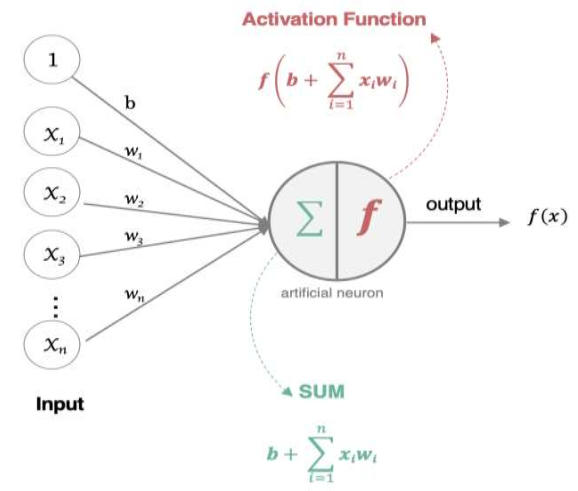
神经元=输入X权重+偏置->激活函数
权重:调节每个输入的重要性(类似音量旋钮)
偏置:调整输出的基准线(比如天生爱吃甜食)
激活函数:决定是否触发输出(比如及格线60分)
权重和偏置怎么来的?
一开始随机初始化,训练时通过数据自动调整到最优值
1.1、神经网络
使用多个神经元来构建神经网络,相邻之间的神经元相互连接,并给每一个连接分配一个强度,如下图:
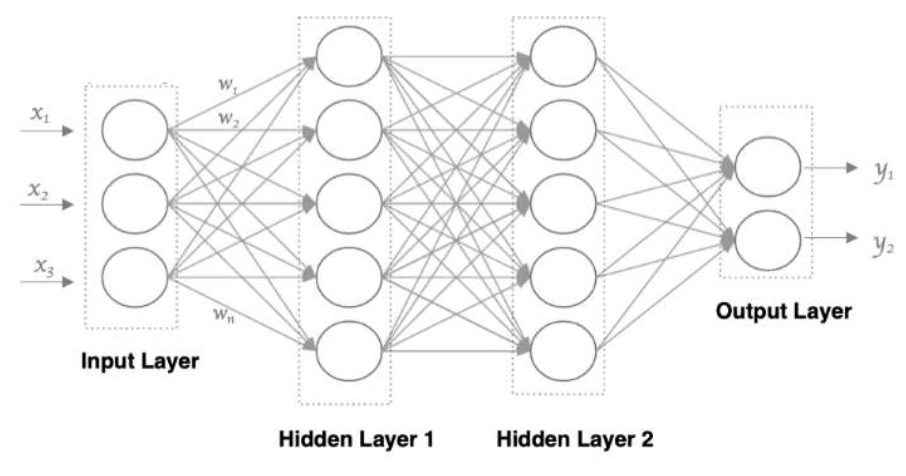
神经网络中信息只向一个方向移动,即从输入节点向前移动,通过隐藏节点,再向输出节点移动,神经元的三层结构:
输入层:
- 像眼睛一样接受数据,比如输入一张3个数字的表格(比如身高,体重,年龄)
- 代码层面对应的是:my_data = torch.randn(5,3)生成一个5行3列的随机数据(5个人,每人3个特征)
隐藏层
- 像大脑一样处理数据,图中有两层“脑细胞”(Hidder Layer1和Hidden Layer2)
输出层:
- 像“嘴巴”一样给出答案,比如输出两个结果,y1,y2
1.2、神经网络的特点:
- 同一层的神经元之间没有连接。
- 第N层的每个神经元和第N-1层的所有神经元相连(full conneted的含义),这就是全连接神经网络
- 第N-1层神经元的输出就是第N层神经元的输入
- 每个连接都有一个权重值(w系数和b系数)
深度学习与机器学习的关系
深度学习是机器学习的一个分支,深度学习用多层神经网络(尤其是深层的网络)来学习数据,自动从数据中提取复杂特征,不用人工设计规则。
二、激活函数
激活函数用于对每层的输出数据进行变换,进而为整个网络注入非线性因素,此时,神经网络就可以拟合各种曲线,没有引入非线性因素的网络等价于使用一个线性模型来拟合
通过给网格输出增加激活函数,实现引入非线性因素,使得网络模型可以逼近任意函数,提升网络对复杂问题的拟合能力
2.1、常见的激活函数
1、sigmoid激活函数
- 可以将任意的输入映射到(0,1)之间,当输入的值大致在<-6或者>6时,意味着输入任何值得到的激活值都是差不多的,这样会丢失部分信息
- 对于sigmoid函数而言,输入值在[-6,6]之间输出值才有明显差异,输入值在[3,-3]之间才会有比较好的效果
- sigmoid网络在5层之内就会产生梯度消失现象,该激活函数并不是以0为中心的,在实践中这种激活函数使用的很少,一般只用于二分类的输出层
2、tanh激活函数
- Tanh 函数将输入映射到 (-1, 1) 之间,图像以 0 为中心,在 0 点对称,当输入 大概<-3 或者>3 时将被映射为 -1 或者 1。其导数值范围 (0, 1),当输入的值大概 <-3 或者 > 3 时,其导数近似 0
- 与 Sigmoid 相比,它是以 0 为中心的,且梯度相对于sigmoid大,使得其收敛速度要比Sigmoid 快,减少迭代次数。然而,从图中可以看出,Tanh 两侧的导数也为 0,同样会造成梯度消失
- 若使用时可在隐藏层使用tanh函数,在输出层使用sigmoid函数
3、softMax激活函数
softMax用于多分类过程中,是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展示出来,将网络输出的logits通过softMax函数,映射成为(0,1)的值,这些值的累加和为1,选取概率最大的节点,作为我们的预测目标类别
4、ReLU激活函数
ReLU 激活函数将小于 0 的值映射为 0,而大于 0 的值则保持不变,它更加重视正信号,而忽略负信号,这种激活函数运算更为简单,能够提高模型的训练效率。
当x<0时,ReLU导数为0,而当x>0时,则不存在饱和问题。所以,ReLU 能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。然而,随着训练的推进,部分输入会落入小于0区域,导致对应权重无法更新。这种现象被称为“神经元死亡”。
ReLU是目前最常用的激活函数。与sigmoid相比,RELU的优势是:
采用sigmoid函数,计算量大(指数运算),反向传播求误差梯度时,计算量相对大,而采用
Relu激活函数,整个过程的计算量节省很多。 sigmoid函数反向传播时,很容易就会出现梯度
消失的情况,从而无法完成深层网络的训练。 Relu会使一部分神经元的输出为0,这样就造成了
网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生
2.2、激活函数的选择方法
对于隐藏层:
- 优先选择ReLU激活函数
- 如果ReLu效果,可以尝试选择其他激活,如Leakly ReLu等
- 如果你使用了ReLU, 需要注意一下Dead ReLU问题, 避免出现大的梯度从而导致过多的神经元死亡。
- 少用使用sigmoid激活函数,可以尝试使用tanh激活函数
对于输出层:
- 二分类问题选择sigmoid激活函数
- 多分类问题选择softmax激活函数
- 回归问题选择identity激活函数
2.3、参数初始化
- 均匀分布初始化
权重参数初始化从区间均匀随机取值。即在(-1/√d,1/√d)均匀分布中生成当前神经元的权重,其中d为每个神经元的输入数量
- 正态分布式初始化
随机初始化从均值为0,标准差是1的高斯分布中取样,使用一些很小的值,对参数W进行初始化
- 全0初始化
将神经网络中的所有权重参数初始化为0
- 全1初始化
将神经网络中的所有权重参数初始化为1
- 固定值初始化
将神经网络中的所有权重参数初始化为某个固定值
- kaiming初始化,也叫做HE初始化
HE 初始化分为正态分布的 HE 初始化、均匀分布的 HE 初始化
正态化的he初始化
stddev = sqrt(2 / fan_in)
均匀分布的he初始化
它从 [-limit,limit] 中的均匀分布中抽取样本, limit是 sqrt(6 / fan_in)
fan_in输入神经元的个数
xavier初始化,也叫做Glorot初始化
该方法也有两种,一种是正态分布的 xavier 初始化、一种是均匀分布的 xavier 初始化
正态化的Xavier初始化
stddev = sqrt(2 / (fan_in + fan_out))
均匀分布的Xavier初始化
[-limit,limit] 中的均匀分布中抽取样本, limit 是 sqrt(6 / (fan_in + fan_out))
fan_in是输入神经元的个数,fan_out是输出的神经元个数
初始化代码:
import torch
import torch.nn.functional as F
import torch.nn as nn
#1. 均匀分布随机初始化
def test01():
print(f"均匀分布随机初始化{'='*30}均匀分布随机初始化")
linear = nn.Linear(5,3)
nn.init.uniform_(linear.weight)
print(linear.weight.data)
# 2、固定初始化
def test02():
print(f"固定初始化{'='*30}固定初始化")
linear = nn.Linear(5,3)
nn.init.constant_(linear.weight,5)
print(linear.weight.data)
#3、全0初始化
def test03():
print(f"全0初始化{'='*30}全0初始化")
linear = nn.Linear(5,3)
nn.init.zeros_(linear.weight)
print(linear.weight.data)
def test04():
print(f"全1初始化{'='*30}全1初始化")
linear = nn.Linear(5,3)
nn.init.ones_(linear.weight)
print(linear.weight.data)
#适合从正态分布 N(mean,std^2) 采样权重。
#需手动调整方差,适合浅层网络或特定分布假设
def test05():
print(f"正态分布随机初始化{'='*30}正态分布随机初始化")
linear = nn.Linear(5,3)
# mean:均值,默认0
#std 标准差,默认1
nn.init.normal_(linear.weight,mean=0,std=1)
print(linear.weight.data)
#6、kaiming 初始化
#针对ReLU族激活函数设计,根据输入/输出维度调整方差
#适合深层网络(如CNN)、ReLU/Leaky ReLU激活函数
def test06():
print(f"kaiming正态分布初始化{'='*30}kaiming正态分布初始化")
#kaiming正态分布初始化
linear = nn.Linear(5,3)
nn.init.kaiming_normal_(linear.weight)
print(linear.weight.data)
print(f"kaiming均匀分布初始化{'='*30}kaiming均匀分布初始化")
#kaiming均匀分布初始化
linear = nn.Linear(5,3)
#nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
#mode:fan_in(前向传播,默认)或 fan_out(反向传播)
#nonlinearity:激活函数类型(如 relu, leaky_relu)
nn.init.kaiming_normal_(linear.weight)
print(linear.weight.data)
#kaiming均匀分布初始化
linear = nn.Linear(5,3)
nn.init.kaiming_uniform_(linear.weight)
print(linear.weight.data)
#7xavier初始化
#正态分布:nn.init.xavier_normal_(tensor, gain=1.0)
#均匀分布:nn.init.xavier_uniform_(tensor, gain=1.0)
#保持输入输出方差一致,适用于对称激活函数(如tanh、sigmoid)
#gain:根据激活函数调整的缩放因子(如tanh的gain=5/3)
def test07():
print(f"xavier正态分布初始化{'='*30}xavier正态分布初始化")
#xavier正态分布初始化
linear = nn.Linear(5,3)
nn.init.xavier_uniform_(linear.weight)
print(linear.weight.data)
print(f"xavier均匀分布初始化{'='*30}xavier均匀分布初始化")
liner = nn.Linear(5,3)
nn.init.xavier_uniform_(linear.weight)
print(linear.weight.data)
if __name__ =="__main__":
test01()
test02()
test03()
test04()
test05()
test06()
test07()
输出结果:
均匀分布随机初始化==============================均匀分布随机初始化
tensor([[0.6716, 0.1197, 0.7008, 0.0801, 0.8953],
[0.0483, 0.4593, 0.5607, 0.2824, 0.1307],
[0.5942, 0.7758, 0.1852, 0.8597, 0.5166]])
固定初始化==============================固定初始化
tensor([[5., 5., 5.,