1 _npu_backend
文章还是从代码开始
import torch_npu, torchair
config = torchair.CompilerConfig()
# 设置图下沉执行模式
config.mode = "reduce-overhead"
npu_backend = torchair.get_npu_backend(compiler_config=config)
opt_model = torch.compile(model, backend=npu_backend)
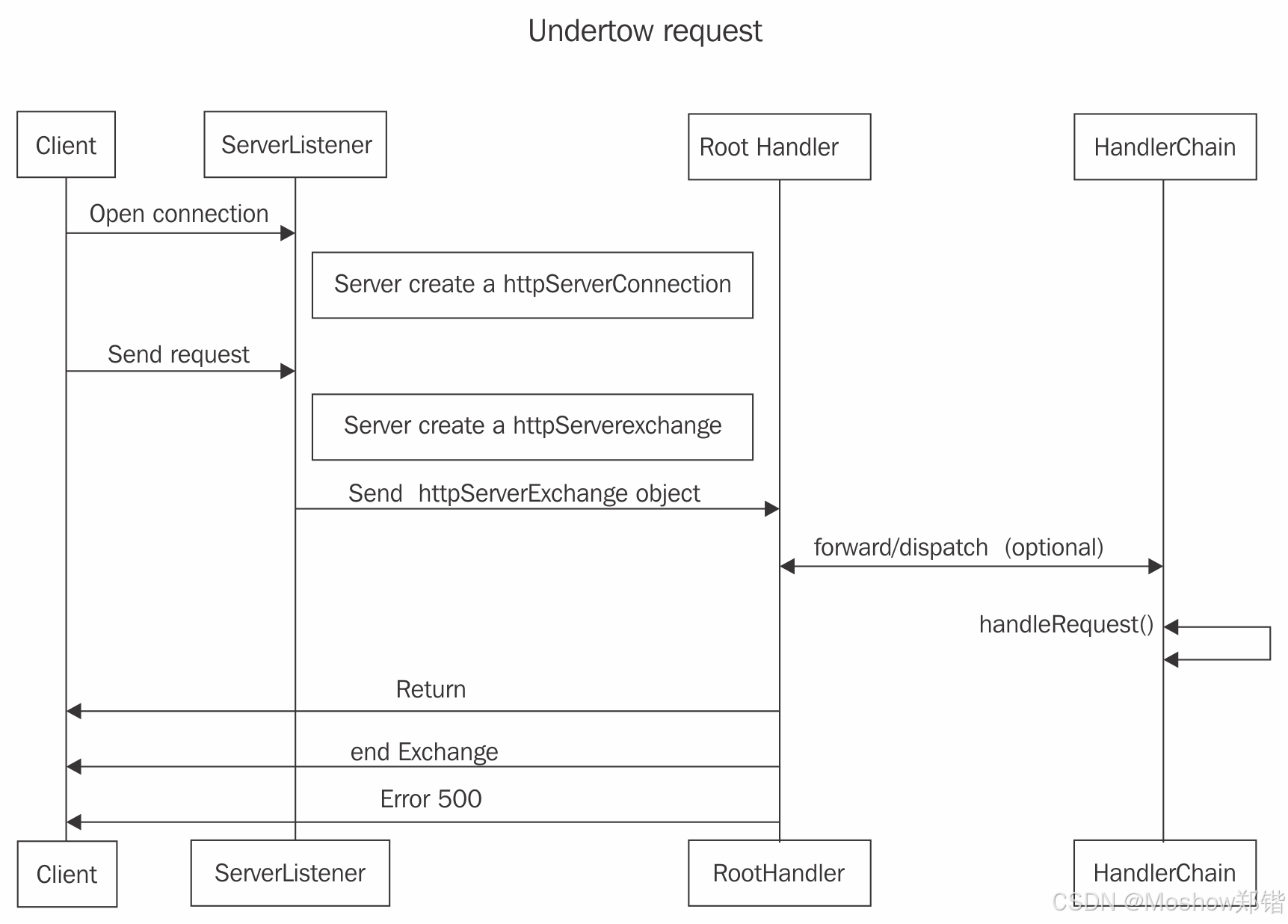
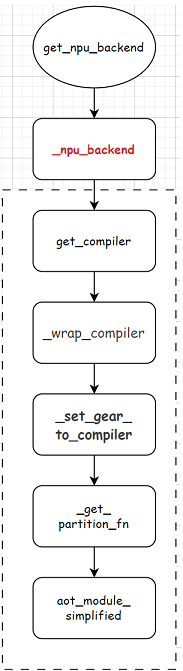
get_npu_backend调用的是_npu_backend函数。整体流程图如下:
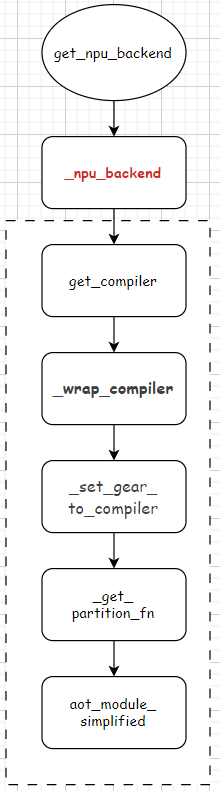
上文Ascend的aclgraph(一)aclgraph是什么?torchair又是怎么成图的?对get_compiler函数进行了分析。本章接着分析剩余的4个部分。
1.1 _wrap_compiler
_wrap_compiler是一个装饰器,先看代码:
def _wrap_compiler(compiler: Callable, compiler_config: CompilerConfig):
@functools.wraps(compiler)
def wrapped_compiler(
gm: torch.fx.GraphModule,
example_inputs: List[torch.Tensor],
is_inference: bool
):
if is_inference and compiler_config.experimental_config.npu_fx_pass:
_npu_joint_graph_passes(gm)
return compiler(gm, example_inputs)
@functools.wraps(compiler)
def joint_compiler(
gm: torch.fx.GraphModule,
example_inputs: List[torch.Tensor]
):
if compiler_config.experimental_config.npu_fx_pass:
_npu_joint_graph_passes(gm)
return compiler(gm, example_inputs)
fw_compiler = functools.partial(wrapped_compiler, is_inference=False)
inference_compiler = functools.partial(wrapped_compiler, is_inference=True)
return fw_compiler, inference_compiler, joint_compiler
依旧使用了python的偏函数的功能:functools.partial。该函数中主要返回了3个compiler对象。
首先是wrapped_compiler,该函数的功能是主要功能就是调用compiler(gm, example_inputs),但根据是否是推理场景,加入了_npu_joint_graph_passes(torch._inductor.fx_passes.joint_graph模块提供)。
joint_graph在torch.compile中一般表示的前向和反向混在一起的一张联合图。
- 对
wrapped_compiler函数进行了2次封装,区别在于is_inference参数。从代码上推测,_npu_joint_graph_passes在推理的时候,需要对图进行_npu_joint_graph_passes优化。在is_inference = True的时候,返回inference_compiler。在is_inference = False的时候,返回fw_compiler,可以认为该compile是带有反向图功能的。这里也可以看出,torchair也是可以用在训练里面的。 - 另外根据
compiler_config.experimental_config.npu_fx_pass参数,专门返回了一个joint_compiler函数。
通过该装饰器,总共返回3个compile执行函数。
return fw_compiler, inference_compiler, joint_compiler
1.2 _set_gear_to_compiler
接着看_set_gear_to_compiler函数。
该函数依旧是个装饰器。先理解下guard是什么,这也是torch.compile中的概念。
在 PyTorch 的 torch.compile 功能中,“guard” 是一个关键概念,它用于确保编译后的代码仅在满足特定条件时执行。Guard 本质上是编译器为了保证优化后的模型行为与原始未优化模型一致而设置的断言或检查点。
Guard 的组成
Guards 主要由以下几部分组成:
- 类型检查:确保输入张量的数据类型保持不变。
- 形状检查:验证输入张量的形状是否符合预期。这对于动态形状的模型尤为重要。
- 设备检查:确认所有张量都在正确的设备(如 CPU 或 GPU)上。
- 值检查:在某些情况下,可能还需要对特定值进行检查以确保逻辑正确性。例如,对于依赖于某个具体值的控制流。
Guard 的作用
- 稳定性:Guards 确保了即使在不同的运行条件下,编译后的模型也能稳定、正确地运行。如果任何 guard 条件不满足,则会触发回退机制,即重新追踪或编译该部分计算图。
- 性能优化:通过设置 guards,编译器能够在假设这些条件始终成立的情况下应用更激进的优化策略,因为它们不需要考虑所有可能的变化情况。这可以显著提高执行效率和资源利用率。
- 动态适应性:尽管静态编译能够带来性能提升,但深度学习模型往往需要处理多样化的输入。Guards 提供了一种方式来平衡静态编译带来的性能优势与动态适应不同输入需求之间的矛盾。
举例来说,在使用 torch.compile 对模型进行编译时,如果你有一个接受可变批次大小的模型,那么编译器会在生成的代码中加入关于输入张量形状的 guards。这意味着,只要输入的批次大小不超过预设的最大值并且不低于最小值,优化后的代码就会被执行;否则,将触发重新编译或者采用默认执行路径。
重点关注函数中的guard_gears_shape。该函数是对图输入的情况进行判断,输入的tensor的shape需要在指定的范围内变化,也就说,torchair当前使用torch.compile支持有限个shape是变化的场景。如果超过了指定的范围,程序就会就会报错推出。
def _set_gear_to_compiler(compiler: Callable, compiler_config: CompilerConfig, input_dim_gears: Dict[int, List[int]]):
@functools.wraps(compiler)
def gear_compiler(
gm: torch.fx.GraphModule,
example_inputs: List[torch.Tensor],
):
for i, dim_gears in input_dim_gears.items():
set_dim_gears(example_inputs[i], dim_gears)
guard_gears_shape(example_inputs)
return compiler(gm, example_inputs)
return gear_compiler
注意,_npu_backend中对上述的fw_compiler和inference_compiler都调用了_set_gear_to_compiler函数。这里也好也好理解,训练和推理都是要确认图的功能是正确的,对图是否改变要有感知。
fw_compiler = _set_gear_to_compiler(fw_compiler, compiler_config, input_dim_gears)
inference_compiler = _set_gear_to_compiler(inference_compiler, compiler_config, input_dim_gears)
1.3 _get_partition_fn
接着看_get_partition_fn函数。
def _get_partition_fn(compiler_config: CompilerConfig):
def partition_fn(graph: torch.fx.GraphModule, joint_inputs, **kwargs):
_npu_joint_graph_passes(graph)
return default_partition(graph, joint_inputs, **kwargs)
if compiler_config.experimental_config.npu_fx_pass:
return partition_fn
return default_partition
partition是torch.compile中计算图拆分的概念,也就是将joint graph的图拆分为前向图和反向图,此处先给出default_partition的解释。
default_partition:模拟了PyTorch的默认行为,找出从forward的输入到输出的所有算子输出,剩余部分都视为backward部分,从而分割出正反向graph,forward的所有中间结果都保存用于backward。
default_partition是torch._functorch.partitioners中的函数。_get_partition_fn返回的partition函数类型与compiler_config.experimental_config.npu_fx_pass参数相关。在配置compiler_config.experimental_config.npu_fx_pass情况下,返回与输入参数joint_inputs相关的partition函数。
return default_partition(graph, joint_inputs, **kwargs)
1.4 aot_module_simplified
aot_module_simplified是_npu_backend中的最后一个调用函数。
return aot_module_simplified(gm, example_inputs, fw_compiler=fw_compiler, bw_compiler=compiler,
decompositions=decompositions, partition_fn=partition_fn,
keep_inference_input_mutations=keep_inference_input_mutations,
inference_compiler=inference_compiler)
aot_module_simplified是torch._functorch.aot_autograd中的函数,看如下注释。
aot_module_simplified
是 PyTorch 中与 Ahead-of-Time (AOT) 编译相关的函数,特别是在使用 TorchInductor 后端时。AOT 编译是指在模型运行之前预先编译模型的计算图,以期达到加速执行和优化资源使用的目的。
在 PyTorch 中,TorchInductor 是 torch.compile 的一个后端,它旨在为 GPU 和 CPU 生成高度优化的代码。aot_module_simplified 函数通常用于简化将一个 PyTorch 模型准备好进行 AOT 编译的过程,简单理解就是AOT编译前的预操作。其主要作用包括:
- 准备模型进行AOT编译:该函数帮助用户方便地指定需要进行 AOT 编译的模型部分。通过处理模型的输入输出、设置必要的编译参数等,使得模型可以直接进入编译流程。
- 优化计算图:在编译阶段,aot_module_simplified 可能会应用一系列优化措施,如算子融合、内存优化等,目的是提高最终编译产物的执行效率。
- 简化流程:正如其名“simplified”所暗示的,这个函数简化了 AOT 编译的准备工作,允许用户以较少的代码实现模型的编译和优化,而不需要深入了解编译过程中的复杂细节。
- 跨设备支持:它可能还提供对不同硬件平台的支持,确保编译后的模型可以在指定的目标设备(如GPU或CPU)上高效运行。
总的来说,aot_module_simplified 提供了一种简化的方式,让开发者可以更容易地利用 PyTorch 的 AOT 编译功能来优化他们的模型性能,尤其是在使用 TorchInductor 后端时。这有助于降低高性能模型部署的门槛,使得更多开发者能够从先进的编译技术和硬件优化中受益。需要注意的是,具体的实现细节可能会随着 PyTorch 版本的更新而有所变化。
2 torch.compile
回到最开始的例子中,可以看到传入到torch.compile中的backend是get_npu_backend返回的,也就是
npu_backend = torchair.get_npu_backend(compiler_config=config)
opt_model = torch.compile(model, backend=npu_backend)
从Ascend的aclgraph(一)aclgraph是什么?torchair又是怎么成图的?开始,反反复复提到了torch.compile概念,看来想了解aclgraph,必须对torch.compile做一个基本的了解。
但由于其代码内容比较复杂,小编认知有限,接下来的内容,对其涉及到的基本概念做个介绍。
2.1 torch.compile背景
参考:https://zhuanlan.zhihu.com/p/9418379234
为了改善模型训练推理性能,Pytorch推出torch.compile,并从torch 1.xx更为torch 2.xx,改变并增强了Pytorch在编译器级别的运行方式,同时开始将pytorch的部分代码从C++迁移回python,主要有以下特点:
- 将动态的 PyTorch 模型转换为静态的、优化过的执行图,从而减少运行时的开销,提高计算效率。
- 用户无需手动修改模型代码或选择特定的优化策略,torch.compile可以自动识别和应用最佳的优化路径,使得模型加速更加便捷。
- 支持广泛的 PyTorch API 和操作,确保大部分现有模型在使用 torch.compile后无需进行大的调整即可获益于性能提升。
torch.compile的出现给我的感觉就是,torch.eager模式性能基本优化到头了,从python->c++->cuda(npu),流程上已经没有可以优化的空间。而如果将模型整形成一张图,图的优化空间比较大,有可为。可能有的小伙伴会问:tensorflow的图模式不是已经很好了吗?tensorflow为什么会日落西山了
这里允许小编胡诌一下。
1、tensorflow在小模型时代,或者说模型输入shape,dtype或format如果保持不变的话,那么使用tensorflow成图的性能依旧不输torch的eager模式,甚至是现在的torch.compile模式;
2、时代成就英雄。tensorflow以图模式(性能)起家,torch以eager模式(易用性)起家,而时代的浪潮是:模型的输入是动态shape的。
- 图模式的性能来源于:模型结构不变(也即是没有if,else等能改变图结构)、输入shape不变(显存效率)等。这样的情况下,模型能做各种算子融合、ir融合的pass,内存利用率也能达到极致。
- 而在动态shape下,图模式的这些优势荡然无存,反而因为图的反复编译,造成的性能的劣化。而torch以eager模式不存在图编译的概念,每次都是单算子下发,时代的浪潮并没有掀翻它,反而是在给它助力。
mindspore(昇思),起步也是从图模式开始,没有赶上时代的步伐,现在还在时代浪潮中被拉扯,而回头看pytorch已然成为了AI领域的的基础设施。
留个问题:大语言模型(LLM)时代,模型的输入也是变化的,那么做图模式的收益来自于哪里呢?
想想看,哪些地方的输入shape是不变的。回答留在后面的文章中。
2.2 torch.compile的组成
torch.compile主要包含四个基础组件:
- TorchDynamo:从python bytecode中解析构建计算图,是一个动态的、Python级别的编译器,旨在捕捉 PyTorch 模型的动态执行路径,将其转换为优化代码,实现bytecode-to-bytecode编译。
- AOTAutograd:是 PyTorch 引入的一种自动求导机制,旨在在模型执行之前预先生成梯度计算的代码。这种方法通过静态分析模型的前向计算图,提前生成反向传播所需的梯度计算逻辑,从而减少运行时的开销,提升训练效率。
- PrimTorch:将2000+ Pytorch op规范化为约250个原始op封闭集合,是 PyTorch 的一个中间表示(Intermediate Representation, IR)层,负责将高层的 PyTorch 操作转换为更低层次的、适合进一步优化和编译的基础操作。它通过简化和标准化操作,提高编译器和后端优化器处理计算图的效率。
- TorchInductor:深度学习编译器,可为多种加速器和后端生成代码,生成OpenAI Triton(Nvidia/AMD GPU)和OpenMP/C++(CPU)代码,它利用多种优化技术,包括内存优化、并行化和低层次的代码生成,以最大化计算性能。
以上四个组件都是用Python编写的,支持动态shape(即能够发送不同大小的张量而无需重新编译),实现灵活并减低开发人员和供应商开发门槛的效果。
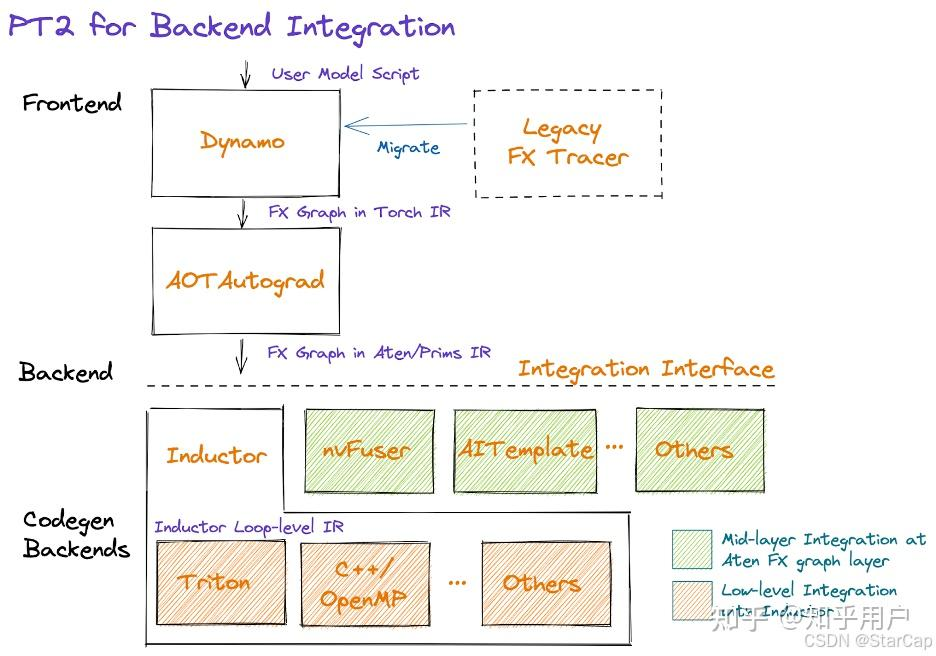
2.3 torch.compile支持的后端
当前支持的后端有:
>>> import torch
>>> import torch._dynamo as dynamo
>>> dynamo.list_backends()
['cudagraphs', 'inductor', 'onnxrt', 'openxla', 'tvm']
一般默认的是inductor,使用的方式是:
import torch
import torchvision.models as models
model = models.resnet18().cuda(
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
compiled_model = torch.compile(model, backend="inductor") # 通过backend参数指定后端,默认为inductor
# compiled_model = torch._dynamo.optimize("inductor")(fn) # 也可以通过torch._dynamo.optmize函数进行编译
x = torch.randn(16, 3, 224, 224).cuda()
optimizer.zero_grad()
out = compiled_model(x)
out.sum().backward()
optimizer.step()
请注意代码中注释的部分:
compiled_model = torch.compile(model, backend="inductor") # 通过backend参数指定后端,默认为inductor
# compiled_model = torch._dynamo.optimize("inductor")(fn) # 也可以通过torch._dynamo.optmize函数进行编译
也就是说torch._dynamo.optimize("inductor")(fn)和torch.compile(model, backend="inductor")是等价调用的。
2.3.1 torch.compile调用
torch.compile函数源码解析:torch.compile只是对torch._dynamo.optmize函数的简单封装
def compile(model: Optional[Callable] = None, *, # Module/function to optimize
fullgraph: builtins.bool = False, #If False (default), torch.compile attempts to discover compileable regions in the function that it will optimize. If True, then we require that the entire function be capturable into a single graph. If this is not possible (that is, if there are graph breaks), then this will raise an error.
dynamic: Optional[builtins.bool] = None, # dynamic shape
backend: Union[str, Callable] = "inductor", # backend to be used
mode: Union[str, None] = None, # Can be either "default", "reduce-overhead", "max-autotune" or "max-autotune-no-cudagraphs"
options: Optional[Dict[str, Union[str, builtins.int, builtins.bool]]] = None, # A dictionary of options to pass to the backend. Some notable ones to try out are
disable: builtins.bool = False) # Turn torch.compile() into a no-op for testing
-> Callable:
# 中间代码省略...
return torch._dynamo.optimize(backend=backend, nopython=fullgraph, dynamic=dynamic, disable=disable)(model)
torch._dynamo.optimize函数解析:进一步分析torch._dynamo.optimize的函数调用栈,会发现torch._dynamo.optimize只是通过_optimize_catch_errors函数返回了一个OptimizeContext对象。
def _optimize(
rebuild_ctx: Callable[[], Union[OptimizeContext, _NullDecorator]],
backend="inductor",
*,
nopython=False,
guard_export_fn=None,
guard_fail_fn=None,
disable=False,
dynamic=None,
) -> Union[OptimizeContext, _NullDecorator]:
# 中间代码省略...
return _optimize_catch_errors(
convert_frame.convert_frame(backend, hooks=hooks), // backend,回调函数
hooks,
backend_ctx_ctor,
dynamic=dynamic,
compiler_config=backend.get_compiler_config()
if hasattr(backend, "get_compiler_config")
else None,
rebuild_ctx=rebuild_ctx,
)
# ---------------------------------------------------------------------------------------------------------------------------------------
def _optimize_catch_errors(
compile_fn,
hooks: Hooks,
backend_ctx_ctor=null_context,
export=False,
dynamic=None,
compiler_config=None,
rebuild_ctx=None,
):
return OptimizeContext(
convert_frame.catch_errors_wrapper(compile_fn, hooks), // 回调函数
backend_ctx_ctor=backend_ctx_ctor,
first_ctx=True,
export=export,
dynamic=dynamic,
compiler_config=compiler_config,
rebuild_ctx=rebuild_ctx,
)
因此,经过torch.compile装饰过的函数/模型成为一个OptimizeContext,其中convert_frame.catch_errors_wrapper成为了OptimizeContext中的一个回调函数 (callback),而这个回调函数包含编译函数入口,如inductor或自定义编译函数。由此可见,torch.compile并没有进行实际的编译,只是做一些简单的初始化工作,只有第一次正式执行代码前才会进行编译。
torch.compile优化流程:基于TorchDynamo和AOTAutograd构建Pytorch的前向和反向计算图,通过PrimTorch将op拆解转化为更低层次的、适合进一步优化和编译的基础op,最后Inductor进行算子融合等图优化并针对特定硬件生成triton(GPU)或OpenMP/C++(CPU)优化代码。
2.3.2 实现自定义的backend后端
从如上TorchInductor的定义:深度学习编译器,可为多种加速器和后端生成代码,生成OpenAI Triton(Nvidia/AMD GPU)和OpenMP/C++(CPU)代码。也就是说,这种后端的作用,是为了生成能够执行的代码。那是否可以自己自定义后端实现?来来来,结合例子试一下。
import torch
from typing import List
import torch._dynamo as dynamo
def my_compiler(gm: torch.fx.GraphModule, example_inputs_: List[torch.Tensor]):
print("===============my compiler=================")
gm.graph.print_tabular() # 格式化输出FX Graph
print("code is:",gm.code) # 对应的python代码
return gm
# 调用torch._dynamo.optimize函数
def my_func(x, y):
if x.sum() > y.sum():
loss = torch.cos(torch.cos(x))
else:
loss = torch.cos(torch.cos(y))
return loss
def test():
func = dynamo.optimize(my_compiler)(my_func) // my_compiler就是自定义的后端,my_func就是模型
x, y = torch.randn(10,requires_grad=True), torch.randn(10,requires_grad=True)
func(x,y)
test()
如上,my_compiler就是自定义的而后端。
看到这里也就明白了。_npu_backend的后端也是自定义的,生成的或者优化后的代码是能在npu上执行的代码。
下一篇对TorchDynamo做个一个简单的了解。