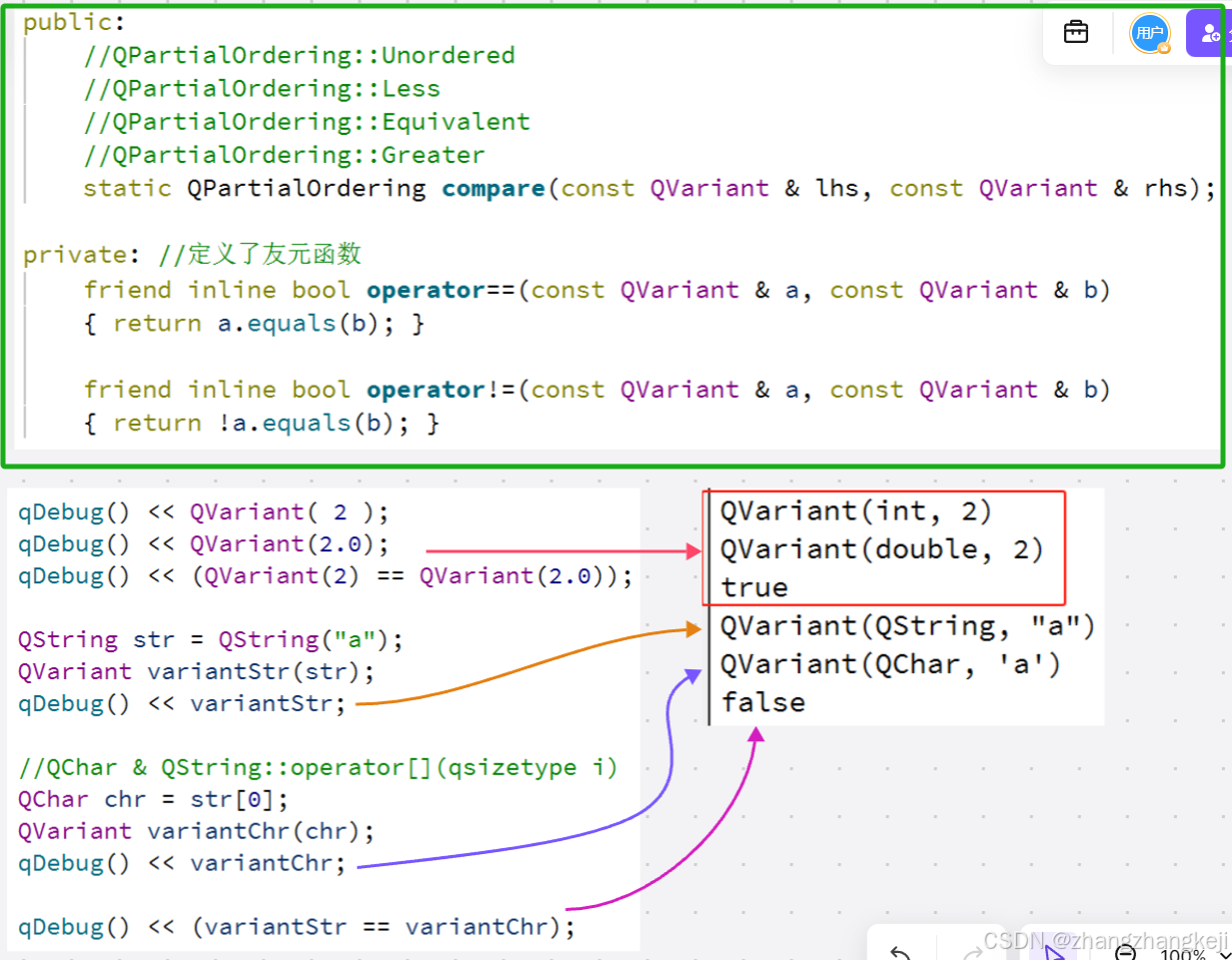
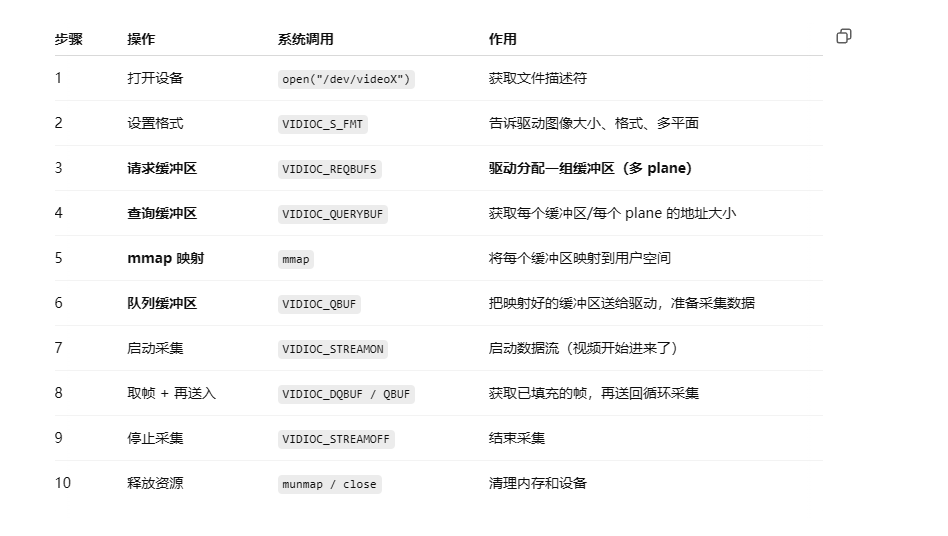
切分词语,normalization
给你一段句子,然后将这段句子拆分成一个一个的单个的单词,同时对每个单词进行
normalization(时态转换,单复数转换),分词器
recall,召回率:搜索的时候,增加能够搜索到的结果的数量
1 character filter:在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html
标签(<span>hello<span> ‐‐> hello),& ‐‐> and(I&you ‐‐> I and you)
2
3 tokenizer:分词,hello you and me ‐‐> hello, you, and, me
4
5 token filter:lowercase,stop word,synonymom,liked ‐‐> like,Tom ‐‐> tom,a/th
e/an ‐‐> 干掉,small ‐‐> little
6
一个分词器,很重要,将一段文本进行各种处理,最后处理好的结果才会拿去建立倒
排索引
2、内置分词器的介绍
1 Set the shape to semi‐transparent by calling set_trans(5)
2
3 standard analyzer:set, the, shape, to, semi, transparent, by, calling, set_tra
ns, 5(默认的是standard)
4
5 simple analyzer:set, the, shape, to, semi, transparent, by, calling, set, tran
s
6
7 whitespace analyzer:Set, the, shape, to, semi‐transparent, by, calling, set_tr
ans(5)
8
9 stop analyzer:移除停用词,比如a the it等等
10
11 测试:
12 POST _analyze
13 {
14 "analyzer":"standard",
15 "text":"Set the shape to semi‐transparent by calling set_trans(5)"
16 }
3、定制分词器
1)默认的分词器
standard
standard tokenizer:以单词边界进行切分
standard token filter:什么都不做
lowercase token filter:将所有字母转换为小写
stop token filer(默认被禁用):移除停用词,比如a the it等等
2)修改分词器的设置
启用english停用词token filter
1 PUT /my_index
2 {
3 "settings": {
4 "analysis": {
5 "analyzer": {
6 "es_std": {
7 "type": "standard",
8 "stopwords": "_english_"
9 }
10 }
11 }
12 }
13 }
14
15 GET /my_index/_analyze
16 {
17 "analyzer": "standard",
18 "text": "a dog is in the house"
19 }
20
21 GET /my_index/_analyze
22 {
23 "analyzer": "es_std",
24 "text":"a dog is in the house"
25 }
26
27 3、定制化自己的分词器
28
29 PUT /my_index
30 {
31 "settings": {
32 "analysis": {
33 "char_filter": {
34 "&_to_and": {
35 "type": "mapping",
36 "mappings": ["&=> and"]
37 }
38 },
39 "filter": {
40 "my_stopwords": {
41 "type": "stop",
42 "stopwords": ["the", "a"]
43 }
44 },
45 "analyzer": {
46 "my_analyzer": {
47 "type": "custom",
48 "char_filter": ["html_strip", "&_to_and"],
49 "tokenizer": "standard",
50 "filter": ["lowercase", "my_stopwords"]
51 }
52 }
53 }
54 }
55 }
56
57 GET /my_index/_analyze
58 {
59 "text": "tom&jerry are a friend in the house, <a>, HAHA!!",
60 "analyzer": "my_analyzer"
61 }
62
63 PUT /my_index/_mapping/my_type
64 {
65 "properties": {
66 "content": {
67 "type": "text",
68 "analyzer": "my_analyzer"
69 }
70 }
71 }ik分词器详解
41 "type": "stop",
42 "stopwords": ["the", "a"]
43 }
44 },
45 "analyzer": {
46 "my_analyzer": {
47 "type": "custom",
48 "char_filter": ["html_strip", "&_to_and"],
49 "tokenizer": "standard",
50 "filter": ["lowercase", "my_stopwords"]
51 }
52 }
53 }
54 }
55 }
56
57 GET /my_index/_analyze
58 {
59 "text": "tom&jerry are a friend in the house, <a>, HAHA!!",
60 "analyzer": "my_analyzer"
61 }
62
63 PUT /my_index/_mapping/my_type
64 {
65 "properties": {
66 "content": {
67 "type": "text",
68 "analyzer": "my_analyzer"
69 }
70 }
71 }
3)ik分词器详解
ik配置文件地址:es/plugins/ik/config目录
IKAnalyzer.cfg.xml:用来配置自定义词库
main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在
一起
quantifier.dic:放了一些单位相关的词
suffix.dic:放了一些后缀
surname.dic:中国的姓氏
stopword.dic:英文停用词
ik原生最重要的两个配置文件
main.dic:包含了原生的中文词语,会按照这个里面的词语去分词
stopword.dic:包含了英文的停用词
停用词,stopword
a the and at but
一般,像停用词,会在分词的时候,直接被干掉,不会建立在倒排索引中
4)IK分词器自定义词库
(1)自己建立词库:每年都会涌现一些特殊的流行词,网红,蓝瘦香菇,喊麦,鬼
畜,一般不会在ik的原生词典里
自己补充自己的最新的词语,到ik的词库里面去
IKAnalyzer.cfg.xml:ext_dict,custom/mydict.dic
补充自己的词语,然后需要重启es,才能生效
(2)自己建立停用词库:比如了,的,啥,么,我们可能并不想去建立索引,让人家
搜索
custom/ext_stopword.dic,已经有了常用的中文停用词,可以补充自己的停用词,然
后重启es
1 IK分词器源码下载:https://github.com/medcl/elasticsearch‐analysis‐ik/tree
5)IK热更新
每次都是在es的扩展词典中,手动添加新词语,很坑
(1)每次添加完,都要重启es才能生效,非常麻烦
(2)es是分布式的,可能有数百个节点,你不能每次都一个一个节点上面去修改
es不停机,直接我们在外部某个地方添加新的词语,es中立即热加载到这些新词语
IKAnalyzer.cfg.xml
<properties>
2 <comment>IK Analyzer 扩展配置</comment>
3 <!‐‐用户可以在这里配置自己的扩展字典 ‐‐>
4 <entry key="ext_dict">location</entry>
5 <!‐‐用户可以在这里配置自己的扩展停止词字典‐‐>
6 <entry key="ext_stopwords">location</entry>
7 <!‐‐用户可以在这里配置远程扩展字典 ‐‐>
8 <entry key="remote_ext_dict">words_location</entry>
9 <!‐‐用户可以在这里配置远程扩展停止词字典‐‐>
10 <entry key="remote_ext_stopwords">words_location</entry>
11 </properties>
12高亮显示
在搜索中,经常需要对搜索关键字做高亮显示,高亮显示也有其常用的参数,在这个案例中
做一些常用参数的介绍。
现在搜索cars索引中remark字段中包含“大众”的document。并对“XX关键字”做高亮显
示,高亮效果使用html标签<span>,并设定字体为红色。如果remark数据过长,则只显示前20个
字符。
1 PUT /news_website
2 {
3 "mappings": {
4
5 "properties": {
6 "title": {
7 "type": "text",
8 "analyzer": "ik_max_word"
9 },
10 "content": {
11 "type": "text",
12 "analyzer": "ik_max_word"
13 }
14 }
15 }
16
17 }
18
19
20 PUT /news_website
21 {
22 "settings" : {
23 "index" : {
24 "analysis.analyzer.default.type": "ik_max_word"
25 }
26 }
27 }
28
29
30
31
32 PUT /news_website/_doc/1
33 {
34 "title": "这是我写的第一篇文章",
35 "content": "大家好,这是我写的第一篇文章,特别喜欢这个文章门户网站!!!"
36 }
37
38 GET /news_website/_doc/_search
39 {
40 "query": {
41 "match": {
42 "title": "文章"
43 }
44 },
45 "highlight": {
46 "fields": {
47 "title": {}
48 }
49 }
50 }
51
52 {
53 "took" : 458,
54 "timed_out" : false,
55 "_shards" : {
56 "total" : 1,
57 "successful" : 1,
58 "skipped" : 0,
59 "failed" : 0
60 },
61 "hits" : {
62 "total" : {
63 "value" : 1,
64 "relation" : "eq"
65 },
66 "max_score" : 0.2876821,
67 "hits" : [
68 {
69 "_index" : "news_website",
70 "_type" : "_doc",
71 "_id" : "1",
72 "_score" : 0.2876821,
73 "_source" : {
74 "title" : "我的第一篇文章",
75 "content" : "大家好,这是我写的第一篇文章,特别喜欢这个文章门户网站!!!"
76 },
77 "highlight" : {
78 "title" : [
79 "我的第一篇<em>文章</em>"
80 ]
81 }
82 }
83 ]
84 }
85 }
86
87 <em></em>表现,会变成红色,所以说你的指定的field中,如果包含了那个搜索词的话,就会在
那个field的文本中,对搜索词进行红色的高亮显示
88
89 GET /news_website/_doc/_search
90 {
91 "query": {
92 "bool": {
93 "should": [
94 {
95 "match": {
96 "title": "文章"
97 }
98 },
99 {
100 "match": {
101 "content": "文章"
102 }
103 }
104 ]
105 }
106 },
107 "highlight": {
108 "fields": {
109 "title": {},
110 "content": {}
111 }
112 }
113 }
114
115 highlight中的field,必须跟query中的field一一对齐的
116
117 2、常用的highlight介绍
118
119 plain highlight,lucene highlight,默认
120
121 posting highlight,index_options=offsets
122
123 (1)性能比plain highlight要高,因为不需要重新对高亮文本进行分词
124 (2)对磁盘的消耗更少
125
126
127 DELETE news_website
128 PUT /news_website
129 {
130 "mappings": {
131 "properties": {
132 "title": {
133 "type": "text",
134 "analyzer": "ik_max_word"
135 },
136 "content": {
137 "type": "text",
138 "analyzer": "ik_max_word",
139 "index_options": "offsets"
140 }
141 }
142 }
143 }
144
145 PUT /news_website/_doc/1
146 {
147 "title": "我的第一篇文章",
148 "content": "大家好,这是我写的第一篇文章,特别喜欢这个文章门户网站!!!"
149 }
150
151 GET /news_website/_doc/_search
152 {
153 "query": {
154 "match": {
155 "content": "文章"
156 }
157 },
158 "highlight": {
159 "fields": {
160 "content": {}
161 }
162 }
163 }
164
165 fast vector highlight
166
167 index‐time term vector设置在mapping中,就会用fast verctor highlight
168
169 (1)对大field而言(大于1mb),性能更高
170
171 delete /news_website
172
173 PUT /news_website
174 {
175 "mappings": {
176 "properties": {
177 "title": {
178 "type": "text",
179 "analyzer": "ik_max_word"
180 },
181 "content": {
182 "type": "text",
183 "analyzer": "ik_max_word",
184 "term_vector" : "with_positions_offsets"
185 }
186 }
187 }
188 }
189
190 强制使用某种highlighter,比如对于开启了term vector的field而言,可以强制使用plain h
ighlight
191
192 GET /news_website/_doc/_search
193 {
194 "query": {
195 "match": {
196 "content": "文章"
197 }
198 },
199 "highlight": {
200 "fields": {
201 "content": {
202 "type": "plain"
203 }
204 }
205 }
206 }
207
208 总结一下,其实可以根据你的实际情况去考虑,一般情况下,用plain highlight也就足够了,
不需要做其他额外的设置
209 如果对高亮的性能要求很高,可以尝试启用posting highlight
210 如果field的值特别大,超过了1M,那么可以用fast vector highlight
211
212 3、设置高亮html标签,默认是<em>标签
213
214 GET /news_website/_doc/_search
215 {
216 "query": {
217 "match": {
218 "content": "文章"
219 }
220 },
221 "highlight": {
222 "pre_tags": ["<span color='red'>"],
223 "post_tags": ["</span>"],
224 "fields": {
225 "content": {
226 "type": "plain"
227 }
228 }
229 }
230 }
231
232 4、高亮片段fragment的设置
233
234 GET /_search
235 {
236 "query" : {
237 "match": { "content": "文章" }
238 },
239 "highlight" : {
240 "fields" : {
241 "content" : {"fragment_size" : 150, "number_of_fragments" : 3 }
242 }
243 }
244 }
245
246 fragment_size: 你一个Field的值,比如有长度是1万,但是你不可能在页面上显示这么长
啊。。。设置要显示出来的fragment文本判断的长度,默认是100
247 number_of_fragments:你可能你的高亮的fragment文本片段有多个片段,你可以指定就显示几
个片段
248