简述
github地址在
GitHub - xinchen-ai/Westlake-OmniContribute to xinchen-ai/Westlake-Omni development by creating an account on GitHub.![]() https://github.com/xinchen-ai/Westlake-Omni
https://github.com/xinchen-ai/Westlake-Omni
Westlake-Omni 是由西湖心辰(xinchen-ai)开发的一个开源中文情感端到端语音交互大模型,托管在 Hugging Face 平台 , Hugging Face地址
https://huggingface.co/xinchen-ai/Westlake-Omni![]() https://huggingface.co/xinchen-ai/Westlake-Omni它旨在通过统一的文本和语音模态处理,实现低延迟、高质量的中文情感语音交互。该模型亮点是
https://huggingface.co/xinchen-ai/Westlake-Omni它旨在通过统一的文本和语音模态处理,实现低延迟、高质量的中文情感语音交互。该模型亮点是
Trained on a high-quality Chinese emotional speech dataset, enabling native emotional speech interaction in Chinese. 在高质量的中文情感语音数据集上训练,使其能够实现原生的中文情感语音交互。
应用场景
- 智能助手:在手机或智能家居设备中提供情感化的语音交互。
- 客户服务:作为自动客服,处理咨询和投诉,提供 24/7 服务。
- 教育辅助:支持语言学习和课程辅导,生成情感化的教学语音。
- 医疗咨询:提供语音交互的健康指导,增强患者体验。
- 娱乐与新闻:生成情感化的游戏对话或新闻播报。
1 Westlake-Omni 模型概述
Westlake-Omni 是一个多模态大语言模型,专注于中文情感语音交互。其核心特点包括:
- 统一模态处理:通过离散表示法(discrete representations),将语音和文本模态统一处理,简化跨模态交互。
- 低延迟交互:支持实时语音输入和输出,生成文本和语音响应几乎无延迟。
- 情感表达:在高质量中文情感语音数据集上训练,能够理解和生成具有情感色彩的语音,增强交互的人性化。
- 开源特性:模型代码和权重在 GitHub(https://github.com/xinchen-ai/Westlake-Omni)和 Hugging Face 上公开,支持社区进一步开发和优化。
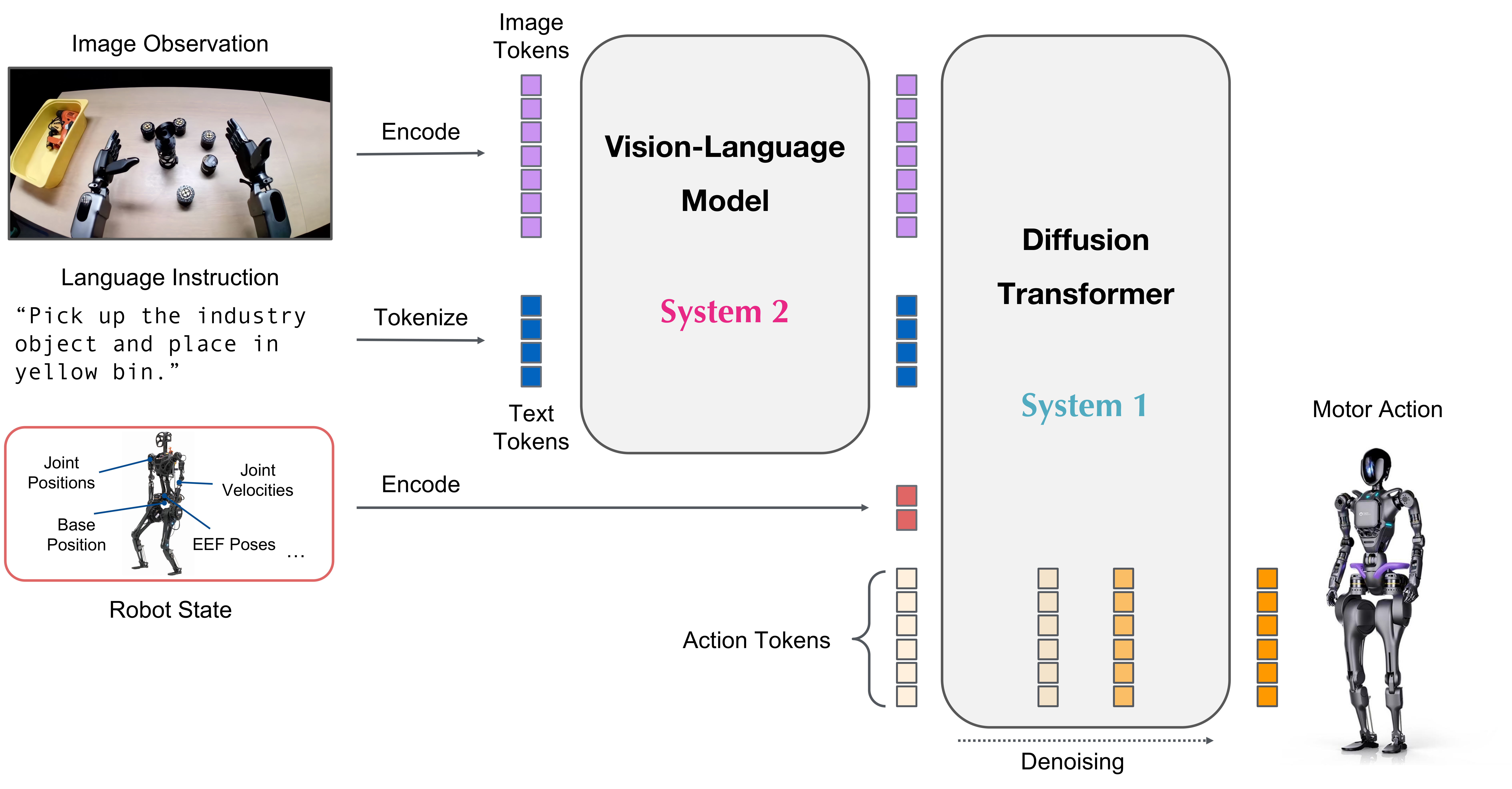
2. 模型原理与架构
Westlake-Omni 的核心在于其多模态架构,能够同时处理语音和文本输入,并生成相应的文本和情感语音输出。以下从原理和架构层面逐步讲解。
2.1 统一模态处理:离散表示法
Westlake-Omni 采用离散表示法(discrete representations)来统一文本和语音模态的处理。传统多模态模型通常需要独立的语音识别(ASR)、文本处理(NLP)和语音合成(TTS)模块,而 Westlake-Omni 通过将语音和文本转化为统一的离散 token 表示,简化了模态间的转换和处理流程。
- 离散表示的原理:
- 语音信号(如 WAV 文件)通过编码器(可能是 Whisper 或 Wave2Vec 类似的预训练模型)转换为离散的语音 token。
- 文本输入直接通过分词器(tokenizer)转换为文本 token。
- 这些 token 在模型内部被统一编码为嵌入向量(embeddings),进入相同的 transformer 架构处理。
- 输出端,模型可以生成文本 token 或语音 token,并通过解码器转换为自然语言或语音。
- 优势:
- 统一表示减少了模态转换的复杂性,提高了计算效率。
- 支持端到端的训练和推理,降低延迟。
- 便于扩展到其他模态。
2.2 模型架构
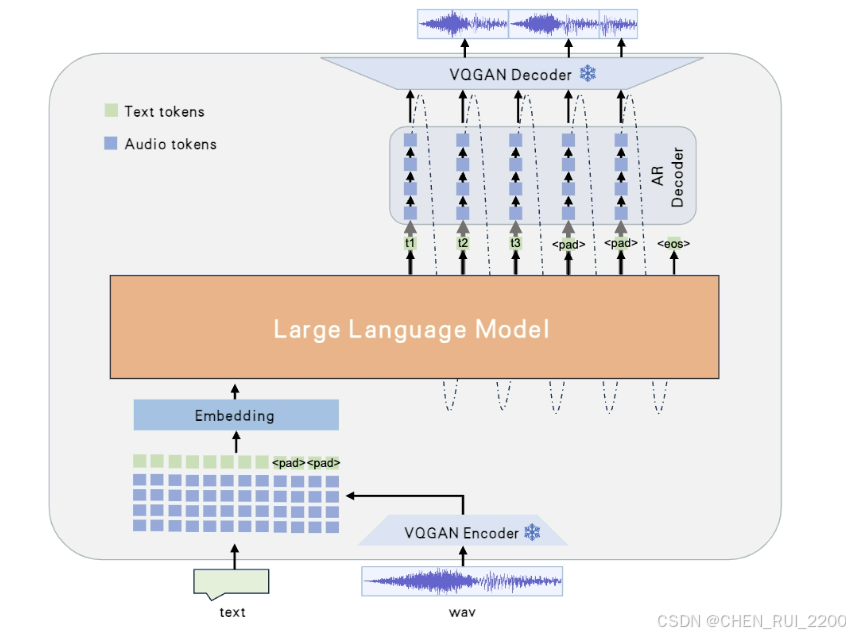
Westlake-Omni 的架构可以分为以下几个关键组件(以下为文字描述的结构,建议参考 GitHub 仓库中的架构图):
- 输入编码器:
- 语音编码器:将原始音频(例如 WAV 文件)编码为离散 token,可能基于 Whisper 或类似的语音预训练模型。
- 文本分词器:将输入文本(例如“最近心情不好,能聊聊吗?”)分词为 token,生成嵌入向量。
- 统一嵌入层:将语音和文本 token 映射到一个共享的嵌入空间,形成统一的输入表示。
- Transformer 核心:
- 基于 Transformer 的多层架构,包含自注意力(self-attention)和前馈神经网络(FFN)。
- 支持多模态输入的上下文建模,能够捕捉语音中的情感线索和文本中的语义信息。
- 可能采用因果注意力(causal attention)机制,确保实时生成(即生成当前 token 时不依赖未来 token)。
- 情感建模模块:
- 专门设计的情感理解和生成模块,用于分析语音输入中的情感色彩(如语调、语速)并在输出中注入相应的情感。
- 可能通过额外的注意力机制或嵌入层,在生成语音时控制情感表达(如高兴、悲伤、平静)。
- 输出解码器:
- 文本解码器:将 Transformer 的输出 token 转换为自然语言文本。
- 语音解码器:将 token 转换为语音波形,可能基于预训练的 TTS 模型(如 Tacotron 或 VITS)。
- 支持同时生成文本和语音,实现“边思考边说话”的效果。
- 低延迟优化:
- 采用流式处理(streaming processing),将输入音频分块(chunked input)处理,减少初始延迟。
- 输出端通过增量生成(incremental generation),实时产生语音和文本。
2.3 模型代码
FireflyArchitecture 模型
FireflyArchitecture 是一个专门为音频处理设计的神经网络模型,主要用于将输入音频(如语音)转换为高质量的音频输出,典型应用包括文本转语音(TTS)或语音转换。它的工作流程可以概括为以下几个步骤:
- 音频预处理:将原始音频波形转换为梅尔频谱图(Mel-Spectrogram),这是一种模仿人类听觉的频率表示形式。
- 特征编码:将梅尔频谱图编码为高层次的特征表示(latent representation)。
- 特征量化:通过量化和下采样,将特征压缩为离散的 token 表示,减少数据量并便于处理。
- 音频生成:将量化的特征解码为高质量的音频波形。
模型由以下四个核心组件组成:
- LogMelSpectrogram:将原始音频转换为梅尔频谱图。
- ConvNeXtEncoder:对梅尔频谱图进行编码,提取高层次特征。
- DownsampleFiniteScalarQuantize:对特征进行量化和下采样,生成离散表示。
- HiFiGANGenerator:将量化后的特征解码为音频波形。
1. LogMelSpectrogram(梅尔频谱图转换)
作用:将原始音频波形(时域信号)转换为梅尔频谱图,这是一种基于频率的表示形式,更适合人类听觉感知和后续处理。
通俗解释:
- 想象音频波形是一条上下波动的曲线,记录了声音的振幅随时间变化。直接处理这种波形很复杂,因为它包含大量数据。
- LogMelSpectrogram 就像一个“音频分析仪”,它把波形分解成不同频率的成分(类似乐谱中的音高),然后按照人类耳朵对频率的敏感度(梅尔尺度)重新组织这些信息。
- 最终输出的是一个二维图像(梅尔频谱图),横轴是时间,纵轴是频率,亮度表示强度。
实现细节:
- 输入:原始音频波形(1D 张量,形状为 [batch_size, 1, time_steps])。
- 处理步骤:
- 短时傅里叶变换(STFT):通过 torch.stft 将音频分成小段(帧),计算每段的频率成分,生成线性频谱图。
- 参数:n_fft=2048(傅里叶变换点数)、win_length=2048(窗口长度)、hop_length=512(帧间步长)。
- 使用汉宁窗(Hann Window)平滑信号,减少频谱泄漏。
- 梅尔尺度转换:通过梅尔滤波器组(torchaudio.functional.melscale_fbanks)将线性频谱图转换为梅尔频谱图。
- 参数:n_mels=160(梅尔滤波器数量)、sample_rate=44100(采样率)、f_min=0.0(最低频率)、f_max=22050(最高频率)。
- 对数压缩:对梅尔频谱图应用对数操作(torch.log),将幅度压缩到更适合神经网络处理的范围。
- 短时傅里叶变换(STFT):通过 torch.stft 将音频分成小段(帧),计算每段的频率成分,生成线性频谱图。
- 输出:梅尔频谱图(形状为 [batch_size, n_mels, time_frames]),其中 time_frames = time_steps // hop_length。
- 关键特性:
- 支持动态采样率调整(通过重采样)。
- 可选择返回线性频谱图(return_linear=True)用于调试或多任务训练。
- 使用反射填充(reflect 模式)处理音频边界,避免边缘失真。
def forward(self, x: Tensor, return_linear: bool = False, sample_rate: int = None) -> Tensor:
if sample_rate is not None and sample_rate != self.sample_rate:
x = F.resample(x, orig_freq=sample_rate, new_freq=self.sample_rate)
linear = self.spectrogram(x) # 线性频谱图
x = self.apply_mel_scale(linear) # 梅尔频谱图
x = self.compress(x) # 对数压缩
if return_linear:
return x, self.compress(linear)
return x- 梅尔频谱图比原始波形更紧凑,减少了数据量,便于神经网络处理。
- 梅尔尺度模拟了人类听觉对高低频的非线性感知,使得模型更擅长处理语音相关任务。
2. ConvNeXtEncoder(特征编码器)
作用:对梅尔频谱图进行编码,提取高层次的特征表示,用于后续量化和解码。
通俗解释:
- 梅尔频谱图就像一张描述声音的“图像”,但它仍然包含很多冗余信息。ConvNeXtEncoder 就像一个“特征提取器”,它分析这张图像,提炼出最重要的模式和结构(比如语音的音调、节奏、语义)。
- 它使用了一种现代化的卷积网络结构(ConvNeXt),通过多层处理逐步将梅尔频谱图压缩为更抽象的特征表示。
实现细节:
- 输入:梅尔频谱图(形状为 [batch_size, n_mels=160, time_frames])。
- 结构:
- 下采样层(downsample_layers):
- 初始层(stem):通过 FishConvNet(1D 卷积)将输入通道从 n_mels=160 转换为第一个维度 dims[0]=128,并应用层归一化(LayerNorm)。
- 后续下采样层:通过 1x1 卷积和层归一化,将通道数逐步增加(dims=[128, 256, 384, 512]),压缩时间维度。
- 阶段(stages):
- 包含多个 ConvNeXtBlock,每个块是一个残差结构,结合深度卷积(depthwise conv)、层归一化、MLP(多层感知机)和随机 DropPath(随机深度,增强泛化能力)。
- 每个阶段有不同数量的块(depths=[3, 3, 9, 3]),对应不同的通道数(dims)。
- 归一化:最后通过层归一化(LayerNorm)稳定输出。
- 下采样层(downsample_layers):
- 输出:高层次特征表示(形状为 [batch_size, dims[-1]=512, reduced_time_frames]),时间维度因下采样而减少。
- 关键特性:
- 使用 ConvNeXtBlock,结合深度卷积和 MLP,提升特征提取能力。
- 支持随机深度(drop_path_rate=0.2),防止过拟合。
- 初始化权重采用截断正态分布(trunc_normal_),确保训练稳定性。
def forward(self, x: torch.Tensor) -> torch.Tensor:
for i in range(len(self.downsample_layers)):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
return self.norm(x)- ConvNeXtEncoder 提取了音频的语义和结构信息,为后续量化提供了高质量的特征。
- 其现代化的卷积设计(ConvNeXt)比传统卷积网络更高效,适合处理复杂音频数据。
3. DownsampleFiniteScalarQuantize(特征量化和下采样)
作用:将编码后的特征量化为离散的 token 表示,并通过下采样减少时间维度,压缩数据量。
通俗解释:
- 编码后的特征就像一本厚厚的书,包含很多细节,但我们只需要一个简短的“摘要”。DownsampleFiniteScalarQuantize 就像一个“压缩机”,它把特征简化为一组数字(token),就像把一首歌压缩成几个关键音符。
- 它还通过下采样减少时间分辨率,降低计算量。
实现细节:
- 输入:编码后的特征(形状为 [batch_size, dim=512, time_frames])。
- 结构:
- 下采样(downsample):
- 通过一系列 FishConvNet 和 ConvNeXtBlock,将时间维度按 downsample_factor=[2, 2] 缩减(总缩减因子为 4)。
- 通道数根据 downsample_dims 调整,保持信息完整性。
- 量化(residual_fsq):
- 使用 GroupedResidualFSQ(分组残差有限标量量化),将特征量化为离散的索引(indices)。
- 参数:n_codebooks=1(量化器数量)、n_groups=8(分组数)、levels=[8, 5, 5, 5](量化级别,约 2^10 个可能值)。
- 上采样(upsample):
- 在解码时,通过 FishTransConvNet 和 ConvNeXtBlock,将量化后的特征恢复到原始时间分辨率。
- 下采样(downsample):
- 输出:
- 编码:量化索引(形状为 [batch_size, n_groups * n_codebooks, reduced_time_frames])。
- 解码:恢复的特征(形状为 [batch_size, dim=512, original_time_frames])。
- 关键特性:
- 向量量化(FSQ)减少了存储和计算需求,适合实时应用。
- 分组残差量化提高了量化精度。
- 下采样和上采样确保时间维度的可逆性。
def encode(self, z):
z = self.downsample(z)
_, indices = self.residual_fsq(z.mT)
indices = rearrange(indices, "g b l r -> b (g r) l")
return indices
def decode(self, indices: torch.Tensor):
indices = rearrange(indices, "b (g r) l -> g b l r", g=self.residual_fsq.groups)
z_q = self.residual_fsq.get_output_from_indices(indices)
z_q = self.upsample(z_q.mT)
return z_q4. HiFiGANGenerator(音频生成器)
作用:将量化后的特征解码为高质量的音频波形。
通俗解释:
- 量化后的特征就像一个简化的“乐谱”,HiFiGANGenerator 是一个“音乐家”,它根据这个乐谱重新演奏出一首完整的歌曲(音频波形)。
- 它使用了一种高效的生成器结构(HiFi-GAN),通过上采样和残差块生成逼真的音频。
实现细节:
- 输入:量化后恢复的特征(形状为 [batch_size, dim=512, time_frames])。
- 结构:
- 预卷积(conv_pre):
- 通过 FishConvNet 将输入通道从 num_mels=512 转换为初始通道 upsample_initial_channel=512。
- 上采样层(ups):
- 通过 FishTransConvNet,将时间维度按 upsample_rates=[8, 8, 2, 2, 2] 上采样(总因子为 512,匹配 hop_length)。
- 通道数逐步减半(512 → 256 → 128 → 64 → 32)。
- 残差块(resblocks):
- 使用 ParallelBlock,包含多个 ResBlock1,每个块有不同核大小(resblock_kernel_sizes=[3, 7, 11])和膨胀率(resblock_dilation_sizes)。
- 并行处理不同核大小的特征,增强多样性。
- 后处理:
- 通过 SiLU 激活(activation_post)和 FishConvNet(conv_post)生成最终波形。
- 使用 tanh 激活将输出限制在 [-1, 1],匹配音频波形范围。
- 预卷积(conv_pre):
- 输出:音频波形(形状为 [batch_size, 1, time_steps]),时间步数为 time_frames * hop_length。
- 关键特性:
- HiFi-GAN 结构以高保真音频生成著称,广泛用于 TTS。
- 权重归一化(weight_norm)提高训练稳定性。
- 支持梯度检查点(checkpoint),降低内存占用。
def forward(self, x):
x = self.conv_pre(x)
for i in range(self.num_upsamples):
x = F.silu(x, inplace=True)
x = self.ups[i](x)
x = self.resblocks[i](x)
x = self.activation_post(x)
x = self.conv_post(x)
x = torch.tanh(x)
return x- HiFiGANGenerator 确保生成的音频具有高保真度,接近人类语音。
- 其上采样和残差设计平衡了质量和效率,适合实时应用。
3 结构示意图
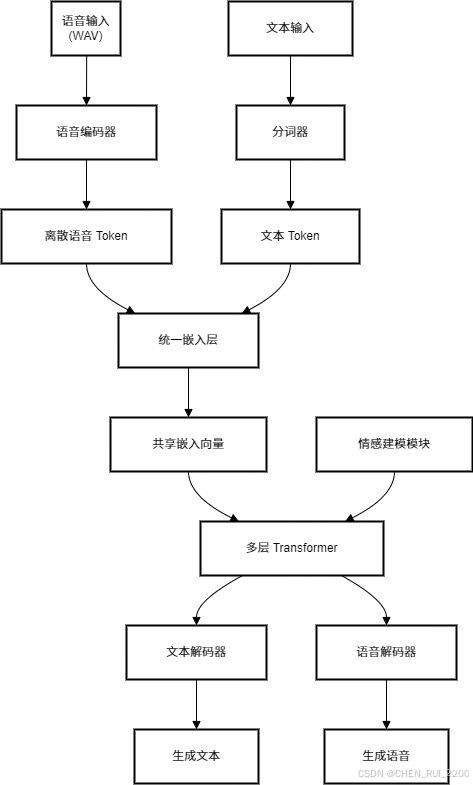
Westlake-Omni 的低延迟特性是其一大亮点,依赖以下技术:
- 流式输入处理:语音输入被分块处理,每收到一小段音频即可开始编码和生成响应,无需等待完整输入。
- 增量生成:模型在生成 token 时逐个输出,而不是一次性生成完整序列,适合实时对话。
- 高效推理:通过优化 Transformer 架构(如减少注意力计算复杂度)和硬件加速(如 GPU),确保快速响应。
3.1 情感理解与表达
Westlake-Omni 在高质量中文情感语音数据集上训练,具备以下能力:
- 情感理解:通过分析语音的音高、语速、音量等特征,识别用户的情感状态(如悲伤、兴奋)。
- 情感生成:在生成语音时,调整输出的语调和节奏,匹配目标情感。例如,回应“心情不好”时,生成带有安慰语气的语音。
- 上下文保持:通过 Transformer 的长上下文建模能力,维持对话的连贯性和情感一致性。
3.2 数据流与整体工作流程
FireflyArchitecture 的整体工作流程如下:
def encode(self, audios, audio_lengths):
mels = self.spec_transform(audios)
mel_lengths = audio_lengths // self.spec_transform.hop_length
mel_masks = sequence_mask(mel_lengths, mels.shape[2])
mels = mels * mel_masks[:, None, :].float()
encoded_features = self.backbone(mels) * mel_masks[:, None, :].float()
feature_lengths = mel_lengths // self.downsample_factor
return self.quantizer.encode(encoded_features), feature_lengths
def decode(self, indices, feature_lengths):
z = self.quantizer.decode(indices) * mel_masks[:, None, :].float()
x = self.head(z) * audio_masks[:, None, :].float()
return x, audio_lengths- 输入:原始音频波形([batch_size, 1, time_steps])和对应的长度(audio_lengths)。
- 梅尔频谱图转换:
- 通过 LogMelSpectrogram 将音频转换为梅尔频谱图([batch_size, n_mels, time_frames])。
- 使用掩码(sequence_mask)处理变长序列。
- 编码:
- ConvNeXtEncoder 将梅尔频谱图编码为高层次特征([batch_size, dim, reduced_time_frames])。
- DownsampleFiniteScalarQuantize 量化为离散索引([batch_size, n_groups * n_codebooks, further_reduced_time_frames])。
- 解码:
- DownsampleFiniteScalarQuantize 将索引解码为特征([batch_size, dim, time_frames])。
- HiFiGANGenerator 将特征转换为音频波形([batch_size, 1, time_steps])。
3.3 优势与局限性
优势
- 端到端设计:从语音输入到语音输出全程由单一模型处理,减少模块间误差。
- 低延迟:流式处理和增量生成适合实时交互。
- 情感能力:在中文情感语音交互方面表现出色,增强用户体验。
- 开源:公开代码和模型权重,便于社区优化和定制。
局限性
- 数据集依赖:模型性能依赖于中文情感语音数据集的质量和多样性,可能在非中文或特定方言场景下表现不佳。
- 计算资源:实时推理需要 GPU 支持,对硬件要求较高。
- 模态扩展:目前专注于语音和文本,尚未支持图像或视频输入,功能相对单一。
- 开源文档:官方文档可能不够详细,需参考代码深入理解。
与其他模型的对比
与 Qwen2.5-Omni()和 Mini-Omni()等模型相比,Westlake-Omni 的特点如下:
- 与 Qwen2.5-Omni 的对比:
- 相似点:两者均为端到端多模态模型,支持文本和语音交互。
- 不同点:Qwen2.5-Omni 支持更多模态(包括图像和视频),而 Westlake-Omni 专注于中文情感语音,延迟更低,情感表达更强。
- 架构差异:Qwen2.5-Omni 采用 Thinker-Talker 架构,而 Westlake-Omni 强调离散表示的统一处理。
- 与 Mini-Omni 的对比:
- 相似点:两者均为开源,专注于实时语音交互。
- 不同点:Mini-Omni 使用 Qwen2 作为语言骨干,规模较小,而 Westlake-Omni 更专注于中文情感场景,数据集更定制化。
使用页面测试
输入文本:
因为无法播放音频,我截取控制台输出
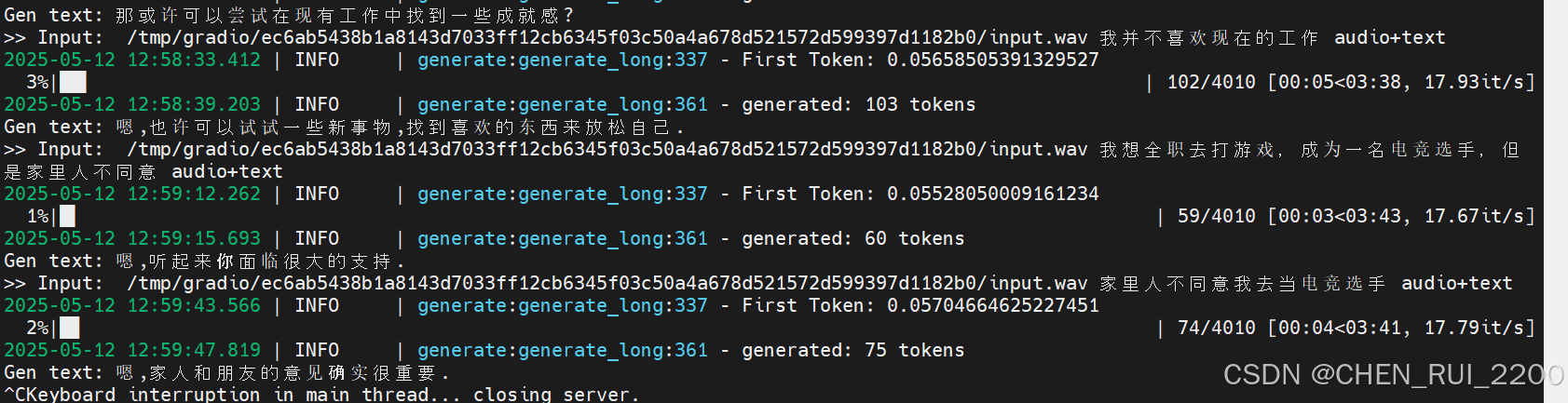
>> Input: /tmp/gradio/ec6ab5438b1a8143d7033ff12cb6345f03c50a4a678d521572d599397d1182b0/input.wav 我并不喜欢现在的工作 audio+text
2025-05-12 12:58:33.412 | INFO | generate:generate_long:337 - First Token: 0.05658505391329527
3%|██▍ | 102/4010 [00:05<03:38, 17.93it/s]
2025-05-12 12:58:39.203 | INFO | generate:generate_long:361 - generated: 103 tokens
Gen text: 嗯,也许可以试试一些新事物,找到喜欢的东西来放松自己.
>> Input: /tmp/gradio/ec6ab5438b1a8143d7033ff12cb6345f03c50a4a678d521572d599397d1182b0/input.wav 我想全职去打游戏,成为一名电竞选手,但是家里人不同意 audio+text
2025-05-12 12:59:12.262 | INFO | generate:generate_long:337 - First Token: 0.05528050009161234
1%|█▍ | 59/4010 [00:03<03:43, 17.67it/s]
2025-05-12 12:59:15.693 | INFO | generate:generate_long:361 - generated: 60 tokens
Gen text: 嗯,听起来你面临很大的支持.
>> Input: /tmp/gradio/ec6ab5438b1a8143d7033ff12cb6345f03c50a4a678d521572d599397d1182b0/input.wav 家里人不同意我去当电竞选手 audio+text
2025-05-12 12:59:43.566 | INFO | generate:generate_long:337 - First Token: 0.05704664625227451
2%|█▊ | 74/4010 [00:04<03:41, 17.79it/s]
2025-05-12 12:59:47.819 | INFO | generate:generate_long:361 - generated: 75 tokens
Gen text: 嗯,家人和朋友的意见确实很重要.