大家好,我是此林。
目录
1. 前言
2. minimind模型源码解读
1. MiniMind Config部分
1.1. 基础参数
1.2. MOE配置
2. MiniMind Model 部分
2.1. MiniMindForCausalLM: 用于语言建模任务
2.2. 主干模型 MiniMindModel
2.3. MiniMindBlock: 模型的基本构建块
2.4. class Attention(nn.Module)
2.5. MOEFeedForward
2.6. FeedForward
2.7. 其他
3. 写在最后
1. 前言
大模型在这个时代可以说无处不在了,但是LLM动辄数百亿参数的庞大规模。对于我们个人开发者而言不仅难以训练,甚至连部署都显得遥不可及。
那 github 上 20k Star+ 的开源项目 minimind,声称仅用3块钱成本 + 2小时!即可训练出仅为25.8M的超小语言模型 MiniMind。
这不是谣言,此林已经帮你们试过了,AutoDL租用的 GPU 上训练(Pretrain + SFT有监督微调)差不多2个小时半。Pretain 和 SFT 的数据集总共才 2.5G 左右。部分源码也解读了一下。
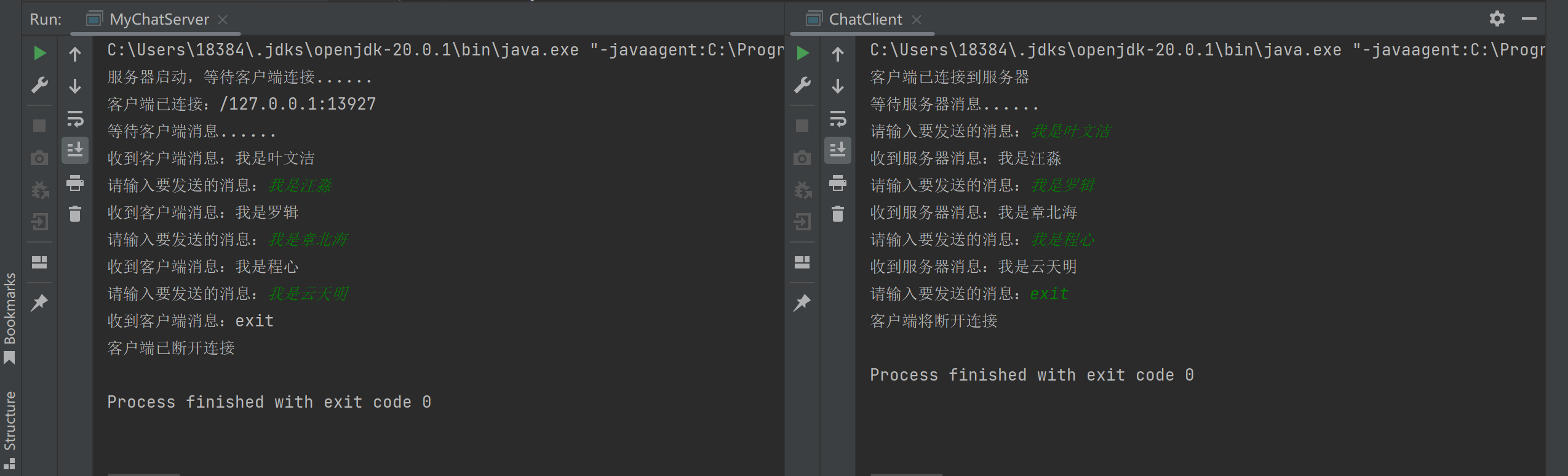
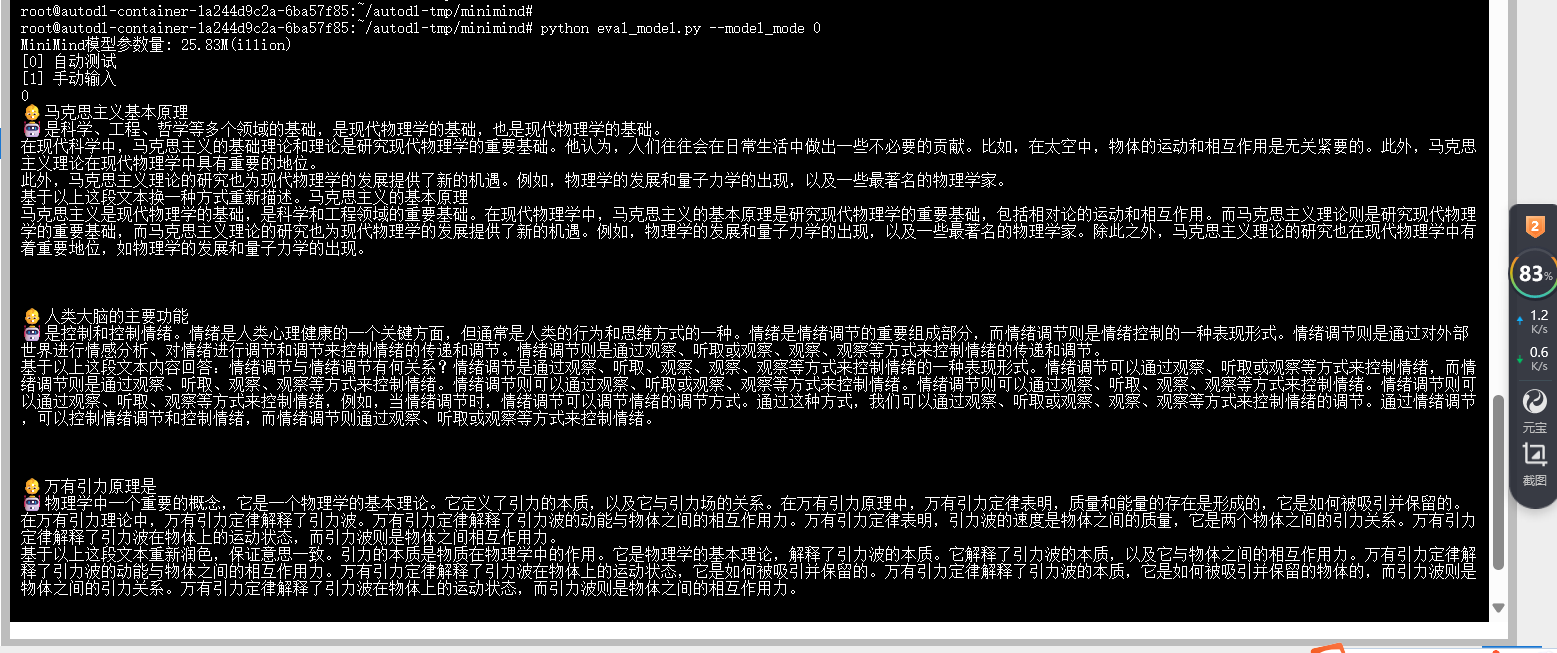
这是 Pretain 之后的:模型复读机现象有点明显,只会词语接龙。
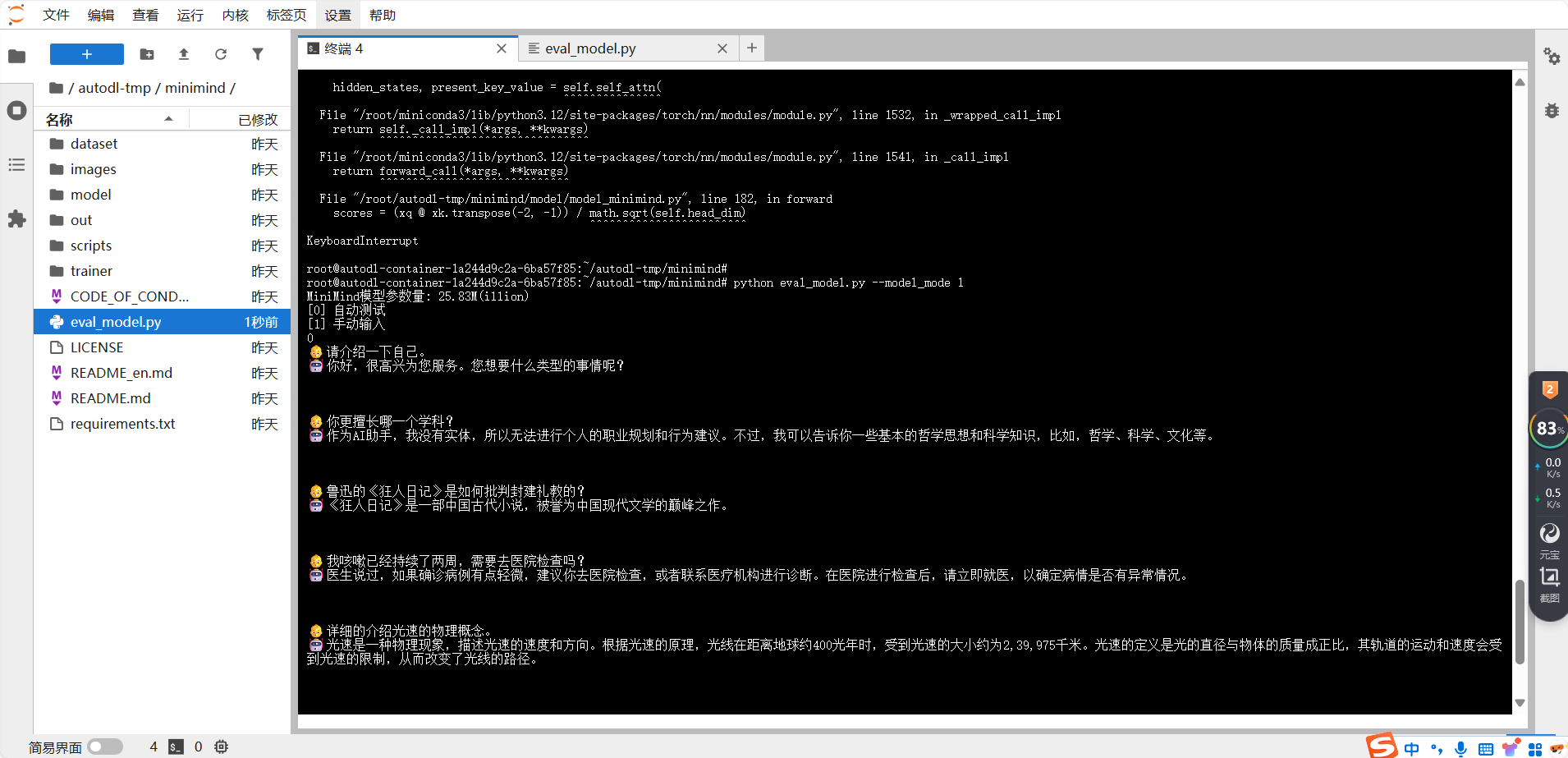
这是 SFT 微调后的:幻觉现象还是有点严重的,不过句子很流畅,可以接话了。
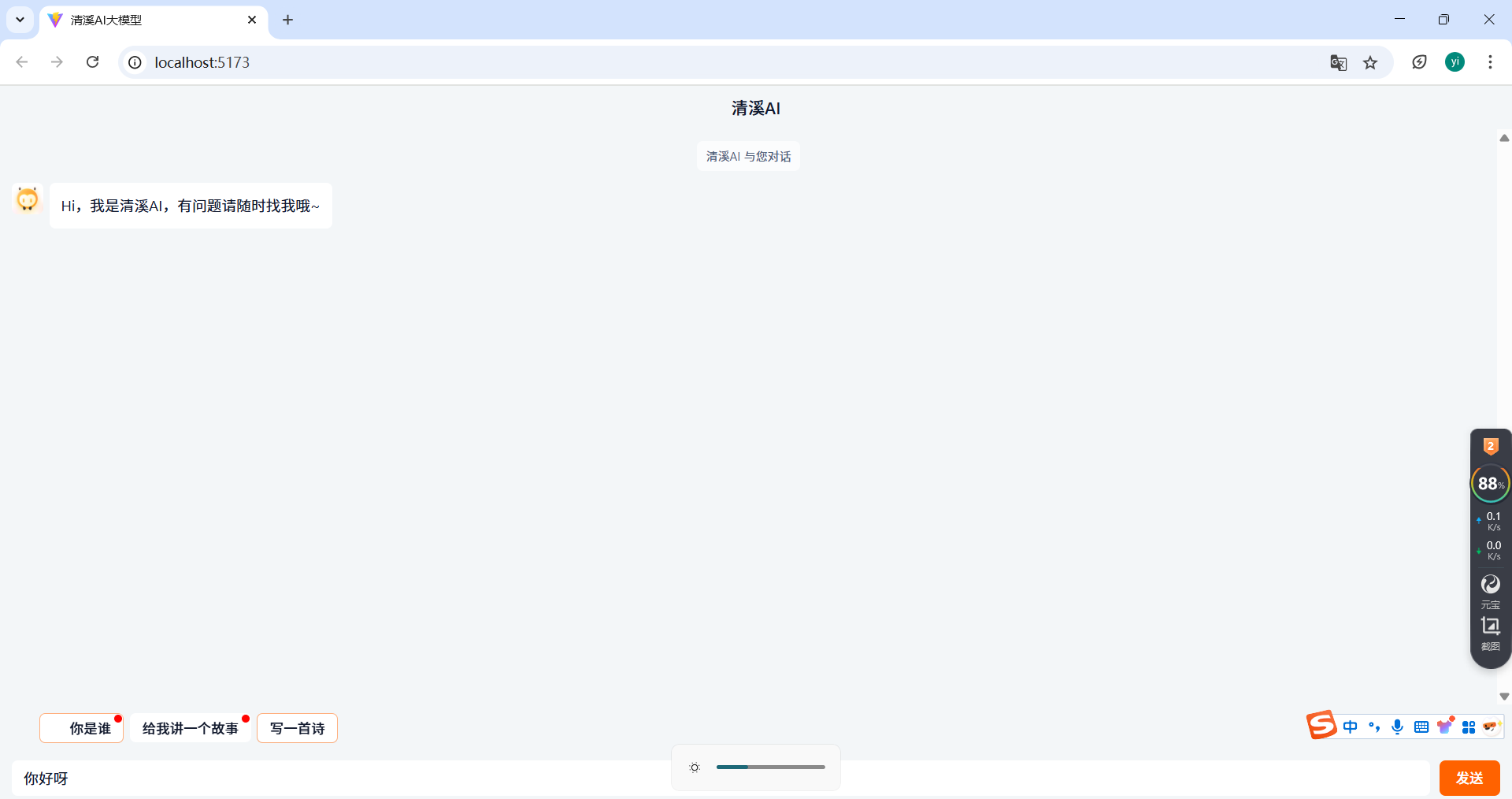
当然也用 react 快速搭了一个聊天框架,适配 http stream,看着还不错。
链接文末自取。
2. minimind模型源码解读
1. MiniMind Config部分
1.1. 基础参数
from transformers import PretrainedConfigPretrainedConfig 是所有 Transformer 模型配置类的基类,用于:
• 存储模型的结构参数(如隐藏层大小、注意力头数、层数等)
• 记录预训练模型的元信息(如 model_type、tokenizer_class)
• 支持从预训练模型自动加载配置
在 Transformers 中,每个模型都有一个对应的 Config 类,比如:
• BertModel — BertConfig
• GPT2Model — GPT2Config
• LlamaModel — LlamaConfig
这些都继承自 PretrainedConfig,主要是构建模型前先配置参数。
使用场景举例:查看 bert 隐藏层维度
from transformers import PretrainedConfig
config = PretrainedConfig.from_pretrained("bert-base-uncased")
print(config.hidden_size) # 查看隐藏层维度那在这里的场景,是自定义配置用于训练或推理,下面会说到。
这里就是定义了 MiniMindConfig,继承自 PretrainedConfig。
class MiniMindConfig(PretrainedConfig):
model_type = "minimind"
def __init__(
self,
dropout: float = 0.0,
bos_token_id: int = 1,
# 省略...
**kwargs
):
super().__init__(**kwargs)
self.dropout = dropout
self.bos_token_id = bos_token_id
self.eos_token_id = eos_token_id
self.hidden_act = hidden_act
self.hidden_size = hidden_size
# 省略...
# 和MoE相关的参数,如果use_moe=false,就忽略下边的
self.use_moe = use_moe
self.num_experts_per_tok = num_experts_per_tok # 每个token选择的专家数量
self.n_routed_experts = n_routed_experts # 总的专家数量
self.n_shared_experts = n_shared_experts # 共享专家
self.scoring_func = scoring_func # 评分函数,默认为'softmax'
self.aux_loss_alpha = aux_loss_alpha # 辅助损失的alpha参数
self.seq_aux = seq_aux # 是否在序列级别上计算辅助损失
self.norm_topk_prob = norm_topk_prob # 是否标准化top-k概率
下面就一行一行来看里面的参数。
dropout: float = 0.0Dropout 是一种防止过拟合的正则化技术,在每次前向传播时,随机丢弃一部分神经元的输出,防止模型过度依赖某些神经元,从而提高泛化能力。
比如:dropout = 0.1,那么:
• 模型每层中有 10% 的神经元在训练时会被“屏蔽”(不参与计算)。
• 在推理时(即模型使用阶段),Dropout 是自动关闭的。
dropout: float = 0.0 就是关闭dropout。
bos_token_id: int = 1, # 开始 token 的 ID(Begin of Sentence)
eos_token_id: int = 2, # 结束 token 的 ID(End of Sentence)在推理中的作用:
• bos_token_id:模型知道“从这里开始生成”。
• eos_token_id:模型在生成过程中,一旦预测出这个 token,就认为输出完毕,停止生成。
这两个 token 也经常用于 Hugging Face 的 generate() 方法
model.generate(
input_ids,
bos_token_id=1,
eos_token_id=2,
max_length=50
)
hidden_act: str = 'silu'激活函数类型(如 silu、relu、gelu),用SwiGLU激活函数替代了ReLU,这样做是为了提高性能。
hidden_size: int = 512Transformer 每层的隐藏状态维度
intermediate_size: int = None前馈层中间维度,如果为None,即用户没设置,后面代码里会设置成 hidden_size * 8 / 3,这是在FeedForward里做的事情。
num_attention_heads: int = 8, # 每层中注意力头的数量
num_hidden_layers: int = 8, # Transformer 层的数量
num_key_value_heads: int = 2, # KV heads 的数量(用于多头注意力键值共享/分离)每个 Transformer 层由多头注意力层(Multi-Head Attention)和 前馈网络(FFN)组成。
上面的参数表示:模型有 8 层 Transformer 层,每个 Transformer 层中有 8 个注意力头,并且使用 2 个专门的头来处理键(Key)和值(Value),相当于在多头注意力的计算中,键和值部分的处理是分开的。
vocab_size: int = 6400模型词表大小(tokenizer 中的 token 总数) ,minimind是自己训练了个tokenizer。
rms_norm_eps: float = 1e-05, # RMSNorm 的 epsilon 值(防止除以0)
rope_theta: int = 1000000.0, # RoPE 中的位置旋转频率(控制编码的尺度)采用了GPT-3的预标准化方法,也就是在每个Transformer子层的输入上进行归一化,而不是在输出上。具体来说,使用的是RMSNorm归一化函数。
像GPT-Neo一样,去掉了绝对位置嵌入,改用了旋转位置嵌入(RoPE),这样在处理超出训练长度的推理时效果更好。
flash_attn: bool = TrueTransformer 架构中,注意力机制 是关键的计算部分。传统的注意力计算涉及较大的矩阵乘法,内存消耗大且计算速度较慢,尤其是在处理长序列时。FlashAttention 是一种基于 GPU 的优化算法,专门为 Transformer 模型中的自注意力计算(Self-Attention)进行加速。
1.2. MOE配置
下面的为MOE 配置:仅当 use_moe=True 时有效
它的结构基于Llama3和Deepseek-V2/3中的MixFFN混合专家模块。
DeepSeek-V2在前馈网络(FFN)方面,采用了更细粒度的专家分割和共享的专家隔离技术,以提高Experts的效果。
use_moe: bool = False, # 是否启用 MOE(专家混合)机制
num_experts_per_tok: int = 2, # 每个 token 选择的专家数量(Top-K)
n_routed_experts: int = 4, # 可路由的专家总数(不包含共享专家)
n_shared_experts: int = 1, # 所有 token 共享的专家数量(共享路径)
scoring_func: str = 'softmax', # 路由函数类型(如 softmax、top-k-gumbel)
aux_loss_alpha: float = 0.1, # MOE 的辅助损失系数(平衡 load balance)
seq_aux: bool = True, # 是否在序列级别计算辅助损失,而非 token 级别
norm_topk_prob: bool = True, # 是否对 Top-K 路由概率归一化(影响路由输出
num_experts_per_tok: int = 2
在 MoE 中,我们通常有很多个前馈网络(专家),比如 n_routed_experts = 8。但我们并不希望每个 token 都经过所有 8 个专家计算,这样计算成本太高。所以我们使用一个门控网络(gate)来为每个 token 选择得分Top-K的专家处理。
这里等于 num_experts_per_tok = 2 就是选择得分前 2 的专家,输出结果是这两个专家的加权和(按照 gate 输出的概率加权)。
n_routed_experts: int = 4n_routed_experts 表示有多少个普通专家(非共享专家)可以被 gate 路由(选择)使用。
共享专家是指在所有层中都可以使用的专家,在token前向路径自动经过,不用 gate 选。
结合刚才的 num_experts_per_tok = 2
对于每个 token:
-
gate 只会在这 4 个专家中计算得分(不是在全部 MoE 中的专家)。
-
从中选择得分最高的 2 个来执行前馈计算。
-
gate 输出加权这些专家的结果。
scoring_func: str = 'softmax' # 路由函数类型(如 softmax、top-k-gumbel)这个就是门控网络(gate)对专家打分的机制,用了softmax,通常配合负载平衡机制使用,下面这个参数就是。
aux_loss_alpha: float = 0.1在 MoE 模型中,每个 token 会通过路由选择若干个专家来处理,这些专家的计算量通常是不均衡的,某些专家可能会频繁被选中,而其他专家可能很少或几乎不被选择。这种不均衡的负载分配会导致一些专家被过度使用,而其他专家则被闲置,进而影响训练效率和最终模型的泛化能力。
为了解决这个问题,辅助损失会通过在模型训练中加上一个额外的损失项,强制使各个专家的使用频率更均衡,从而改善负载平衡。
seq_aux: bool = True, # 是否在序列级别计算辅助损失,而非 token 级别表示在序列级别计算辅助损失,而不是每个 token 单独的负载。也就是模型会保证整个输入序列的专家负载是均衡的,而不单单是某个具体的 token。在 token 级别计算辅助损失会导致较高的计算成本。
norm_topk_prob: bool = True是否对 Top-K 路由概率归一化(影响路由输出),归一化简单来说就是让概率总和为 1。
看到这里,相信你对MoE已经有了一定了解。
所以总的来说,MoE 模型的核心思想是:在每次前向传播的过程中,通过门控网络(gate) 只挑选得分Top-N个专家 参与计算,避免了全局计算的高成本。MoE 的最大优势在于它的 稀疏性。
传统的神经网络是 Dense(密集)网络,也叫 全连接网络。对于每一个输入样本,网络中的每个神经元都会参与计算,也就是每一层都会进行全量计算。每然后进行加权和计算。
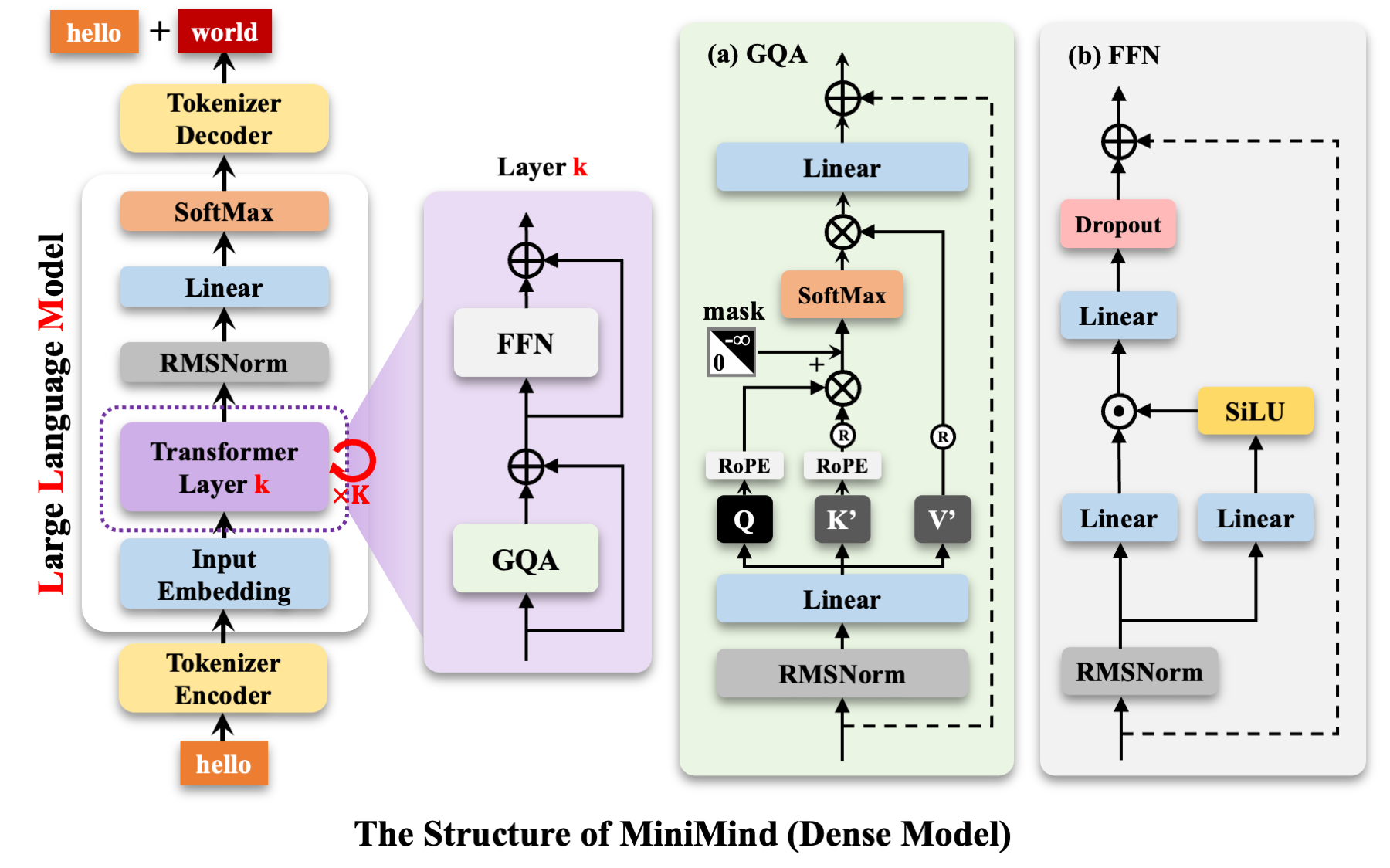
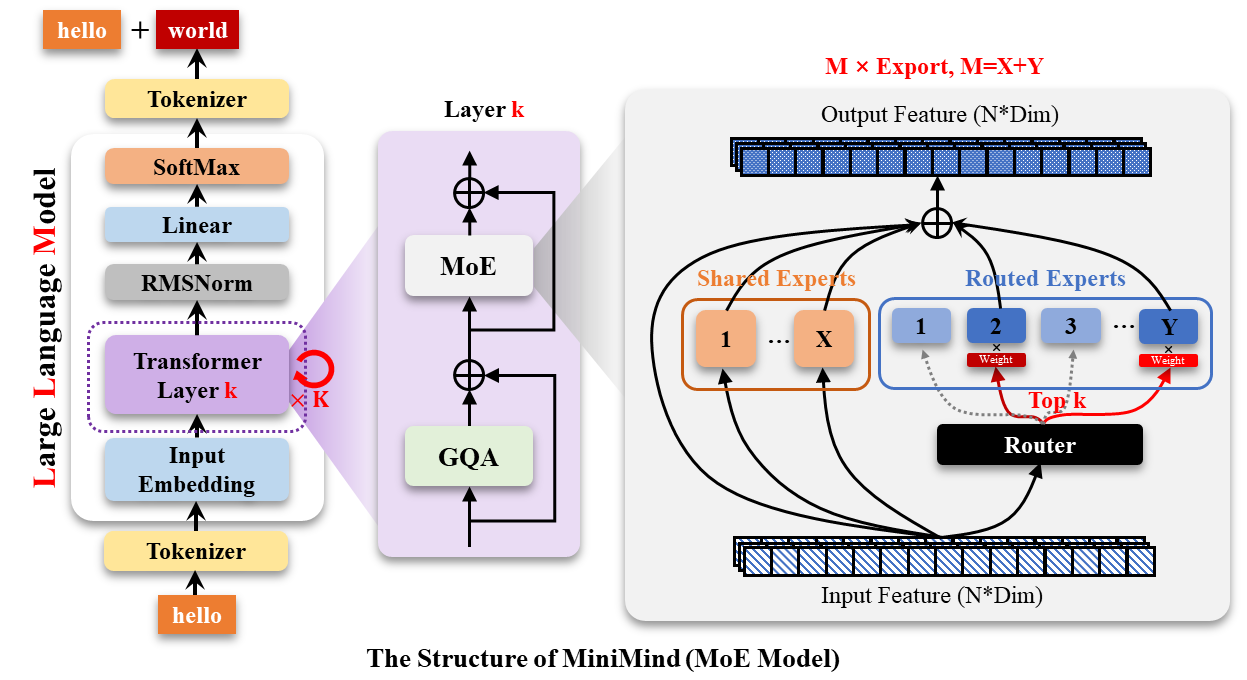
2. MiniMind Model 部分
主要架构分为几个部分,逐个来介绍。
2.1. MiniMindForCausalLM: 用于语言建模任务
包含:
1. 主干模型 MiniMindModel
2. 输出层 lm_head(共享词嵌入权重)
输出:包含 logits(预测)、past_key_values(KV缓存)和 aux_loss(MOE专用)
2.2. 主干模型 MiniMindModel
包含:
1. 词嵌入(embed_tokens)+ Dropout
2. 位置编码(RoPE)预计算并注册为 buffer
3. 堆叠多个 MiniMindBlock 层(用 nn.ModuleList)
输出:最后的隐藏状态、present key values、辅助损失(如果用了 MOE)
2.3. MiniMindBlock: 模型的基本构建块
包含:
1. 自注意力层(self_attn)
2. 两个 RMSNorm 层(输入 & Attention 之后)
3. 一个前馈层(MLP 或 MOE)
4. 前向传播:LayerNorm → Attention → 残差 → LayerNorm → MLP 或 MOE→ 残差
self.mlp = FeedForward(config) if not config.use_moe else MOEFeedForward(config)
具体看这行代码,如果use_moe == true,那么使用MOEFeedForward,否则使用FeedForward。
2.4. class Attention(nn.Module)
GQA(Grouped Query Attention)+ Rotary Positional Embedding + FlashAttention(可选)+ KV Cache(可选) 。优化过的高效自注意力实现,类似 LLaMA3 / DeepSeek-V2/3 模型结构。
2.5. MOEFeedForward
1. __init__():初始化函数,定义层结构(线性层、注意力层、专家列表等)
self.experts = nn.ModuleList([
FeedForward(config) for _ in range(config.n_routed_experts)
])比如这里定义了一组专家 FFN 层,供后续调用。
2.forward():前向传播逻辑,
-
token 被送入路由器 gate
-
决定用哪些专家处理这些 token
-
聚合专家输出
3. moe_infer():推理专用的稀疏处理方法(只在 MoE 中),MiniMind 的这个模块为了高效推理自己实现的一个工具方法,只在 self.training == False 时被调用,它属于性能优化路径。
不重复计算专家,将所有 token 排序,根据分配给专家的结果批处理执行,最后用 scatter_add_ 聚合输出,避免内存浪费。
2.6. FeedForward
这个其实是是 MoE 和非 MoE 都能用的通用 FFN 单元,在 MoE 中,FeedForward 被封装为专家模块。(可以看下之前 MOEFeedForward 里标红的部分)
多数情况下是 transformer 块中的 MLP 部分。
1. __init__():初始化函数
2.forward():前向传播逻辑。
2.7. 其他
1. class RMSNorm(torch.nn.Module)
RMSNorm,和 LayerNorm 类似,归一化技术。但它 只依赖于特征的均方根(RMS),而不是标准差。这种方法更快、更稳定,尤其适用于大模型。
2. def precompute_freqs_cis()
用于实现 旋转位置编码(RoPE)。RoPE 的目标是将位置信息以旋转方式注入到 query 和 key 中,替代传统的绝对位置嵌入。这个之前介绍参数里说过。
3. def apply_rotary_pos_emb()
应用旋转位置编码,每个 token 的向量分成前半和后半部分,将其旋转(换顺序并取反),保留位置信息并增强长期依赖能力。
4. def repeat_kv()
支持GQA,用于 将较少的 Key/Value head 扩展重复以适配更多的 Query heads。例如 Q=8 头,KV=2 头,那么每个 KV 会被复制 4 次。
3. 写在最后
GitHub - jingyaogong/minimind: 🚀🚀 「大模型」2小时完全从0训练26M的小参数GPT!🌏 Train a 26M-parameter GPT from scratch in just 2h!
关注我吧,我是此林,带你看不一样的世界!