在经过前面的简单的C++入门语法的学习后,我们开始接触C++最重要的组成部分之一:STL
目录
STL的介绍
什么是STL
STL的历史
UTF-8编码原理(了解)
UTF-8编码原理
核心编码规则
规则解析
编码步骤示例
1. 确定码点范围
2. 转换为二进制
3. 按格式填充数据位
4. 合并字节序列
UTF-8编码示例表
UTF-8的核心优势
与其他编码的对比
实际应用场景
string类
为什么要学习string类?
标准库中的string类
string类(了解)
auto和范围for
auto关键字
范围for
string类的常用接口说明
string类对象的容量操作
string的遍历
一、[]运算符重载介绍
二、迭代器
三、范围for (C++11)
string类对象的修改操作
string类非成员函数
迭代器的介绍
迭代器的概念与分类
string中迭代器的获取方式
迭代器的基本操作
涉及迭代器的string成员函数
与STL算法结合使用
迭代器失效问题
实际应用示例
迭代器的意义:
一些string类的例题
1.仅仅反转字母
2.查找字符串中第一个唯一的字符
STL的介绍
什么是STL
STL是C++标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个保罗数据结构和算法的软件框架
STL的历史
C++ STL版本历史发展总览
| 标准版本 | 发布时间 | 新增组件与特性 | 关键特性与改进 | 影响与意义 |
|---|---|---|---|---|
| C++98 | 1998 | - 容器:vector, list, deque, set, map- 算法: sort, find, copy- 迭代器、函数对象、适配器 | 首次将STL纳入C++标准,确立泛型编程范式。 | 奠定了现代C++标准库的基础,成为工业级开发的标配。 |
| C++03 | 2003 | - 无新增组件 | 技术性修订,修复C++98中的缺陷和模糊定义。 | 提升跨平台一致性,稳定了STL的实现。 |
| C++11 | 2011 | - 新容器:unordered_map, unordered_set, array, forward_list- 智能指针: shared_ptr, unique_ptr- 移动语义支持 | - 引入右值引用和移动语义 - 支持Lambda表达式 - 线程安全组件(如 std::thread) | 现代化STL,显著提升性能和灵活性,推动多核编程。 |
| C++14 | 2014 | - 泛型Lambda - std::exchange, std::quoted | 优化C++11特性,增强泛型编程能力。 | 简化代码,提升开发效率。 |
| C++17 | 2017 | - std::optional, std::variant, std::string_view- std::filesystem- 并行算法 | - 文件系统标准化 - 并行执行算法(如 std::sort支持多线程) | 强化实用性和性能,支持现代硬件并行计算。 |
| C++20 | 2020 | - 范围库(std::ranges)- 概念(Concepts) - std::span, std::format | - 链式操作简化算法调用(如views::filter)- 约束模板参数,提升编译期类型安全。 | 革命性改进,代码更简洁、安全,支持函数式编程风格。 |
| C++23 | 2023 | - std::flat_map, std::flat_set- std::ranges::to- 网络库(提案中) | - 扁平化关联容器优化性能 - 网络编程接口标准化(进行中) | 进一步优化数据结构和算法,扩展应用领域(如网络和嵌入式)。 |
各版本核心改进对比
| 特性分类 | C++98 | C++11 | C++17 | C++20 |
|---|---|---|---|---|
| 容器 | 基础线性/关联容器 | 哈希容器、固定数组 | 类型安全联合体、文件系统 | 范围视图、span |
| 算法 | 基础泛型算法 | 支持Lambda和移动语义 | 并行算法、随机抽样 | 范围库链式操作 |
| 内存管理 | 原始指针 | 智能指针(shared_ptr) | 内存资源管理(PMR) | 无重大更新 |
| 并发支持 | 无 | std::thread, std::mutex | 无重大更新 | 无重大更新 |
| 元编程 | 基础模板 | 类型推导(auto) | 结构化绑定、if constexpr | 概念(Concepts) |
| 实用性工具 | 无 | std::function, std::bind | std::optional, std::any | std::format, std::chrono |
关键版本里程碑
-
C++98:STL标准化,泛型编程成为主流。
-
C++11:现代化改造,支持移动语义和多线程。
-
C++17:实用工具扩展,文件系统和并行计算。
-
C++20:范围库和概念,代码简洁性与安全性飞跃。
-
C++23:扁平化容器和网络库,优化高性能场景。
主流STL实现对比
| 实现名称 | 所属编译器 | 特点 |
|---|---|---|
| libstdc++ | GCC | 兼容性强,支持旧标准,广泛用于Linux系统。 |
| libc++ | Clang/LLVM | 轻量高效,积极支持新标准(如C++20特性)。 |
| MSVC STL | MSVC | 深度集成Windows生态,优化调试模式,支持最新C++特性。 |
UTF-8编码原理(了解)
UTF-8编码原理
UTF-8(Unicode Transformation Format-8)是一种可变长度字符编码,用于将Unicode字符映射为字节序列。它兼容ASCII,支持所有Unicode字符(当前最长达21位),且无字节序(Endianness)问题,广泛应用于互联网和跨平台数据交换。
核心编码规则
UTF-8通过1到4个字节表示一个字符,编码规则如下:
| Unicode码点范围(十六进制) | UTF-8编码格式(二进制) | 字节数 |
|---|---|---|
U+0000 ~ U+007F | 0xxxxxxx | 1字节 |
U+0080 ~ U+07FF | 110xxxxx 10xxxxxx | 2字节 |
U+0800 ~ U+FFFF | 1110xxxx 10xxxxxx 10xxxxxx | 3字节 |
U+10000 ~ U+10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 4字节 |
规则解析
-
首字节前缀:
-
1字节:以
0开头。 -
2字节:以
110开头。 -
3字节:以
1110开头。 -
4字节:以
11110开头。
-
-
后续字节前缀:所有后续字节均以
10开头。 -
数据位填充:
x表示Unicode码点的二进制位,从高位到低位依次填充。
编码步骤示例
以字符 “€”(Unicode码点 U+20AC)为例,演示UTF-8编码过程:
1. 确定码点范围
-
U+20AC属于U+0800 ~ U+FFFF,需 3字节 编码。
2. 转换为二进制
-
十六进制
20AC→ 二进制0010 0000 1010 1100(共16位)。
3. 按格式填充数据位
-
3字节模板:
1110xxxx 10xxxxxx 10xxxxxx。 -
将16位码点拆分填充:
-
首字节:取高4位
0010→ 填充到1110xxxx→11100010。 -
第二字节:取中间6位
000010→ 填充到10xxxxxx→10000010。 -
第三字节:取低6位
101100→ 填充到10xxxxxx→10101100。
-
4. 合并字节序列
-
最终UTF-8编码(十六进制):
E2 82 AC。
UTF-8编码示例表
| 字符 | Unicode码点 | UTF-8编码(十六进制) | 二进制格式 |
|---|---|---|---|
| 'A' | U+0041 | 41 | 01000001 |
| 'ç' | U+00E7 | C3 A7 | 11000011 10100111 |
| '中' | U+4E2D | E4 B8 AD | 11100100 10111000 10101101 |
| '😂' | U+1F602 | F0 9F 98 82 | 11110000 10011111 10011000 10000010 |
UTF-8的核心优势
-
兼容ASCII:
-
所有ASCII字符(0x00-0x7F)的UTF-8编码与原ASCII编码一致,旧系统可无缝兼容。
-
-
空间高效:
-
常用字符(如拉丁字母、汉字)仅需2-3字节,比UTF-16/UTF-32更节省空间。
-
-
无字节序问题:
-
字节顺序固定(Big-Endian),无需BOM(Byte Order Mark)。
-
-
容错能力强:
-
通过前缀模式可检测编码错误(如无效的后续字节)。
-
与其他编码的对比
编码方式 特点 适用场景 UTF-8 可变长度(1-4字节),兼容ASCII,无字节序问题 网络传输、存储、跨平台 UTF-16 固定2或4字节,存在大端(BE)和小端(LE)问题,需BOM标记 Windows系统、部分旧协议 UTF-32 固定4字节,直接映射码点,空间占用大 内存处理、内部计算
实际应用场景
-
Web开发:
-
HTML、JSON、XML默认使用UTF-8编码,确保多语言支持。
-
-
文件存储:
-
文本文件(如
.txt、.csv)优先使用UTF-8,避免乱码。
-
-
数据库:
-
MySQL、PostgreSQL等数据库推荐UTF-8作为字符集。
-
-
编程语言:
-
Python、Java、JavaScript等均原生支持UTF-8字符串处理。
-
-
string类
为什么要学习string类?
C语言中,字符串是以'\0'结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
标准库中的string类
string类(了解)
官方string类的介绍文档:
<string> - C++ 参考
string - C++ 参考
在使用string类的时候,必须要包含头文件<string.h>以及
using namespace stdauto和范围for
auto关键字
早期C/C++中auto的含义是:使用auto修饰的变量是具有自动储存器的局部变量,后来这个不重要了。在C++11 中auto有了全新的含义:auto不再是一个储存类型的指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
用auto声明指针类型时,用auto和auto*没有任何区别,但是用auto声明引用类型时候必须加&,否则只是拷贝而无法通过它去改变指向的值
int main()
{
int x = 10;
auto y = x;
auto *z= &x;
auto& m = x;
cout<<typeid(y).name()<<endl;
cout<<typeid(z).name()<<endl;
cout<<typeid(m).name()<<endl;
return 0;
}这么写也可以
auto p1=&x;
auto* p2=&x;但是不能这么写
auto *p2=x;当同一行声明多个变量的时候,这些变量必须是相同类型的,否则编译器会报错。因为编译器实际上只对第一个类型进行推导,然后用推导出来的类型去定义其他变量
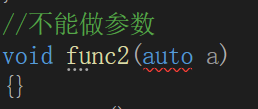
auto不能作为函数的参数,可以做返回值,但是建议谨慎使用
#include <iostream>
using namespace std;
int func1()
{
return 10;
}
//不能做参数
void func2(auto a)
{}
//可以做返回值但是谨慎使用
auto func3()
{
return 10;
}
int main()
{
int a = 10;
auto b = a;
auto c = 'a';
auto d = func1();
//编译错误:“e”包含类型“auto”必须要有初始值
auto e;
cout<<typeid(b).name()<<endl;
cout<<typeid(c).name()<<endl;
cout<<typeid(d).name()<<endl;
return 0;
}
auto不能直接声明数组
int main()
{
auto aa = 1, bb = 2;
//编译错误:声明符列表中,“auto”必须始终推到为同一类型
auto cc = 3, dd = 4.0;
//编译错误:不能将“auto[]”用作函数参数类型
auto arr[] ={4,5,6};
return 0;
}关于 typeid(b).name() 的解析
-
typeid(b):
使用typeid运算符获取变量b的类型信息,返回一个std::type_info对象的常量引用。-
作用:在运行时(RTTI,Run-Time Type Information)或编译时获取类型信息。
-
头文件:需包含
<typeinfo>。
-
-
.name():
std::type_info的成员函数,返回一个表示类型名称的字符串(格式取决于编译器实现)。-
输出示例:
-
GCC/Clang:
i(表示int) -
MSVC:
int
-
-
-
cout << ... << endl:
输出typeid(b).name()返回的字符串,并换行。
auto真正的应用:
#include <iostream>
#include<string>
#include<map>
using namespace std;
int main()
{
std::map<std::string, std::string> dict = { {"apple","苹果"},{"orange","橘子"},{"pear","梨"}};
//auto的应用
//std::map<std::string, std::string>::iterator it = dict.begin();
auto it =dict.begin();
while (it != dict.end())
{
cout<<it->first<<" "<<it->second<<endl;
++it;
}
return 0;
}范围for
对于有范围的集合而言,程序员说明循环的范围是多余的,有时候还会容易犯错误。因此C++11引入了基于范围的for循环。for循环后括号由冒号“:”分为两部分:第一部分是范围用于迭代的变量,第二部分则表示被迭代的范围,自动迭代自动取数据,自动判断结束
范围for可以作用到数组和容器对象上遍历。
范围for的底层很简单,容器遍历实际上就是替换为迭代器,从汇编也可以看到
#include<iostream>
#include<string>
#include<map>
using namespace std;
int main()
{
int arr[] = {1,2,3,4,5};
C++98的遍历
//for (int i = 0;i < sizeof(arr) / sizeof(arr[0]);i++)
//{
// cout<<arr[i]<<endl;
//}
//C++11的遍历
for (auto& e : arr)
{
e *= 2;
}
for (auto&e : arr)
{
cout<<e<<" " << endl;
}
string str("hello world");
for (auto ch : str)
{
cout<<ch<<" ";
}
cout<<endl;
return 0;
}string类的常用接口说明
string的构造方式

他们的特点分别为:

| (constructor)函数名称 | 功能说明 |
| string(重点) | 构造空的string类,即空字符串 |
| string(const char*s)(重点) | 用C-string来构造string类对象 |
| string(size_t n,char c) | string类对象包含n个字符c |
| string(const string &s)(重点) | 拷贝构造函数 |
一个简单的string程序
#include <iostream>
#include<string>
using namespace std;
void test()
{
//最常见的两种string构造方式
string s1; //构造空字符串
string s2 = "hello world"; //构造常量字符串
string s3(s2); //拷贝构造
string s4(s2, 1, 5); //从s2中构造子串
string s5(s2, 1, 50);
string s6(s2, 1);
const char* str = "hello world";//常量字符串
string s7(str, 5); //从常量字符串构造
string s8(100,'#'); //从常量字符串构造
cout << s1 << endl;
cout << s2 << endl;
cout << s3 << endl;
cout << s4 << endl;
cout << s5 << endl;
cout << s6 << endl;
cout << s7 << endl;
cout << s8 << endl;
}
int main()
{
test();
return 0;
}结果为:

string类对象的容量操作
| 函数名称 | 功能说明 |
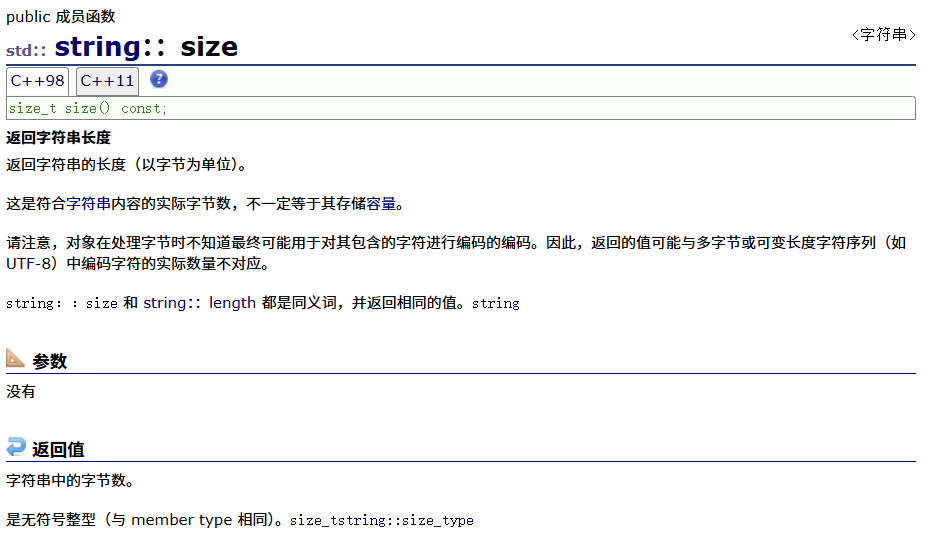
| size(重点) | 返回字符串有效字符长度 |
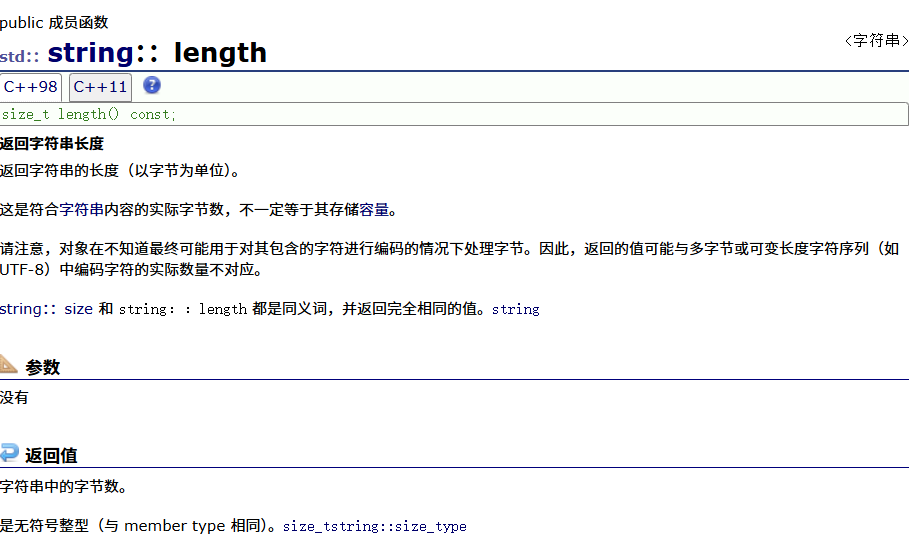
| length | 返回字符串有效字符长度 |
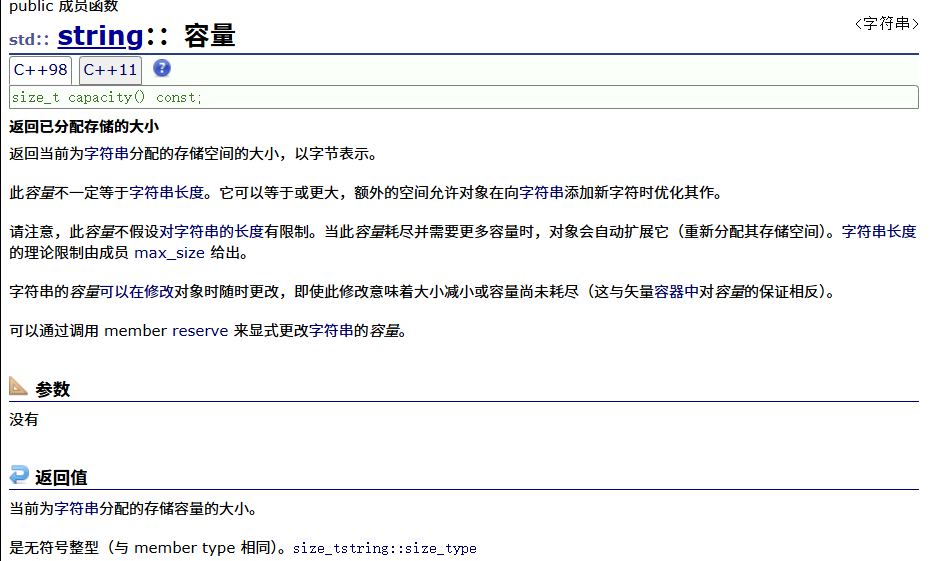
| capacity | 返回空间总大小 |
| empty(重点) | 检测字符串释放为空串,是返回true,否返回false |
| clear(重点) | 清空有效字符 |
| reserve(重点) | 给字符串预留空间 |
| resize(重点) | 讲有效字符的个数改成n个,多出的空间用字符c填充 |
注意:
1. size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一致,一般情况下基本都是用size()。
2. clear()只是将string中有效字符清空,不改变底层空间大小。
3. resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, charc)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
4. reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserver不会改变容量大小。
参考文献:string - C++ 参考
以下是一些关键内容的截图:
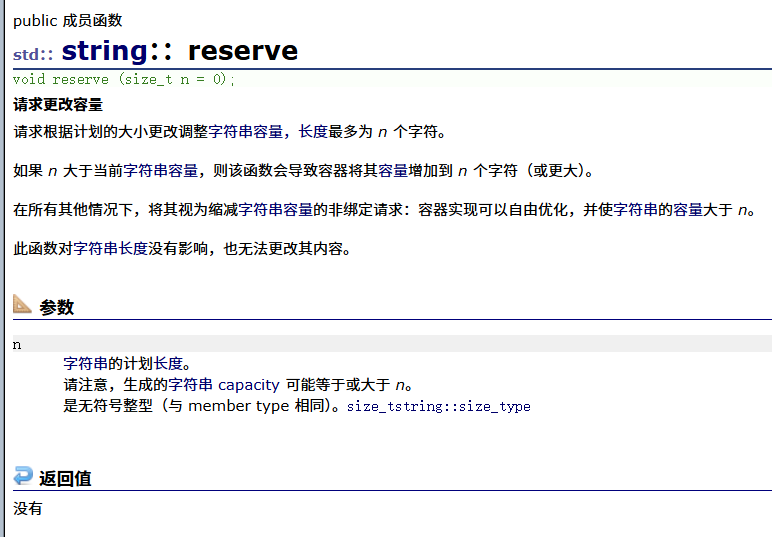

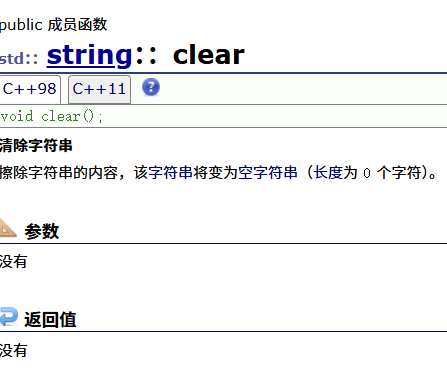
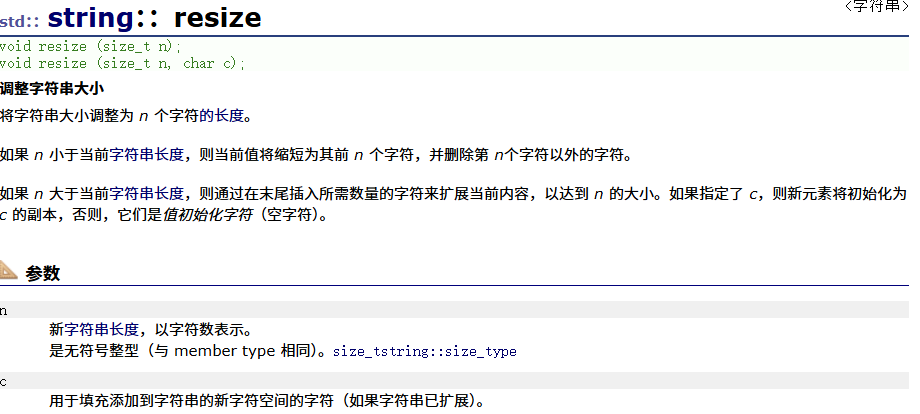
string的遍历
| 函数名称 | 功能说明 |
| operator[](重点) | 返回pos的位置,const string类对象调用 |
| begin+end | begin获取一个字符的迭代器+end获取最后一个字符下一个位置的迭代器 |
| rbegin+rend | begin获取一个字符的迭代器+end获取最后一个字符下一个位置的迭代器 |
| 范围for | C++11支持更简洁的范围for新遍历方式 |
一、[]运算符重载介绍
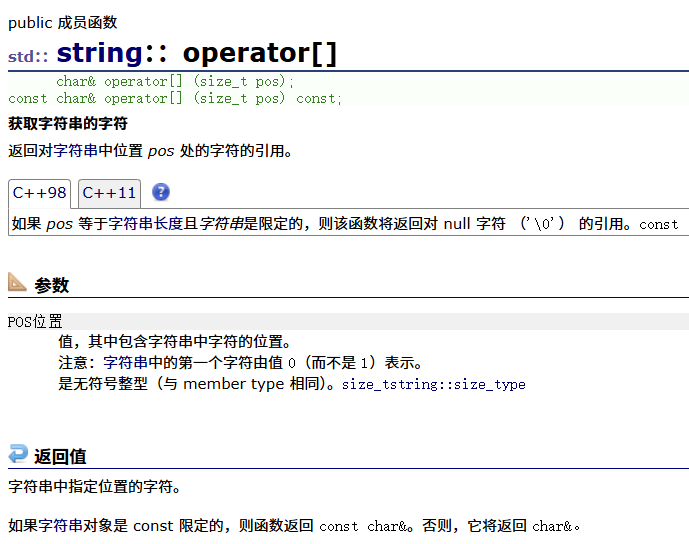
我们很明显地发现:s2是不能修改的

因为它们的调用关系是这样的
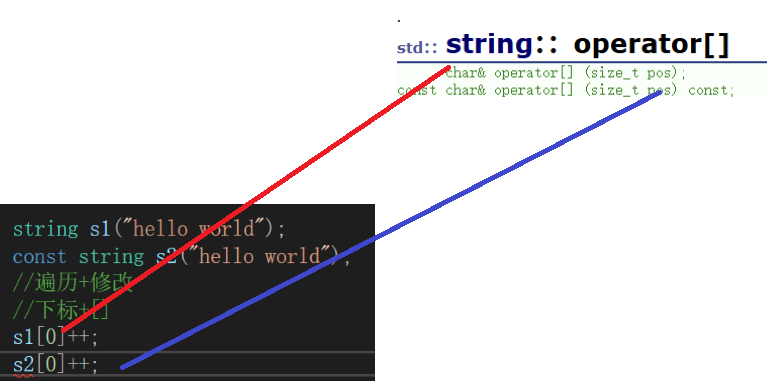
void test()
{
string s1("hello world");
const string s2("hello world");
//遍历+修改
//下标+[]
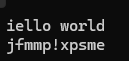
s1[0]++;
/*s2[0]++;*/
cout<<s1<<endl;
for (size_t i = 0;i < s1.size();i++)
{
s1[i]++;
}cout << s1 << endl;
}
int main()
{
test();
return 0;
}结果为:
二、迭代器
迭代器是像指针一样的类型对象
void test()
{
string s1("hello world");
const string s2("hello world");
//遍历+修改
//下标+[]
s1[0]++;
/*s2[0]++;*/
cout<<s1<<endl;
for (size_t i = 0;i < s1.size();i++)
{
s1[i]++;
}
cout << s1 << endl;
//begin() end()返回的是一段迭代器位置的区间,形式是这样的[ )
//迭代器
//s1--
//iterator迭代器
//迭代器使用起来像指针
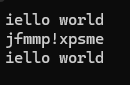
string::iterator it = s1.begin();
while (it!= s1.end())
{
(*it)--;
++it;
}
cout << s1 << endl;
}
int main()
{
test();
return 0;
}结果为:
迭代器是所有容器的主流迭代方式,迭代器具有迁移性,掌握一个其他的也可以轻松上手
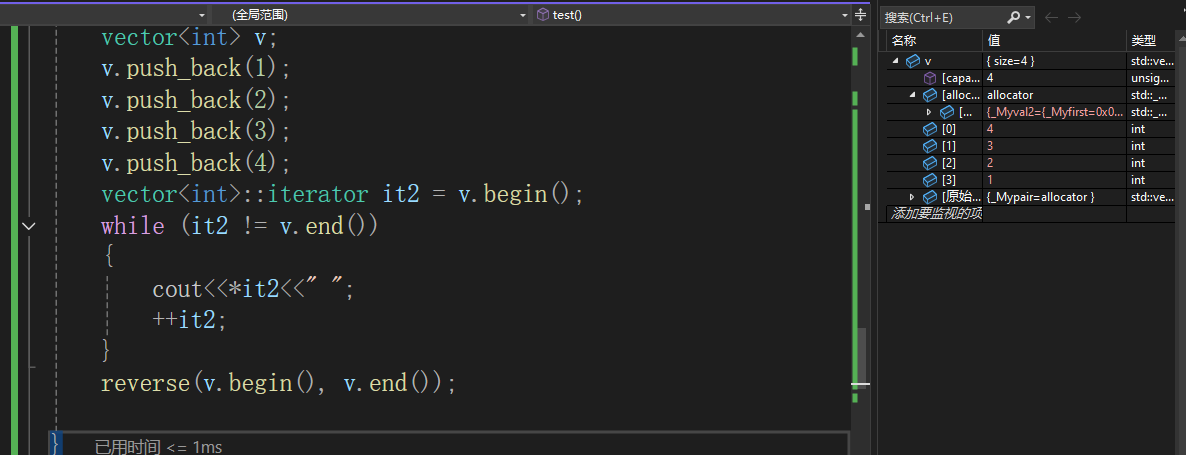
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
vector<int>::iterator it2 = v.begin();
while (it2 != v.end())
{
cout<<*it2<<" ";
++it2;
}
![]()
三、范围for (C++11)
(这里需要结合前面的auto和范围for的拓展知识内容)
#include<iostream>
#include<string>
#include<map>
using namespace std;
int main()
{
int arr[] = {1,2,3,4,5};
//C++11的遍历
for (auto& e : arr)
//从:开始自动,特点是:
//自动取范围中的数据赋值给e,
//自动判断结束
//自动迭代
{
e *= 2;
}
for (auto&e : arr)
{
cout<<e<<" " << endl;
}
string str("hello world");
for (auto ch : str)
{
cout<<ch<<" ";
}
cout<<endl;
return 0;
}范围for可以遍历vector,list等其他容器。
范围for本质上底层也会替换为新迭代器,即e=*迭代器
string类对象的修改操作
| 函数名称 | 功能介绍 |
| push back | 在字符串中后尾插字符c |
| append | 在字符串后追加一个字符串 |
| operator+=(重点) | 在字符串后追加字符串str |
| c_str(重点) | 返回C格式字符串 |
| find+npos(重点) | 从字符串pos位置开始向后找字符c,返回该字符在字符串中的位置 |
| rfind | 从字符串pos位置开始往前找字符c,返回该字符在字符串中位置 |
| substr | 在str中从pos位置开始,截取n个字符然后返回 |
注意:
1. 在string尾部追加字符时,s.push_back(c) / s.append(1, c) / s += 'c'三种的实现方式差不多,一般情况下string类的+=操作用的比较多,+=操作不仅可以连接单个字符,还可以连接字符串。
2. 对string操作时,如果能够大概预估到放多少字符,可以先通过reserve把空间预留好。
void test()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
vector<int>::iterator it2 = v.begin();
while (it2 != v.end())
{
cout<<*it2<<" ";
++it2;
}
reverse(v.begin(), v.end());
}
string类非成员函数
| 函数 | 功能说明 |
| operator+ | 尽量少用,因为传值返回,导致深拷贝效率降低 |
| operator>>(重点) | 输入运算符重载 |
| operator<<(重点) | 输出运算符重载 |
| getline(重点) | 获取一行字符串 |
| relation operators(重点) | 大小比较 |
上面的几个接口大家了解一下,下面的OJ题目中会有一些体现他们的使用。string类中还有一些其他的操作,这里不一一列举,大家在需要用到时不明白了查文档即可。
迭代器的介绍
迭代器的概念与分类
迭代器是STL中访问容器元素的通用接口,行为类似指针,但抽象程度更高。
-
迭代器类别:
-
正向迭代器(Forward Iterator):单向遍历(如
std::string::iterator)。 -
双向迭代器(Bidirectional Iterator):支持双向移动(如
std::list::iterator)。 -
随机访问迭代器(Random Access Iterator):支持跳跃访问(如
std::vector::iterator)。 -
反向迭代器(Reverse Iterator):逆序遍历容器(如
std::string::reverse_iterator)。 -
const迭代器:禁止修改元素(如
std::string::const_iterator)。
-
-
string的迭代器类型:
-
std::string::iterator:可修改的随机访问迭代器。 -
std::string::const_iterator:不可修改的随机访问迭代器。 -
std::string::reverse_iterator:可修改的反向迭代器。 -
std::string::const_reverse_iterator:不可修改的反向迭代器。
-
string中迭代器的获取方式
通过成员函数获取不同类别的迭代器:
正向迭代器:
std::string str = "Hello";
auto begin = str.begin(); // 指向第一个字符的迭代器
auto end = str.end(); // 指向末尾(最后一个字符的下一位)反向迭代器:
auto rbegin = str.rbegin(); // 指向最后一个字符的反向迭代器
auto rend = str.rend(); // 指向头部前一位的反向迭代器const迭代器:
auto cbegin = str.cbegin(); // 常量正向迭代器
auto crbegin = str.crbegin(); // 常量反向迭代器迭代器的基本操作
遍历字符串:
for (auto it = str.begin(); it != str.end(); ++it) {
std::cout << *it; // 解引用访问字符
}反向遍历:
for (auto rit = str.rbegin(); rit != str.rend(); ++rit) {
std::cout << *rit; // 输出逆序字符
}随机访问:
auto it = str.begin() + 3; // 跳转到第4个字符('l')
std::cout << *it; // 输出 'l'涉及迭代器的string成员函数
构造与赋值:
std::string s4(str.begin(), str.begin() + 3); // 构造子串 "Hel"
str.assign(s4.rbegin(), s4.rend()); // 赋值逆序子串 "leH"插入与删除:
str.insert(str.begin() + 2, 'X'); // 在位置2插入'X' → "HeXllo"
str.erase(str.begin() + 1); // 删除位置1的字符 → "HXllo"查找与替换:
auto pos = std::find(str.begin(), str.end(), 'X');
if (pos != str.end()) {
*pos = 'Y'; // 替换找到的字符
}与STL算法结合使用
利用标准算法处理字符串:
排序字符串字符:
std::sort(str.begin(), str.end()); // 升序排列字符统计字符出现次数:
int count = std::count(str.begin(), str.end(), 'l');条件查找:
auto it = std::find_if(str.begin(), str.end(), [](char c) {
return c >= 'A' && c <= 'Z';
});迭代器失效问题
-
导致失效的操作:
-
修改字符串长度(如
append(),insert(),erase())。 -
重新分配内存(如
reserve()不足时扩容)。
-
-
安全实践:
-
在修改操作后,避免使用旧的迭代器。
-
使用索引或重新获取迭代器。
-
实际应用示例
逆序输出字符串:
for (auto rit = str.rbegin(); rit != str.rend(); ++rit) {
std::cout << *rit;
}删除所有空格:
str.erase(std::remove(str.begin(), str.end(), ' '), str.end());转换为大写:
std::transform(str.begin(), str.end(), str.begin(), ::toupper);迭代器的意义:
1.统一类似的方式遍历修改容器
2.算法脱离了具体的底层结构,与底层结构解耦(降低耦合,降低关联关系)
算法独立模板实现,针对多个容器处理
下图就是相关的代码示例:(使用前要包含头文件<algorithm>)
一些string类的例题
1.仅仅反转字母
题目:

这道题本质上是类似于快速排序算法
这道题不适合用范围for,也不适合迭代器。用下标法求解这道题:
class Solution
{
public:
string reverseOnlyLetters(string s)
{
if(s.empty())
return s;
size_t begin=0,end=s.size()-1;
while(begin<end)
{
while(begin<end&&!isalpha(s[begin]))
{
++begin;
}
while(begin<end&&!isalpha(s[end]))
{
--end;
}
swap(s[begin],s[end]);
++begin;
--end;
}
return s;
}
};或者
class Solution
{
public:
bool isletter(char ch)
{
if(ch>='a'&&ch<='z')
{
return true;
}
else if(ch>='A'&&ch<='Z')
{
return true;
}
else
{
return false;
}
}
string reverseOnlyLetters(string s)
{
if(s.empty())
return s;
size_t begin=0,end=s.size()-1;
while(begin<end)
{
while(begin<end&&!isletter(s[begin]))
{
++begin;
}
while(begin<end&&!isletter(s[end]))
{
--end;
}
swap(s[begin],s[end]);
++begin;
--end;
}
return s;
}
};2.查找字符串中第一个唯一的字符
题目:

思路:哈希
哈希就是映射,即建立数字与位置的映射,就像下图这样
class Solution
{
public:
int firstUniqChar(string s)
{
int count[26]={0};
//每个字符出现的次数
for(auto e:s)
{
count[e-'a']++;
}
for(size_t i=0;i<s.size();++i)
{
if(count[s[i]-'a']==1)
{
return i;
}
}
return -1;
}
};本期博客就到这里了,string的内容还没有结束,后续我们会进一步了解string的应用