消息队列(Message Queue, MQ)作为现代分布式系统的基础组件,极大提升了系统的解耦、异步处理和削峰能力。本文以Kafka为例,系统梳理消息队列的核心原理、架构细节及实际应用。
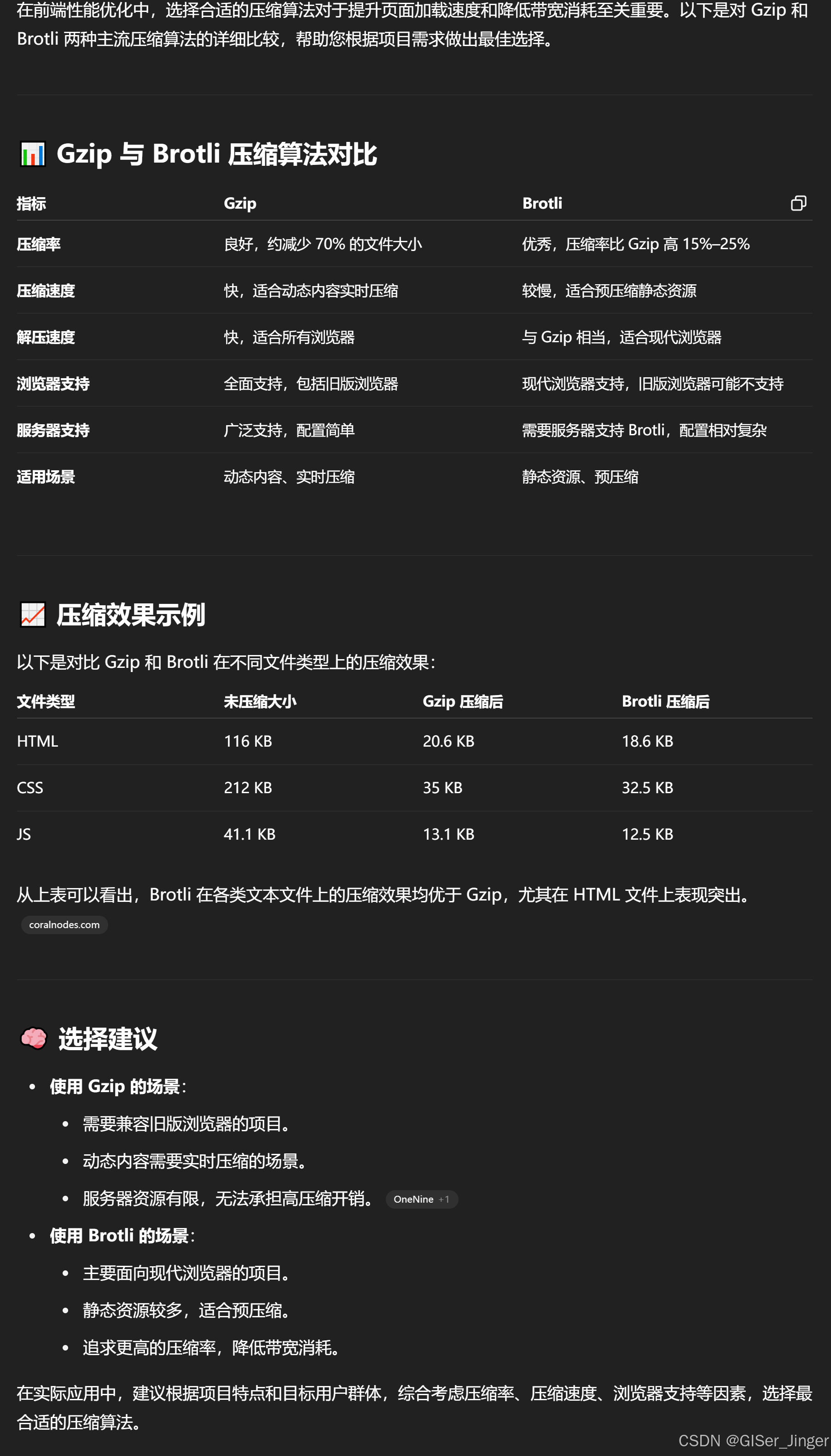
Kafka 基础架构及术语关系图
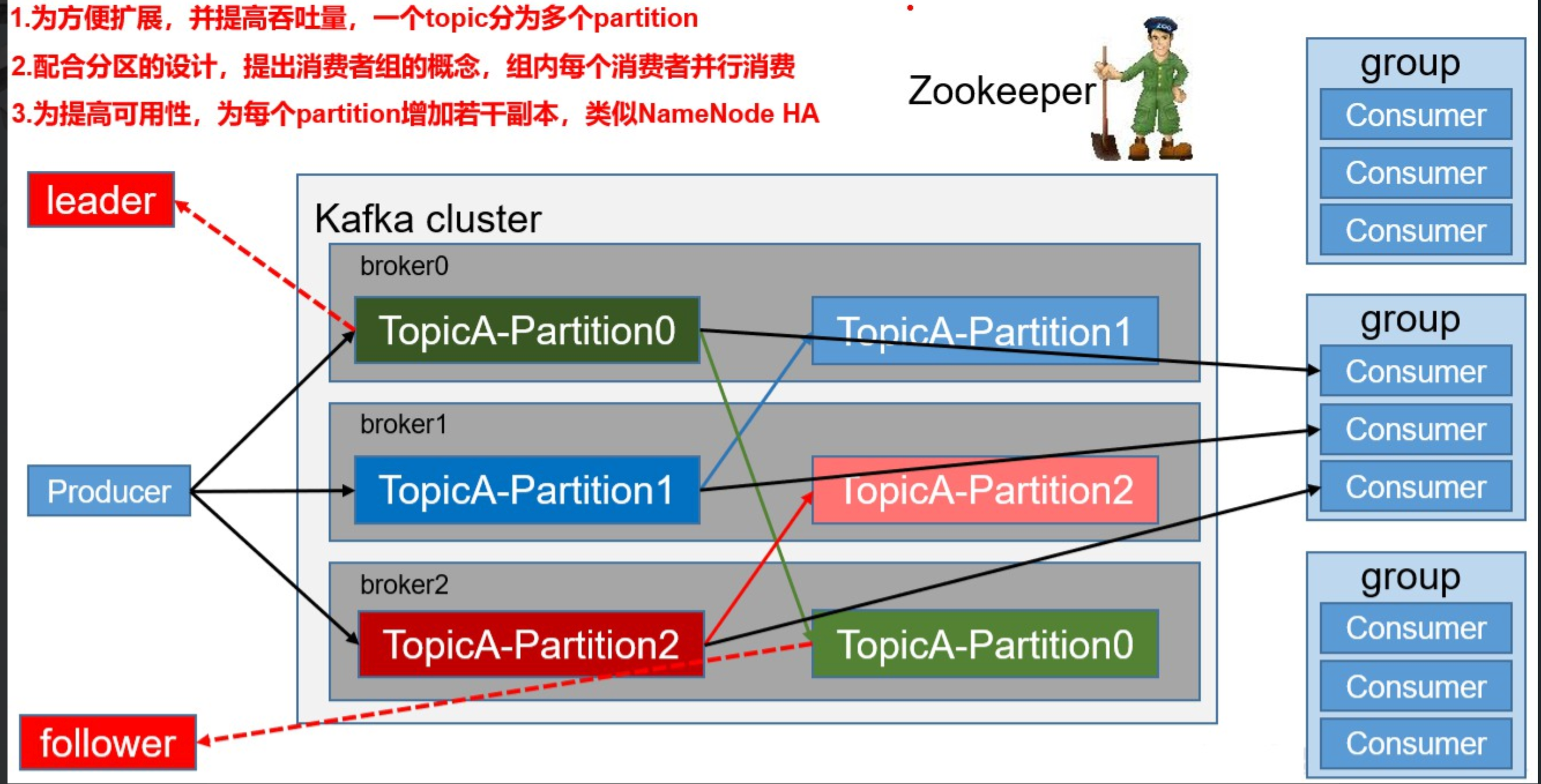
术语简要说明
- Producer:消息生产者,负责发送消息到 Topic。
- Broker:Kafka 实例,每台服务器可有一个或多个 Broker,负责存储和转发消息。
- Topic:消息主题,逻辑分类,数据以 Topic 组织。
- Partition:Topic 的分区,提升并发和吞吐量,每个分区的数据互不重复。
- Replication:分区副本,提升容错性,分为 Leader 和 Follower。
- Message:每条发送的消息主体。
- Consumer:消息消费者,负责消费 Topic 中的数据。
- Consumer Group:消费者组,组内消费者协作消费分区数据,提升吞吐量。
- Zookeeper:Kafka 集群依赖 Zookeeper 存储元信息,保证系统可用性。
为什么需要消息队列?
在分布式系统中,服务之间往往需要解耦、异步和高效通信。以快递和便利店的类比,消息队列就像"中转站",让生产者和消费者解耦:
- 解耦:生产者和消费者无需直接通信,通过队列中转,降低系统耦合度,便于独立扩展和维护。
- 异步:生产者无需等待消费者处理完毕,提升整体响应速度和系统吞吐量。
- 削峰填谷:高峰期消息先入队,消费者按能力慢慢处理,平滑流量压力,防止系统被突发流量压垮。
- 容错与可靠性:消息队列可持久化消息,防止数据丢失,提升系统健壮性。
消息队列的两种通信模式
- 点对点模式(P2P):
- 每条消息只被一个消费者消费。
- 适合任务分发、工作队列等场景。
- 消息有明确的发送者和接收者,消费后即被移除。
- 发布/订阅模式(Pub/Sub):
- 一条消息可被多个订阅者消费。
- 适合广播、通知、日志收集等场景。
- 生产者将消息发布到主题,所有订阅该主题的消费者都能收到消息。
Kafka简介
核心概念与机制
- Segment(段文件):分区的物理存储单元,便于管理和查找。
- Offset:消息在分区内的唯一编号,消费者通过offset定位消费进度。
- 副本机制:每个分区可配置多个副本(Replica),提升数据可靠性和高可用性。
- Leader-Follower:每个分区有一个Leader,负责读写请求,Follower同步Leader数据。
消息存储与高效查找
Kafka 在数据持久化方面采用了高效的顺序写入机制。Producer 将数据写入 Kafka 后,Kafka 会将数据直接顺序写入磁盘,避免了随机写入的低效问题。Kafka 启动时会单独开辟一块磁盘空间用于顺序写入,这也是其高并发高吞吐的关键。
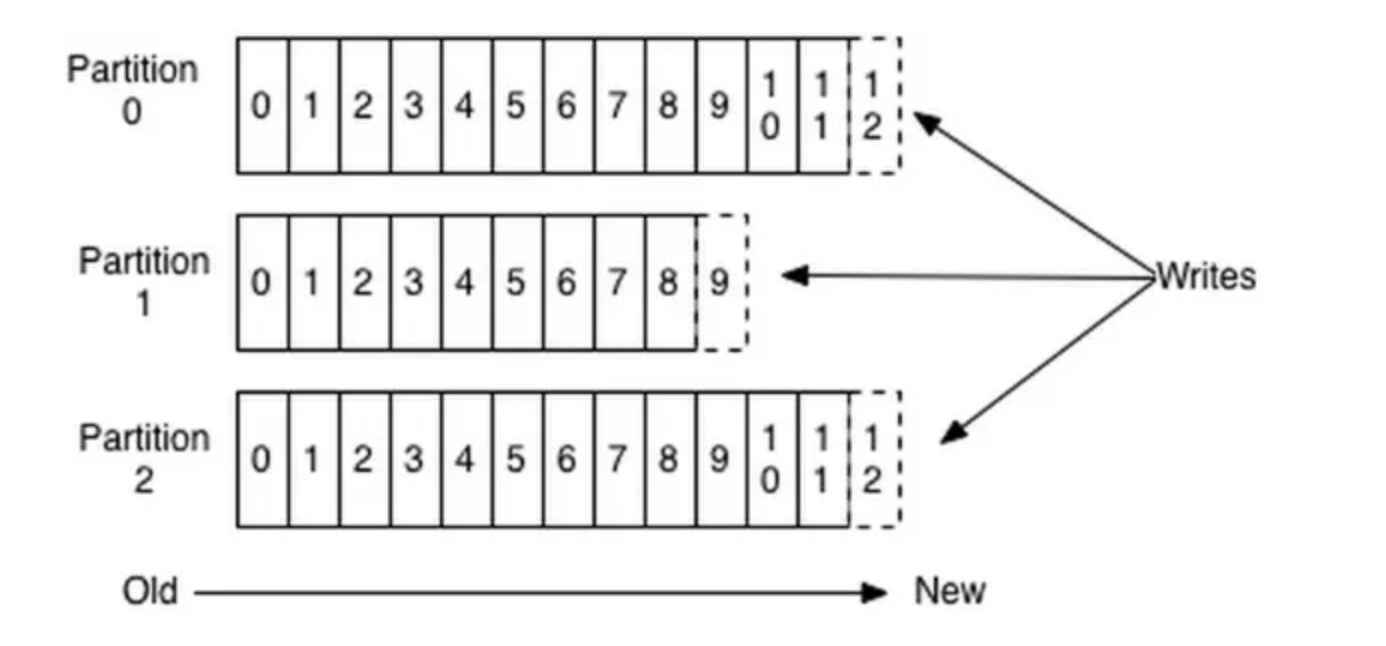
Partition 结构
每个 Topic 可以分为一个或多个 Partition。Partition 在服务器上的表现形式就是一个个文件夹,每个 Partition 文件夹下包含多组 segment 文件。每组 segment 文件又包含 .index 文件、.log 文件、.timeindex 文件(早期版本中没有)。
.log文件:实际存储消息(message)的地方。.index和.timeindex文件:为索引文件,用于高效检索消息。
如:
- 一个 Partition 可能有三组 segment 文件,每个 log 文件的大小相同,但存储的 message 数量可能不同(因每条 message 大小不一)。
- 文件命名以该 segment 最小 offset 命名,如
000.index存储 offset 为 0~368795 的消息。 - Kafka 通过分段(segment)+ 索引的方式,实现高效查找。
Message 结构
每条消息(message)在 log 文件中的结构主要包括:
- offset:8 字节有序 id,唯一标识消息在 partition 内的位置。
- 消息大小:4 字节,描述消息体的大小。
- 消息体:实际存放的数据(通常已压缩),大小不定。
存储策略
Kafka 无论消息是否被消费,都会保存所有消息。对于旧数据,Kafka 提供两种删除策略:
- 基于时间:如默认 168 小时(7 天)后自动删除。
- 基于大小:如默认 1GB,超出后删除最早的数据。
需要注意:Kafka 读取特定消息的时间复杂度为 O(1),删除过期文件并不会提升查找性能。
- 消息即使被消费也不会立即删除,便于多消费者组独立消费。
- 这种分段+索引+顺序写入的设计,是 Kafka 能够兼顾高吞吐与高效检索的核心。
消费机制与消费组
消息存储在 log 文件后,消费者即可进行消费。与生产消息类似,消费者在拉取消息时也是直接向分区的 leader 拉取数据。
Kafka 支持多个消费者组成一个消费者组(Consumer Group),每个组有唯一的 group id。组内的每个消费者可以消费同一 topic 下不同分区的数据,但同一分区的数据不会被组内多个消费者重复消费。
- 当消费者组内的消费者数量小于分区数量时,部分消费者会消费多个分区的数据,导致这些消费者的负载较重。
- 当消费者数量多于分区数量时,多出来的消费者不会分配到任何分区,不参与消费。
- 实际应用中,建议消费者组的 consumer 数量与 partition 数量一致,以充分利用并发能力。
offset 查找与高效检索
Kafka 通过 segment + offset + 稀疏索引 + 二分查找 + 顺序查找等机制,实现高效的数据定位。查找某个 offset 的消息流程如下:
- 先定位 offset 所在的 segment 文件(利用二分法查找)。
- 打开该 segment 的 .index 文件,查找小于或等于目标 offset 的最大相对 offset 条目,获取其物理偏移量。
- 从该物理位置开始顺序扫描 log 文件,直到找到目标 offset 的消息。
这种机制依赖 offset 的有序性和稀疏索引,极大提升了查找效率。
offset 管理
每个消费者需要记录自己消费到的位置(offset)。
- 早期 Kafka 版本将 offset 存储在 Zookeeper 中,易导致重复消费且性能有限。
- 新版本中,offset 已直接存储在 Kafka 集群的
__consumer_offsets这个特殊 topic 中,支持断点续传和高效管理。
应用场景
- 日志收集与分析:集中采集应用日志,实时分析与监控。
- 流式数据处理:与Spark、Flink等流处理框架集成,实现实时大数据分析。
- 消息驱动架构:微服务间异步通信,解耦业务模块。
- 事件溯源与审计:持久化事件流,便于追踪和回溯。
优缺点分析
优点:
- 高吞吐、低延迟,适合大规模数据流转。
- 分布式架构,易于横向扩展。
- 支持消息持久化和多副本,数据可靠性高。
- 灵活的消费模型,适应多种业务场景。
缺点:
- 依赖Zookeeper(或KRaft),运维复杂度较高。
- 消息顺序只在分区内保证,跨分区无序。
- 不适合极端低延迟、强事务场景。
总结
消息队列通过解耦、异步和削峰,极大提升了系统的弹性和可维护性。Kafka作为业界主流消息中间件,凭借高吞吐、分布式和高可用特性,成为大规模数据流转的首选。理解其原理和架构,有助于更好地设计和优化分布式系统。