Prompt-Aware Adapter: Towards Learning Adaptive Visual Tokens for Multimodal Large Language Models
➡️ 论文标题:Prompt-Aware Adapter: Towards Learning Adaptive Visual Tokens for Multimodal Large Language Models
➡️ 论文作者:Yue Zhang, Hehe Fan, Yi Yang
➡️ 研究机构: 浙江大学
➡️ 问题背景:当前的多模态大语言模型(Multimodal Large Language Models, MLLMs)通过适配器(adapters)将视觉输入转换为大语言模型(LLMs)可理解的token,但大多数适配器生成的视觉token与提示(prompt)无关,导致在处理复杂场景时效率低下,增加了LLMs的认知负担。
➡️ 研究动机:为了提高MLLMs在处理复杂视觉场景时的效率和准确性,研究团队提出了一种新的提示感知适配器(prompt-aware adapter),该适配器能够根据提示动态地嵌入视觉输入,从而更有效地捕捉与提示相关的视觉线索。
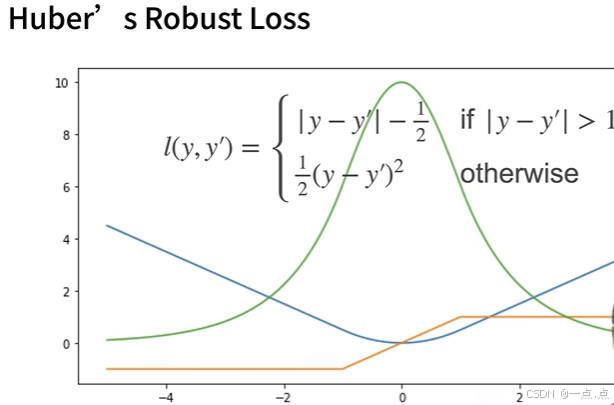
➡️ 方法简介:研究团队设计了一种包含全局注意力(global attention)和局部注意力(local attention)的提示感知适配器。全局注意力用于捕捉与提示相关的粗粒度视觉感知,而局部注意力则专注于细化对特定细粒度区域的响应。这种方法使得适配器能够更有效地揭示视觉上下文,并将注意力转移到相关区域。
➡️ 实验设计:研究团队在COCO-QA和MME数据集上进行了实验,评估了提示感知适配器在不同任务(如物体分类、计数、颜色识别和位置推理)中的表现。实验结果表明,与提示无关的基线方法相比,提示感知适配器在COCO-QA数据集上显著提高了物体分类、计数、颜色识别和位置推理的性能,分别提升了7.71%、18.42%、12.84%和9.51%。在MME数据集上,该方法在感知任务和认知任务的总得分上分别提高了59.43%和46.91%。
LM4LV: A Frozen Large Language Model for Low-level Vision Tasks
➡️ 论文标题:LM4LV: A Frozen Large Language Model for Low-level Vision Tasks
➡️ 论文作者:Boyang Zheng, Jinjin Gu, Shijun Li, Chao Dong
➡️ 研究机构: Shanghai Jiao Tong University, Shanghai AI Laboratory, Nanjing University, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences
➡️ 问题背景:大型语言模型(LLMs)的成功催生了多模态大型语言模型(MLLMs)的新研究趋势,这些模型在计算机视觉的多个领域中改变了范式。尽管MLLMs在许多高级视觉和视觉-语言任务(如VQA和文本到图像生成)中展示了有希望的结果,但目前尚无研究展示MLLMs如何在低级视觉任务中发挥作用。研究发现,大多数当前的MLLMs由于其视觉模块的设计,对低级特征视而不见,因此无法解决低级视觉任务。
➡️ 研究动机:现有的MLLMs主要集中在文本和图像模态的更好语义融合上,而低级视觉任务尚未显著受益于MLLMs带来的变化。本研究旨在探索如何利用MLLMs接受、处理和输出低级特征,以弥合MLLMs与低级视觉任务之间的差距。这不仅能够推动MLLMs的极限,还能为低级视觉任务提供更好的用户交互和更高的可解释性。
➡️ 方法简介:研究团队提出了一种框架LM4LV,该框架使冻结的LLM能够在没有任何多模态数据或先验的情况下解决一系列低级视觉任务。通过训练两个线性层与视觉数据,冻结的LLM展示了在多种低级视觉任务上的非平凡能力。
➡️ 实验设计:实验在多个低级视觉任务上进行,包括去噪、去模糊、椒盐噪声去除、去雨和去遮罩。实验设计了不同的退化类型和程度,以及不同的评估指标(如PSNR和SSIM),以全面评估模型在处理低级视觉特征方面的性能。实验结果表明,LM4LV在所有恢复任务中均优于仅使用MAE重建退化图像的基线方法,平均PSNR提高了3.96dB,平均SSIM提高了0.09。在空间操作任务中,LM4LV也取得了接近基线的高PSNR和SSIM值。
Human-Centered Automation
➡️ 论文标题:Human-Centered Automation
➡️ 论文作者:Carlos Toxtli
➡️ 研究机构: Clemson University, USA
➡️ 问题背景:随着生成式人工智能(如大型语言模型LLMs和多模态大型语言模型MLLMs)的快速发展,这些技术有潜力彻底改变我们在各个行业中的工作方式和与数字系统的互动方式。然而,当前的软件自动化技术(如机器人流程自动化RPA框架)往往需要领域专业知识,缺乏可见性和直观界面,使得用户难以充分利用这些技术。
➡️ 研究动机:本文旨在介绍并倡导新兴的人类中心自动化(HCA)领域,该领域在自动化系统的设计和开发中优先考虑用户需求和偏好。通过将用户置于自动化过程的中心,HCA寻求创建直观、适应性强且赋权的解决方案,使用户能够在无需广泛技术知识的情况下利用AI和RPA的优势。
➡️ 方法简介:研究团队提出了一个框架,用于设计以用户为中心的自动化解决方案。该框架强调了考虑用户视角的重要性,并提供了多个示例和指南,说明如何在不同领域和用例中应用HCA,以简化工作流程并保持竞争力。
➡️ 实验设计:论文讨论了现有自动化方法的局限性,包括RPA和生成式AI的挑战,以及HCA在提高生产力、创新和普及这些技术方面的潜力。研究还探讨了如何利用多模态大型语言模型(MLLMs)理解用户行为和屏幕内容,以实现更高级和上下文感知的自动化解决方案。此外,论文还探讨了实现更先进和上下文感知自动化解决方案的路径,并呼吁研究人员和实践者关注开发适应用户需求、提供直观界面并利用高端AI能力的自动化技术,以创造一个更加可访问和用户友好的自动化未来。
A Survey of Multimodal Large Language Model from A Data-centric Perspective
➡️ 论文标题:A Survey of Multimodal Large Language Model from A Data-centric Perspective
➡️ 论文作者:Tianyi Bai, Hao Liang, Binwang Wan, Yanran Xu, Xi Li, Shiyu Li, Ling Yang, Bozhou Li, Yifan Wang, Bin Cui, Ping Huang, Jiulong Shan, Conghui He, Binhang Yuan, Wentao Zhang
➡️ 研究机构: 香港科技大学、北京大学、哈尔滨工业大学、苹果公司、中国科学技术大学、上海人工智能实验室
➡️ 问题背景:多模态大语言模型(Multimodal Large Language Models, MLLMs)通过整合和处理来自多种模态的数据(包括文本、视觉、音频、视频和3D环境),增强了标准大语言模型的能力。数据在这些模型的开发和优化中起着关键作用。本文从数据驱动的角度全面回顾了MLLMs的文献,探讨了预训练和适应阶段的多模态数据准备方法,分析了数据集的评估方法,并回顾了评估MLLMs的基准。
➡️ 研究动机:尽管现有的MLLMs主要集中在模型架构的改进上,但数据对模型性能的影响同样重要。本文旨在从数据驱动的角度提供对MLLMs的全面理解,促进该领域的进一步探索和创新。
➡️ 方法简介:本文从数据收集、数据处理、数据选择和数据评估四个方面系统地回顾了MLLMs的数据准备和管理流程。具体包括数据收集的来源、数据处理的方法(如过滤、去重和增强)、数据选择的方法(如主动学习、分布无关和分布相关选择),以及数据评估的方法和评估基准。
➡️ 实验设计:本文没有具体描述实验设计,而是通过文献回顾的方式,总结了不同阶段的数据处理方法和评估标准,包括数据收集的来源、数据处理的方法、数据选择的方法,以及数据评估的方法和评估基准。这些内容为研究人员提供了关于MLLMs数据处理的全面指南。
RLAIF-V: Open-Source AI Feedback Leads to Super GPT-4V Trustworthiness
➡️ 论文标题:RLAIF-V: Open-Source AI Feedback Leads to Super GPT-4V Trustworthiness
➡️ 论文作者:Tianyu Yu, Haoye Zhang, Qiming Li, Qixin Xu, Yuan Yao, Da Chen, Xiaoman Lu, Ganqu Cui, Yunkai Dang, Taiwen He, Xiaocheng Feng, Jun Song, Bo Zheng, Zhiyuan Liu, Tat-Seng Chua, Maosong Sun
➡️ 研究机构: 清华大学计算机科学与技术系、新加坡国立大学NExT++实验室、哈尔滨工业大学、阿里巴巴淘宝天猫集团、鹏城实验室
➡️ 问题背景:当前的多模态大语言模型(MLLMs)在处理多样化的多模态任务时表现出色,但这些模型容易生成与人类偏好不符的错误内容。为了使MLLMs与人类偏好对齐,通常采用基于人类反馈的强化学习(RLHF),但这种方法依赖于劳动密集型的人工标注,难以覆盖模型与人类偏好之间的广泛不一致。最近,基于AI反馈的强化学习(RLAIF)作为一种替代方案,显示出巨大潜力,但现有方法依赖于昂贵的专有模型来提供反馈,且缺乏使用开源MLLMs生成高质量反馈的知识。
➡️ 研究动机:为了克服现有RLAIF方法的挑战,研究团队提出了RLAIF-V框架,旨在通过完全开源的方式对齐MLLMs。该框架通过生成高质量的反馈数据和提供推理时间的自我反馈指导,显著增强了模型的可信度。
➡️ 方法简介:RLAIF-V框架包括两个主要创新:1)高质量反馈生成:通过去混淆的候选响应生成策略和分而治之的方法,提高数据效率和成对偏好准确性。2)推理时间的自我反馈指导:利用直接偏好优化(DPO)对齐的模型生成的奖励分数作为自我反馈,通过长度归一化策略解决对较短响应的偏见。
➡️ 实验设计:在六个基准数据集上进行了实验,包括自动和人工评估。实验设计了不同的反馈生成方法和反馈收集方法,以全面评估模型在偏好学习和推理时间的性能。实验结果表明,RLAIF-V 7B在多个基准上显著减少了对象幻觉和总体幻觉,而RLAIF-V 12B进一步展示了开源MLLMs的自我对齐潜力,其性能甚至超过了GPT-4V。