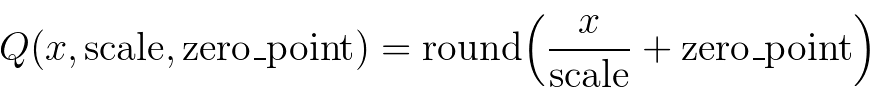名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、深度CNN架构解析
- 1. LeNet-5(1998)
- 2. AlexNet(2012)
- 3. VGG(2014)
- 4. ResNet(2015)
- 5. CNN架构演化与对比
- 二、数据增强技术
- 1. 数据增强的核心原理
- 2. 常见的数据增强技术
- 几何变换
- 颜色和强度变换
- 3. 使用Keras实现数据增强
- 4. 数据增强的最佳实践
- 三、Dropout与Batch Normalization
- 1. Dropout技术
- 工作原理
- Dropout的优势
- 使用建议
- 2. Batch Normalization
- 工作原理
- Batch Normalization的优势
- 使用建议
- 3. Dropout与BN的结合使用
- 四、CIFAR-10图像分类实战
- 1. 数据集介绍
- 2. 数据预处理
- 3. 构建ResNet模型
- 4. 模型训练与评估
- 5. 结果可视化
- 6. 可视化特征图
- 五、总结与展望
- 学习资源
- 下一步学习方向
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第53天:卷积神经网络(CNN)入门
欢迎来到Python星球的第54天!🪐
昨天我们学习了卷积神经网络的基础知识,今天我们将深入探索更高级的CNN架构和技术,这些知识将帮助你构建更强大、更准确的图像识别模型。
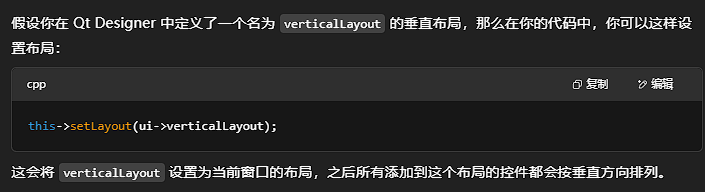
一、深度CNN架构解析
随着深度学习的发展,卷积神经网络的架构也变得越来越复杂和强大。让我们来了解几个里程碑式的CNN架构。
1. LeNet-5(1998)
LeNet-5是由Yann LeCun开发的最早的CNN架构之一,主要用于手写数字识别。
LeNet-5 虽然结构简单,但奠定了现代CNN的基础,包含了卷积层、池化层和全连接层的组合。它的设计思想是通过卷积提取特征,通过池化减少参数,最后通过全连接层进行分类。
2. AlexNet(2012)
AlexNet是深度学习复兴的标志性架构,在2012年的ImageNet竞赛中以显著优势获胜。
AlexNet的主要创新点:
- 使用ReLU激活函数替代传统的Sigmoid,减缓了梯度消失问题
- 引入Dropout来防止过拟合
- 使用GPU加速训练,这使得更深的网络成为可能
- 数据增强技术的广泛应用
3. VGG(2014)
VGG网络由牛津大学Visual Geometry Group提出,以其简洁统一的结构著称。
VGG的主要特点:
- 使用小尺寸卷积核(3×3)替代大尺寸卷积核,通过叠加多层实现更大的感受野
- 网络结构统一,易于理解和扩展
- 具有多个变体(VGG-16, VGG-19等),深度不同
- 参数量大,需要更多的计算资源
4. ResNet(2015)
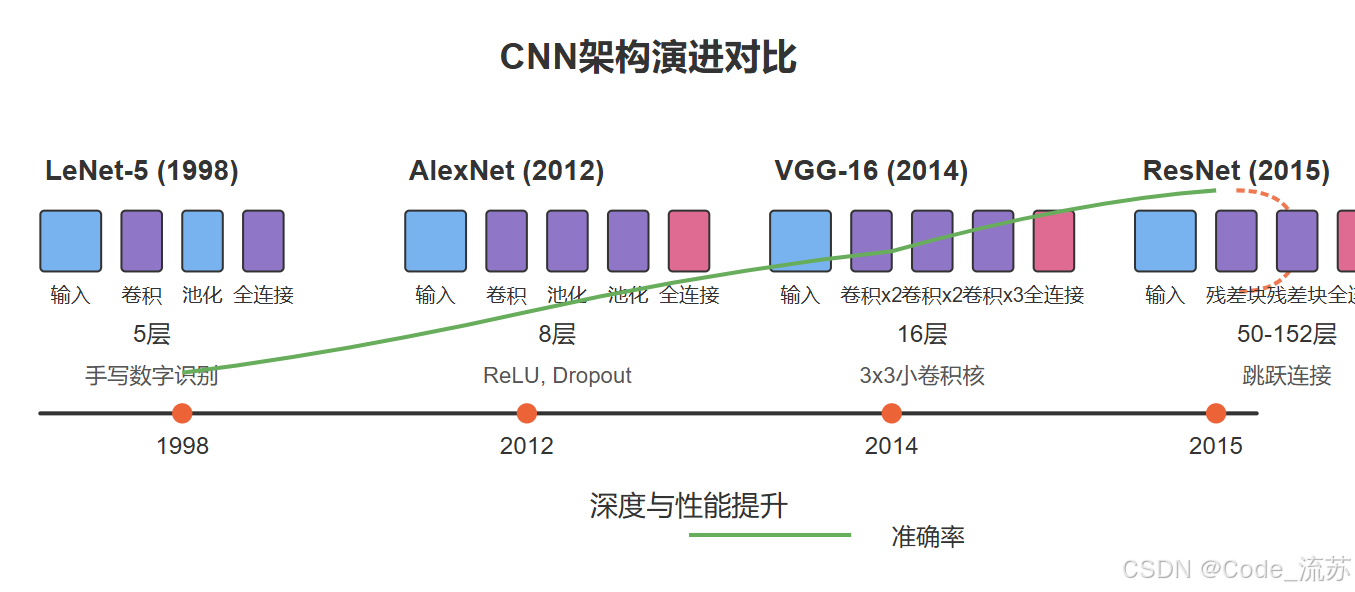
残差网络(ResNet)解决了深度网络训练中的梯度消失/爆炸问题,使得训练超过100层的网络成为可能。
ResNet的核心创新是引入了残差块(Residual Block),它通过添加跳跃连接(Skip Connection),允许信息直接从前层传递到后层,大大缓解了梯度消失问题。
残差块的数学表达式为: F(x) + x,其中F(x)是需要学习的残差映射,x是输入特征。这种简单而优雅的设计使网络能够学习残差而非完整映射,大大简化了训练过程。
5. CNN架构演化与对比
随着时间的推移,CNN架构变得越来越深,性能也越来越强:
| 网络名称 | 年份 | 层数 | 参数量 | Top-5错误率(ImageNet) | 主要创新点 |
|---|---|---|---|---|---|
| LeNet-5 | 1998 | 5 | 60K | - | 基础CNN结构 |
| AlexNet | 2012 | 8 | 62M | 15.3% | ReLU, Dropout, 数据增强 |
| VGG-16 | 2014 | 16 | 138M | 7.3% | 小卷积核堆叠, 统一结构 |
| ResNet-50 | 2015 | 50 | 25.6M | 3.6% | 残差连接 |
| ResNet-152 | 2015 | 152 | 60M | 3.57% | 超深网络 |
我们可以看到,深度增加的同时,现代网络通过特殊设计(如残差连接)实现了参数量的相对控制。
二、数据增强技术
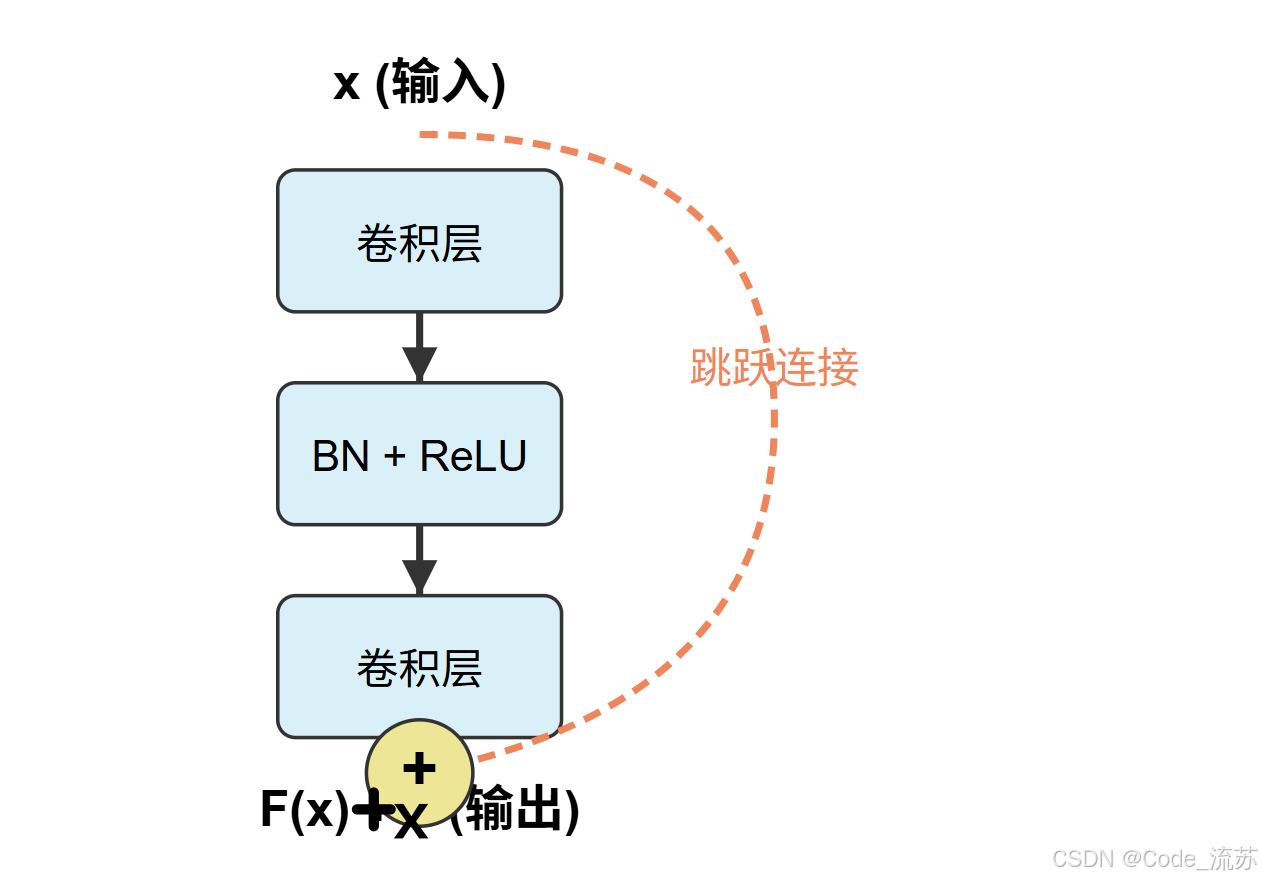
数据增强是解决过拟合和提高模型泛化能力的重要技术,尤其在训练数据有限的情况下。
1. 数据增强的核心原理
数据增强通过对原始图像进行各种变换,生成新的训练样本,从而:
- 扩大训练集规模
- 增加数据多样性
- 提高模型对各种变化的鲁棒性
- 减少过拟合
2. 常见的数据增强技术
几何变换
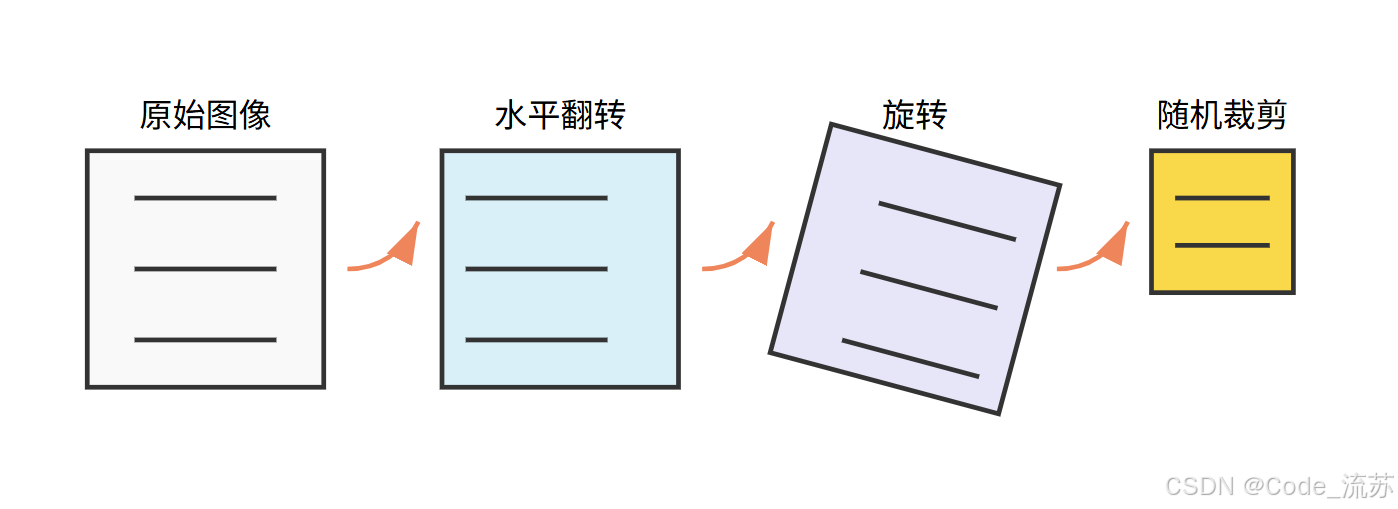
-
水平翻转(Horizontal Flip)
- 将图像左右翻转
- 特别适合对称物体,如人脸、车辆等
- 代码实现:
tf.image.flip_left_right(image)
-
旋转(Rotation)
- 将图像按一定角度旋转
- 通常使用较小的角度(如±15°)避免信息丢失
- 代码实现:
tf.image.rot90(image, k=1)(旋转90度)
-
随机裁剪(Random Crop)
- 从原图中随机裁剪一部分作为训练样本
- 能够强制模型关注图像的不同部分
- 代码实现:
tf.image.random_crop(image, [height, width, 3])
颜色和强度变换
-
亮度和对比度调整
- 随机改变图像的亮度和对比度
- 提高模型对不同光照条件的适应能力
- 代码实现:
# 随机调整亮度 image = tf.image.random_brightness(image, max_delta=0.2) # 随机调整对比度 image = tf.image.random_contrast(image, lower=0.8, upper=1.2)
-
色调和饱和度调整
- 改变图像的色调和饱和度
- 增强模型对颜色变化的鲁棒性
- 代码实现:
# 随机调整色调 image = tf.image.random_hue(image, max_delta=0.2) # 随机调整饱和度 image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
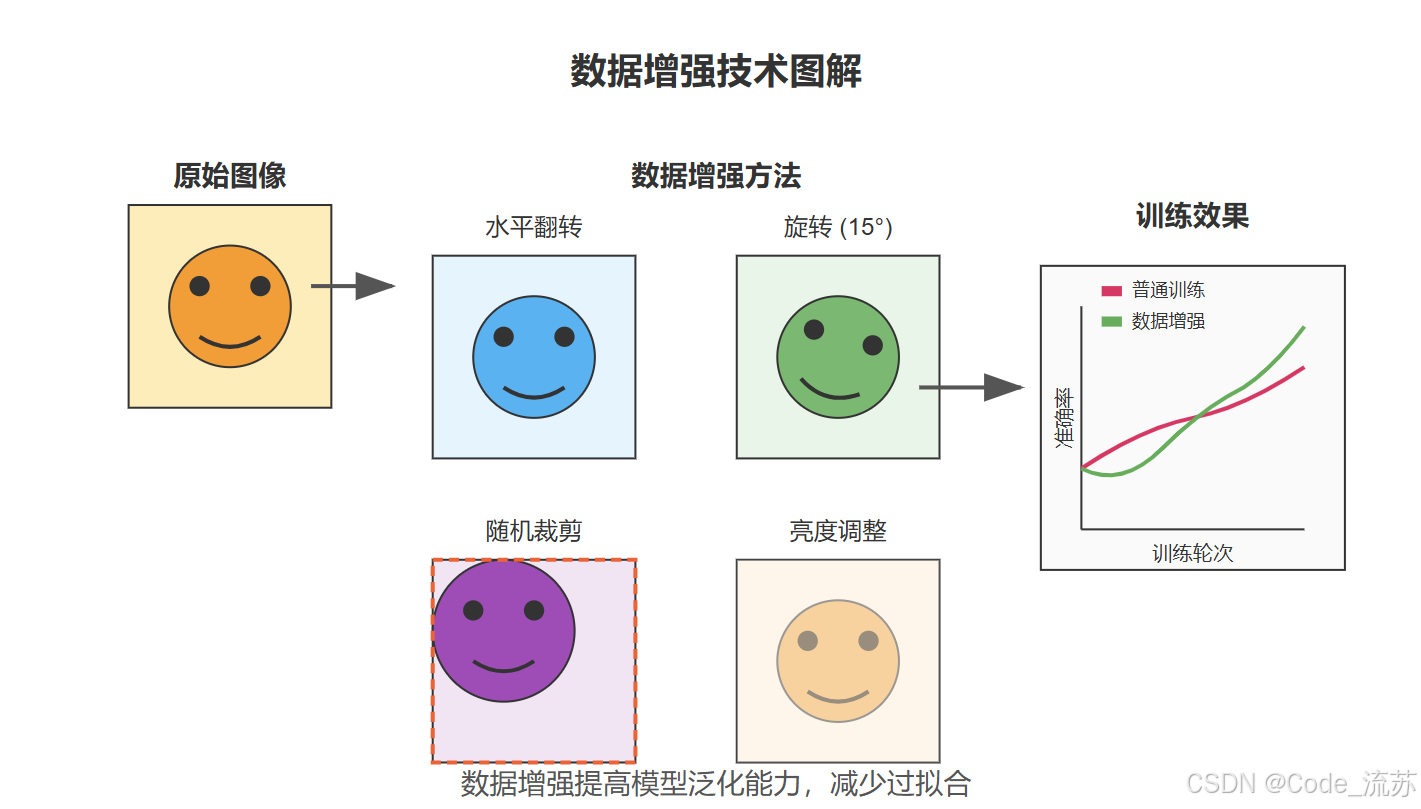
3. 使用Keras实现数据增强
Keras提供了便捷的ImageDataGenerator类来实现数据增强:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 创建数据增强器
data_augmentation = ImageDataGenerator(
rotation_range=15, # 旋转范围(0-180)
width_shift_range=0.1, # 水平平移范围
height_shift_range=0.1, # 垂直平移范围
horizontal_flip=True, # 水平翻转
zoom_range=0.1, # 缩放范围
shear_range=0.1, # 剪切变换范围
brightness_range=[0.8, 1.2], # 亮度调整范围
fill_mode='nearest' # 填充模式
)
# 应用到训练数据
train_generator = data_augmentation.flow(
x_train, y_train,
batch_size=32
)
# 训练模型
model.fit(
train_generator,
steps_per_epoch=len(x_train) // 32,
epochs=50
)
4. 数据增强的最佳实践
- 保持标签一致性:确保增强后的图像仍然与原来的标签相符
- 适度使用:过度增强可能引入不必要的噪声
- 领域相关:根据特定任务选择合适的增强方法(例如医学图像可能不适合颜色变换)
- 实时增强:在训练过程中动态生成增强图像,而不是预先生成
- 验证集不增强:只对训练集应用数据增强,验证集保持原样以准确评估模型性能
三、Dropout与Batch Normalization
在深度神经网络中,Dropout和Batch Normalization是两种重要的正则化和优化技术。
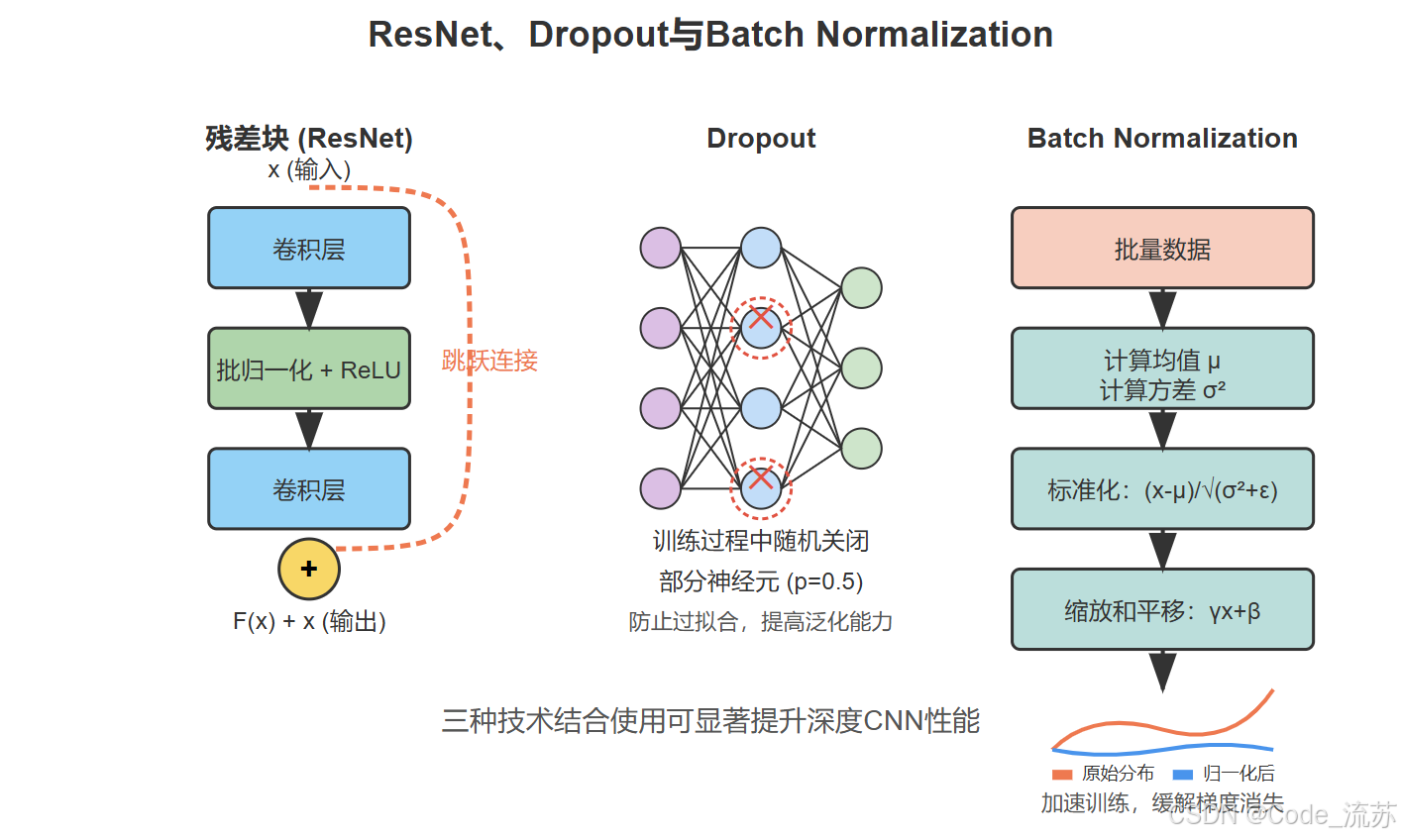
1. Dropout技术
Dropout是一种简单而有效的正则化技术,主要用于防止神经网络过拟合。
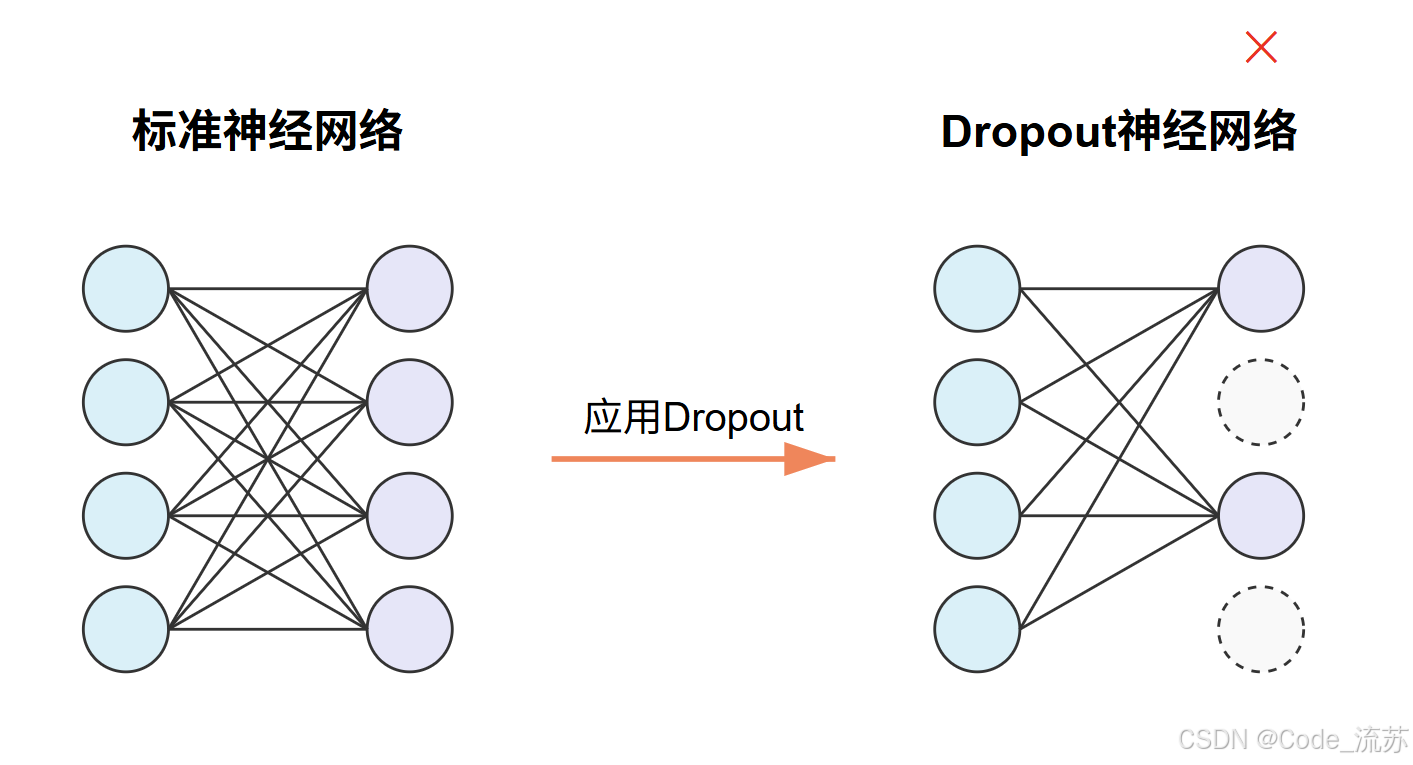
工作原理
Dropout在训练过程中随机关闭(设置为0)一定比例的神经元,强制网络学习更加鲁棒的特征表示。具体来说:
-
训练阶段:以概率p随机断开神经元连接
# Dropout层,p=0.5表示有50%的神经元会被随机关闭 model.add(Dropout(0.5)) -
测试阶段:所有神经元都参与计算,但输出会乘以(1-p)进行缩放,以补偿训练时丢弃的神经元
Dropout的优势
- 防止过拟合:通过随机丢弃神经元,避免网络对训练数据的过度记忆
- 提高鲁棒性:迫使网络学习多样化的特征,不依赖于特定的神经元组合
- 实现了集成学习:相当于同时训练多个不同的子网络,并在测试时进行平均
- 降低神经元间的共适应性:防止神经元之间形成强依赖关系
使用建议
- 合适的丢弃率:通常设置为0.2-0.5,较大的网络可以使用较高的丢弃率
- 放置位置:一般放在全连接层之后,卷积层之后较少使用
- 不在测试时使用:测试阶段应关闭Dropout功能
2. Batch Normalization
Batch Normalization (BN)是一种网络层,用于标准化每一层的输入,从而加速训练过程并提高模型性能。
工作原理
Batch Normalization通过以下步骤对每个mini-batch的特征进行标准化:
- 计算批次均值:μᵦ = (1/m) Σᵢ₌₁ᵐ xᵢ
- 计算批次方差:σ²ᵦ = (1/m) Σᵢ₌₁ᵐ (xᵢ - μᵦ)²
- 标准化:x̂ᵢ = (xᵢ - μᵦ) / √(σ²ᵦ + ε),其中ε是一个小常数,防止除零
- 缩放和偏移:yᵢ = γ · x̂ᵢ + β,其中γ和β是可学习的参数
在Keras中的实现:
from tensorflow.keras.layers import BatchNormalization
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(BatchNormalization())
Batch Normalization的优势
- 加速训练:通过标准化每层的输入,减少了内部协变量偏移,使得优化过程更加稳定
- 允许更高的学习率:归一化后的数据不容易产生梯度爆炸或消失
- 减少过拟合:具有一定的正则化效果,因为每个mini-batch的统计量有微小波动
- 降低对初始化的敏感性:减轻了权重初始化对模型训练的影响
- 减少对Dropout的依赖:在某些情况下,BN可以部分替代Dropout的功能
使用建议
- 放置位置:一般放在卷积层或全连接层之后,激活函数之前
- 与激活函数的关系:
# 推荐方式:Conv -> BN -> ReLU model.add(Conv2D(64, (3, 3))) model.add(BatchNormalization()) model.add(Activation('relu')) - 小批量大小:BN对较小的批量大小效果不佳,建议使用>=32的批量大小
- 推理阶段:测试时使用整个训练集的均值和方差,而不是批次统计量
3. Dropout与BN的结合使用
Dropout和Batch Normalization通常可以结合使用,但需要注意顺序:
model.add(Conv2D(64, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.3)) # 在激活函数之后应用Dropout
研究表明,将BN放在激活函数前,将Dropout放在激活函数后效果最佳。
四、CIFAR-10图像分类实战
CIFAR-10是一个包含60,000张32×32彩色图像的数据集,分为10个类别,每类6,000张图像。这是一个很好的CNN进阶练习数据集。
1. 数据集介绍
CIFAR-10的10个类别包括:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。
# 加载CIFAR-10数据集
from tensorflow.keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 查看数据集形状
print(f"训练集: {x_train.shape}, {y_train.shape}")
print(f"测试集: {x_test.shape}, {y_test.shape}")
2. 数据预处理
import numpy as np
from tensorflow.keras.utils import to_categorical
# 数据归一化
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# 对标签进行one-hot编码
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# 创建数据增强器
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
zoom_range=0.1
)
# 将数据增强器应用于训练数据
datagen.fit(x_train)
3. 构建ResNet模型
让我们实现一个基于ResNet的深度CNN模型来分类CIFAR-10图像:
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, BatchNormalization, Activation
from tensorflow.keras.layers import MaxPooling2D, AveragePooling2D, Flatten, Dense, add, Dropout
def residual_block(x, filters, kernel_size=3, stride=1, conv_shortcut=False):
"""残差块的实现"""
shortcut = x
if conv_shortcut:
shortcut = Conv2D(filters, 1, strides=stride)(shortcut)
shortcut = BatchNormalization()(shortcut)
# 第一个卷积块
x = Conv2D(filters, kernel_size, strides=stride, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 第二个卷积块
x = Conv2D(filters, kernel_size, padding='same')(x)
x = BatchNormalization()(x)
# 添加跳跃连接
x = add([x, shortcut])
x = Activation('relu')(x)
return x
def build_resnet_model(input_shape, num_classes):
"""构建ResNet模型"""
inputs = Input(shape=input_shape)
# 初始卷积层
x = Conv2D(32, 3, padding='same')(inputs)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 残差块
x = residual_block(x, 32)
x = residual_block(x, 32)
x = residual_block(x, 64, stride=2, conv_shortcut=True)
x = residual_block(x, 64)
x = residual_block(x, 128, stride=2, conv_shortcut=True)
x = residual_block(x, 128)
# 全局平均池化
x = AveragePooling2D(pool_size=4)(x)
x = Flatten()(x)
x = Dense(256)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Dropout(0.5)(x)
# 输出层
outputs = Dense(num_classes, activation='softmax')(x)
model = Model(inputs=inputs, outputs=outputs)
return model
# 构建模型
model = build_resnet_model((32, 32, 3), 10)
# 编译模型
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
# 打印模型结构
model.summary()
4. 模型训练与评估
from tensorflow.keras.callbacks import ModelCheckpoint, LearningRateScheduler, ReduceLROnPlateau
# 学习率调度器
def lr_schedule(epoch):
lr = 0.001
if epoch > 75:
lr *= 0.1
if epoch > 100:
lr *= 0.1
return lr
lr_scheduler = LearningRateScheduler(lr_schedule)
# 学习率自动调整
reduce_lr = ReduceLROnPlateau(
monitor='val_loss',
factor=0.2,
patience=5,
min_lr=0.00001
)
# 模型保存
checkpoint = ModelCheckpoint(
'best_resnet_cifar10.h5',
monitor='val_accuracy',
save_best_only=True,
mode='max'
)
# 训练模型
batch_size = 64
epochs = 120
history = model.fit(
datagen.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch=len(x_train) // batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
callbacks=[lr_scheduler, reduce_lr, checkpoint]
)
# 加载最佳模型
from tensorflow.keras.models import load_model
best_model = load_model('best_resnet_cifar10.h5')
# 评估模型
score = best_model.evaluate(x_test, y_test)
print(f"测试集准确率: {score[1]*100:.2f}%")
5. 结果可视化
import matplotlib.pyplot as plt
# 绘制训练历史
plt.figure(figsize=(12, 4))
# 准确率曲线
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.title('模型准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率')
plt.legend()
# 损失曲线
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.title('模型损失')
plt.xlabel('Epoch')
plt.ylabel('损失')
plt.legend()
plt.tight_layout()
plt.show()
# 混淆矩阵
from sklearn.metrics import confusion_matrix
import seaborn as sns
# 预测测试集
y_pred = best_model.predict(x_test)
y_pred_classes = np.argmax(y_pred, axis=1)
y_true = np.argmax(y_test, axis=1)
# 计算混淆矩阵
cm = confusion_matrix(y_true, y_pred_classes)
# 绘制混淆矩阵
plt.figure(figsize=(10, 8))
class_names = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=class_names, yticklabels=class_names)
plt.title('混淆矩阵')
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.show()
6. 可视化特征图
查看卷积层提取的特征,帮助我们理解CNN的工作原理:
import tensorflow as tf
# 创建一个模型,用于提取中间层特征
layer_outputs = [layer.output for layer in model.layers if isinstance(layer, tf.keras.layers.Conv2D)]
activation_model = tf.keras.models.Model(inputs=model.input, outputs=layer_outputs)
# 选择一张测试图像
img_index = 12
test_img = x_test[img_index:img_index+1]
# 获取特征图
activations = activation_model.predict(test_img)
# 显示原始图像
plt.figure(figsize=(6, 6))
plt.imshow(x_test[img_index])
plt.title(f"原始图像: {class_names[y_true[img_index]]}")
plt.axis('off')
plt.show()
# 可视化前两个卷积层的特征图
plt.figure(figsize=(15, 8))
for i in range(2):
feature_maps = activations[i]
n_features = min(16, feature_maps.shape[-1]) # 最多显示16个特征图
for j in range(n_features):
plt.subplot(2, 8, i*8+j+1)
plt.imshow(feature_maps[0, :, :, j], cmap='viridis')
plt.axis('off')
if j == 0:
plt.title(f"卷积层 {i+1}")
plt.tight_layout()
plt.show()
五、总结与展望
在本文中,我们深入探讨了卷积神经网络的进阶内容。我们学习了从LeNet到ResNet的经典CNN架构演化,了解了数据增强的重要性和实现方法,掌握了Dropout和Batch Normalization的工作原理,并通过CIFAR-10图像分类任务进行了实践。
这些进阶知识将帮助你构建更强大、更准确的卷积神经网络模型。随着深度学习的不断发展,CNN架构也在不断创新,如MobileNet(轻量级网络)、EfficientNet(自动缩放网络)等,这些都是值得进一步探索的方向。
学习资源
-
论文:
- Deep Residual Learning for Image Recognition (ResNet)
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
-
课程:
- 吴恩达的深度学习课程(Coursera)
- CS231n: Convolutional Neural Networks for Visual Recognition(斯坦福)
-
书籍:
- 《Deep Learning》by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
下一步学习方向
- 迁移学习:利用预训练模型加速新任务的学习
- 目标检测:YOLO、SSD、Faster R-CNN等算法
- 语义分割:U-Net、DeepLab等架构
- 生成对抗网络(GANs):用于图像生成和风格迁移
希望本文对你理解卷积神经网络的进阶内容有所帮助。在下一篇文章中,我们将探索更多深度学习的前沿技术!
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!