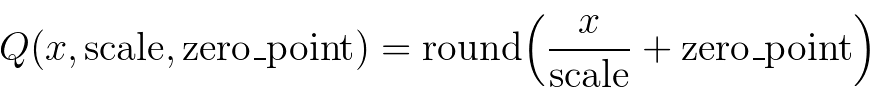名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、什么是深度学习?它与传统机器学习的区别
- 1. 深度学习的定义
- 2. 深度学习与传统机器学习的区别
- 二、神经网络的发展历程:感知机 → 深度神经网络
- 1. 感知机:神经网络的起点
- 2. 多层感知机(MLP)
- 3. 反向传播与深度学习的第一次浪潮
- 4. 深度学习的复兴与突破
- 三、安装深度学习框架
- 1. TensorFlow 入门安装与配置
- (1) 使用pip安装TensorFlow
- (2) 验证安装
- (3) TensorFlow环境配置建议
- 2. PyTorch 入门安装与配置
- (1) 使用pip安装PyTorch
- (2) 验证安装
- (3) PyTorch环境配置建议
- 四、编写第一个深度学习程序(Hello World)
- 1. TensorFlow实现
- 2. PyTorch实现
- 五、练习:运行一个简单的神经网络模型
- 练习:使用深度学习识别手写数字
- TensorFlow版本
- 拓展练习
- 六、总结与展望
- 参考资源
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第49天:特征工程与全流程建模
欢迎来到Python星球的第50天!🪐
今天我们将踏入人工智能领域中最令人兴奋的技术——深度学习。随着这项技术的飞速发展,它已经在图像识别、自然语言处理、推荐系统等众多领域掀起了革命性的变化。让我们一起探索这个奇妙的世界!
一、什么是深度学习?它与传统机器学习的区别
1. 深度学习的定义
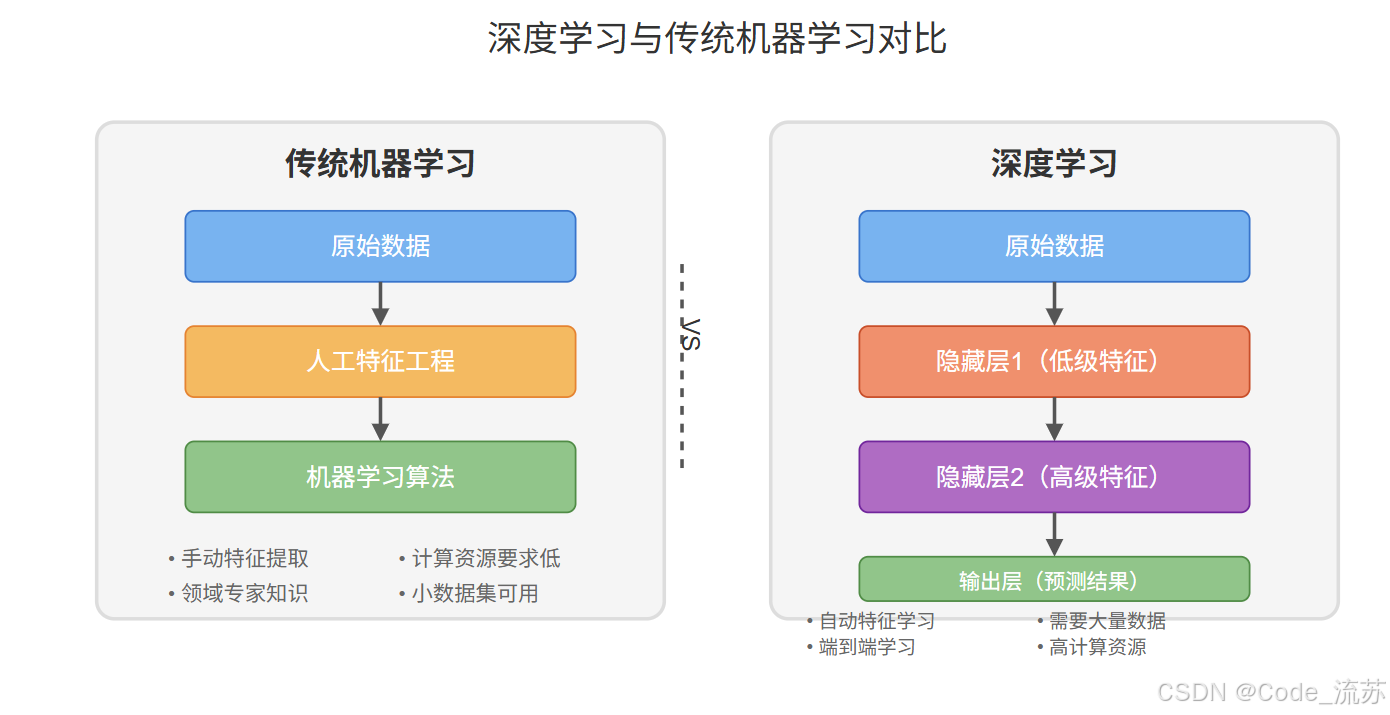
深度学习是机器学习的一个分支,它通过模拟人脑的结构和功能,使用多层神经网络来学习数据中的复杂模式。与传统的机器学习算法相比,深度学习能够自动从原始数据中提取特征,无需人工干预即可发现数据中的隐藏规律。
以学习的例子,来再理解一下机器学习和深度学习的概念。
-
机器学习 类似于 教学生解题时给他们公式和步骤;
-
深度学习 类似于 让学生自己总结出解题的公式。
深度学习的核心在于其"深度",即神经网络中的多层结构。每一层都能够学习数据的不同级别的抽象表示,从简单的特征(如图像中的边缘、文本中的单词)到复杂的概念(如人脸、句子的语义)。
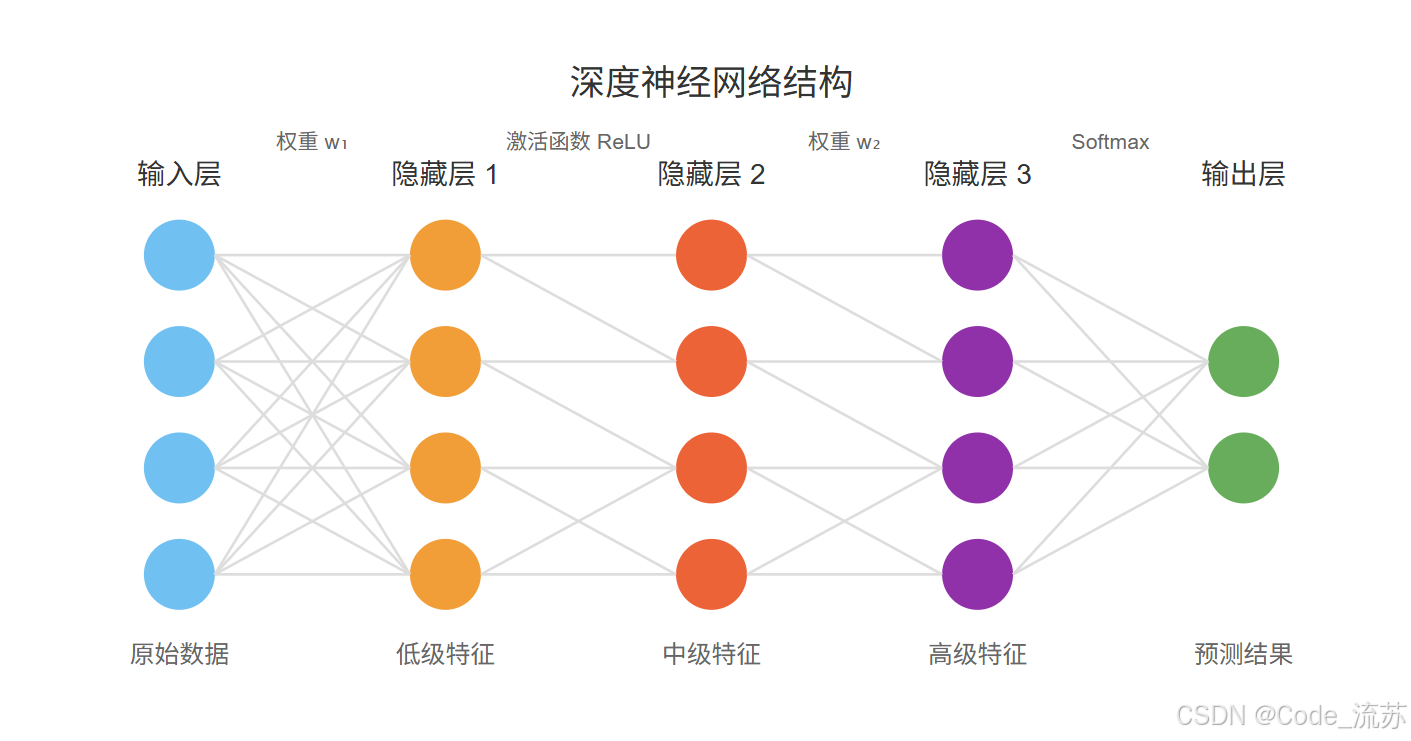
2. 深度学习与传统机器学习的区别
| 特性 | 传统机器学习 | 深度学习 |
|---|---|---|
| 特征提取 | 需要人工设计特征 | 自动学习特征 |
| 数据量要求 | 可以在较小的数据集上表现良好 | 通常需要大量数据 |
| 计算资源 | 计算资源需求相对较低 | 需要强大的计算资源(GPU/TPU) |
| 可解释性 | 多数算法具有较好的可解释性 | 通常被视为"黑盒",可解释性较差 |
| 适用场景 | 结构化数据,问题明确 | 非结构化数据(图像、文本、音频) |
| 性能上限 | 随着数据增加,性能提升有限 | 随着数据和模型规模增加,性能可持续提升 |
传统机器学习算法(如我们之前学习的决策树、SVM等)在特征明确的情况下效果很好,但面对原始的、复杂的数据(如图像、音频)时往往力不从心。
而 深度学习 则擅长从这些复杂数据中自动学习表示,这也是为什么它在计算机视觉、自然语言处理等领域取得了突破性进展。
二、神经网络的发展历程:感知机 → 深度神经网络
1. 感知机:神经网络的起点
感知机(Perceptron)是最早的人工神经网络模型之一,由Frank Rosenblatt在1958年提出。它模拟了单个神经元的工作方式,接收多个输入信号,通过加权求和和激活函数产生输出。
感知机的数学表达式为:
output = activation_function(∑(weight_i * input_i) + bias)
尽管结构简单,感知机只能解决线性可分的问题(如逻辑与、逻辑或),但它奠定了神经网络的基础。
2. 多层感知机(MLP)
为了克服单层感知机的局限性,研究人员提出了多层感知机(Multi-layer Perceptron),它由输入层、一个或多个隐藏层和输出层组成。然而,早期的多层网络面临训练困难的问题,直到反向传播(Backpropagation)算法的出现。
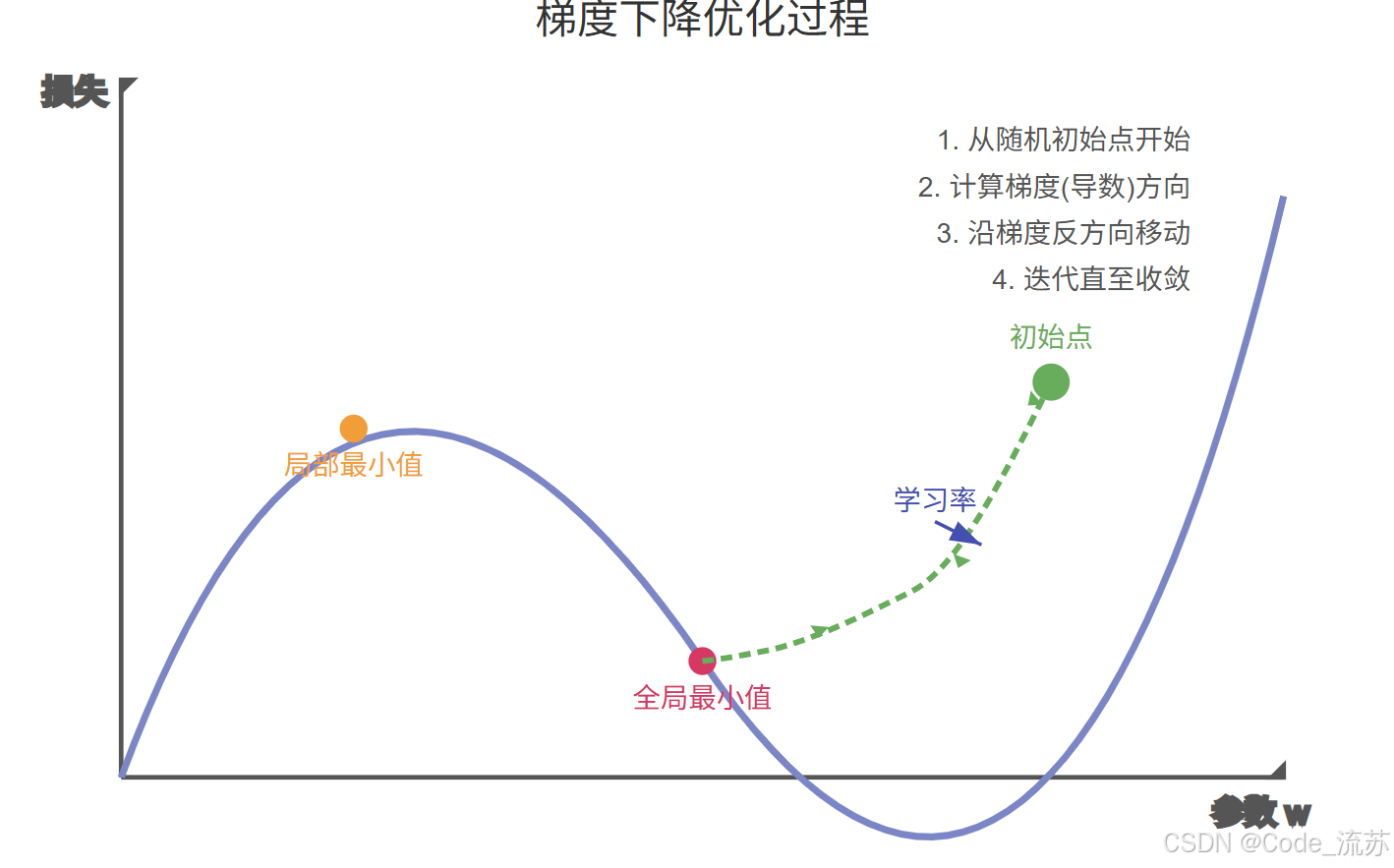
3. 反向传播与深度学习的第一次浪潮
20世纪80年代,反向传播算法的普及解决了多层网络的训练问题。这一算法通过计算损失函数对网络参数的梯度,并沿着梯度的反方向调整参数,从而最小化预测误差。
4. 深度学习的复兴与突破
尽管理论基础早已建立,但直到21世纪初,深度学习才真正取得突破性进展。这主要得益于三个关键因素:
- 大规模数据:互联网时代产生的海量数据为模型训练提供了充足的素材
- 计算能力:GPU等并行计算设备的发展大幅提升了训练速度
- 算法创新:新的网络结构和优化算法不断涌现
2012年,AlexNet在ImageNet图像分类竞赛中的惊人表现标志着深度学习时代的到来。此后,各种网络架构如卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)和Transformer等推动了深度学习在各个领域的应用。
三、安装深度学习框架
要开始深度学习之旅,我们首先需要安装相应的框架。目前最流行的两个深度学习框架是TensorFlow和PyTorch,它们各有特色,都值得学习。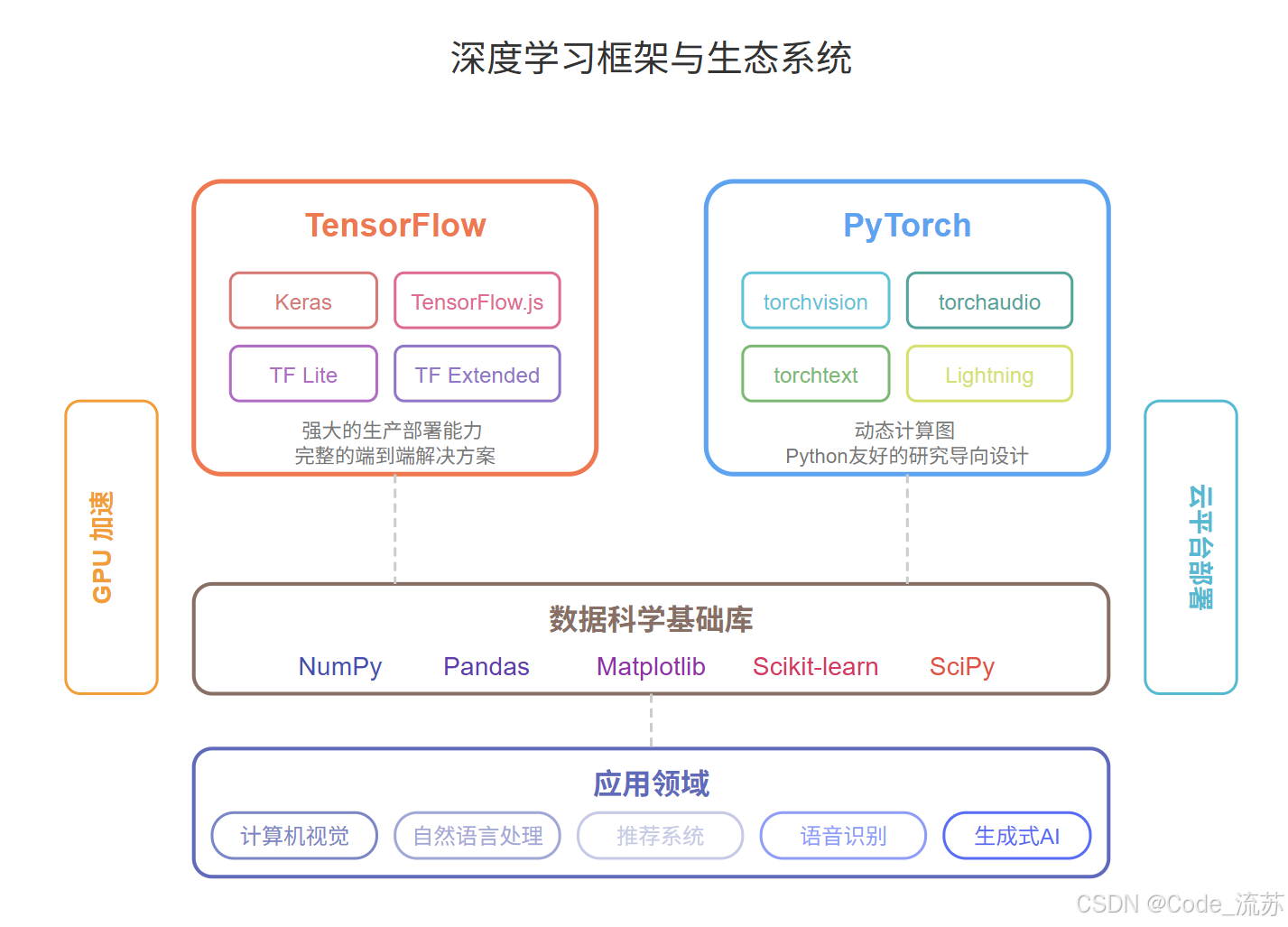
1. TensorFlow 入门安装与配置
TensorFlow是由Google开发的开源深度学习框架,以其强大的生产部署能力和完善的生态系统而著名。
(1) 使用pip安装TensorFlow
# 安装CPU版本的TensorFlow
pip install tensorflow
# 或者安装支持GPU的版本(需要CUDA和cuDNN)
pip install tensorflow-gpu
注意:从TensorFlow 2.0开始,tensorflow-gpu包已合并到tensorflow包中,安装时会自动检测并使用可用的GPU。
(2) 验证安装
安装完成后,可以运行以下代码验证TensorFlow是否正确安装:
import tensorflow as tf
print("TensorFlow版本:", tf.__version__)
# 检查是否可以使用GPU
print("可用的GPU设备:", tf.config.list_physical_devices('GPU'))

(3) TensorFlow环境配置建议
- Python版本:推荐使用Python 3.7-3.9
- 虚拟环境:建议使用Anaconda或venv创建独立的环境
- GPU支持:如需GPU加速,请安装与TensorFlow兼容的CUDA和cuDNN版本
- 内存要求:至少8GB RAM,深度模型训练建议16GB以上
2. PyTorch 入门安装与配置
PyTorch是由Facebook(Meta)AI研究团队开发的深度学习框架,以其动态计算图和直观的Python接口而受到研究人员的青睐。
(1) 使用pip安装PyTorch
PyTorch的安装需要根据你的操作系统和CUDA版本选择适当的命令。访问PyTorch官网(https://pytorch.org/get-started/locally/)可获取最适合你系统的安装命令。
以下是一个通用的安装命令示例:
# 安装CPU版本
pip install torch torchvision torchaudio
# 安装支持CUDA 11.6的GPU版本
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116

(2) 验证安装
使用以下代码验证PyTorch是否正确安装:
import torch
print("PyTorch版本:", torch.__version__)
# 检查CUDA是否可用
print("CUDA是否可用:", torch.cuda.is_available())
if torch.cuda.is_available():
print("CUDA设备数量:", torch.cuda.device_count())
print("当前CUDA设备:", torch.cuda.get_device_name(0))

(3) PyTorch环境配置建议
- Python版本:推荐Python 3.7-3.9
- 虚拟环境:同样推荐使用Anaconda管理环境
- GPU支持:确保安装与PyTorch兼容的CUDA版本
- 额外包:通常需要安装NumPy、Matplotlib等辅助包
四、编写第一个深度学习程序(Hello World)
了解了基本概念并完成环境配置后,让我们编写一个简单的深度学习程序,这就是深度学习领域的"Hello World"。我们将使用最简单的全连接神经网络来解决一个二分类问题。
下面分别用TensorFlow和PyTorch实现同一个任务,你可以根据个人喜好选择其中一个框架开始学习。
1. TensorFlow实现
import tensorflow as tf
import numpy as np
from sklearn.datasets import make_circles
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
from mpl_toolkits.mplot3d import Axes3D
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 生成螺旋形数据(一个经典的非线性二分类问题)
X, y = make_circles(n_samples=1000, noise=0.1, factor=0.2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. 构建神经网络模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu', input_shape=(2,)), # 隐藏层,10个神经元
tf.keras.layers.Dense(10, activation='relu'), # 第二个隐藏层
tf.keras.layers.Dense(1, activation='sigmoid') # 输出层,二分类问题
])
# 3. 编译模型
model.compile(
optimizer='adam', # Adam优化器
loss='binary_crossentropy', # 二分类的损失函数
metrics=['accuracy'] # 评估指标
)
# 4. 训练模型
history = model.fit(
X_train, y_train,
epochs=50, # 训练轮数
batch_size=32, # 批量大小
validation_data=(X_test, y_test), # 验证数据
verbose=1 # 显示进度
)
# 5. 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f"测试集准确率: {accuracy:.4f}")
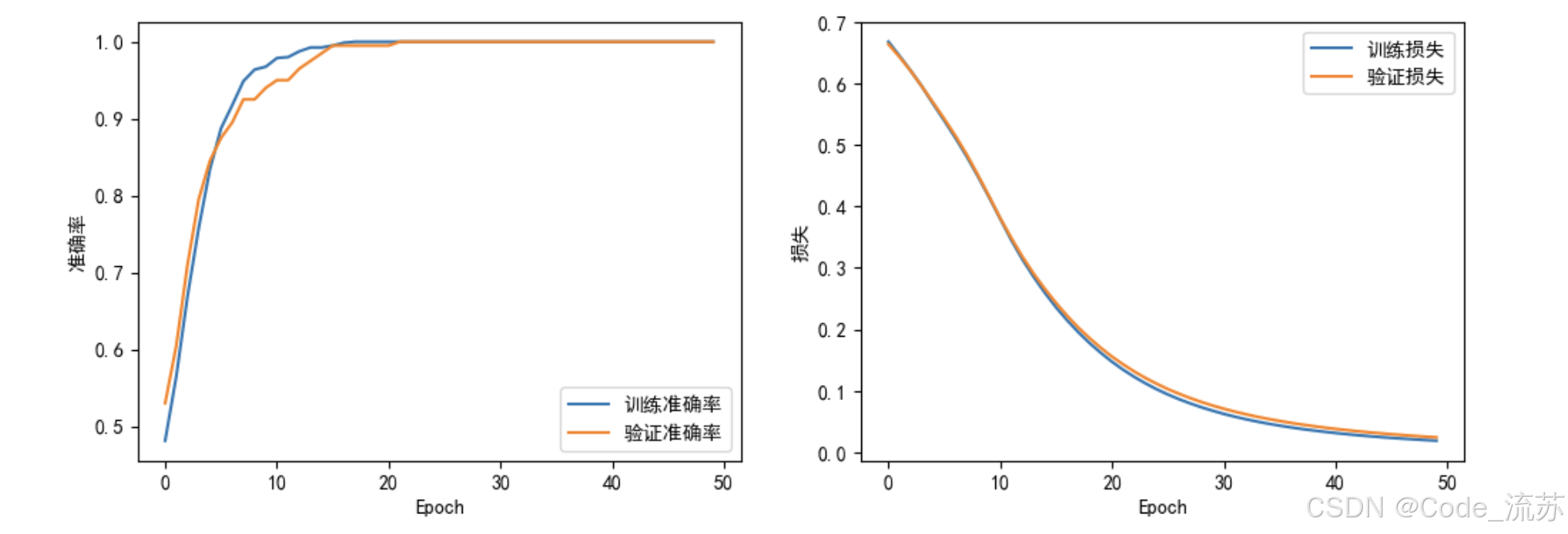
# 6. 可视化训练过程
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.xlabel('Epoch')
plt.ylabel('损失')
plt.legend()
plt.show()
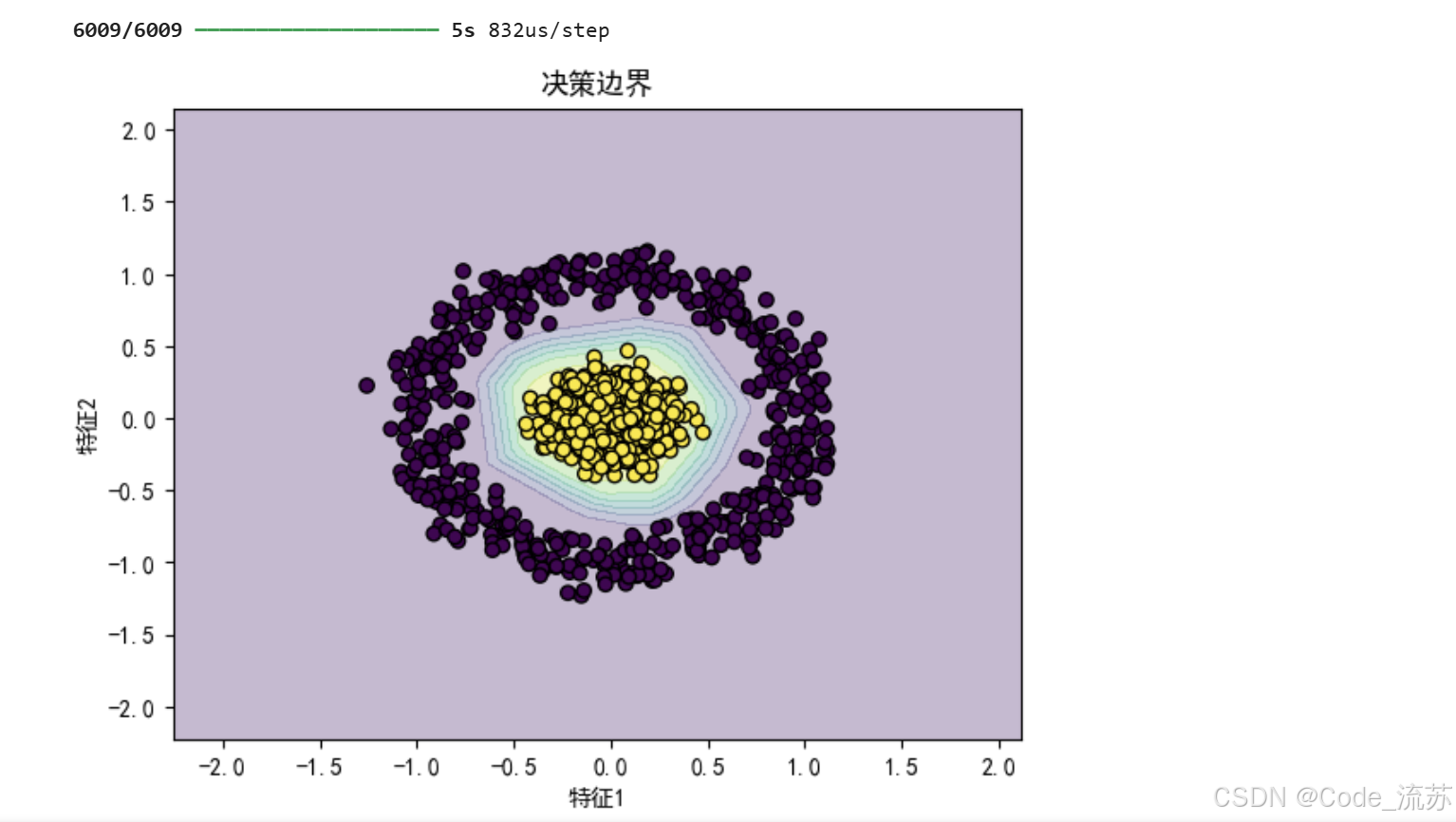
# 7. 可视化决策边界
def plot_decision_boundary(model, X, y):
# 定义网格
h = 0.01
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# 预测网格中每个点的类别
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.title('决策边界')
plt.show()
plot_decision_boundary(model, X, y)

2. PyTorch实现
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from sklearn.datasets import make_circles
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置随机种子确保可重复性
torch.manual_seed(42)
# 1. 生成数据
X, y = make_circles(n_samples=1000, noise=0.1, factor=0.2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 转换为PyTorch张量
X_train = torch.FloatTensor(X_train)
X_test = torch.FloatTensor(X_test)
y_train = torch.FloatTensor(y_train).reshape(-1, 1)
y_test = torch.FloatTensor(y_test).reshape(-1, 1)
# 2. 定义神经网络模型
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.layer1 = nn.Linear(2, 10) # 输入层到第一个隐藏层
self.layer2 = nn.Linear(10, 10) # 第一个隐藏层到第二个隐藏层
self.layer3 = nn.Linear(10, 1) # 第二个隐藏层到输出层
self.relu = nn.ReLU() # ReLU激活函数
self.sigmoid = nn.Sigmoid() # Sigmoid激活函数
def forward(self, x):
x = self.relu(self.layer1(x))
x = self.relu(self.layer2(x))
x = self.sigmoid(self.layer3(x))
return x
model = SimpleNN()
# 3. 定义损失函数和优化器
criterion = nn.BCELoss() # 二元交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.01) # Adam优化器
# 4. 训练模型
num_epochs = 50
batch_size = 32
train_losses = []
val_losses = []
train_accs = []
val_accs = []
for epoch in range(num_epochs):
# 训练模式
model.train()
for i in range(0, len(X_train), batch_size):
# 获取小批量数据
inputs = X_train[i:i+batch_size]
targets = y_train[i:i+batch_size]
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 评估模式
model.eval()
with torch.no_grad():
# 训练集评估
train_outputs = model(X_train)
train_loss = criterion(train_outputs, y_train).item()
train_acc = ((train_outputs > 0.5).float() == y_train).float().mean().item()
# 验证集评估
val_outputs = model(X_test)
val_loss = criterion(val_outputs, y_test).item()
val_acc = ((val_outputs > 0.5).float() == y_test).float().mean().item()
train_losses.append(train_loss)
val_losses.append(val_loss)
train_accs.append(train_acc)
val_accs.append(val_acc)
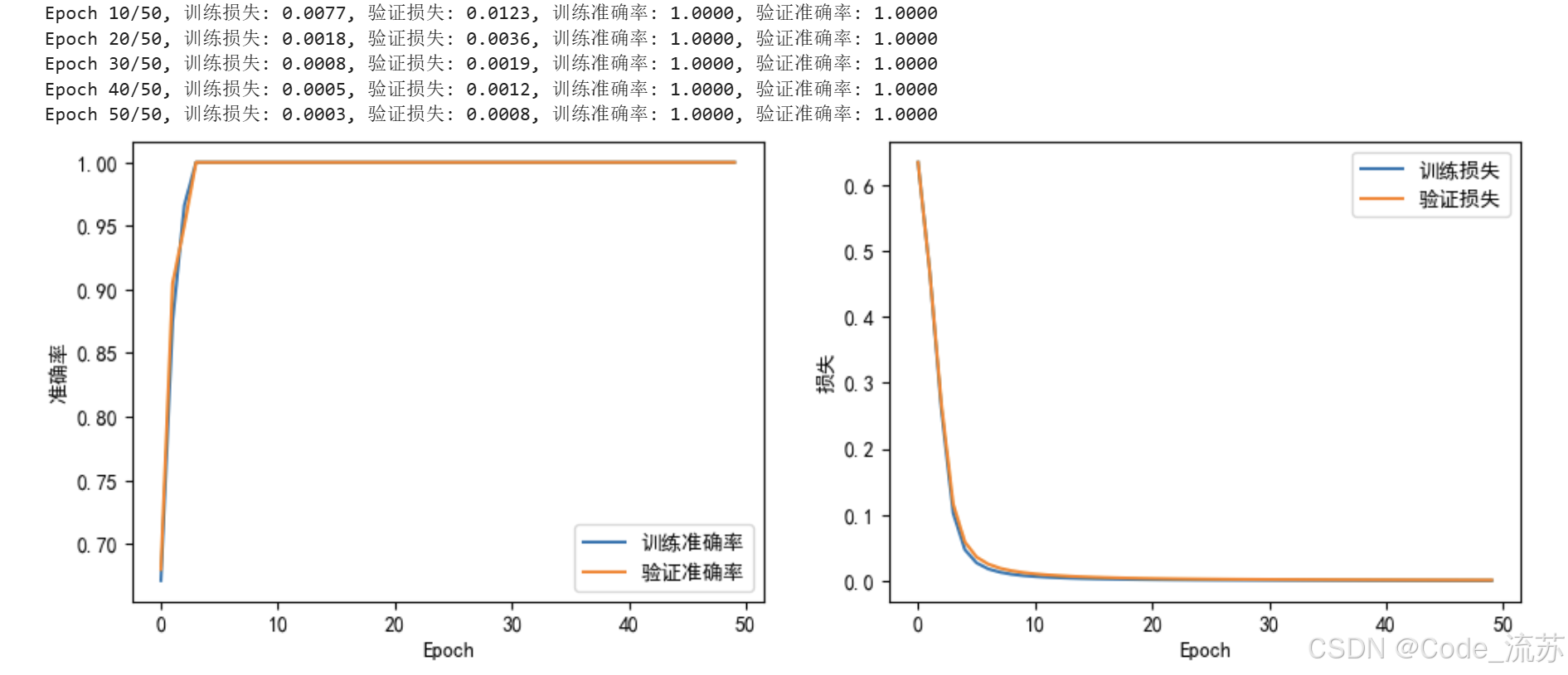
if (epoch+1) % 10 == 0:
print(f'Epoch {epoch+1}/{num_epochs}, 训练损失: {train_loss:.4f}, 验证损失: {val_loss:.4f}, 训练准确率: {train_acc:.4f}, 验证准确率: {val_acc:.4f}')
# 5. 可视化训练过程
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_accs, label='训练准确率')
plt.plot(val_accs, label='验证准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(train_losses, label='训练损失')
plt.plot(val_losses, label='验证损失')
plt.xlabel('Epoch')
plt.ylabel('损失')
plt.legend()
plt.show()
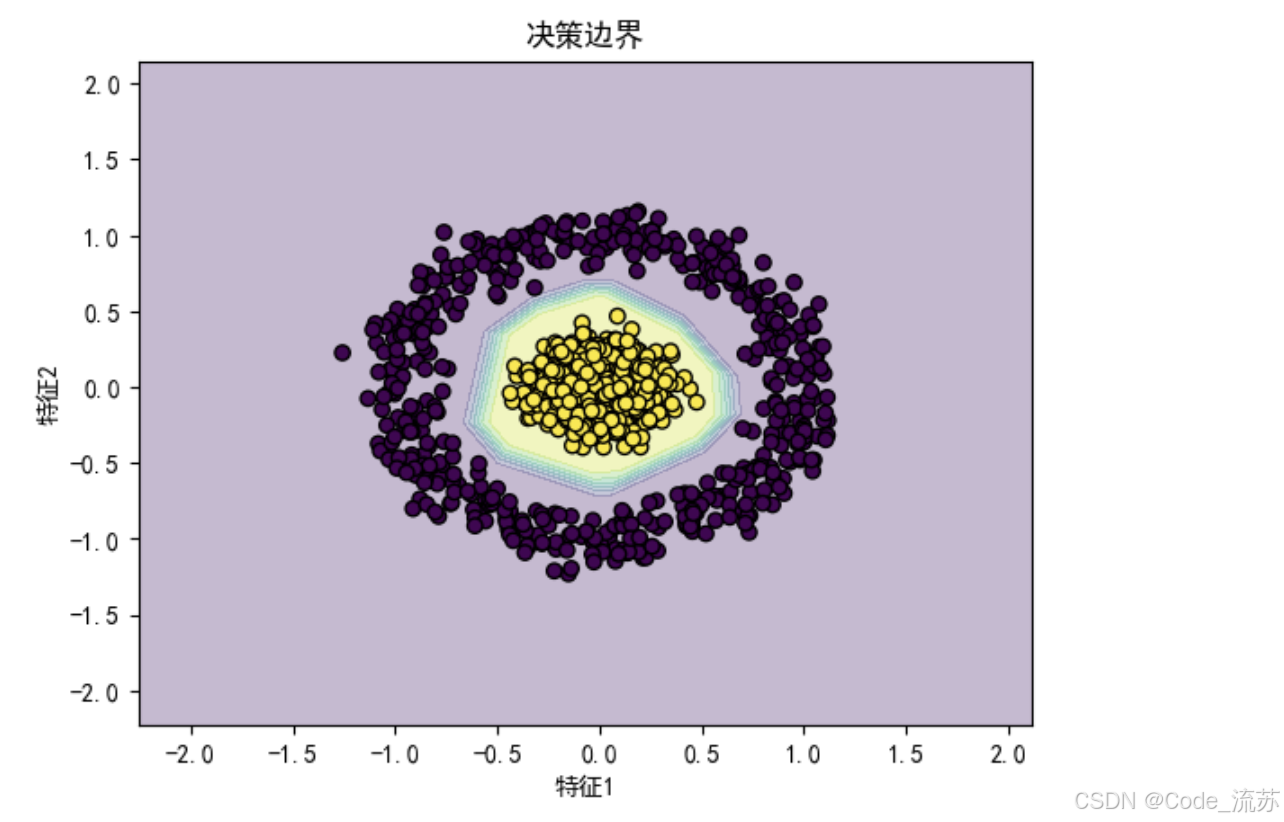
# 6. 可视化决策边界
def plot_decision_boundary(model, X, y):
# 定义网格
h = 0.01
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# 预测网格中每个点的类别
grid = torch.FloatTensor(np.c_[xx.ravel(), yy.ravel()])
with torch.no_grad():
Z = model(grid).reshape(-1).numpy()
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.title('决策边界')
plt.show()
plot_decision_boundary(model, X, y)
五、练习:运行一个简单的神经网络模型
对于初学者来说,理解深度学习的最好方式是亲自动手实践。下面提供一个简单的练习,帮助你巩固今天学到的知识。
练习:使用深度学习识别手写数字
MNIST数据集是机器学习中的"Hello World"数据集,包含了0-9的手写数字图像。这个练习将带你完成一个简单的手写数字识别模型。
TensorFlow版本
import tensorflow as tf
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
import numpy as np
# 1. 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 2. 数据预处理
# 归一化像素值到0-1之间
x_train = x_train / 255.0
x_test = x_test / 255.0
# 3. 构建模型
model = tf.keras.Sequential([
# 将28x28的图像展平为784个特征
tf.keras.layers.Flatten(input_shape=(28, 28)),
# 第一个隐藏层,128个神经元
tf.keras.layers.Dense(128, activation='relu'),
# 第二个隐藏层
tf.keras.layers.Dense(64, activation='relu'),
# 输出层,10个类别(数字0-9)
tf.keras.layers.Dense(10, activation='softmax')
])
# 4. 编译模型
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# 5. 训练模型
history = model.fit(
x_train, y_train,
epochs=10,
batch_size=64,
validation_data=(x_test, y_test)
)
# 6. 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"测试准确率: {test_acc:.4f}")
# 7. 可视化一些预测结果
predictions = model.predict(x_test)
plt.figure(figsize=(15, 6))
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(x_test[i], cmap='gray')
predicted_label = np.argmax(predictions[i])
true_label = y_test[i]
plt.title(f"预测: {predicted_label}, 实际: {true_label}")
plt.axis('off')
plt.tight_layout()
plt.show()


拓展练习
- 尝试调整网络结构(增加/减少层数、改变神经元数量)
- 实验不同的优化器(SGD、RMSprop等)
- 添加批归一化(Batch Normalization)层或Dropout层来提高模型性能
- 将全连接网络改为卷积神经网络(CNN)来提高识别准确率
六、总结与展望
今天,我们踏入了深度学习的世界,了解了它与传统机器学习的区别,神经网络的发展历程,以及如何搭建深度学习环境并运行第一个神经网络模型。这仅仅是深度学习旅程的起点,未来我们将探索更多精彩内容:
- 卷积神经网络(CNN)及其在计算机视觉中的应用
- 循环神经网络(RNN)和LSTM在序列数据处理中的应用
- Transformer架构和其在自然语言处理中的革命性影响
- 生成对抗网络(GAN)和扩散模型等生成模型
- 强化学习的基本概念与应用
深度学习是一个不断发展的领域,新的算法和技术层出不穷。保持学习的热情,跟随最新的研究进展,你将能够利用这些强大的工具解决各种复杂问题。
理论知识固然重要,但真正的学习来自于动手实践。尝试修改今天的代码,构建自己的模型,解决自己感兴趣的问题。只有这样,你才能真正掌握深度学习的精髓。
明天,我们将深入探讨卷积神经网络及其在图像处理中的应用。敬请期待!
参考资源
- TensorFlow官方文档:https://www.tensorflow.org/
- PyTorch官方教程:https://pytorch.org/tutorials/
- 《动手学深度学习》:https://d2l.ai/
- 《深度学习》(花书),Ian Goodfellow等著
- Andrew Ng的深度学习课程:https://www.coursera.org/specializations/deep-learning
学习永无止境,明天再会!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!