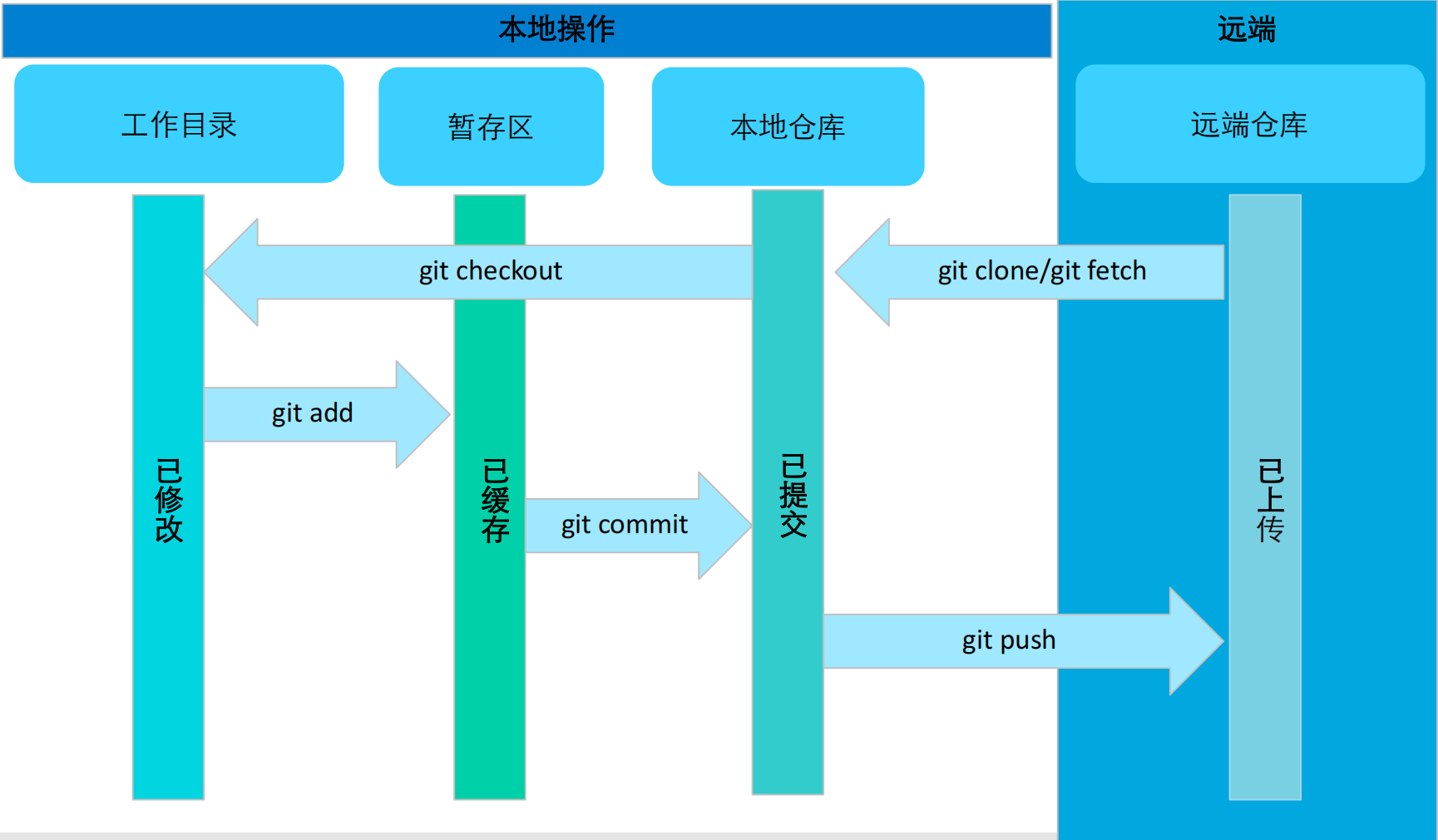
迁移学习原理
- 什么是迁移学习?
- 迁移学习利用在大规模数据集(如ImageNet)上预训练的模型,改装小数据集(如CIFAR-10)。
- 优势:
- 减少训练时间:预训练模型已学习通用特征(如边缘、纹理)。
- 提升性能:小数据集(如CIFAR-10,50K样本)也能达到很高的准确率。
- 降低过度:预训练权重提供强正则化。
- 两种模式:
- 特征提取:中心层,仅训练全连接层,适合小数据集。
- 压力:解冻部分或全部层,调整权重,适合中大型数据集。
- CIFAR-10 需求:
- 自建CNN(Day 6)准确率~83-88%,设定于数据量和模型深度。
- 迁移学习(ResNet18)可利用ImageNet特征,预计~90-95%。
- 步骤关键:
- 加载预训练模型(如ResNet18)。
- 修改输出层(ImageNet的1000类→CIFAR-10的10类)。
- 选择冻结/消耗策略,设置优化器和学习率。
PyTorch实现迁移学习
- 预训练模型:
- PyTorch的torchvision.models提供ResNet18、VGG16等模型。
- 加载:models.resnet18(pretrained=True)(PyTorch < 1.13)或models.resnet18(weights='IMAGENET1K_V1')(新版)。
- 修改模型:
- 替换全连接层:model.fc = nn.Linear(in_features, 10)。
- 冻结参数:
- requires_grad=False顶层设置层,减少计算量。
-
for param in model.parameters(): param.requires_grad = False model.fc.requires_grad = True
- 压力:策略
- 学习率低(如lr=0.0001)影响全连接层或最后几层。
- 差异化学习率:底层层用上下lr,全连接层用上下lr。
- 优化器:
- Adam 或 SGD(带动量),殴打第 5 天的 StepLR。
- 注意事项:
- CIFAR-10图像小(32x32),需调整输入(transforms.Resize(224))车载ResNet。
- 冻结过高层可能会破坏稳定性,解冻过早可能会重新预演训练权。
迁移学习的核心流程(以 PyTorch 为例)
我们以图像任务(如医学图像、CT图像)为例,迁移一个预训练的分割模型,如 UNet 或 nnU-Net:
步骤 1:加载预训练模型
import torch
from unet_model import UNet # 或者使用 torchvision.models, timm 等库
model = UNet(in_channels=1, out_channels=2) # 比如你的CT图像是单通道的
model.load_state_dict(torch.load('pretrained_model.pth'))
步骤 2:根据任务需求调整最后的输出层
比如你现在是2类(脑出血 vs 背景):
model.out_conv = torch.nn.Conv2d(64, 2, kernel_size=1)
步骤 3:选择是否冻结部分层(迁移策略选择)
冻结部分层
如果你的数据量小,而且和原任务相似:
for param in model.encoder.parameters():
param.requires_grad = False
只训练 decoder 和输出层,有助于防止过拟合。
全部解冻
如果你数据够用,或者原始任务差距较大,建议全部训练。
步骤 4:定义优化器和学习率(关键)
如果你只训练部分层,可以设置不同的学习率:
optimizer = torch.optim.Adam([
{'params': model.encoder.parameters(), 'lr': 1e-5},
{'params': model.decoder.parameters(), 'lr': 1e-4},
{'params': model.out_conv.parameters(), 'lr': 1e-3},
])
也可以统一使用较小学习率,比如 1e-4。
步骤 5:开始训练 + 验证模型效果
正常训练即可,重点监控:
-
Dice Score、IoU、Accuracy
-
验证集 loss 是否下降
-
是否过拟合(训练/验证差距大)
二、根据实际情况选择迁移方式
| 情况 | 推荐迁移方式 | 是否冻结 | 学习率设置 |
|---|---|---|---|
| 🔹 你数据很少(<20) | 迁移预训练 + 只训练最后几层 | 冻结大部分层 | 1e-4~1e-3 |
| 🔹 你数据中等(20~200) | 预训练模型基础上全模型微调 | 不冻结 | 1e-4 |
| 🔹 你数据多(>200) | 可选择从头训练 / 微调 | 不冻结 | 1e-4~5e-4 |
| 🔹 新任务和预训练任务差异很大 | 微调底层,保持高层不变 | 冻结部分 | 层间设不同学习率 |
| 🔹 输入模态改变(如RGB→灰度) | 修改输入通道 + 再训练第一层 | 不冻结前几层 | 1e-4 |
三、进阶技巧
1. 分阶段训练策略(渐进式迁移)
先只训练输出层 ➜ 再解冻 encoder 共同训练
2. MixUp、CutMix、图像增强
缓解数据少的问题,提高泛化能力。
3. 使用调度器调整学习率
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min')
四、迁移学习在 nnU-Net 中的具体策略
| nnU-Net 场景 | 操作建议 |
|---|---|
| 微调已有模型 | 用 --pretrained_weights 参数指定 |
| 数据少 | 使用 3d_lowres 或者减少训练 epoch |
| 模态不同 | 修改 dataset.json 中的 modality 信息,重新预处理 |
| 类别不同 | 自动适配输出通道,不需手动改网络结构 |
五、代码模板示例(PyTorch)
# 假设你迁移的是一个 UNet 模型
model = UNet(in_channels=1, out_channels=2)
# 加载预训练参数(除最后一层)
state_dict = torch.load("pretrained.pth")
state_dict.pop("out_conv.weight")
state_dict.pop("out_conv.bias")
model.load_state_dict(state_dict, strict=False)
# 设置优化器
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# 训练循环略
六、遇到的问题与解决办法
| 问题 | 原因 | 解决方式 |
|---|---|---|
| 训练不收敛 | 迁移层不匹配 / 学习率过高 | 降低学习率,重检查层结构 |
| 验证集效果差 | 模型过拟合 | 数据增强、冻结部分层 |
| 迁移失败 | 原模型任务差异大 | 尝试训练更多层或换模型 |
迁移学习的核心实际上就是要根据任务的不同,合理地选择哪些层冻结、哪些层解冻,以及如何调整各层的参数。
迁移学习的关键要素
-
是否冻结神经网络层
-
冻结层意味着这些层的参数在训练过程中不会更新,通常是为了防止过拟合,或者如果你有非常小的训练数据集,冻结部分层可以避免模型过于依赖数据中的噪声。
-
解冻层意味着这些层的参数会参与反向传播和优化,通常用于微调模型,使得网络能更好地适应新的任务。
-
-
冻结多少层
-
**低层(例如卷积层)**通常学习的是一些低级特征(如边缘、纹理等),这些特征在很多任务中是通用的,因此可以冻结。
-
**高层(例如全连接层、分类层)**通常学习的是与特定任务相关的高级特征,这些层可能需要解冻,进行微调。
-
-
是否需要修改某些层的参数
-
输出层:通常,输出层需要根据你当前任务的类别数进行调整。例如,如果原模型是用于10类分类,而你的任务是二分类,那么需要调整输出层的神经元个数。
-
输入层:如果你的输入数据的形态与预训练模型不同(例如通道数不同),那么需要调整输入层。
-
-
不同层的学习率
-
如果你冻结了低层,通常设置较低的学习率只训练高层。冻结低层后,高层可以使用较大的学习率进行微调。
-
如果全网络都解冻,那么可以设置统一学习率或根据层进行不同学习率的设置。
-
示例:
-
冻结卷积层(低层):
低层卷积层主要提取边缘、纹理等基础特征,对于不同的图像任务通常是通用的。所以你可以冻结这些层,避免它们受到训练数据集的影响。 -
微调全连接层(高层):
高层通常用于提取与任务紧密相关的特征。在这个肺部X光图像分类的任务中,模型需要学会分辨“是否有肺炎”,这个特定任务的特征需要重新训练。
from torchvision import models
import torch.nn as nn
# 加载预训练的ResNet18模型
model = models.resnet18(pretrained=True)
# 冻结所有卷积层
for param in model.parameters():
param.requires_grad = False
# 解冻全连接层(用于分类任务)
model.fc = nn.Linear(512, 2) # 2表示二分类任务
# 只训练最后一层
optimizer = torch.optim.Adam(model.fc.parameters(), lr=1e-4)
在这个例子中,只有全连接层(即 model.fc)会参与训练,其他层都被冻结。
示例:微调整个网络
如果你有较多的训练数据(比如几千张图像),你可以解冻整个模型,进行微调:
# 加载预训练的ResNet18模型
model = models.resnet18(pretrained=True)
# 解冻整个模型
for param in model.parameters():
param.requires_grad = True
# 重新定义全连接层
model.fc = nn.Linear(512, 2)
# 设置优化器,训练整个网络
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
在这种情况下,整个模型的所有参数都会被训练,模型能够更好地适应新的数据和任务。
小结:
-
冻结层:决定了哪些层的参数不参与训练(通常是低层特征提取部分),以减少计算负担或避免过拟合。
-
解冻层:决定了哪些层的参数会更新,通常涉及任务相关的高级特征部分(如分类层)。
-
调整输出层:根据任务要求,修改输出层的结构(如类别数)。
实现逐步训练
第一步:加载预训练模型并冻结全部参数
以 ResNet18 为例:
import torchvision.models as models
model = models.resnet18(pretrained=True)
# 冻结所有参数(不参与训练)
for param in model.parameters():
param.requires_grad = False
第二步:替换最后的输出层(根据任务类别数量)
CIFAR-10 有 10 个类别:
import torch.nn as nn
num_classes = 10
model.fc = nn.Linear(model.fc.in_features, num_classes)
这时候,只有最后一层(fc)是可训练的。
第三步:逐步解冻 + 分阶段训练
这里是关键 —— 每轮训练后解冻部分网络层,例如从layer4开始逐渐解冻到layer3、layer2……
你可以按如下方式写:
第 1 阶段:只训练 fc 层(已经自动解冻)
# 只优化 fc 层的参数
optimizer = torch.optim.Adam(model.fc.parameters(), lr=1e-3)
# 训练若干 epoch
train_model(model, dataloader, optimizer, ...)
第 2 阶段:解冻 layer4(最靠近输出的残差层)
for name, param in model.named_parameters():
if "layer4" in name:
param.requires_grad = True
# 优化 layer4 + fc 层参数
params_to_optimize = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.Adam(params_to_optimize, lr=1e-4)
# 再训练若干 epoch
train_model(model, dataloader, optimizer, ...)
第 3 阶段:解冻 layer3,再训练……
for name, param in model.named_parameters():
if "layer3" in name:
param.requires_grad = True
params_to_optimize = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.Adam(params_to_optimize, lr=1e-5)
train_model(model, dataloader, optimizer, ...)
解冻技巧建议:
| 层名 | 含义 | 推荐做法 |
|---|---|---|
| conv1 / bn1 | 提取基础纹理、边缘等 | 不建议轻易解冻(除非任务差别极大) |
| layer1 / layer2 | 中间特征 | 后期可逐步解冻 |
| layer3 / layer4 | 高层语义特征 | 可先解冻 |
| fc | 输出层 | 一定要训练 |
逐步微调的顺序
| 步骤 | 微调层级 | 说明 |
|---|---|---|
| 1️⃣ | 只训练最后一层(fc 或分类头) | 最安全,先学新任务输出 |
| 2️⃣ | 解冻高层(如 ResNet 的 layer4) | 学习高层语义,适配新任务 |
| 3️⃣ | 解冻中层(如 layer3) | 逐步扩展学习能力 |
| 4️⃣ | 解冻低层(如 conv1, layer1) | 仅当任务差异大或图像域变化大时使用 |
小总结
| 阶段 | 冻结情况 | 优化哪些层 | 学习率 |
|---|---|---|---|
| 阶段1 | 冻结全部层,fc 除外 | 只训练 fc | 1e-3 |
| 阶段2 | 解冻 layer4 | 训练 layer4 + fc | 1e-4 |
| 阶段3 | 解冻 layer3 | 训练 layer3 + layer4 + fc | 1e-5 |
逐步训练实际上就是通过if判断语句,冻结或者解冻特定的深度学习层,来达到从低到高逐步训练的效果
附加建议
-
每阶段训练 5~10 个 epoch 观察效果,不要急于解冻太多层;
-
使用 学习率调度器 或手动降低学习率,以免破坏已学好的权重;
-
使用验证集观察是否过拟合。
迁移学习示例 Resnet18应用到CIFAR-10数据集
import torch
import torch.nn as nn
import torch.optim as optim
from PyQt6.QtGui.QRawFont import weight
from PyQt6.QtWidgets.QWidget import sizeHint
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix, classification_report
from transformers import FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING
from CIFAR10_CNN import train_transform, criterion
class Cutout: #数据预处理 随机覆盖
def __init__(self,size,p=0.5):
self.size = size #覆盖图片的大小
self.p = p #随机覆盖的概率
def __call__(self, img):
if torch.rand(1)>self.p: #随机生成0到1之间的数 通过判断语句来决定是否覆盖
return img
h, w = img.shape[1:] #img的形状为 b w h 输出图片的高和宽
cx = torch.randint(0, w, (1,)) #再 宽 上随机生成覆盖图片的横坐标的中心
cy = torch.randint(0, h, (1,))#再 高 上随机生成覆盖图片的纵坐标的中心
x1 = torch.clamp(cx - self.size // 2, 0, w)
x2 = torch.clamp(cx + self.size // 2, 0, w)
y1 = torch.clamp(cy - self.size // 2, 0, h) #后面的参数 是设置坐标的最值
y2 = torch.clamp(cy + self.size // 2, 0, h) #计算 覆盖图片的四个顶角的坐标
img[:, y1:y2, x1:x2] = 0 #把这个区域的像素值设置为0 完成遮挡
return img
#数据预处理
train_transform = transforms.Compose([
transforms.Resize(224), #本来图片的大小为32*32 但是resnet18这个预训练模型的数据图片大小为224*224 所以要将输入的训练集数据改为适应resnet模型的图片大小
transforms.RandomCrop(224,padding=28), #随机裁剪
transforms.RandomHorizontalFlip(), #水平翻转
transforms.ColorJitter(brightness=0.2,contrast=0.2,saturation=0.2,hue=0.1) #颜色抖动
transforms.ToTensor(),
Cutout(size=16,p=0.5), #调整 size 适应 224x224
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3)) #随机选择一块矩形区域,并将其像素内容擦除
#p 应用此变换的概率,0.5 表示 50% 概率进行擦除。
#scale=(min_area, max_area) 擦除区域在整个图像面积中的占比范围。比如:0.02~0.33 表示面积占 2%~33%。
#ratio=(min_ratio, max_ratio) 擦除区域的宽高比(w/h),例如 0.3~3.3 表示形状可以是细长的也可以是扁平的。
#value(可选) 擦除区域填充的像素值(默认是 0,即黑色),可以设为 random 进行随机填充。
])
test_transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
#数据集加载
train_dataset = datasets.CIFAR10(root='./data', train=True, transform=train_transform, download=True)
test_dataset = datasets.CIFAR10(root='./data', train=False, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
#迁移学习 模型主体
model = models.resnet18(weight = 'IMAGENET1K') # 加载 ImageNet 预训练权重
for param in model.parameters():
param.requires_grad = False #冻结模型中的所有参数
num_ftrs = model.fc.in_features #获得 预训练模型的全连接层的 输入数据的大小
model.fc = nn.Linear(num_ftrs,10) #重新设置 模型的全连接层的输出大小 比如CIFAR-10 的 10 类输出 所以输出数据的大小改为10
for param in model.fc.parameters():
param.requires_grad = True #将全连接层解冻 方便后面对全连接层的微调
#图像增强
#Mixup 是一种图像增强技术,它通过将两张图像线性叠加,以及对应标签也按比例线性叠加,从而构造新的训练样本。
#目的是提高模型的泛化能力、鲁棒性,降低过拟合。
def mixup_data(x,y,alpha=1.0):
lam = torch.distributions.beta.Beta(alpha, alpha).sample()
batch_size = x.size(0)
index = torch.randperm(batch_size).to(x.device)
mixed_x = lam * x + (1 - lam) * x[index]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def mixup_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)
criterion = nn.CrossEntropyLoss(label_smoothing=0.1)
optimizer = optim.Adam(model.fc.parameters(),lr=0.001)#仅仅优化全连接层的参数
scheduler = optim.lr_scheduler.StepLR(optimizer,step_size=2,gamma=0.1)
epochs = 5
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
train_accs = []
test_accs = []
for epoch in range(epochs):
model.train()
correct = 0
total = 0
total_loss = 0
for images,labels in train_loader:
images,labels =images.to(device),labels.to(device)
if torch.rand(1)<0.5
images, y_a, y_b, lam = mixup_data(images, labels, alpha=1.0)
logits = model(images)
loss = mixup_criterion(criterion, logits, y_a, y_b, lam)
else:
logits = model(images)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * len(images)
pred = torch.argmax(logits, dim=1)
correct += (pred == labels).sum().item()
total += len(labels)
train_acc = correct / total
train_accs.append(train_acc)
print(f"Epoch {epoch + 1}, Loss: {total_loss / total:.4f}, Train Acc: {train_acc:.4f}")
#计算模型整体的准确率
model.eval() #将模型设置为评估模式
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
logits = model(images)
pred = torch.argmax(logits, dim=1)
correct += (pred == labels).sum().item()
total += len(labels)
test_acc = correct / total
test_accs.append(test_acc)
print(f"Test Acc: {test_acc:.4f}")
scheduler.step()
# 其他详细的评估指标 精确率 召回率 混淆矩阵
model.eval()
all_preds = []
all_labels = []
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
logits = model(images)
preds = torch.argmax(logits, dim=1)
all_preds.extend(preds.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
#将测试集的测试结果和其他数据记录下来 方便后面的评估的计算
#计算各种评估指标
accuracy = sum(p == l for p, l in zip(all_preds, all_labels)) / len(all_labels)
cm = confusion_matrix(all_labels, all_preds) #混淆矩阵
report = classification_report(all_labels, all_preds, target_names=[
'airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']) #分类报告,包含每一类的 精确率 precision,召回率 recall,F1 值 f1-score,支持样本数 support
# Print results
print(f"Test Accuracy: {accuracy:.4f}")
print("\nClassification Report:")
print(report)
# Visualize confusion matrix
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=train_dataset.classes,
yticklabels=train_dataset.classes)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()
# Plot accuracy curves
plt.figure(figsize=(8, 6))
plt.plot(train_accs, label='Train Accuracy')
plt.plot(test_accs, label='Test Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Train vs Test Accuracy')
plt.legend()
plt.show()